

stata实证分析专题【计量经济系列(三)】
文章目录
ʚʕ̯•͡˔•̯᷅ʔɞʚʕ̯•͡˔•̯᷅ʔɞʚʕ̯•͡˔•̯᷅ʔɞʚʕ̯•͡˔•̯᷅ʔɞʚʕ̯•͡˔•̯᷅ʔɞʚʕ̯•͡˔•̯᷅ʔɞʚʕ̯•͡˔•̯᷅ʔɞʚʕ̯•͡˔•̯᷅ʔɞʚʕ̯•͡˔•̯᷅ʔɞʚʕ̯•͡˔•̯᷅ʔɞ



; 1. 数据
use grilic,clear
list s lnw in 1/10
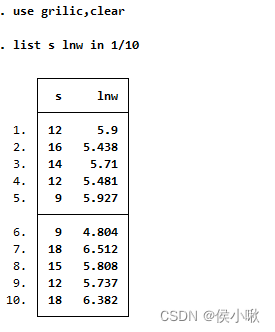
- 有常数项的回归
reg lnw s
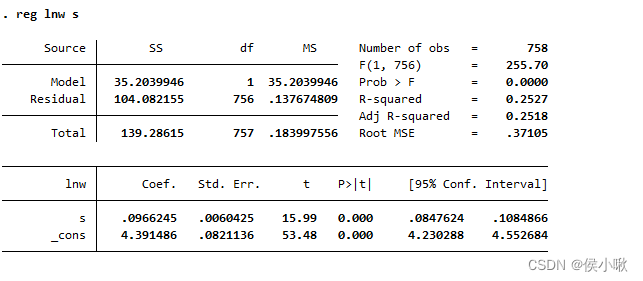
其中
SS中Model 表示可以被模型解释的平方和(回归解释平方和),即ESS。
SS 中 Residual 表示残差平方和(未解释平方和),即RSS。
df表示自由度
MS表示单位自由度的平方和,M S = S S d f \displaystyle MS=\frac{SS}{df}M S =d f S S ,MS可以用来反映数据的变动趋势,对回归分析有一定参考价值 。
Number of obs 表示观测值(数据)的个数
F(1, 756)表示 检验整个方程显著性的F 统计量,即F ( k − 1 , n − k ) F(k-1,n-k)F (k −1 ,n −k )的值,这个在多元回归中更具有研究意义,但是这里还是要先讲一下:
其中k是2,表示有一个常数项,一个自变量的自由度之和为2。
k-1表示减去常数项的自由度。n是758,即758个样本数据的自由度。
将F值与临界值F α ( k − 1 , n − k ) F_{\alpha}(k-1,n-k)F α(k −1 ,n −k )的大小比较,
在5%的置信水平下,因为n-k大于了120,则视为无穷大,即F α ( 1 , ∞ ) F_{\alpha}(1,\infty)F α(1 ,∞)值为3.84,F(1, 756)值为255.7,远大于它,则应拒绝原假设N 0 N_0 N 0 :β_1=β_2=…=0(即模型联合不显著)。表明模型是联合显著的。
在使用stata等工具时,相比F值,更常用的是P值。
Prob>F 即P值,
在此例中,
P值为0,即在0.1、0.05、0.02、0.01的显著性水平下,P值都小于他们,也可以得出拒绝原假设的结论,即模型是联合显著的。
R-squared即R 2 R^2 R 2,可决系数,或拟合优度。
Adj R-squared 即修正可决系数
R ‾ 2 = 1 − ∑ e i 2 / ( n − k ) ∑ ( Y i − Y ‾ ) 2 / ( n − 1 ) = 1 − n − 1 n − k ∑ e i 2 ∑ ( Y i − Y ‾ ) 2 \overline{R}^2=1-\frac{\sum{e_i^2}/(n-k)}{\sum{(Y_i-\overline{Y})^2}/(n-1)}=1-\frac{n-1}{n-k}\frac{\sum{e_i^2}}{\sum{(Y_i-\overline{Y})^2}}R 2 =1 −∑(Y i −Y )2 /(n −1 )∑e i 2 /(n −k )=1 −n −k n −1 ∑(Y i −Y )2 ∑e i 2
Root MSE是均方根误差,也叫方程的标准偏差 或 方程的标准误差。
其不同于标准差
标准差是用来衡量一组数自身的离散程度,而均方根误差是用来衡量观测值同真值之间的偏差,它们的研究对象和研究目的不同,但是计算过程类似。
计算公式为
Root MSE = d i 2 n \displaystyle = \sqrt{\frac{di^2}{n}}=n d i 2 = ( y i − y i ^ ) 2 n \displaystyle=\sqrt{\frac{{(y_i−\hat{y_i})}^2}{n}}=n (y i −y i ^)2
其中y i y_i y i 是真实值,y i ^ \hat{y_i}y i ^是拟合值。而是方差和标准差中则是真实值减去均值进行计算的。
“Coef.”表示回归系数(Coefficient),
“_cons”表示常数项(constant)
所以此处得到的回归线为:
ln w ^ = 4.391 + 0.097 s \displaystyle \hat{\ln{w}}=4.391 + 0.097s ln w ^=4 .3 9 1 +0 .0 9 7 s
t表示T统计量的值,可以与临界值相比较。
P>|t| 即P值。将其与目标显著性水平相比较,具体不再赘述。
[95% Conf. Interval]则表示置信水平为95%的置信区间。
绘制散点图与回归线
twoway (scatter lnw s)(lfit lnw s)

- 无常数项的回归
少数情形,我们希望在做回归的时候施加一定的约束,即x=0时y=0,即截距为零。比如对于一对密度不尽相同的石头,当其体积为0时,质量一定也为0。
noc全称为noconstant
reg lnw s,noc
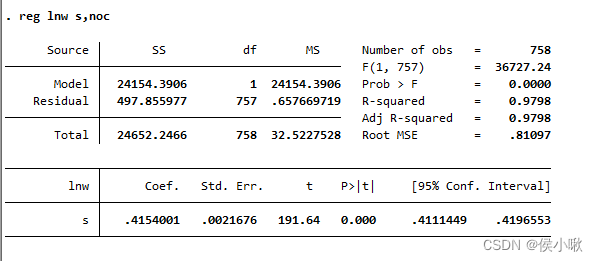
上边解释得太详细了,这里的输出结果就不再一一解释了。
两次计算R 2 R^2 R 2的公式是不相同的,
如果使用原来的公式计算没有常数项的方程R 2 R^2 R 2,即
1 − ∑ i = 1 n ( y i − β 1 x i ) 2 ∑ i = 1 n ( y i − y ‾ ) 2 \displaystyle 1-\frac{\sum_{i=1}^{n}{(y_i-\beta_1x_i)^2}}{\sum_{i=1}^{n}{(y_i-\overline{y})^2}}1 −∑i =1 n (y i −y )2 ∑i =1 n (y i −β1 x i )2
则计算结果为负值。
这里的的R 2 R^2 R 2是由新的公式:
1 − ∑ i = 1 n ( y i − β 1 x i ) 2 ∑ i = 1 n y i 2 \displaystyle 1-\frac{\sum_{i=1}^{n}{(y_i-\beta_1x_i)^2}}{\sum_{i=1}^{n}{y_i^2}}1 −∑i =1 n y i 2 ∑i =1 n (y i −β1 x i )2
计算出的。
通过两次回归,可以看到前者仅有0.2527,而后者高达0.9798。无常数项的R 2 R^2 R 2和有常数项的R 2 R^2 R 2之间是不可比的。
在合适的情形下选择不具有常数项的模型,会更具有经济意义。
而且,无常数项的回归结果得到的系数0.4154作为投资回报率,明显是不合理的。
而从有常数项的回归结果中,可以看到常数项的P值为0,说明拒绝原假设,常数项是显著不为0的,也说明此模型的选择应该有常数项。
- 多元回归
reg lnw s expr tenure smsa rns
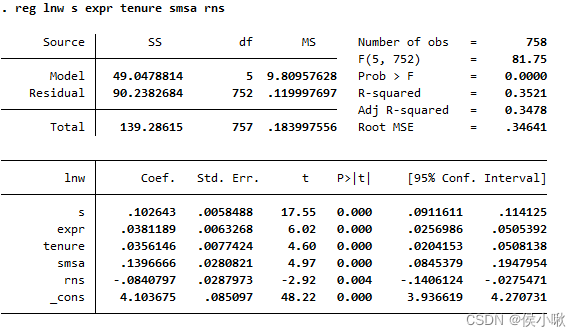
图表读法同上文所述。
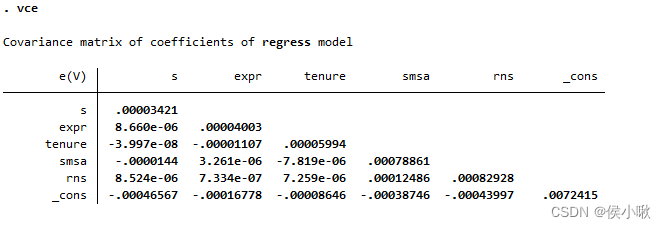
回归系数协方差矩阵 vce
vce指的是 variance covariance matrix estimated
使用命令vce可以实现显示回归系数的协方差矩阵。
其对上一次回归命令的回归结果进行操作,而不需要指定参数。
vce
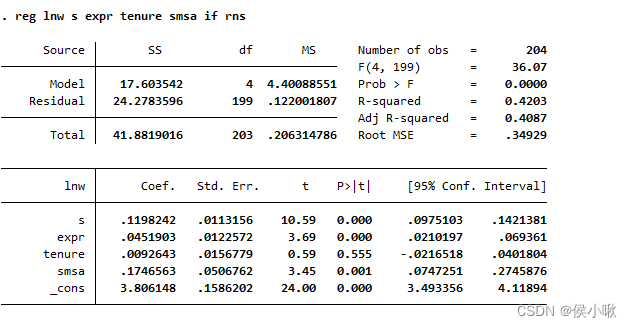
- 对部分满足条件数据做回归
其中rns有0和1两种取值,0表示北方,1表示南方,
如果只对南方居民样本进行回归
reg lnw s expr tenure smsa if rns
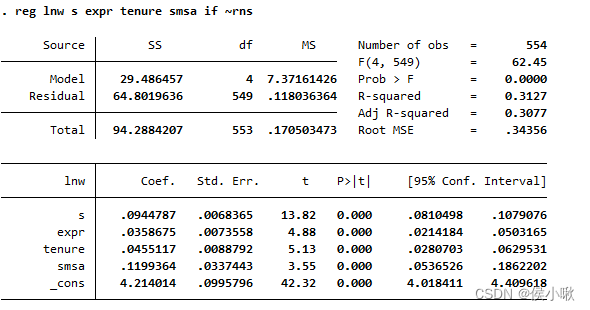
反之,只对北方居民做回归,则使用波浪线符号 ~ 表示逻辑否:
reg lnw s expr tenure smsa if ~rns
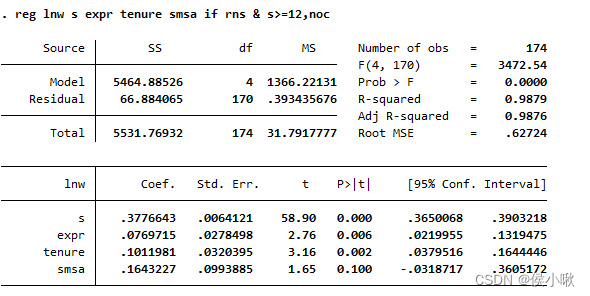
对变量s大于等于12且rns为1的数据,且不要常数项:
reg lnw s expr tenure smsa if rns & s>=12,noc
- predict
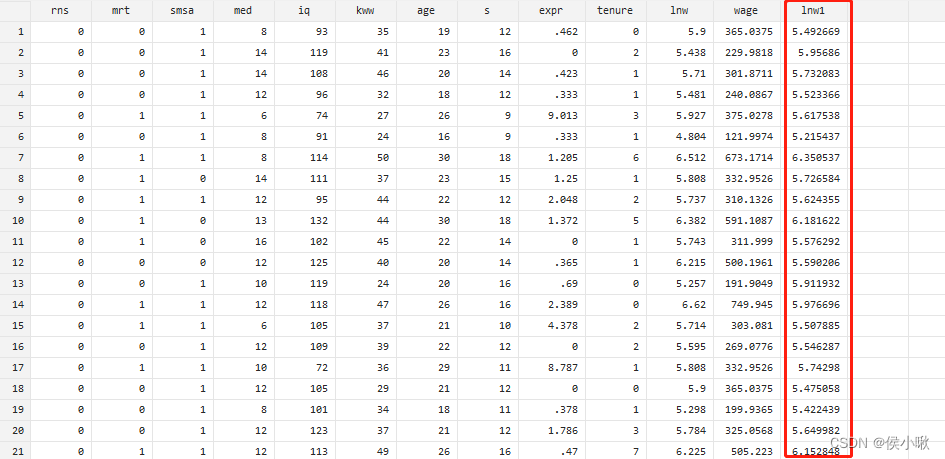
使用predict求被解释变量的拟合值,并生成一列新的变量lnw1
use grilic,clear
quietly reg lnw s expr tenure smsa rns
predict lnw1
其中在命令前加quietly命令,可以使命令悄无声息地执行,而不汇报结果。
使用predict前需要先做回归。
生成的新变量lnw1如图所示,即为被解释变量的拟合值。
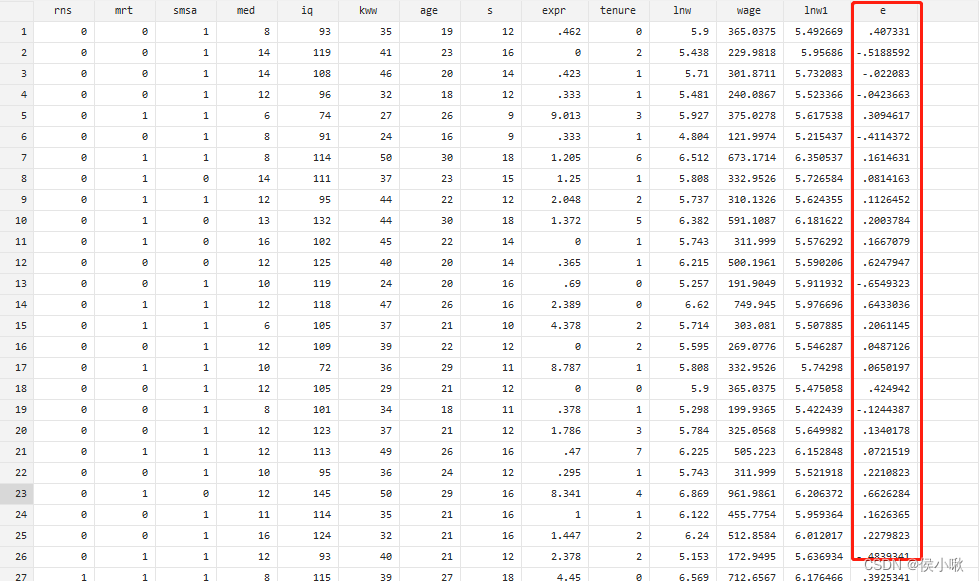
使用predict求计算残差,并生成一列新的变量e
use grilic,clear
quietly reg lnw s expr tenure smsa rns
predict e,residual
- 系数的检验 test
使用test命令可以实现对回归系数的检验
还使用grillic数据,
检验教育投资回报率是否为0.1
原假设H 0 H_0 H 0 即为:β 2 = 0.1 \displaystyle \beta_2=0.1 β2 =0 .1:
use grilic,clear
quietly reg lnw s expr tenure smsa rns
test s=0.1
命令执行效果如下:

这里汇报看F统计量的值和P值。
由P值等于0.6515过大,故这里无法拒绝原假设。
- 多元线性回归的古典假定
y i = β 1 + β 2 x i 2 + . . . + β k x i k + ϵ i \displaystyle y_i =\beta1+\beta2 x_{i2}+…+\beta k x_{ik} +\epsilon_i y i =β1 +β2 x i 2 +…+βk x i k +ϵi ( i = 1 , . . . , n ) (i=1,…,n)(i =1 ,…,n )
①零均值假定
即 严格外生性(strict exogeneity),随机扰动项的条件期望为0。
此假定要求E ( ϵ i ∣ X ) = E ( ϵ i ∣ x 1 , . . . , x n ) = 0 \displaystyle E(\epsilon_i|X)=E(\epsilon_i|x1,…,x_n)=0 E (ϵi ∣X )=E (ϵi ∣x 1 ,…,x n )=0 ( i = 1 , . . . , n ) (i=1,…,n)(i =1 ,…,n )
严格外生性意味着,给定数据矩阵X X X,扰动项ϵ i \epsilon_i ϵi 的条件期望为0。
②球形扰动项
即随机扰动项满足同方差、无自相关。
C o v ( u i , u k ) = \displaystyle Cov(u_i,u_k)=C o v (u i ,u k )=
E [ ( u i − E u i ) ( u k − E u k ) ] \displaystyle E[(u_i-Eu_i)(u_k-Eu_k)]E [(u i −E u i )(u k −E u k )]
= E ( u i u k ) = { σ 2 , i = k 0 , i ≠ k ( i , k = 1 , 2 , . . . n ) \displaystyle =E(u_iu_k)=\left{ \begin{aligned} \sigma^2 ,i = k \ 0 ,i ≠k \ \end{aligned} \right.(i,k=1,2,…n)=E (u i u k )={σ2 ,i =k 0 ,i =k (i ,k =1 ,2 ,…n )
随机扰动项的方差-协方差矩阵为
VAR(U)= [ σ 2 0 . . . 0 0 σ 2 . . . 0 . . . . . . . . . 0 0 . . . σ 2 ] = σ 2 I n \displaystyle =\left[ \begin{matrix} \sigma^2 & 0 & … & 0 \ 0 & \sigma^2 & … & 0 \ … & … & & … \ 0 & 0 & … & \sigma^2 \ \end{matrix} \right]=\sigma^2I_n =⎣⎢⎢⎡σ2 0 …0 0 σ2 …0 ………0 0 …σ2 ⎦⎥⎥⎤=σ2 I n
③随机扰动项与解释变量不相关假定
C o v ( X j i , u i ) = 0 Cov(X_{ji},u_i)=0 C o v (X j i ,u i )=0 ( j = 2 , 3 , . . . , k ; i = 1 , 2 , . . . , n ) (j=2,3,…,k;i=1,2,…,n)(j =2 ,3 ,…,k ;i =1 ,2 ,…,n )
④无多重共线性假定
不存在”严格多重共线性”
即数据矩阵X X X满列秩。
即数据矩阵各列向量线性无关,不存在哪个解释变量是另一个解释变量的倍数,或者说可以被其他解释变量线性表示的情况。
⑤正态性假定
随机扰动项u i u_i u i 服从正态分布
u i u_i u i ~N ( 0 , σ 2 ) N(0,σ^2)N (0 ,σ2 )
- 练习
数据集 airq. dta包含1972年美国加州30个大城市的如下变量:airq(空气质量指数,越低越好) , vala(公司的增加值,千美元) , rain(降雨量,英寸) , coast(是否为海岸城市) , den-sity(人口密度,每平方英里) , income(人均收入,美元)。
(1)把airq对其他变量进行OLS回归。
(2)检验原假设”平均收入对空气质量没有影响”。
(3)检验经济变量density 与 income的联合显著性。
(4)检验环境变量rain 与coast的联合显著性。
(5)检验所有解释变量的联合显著性。
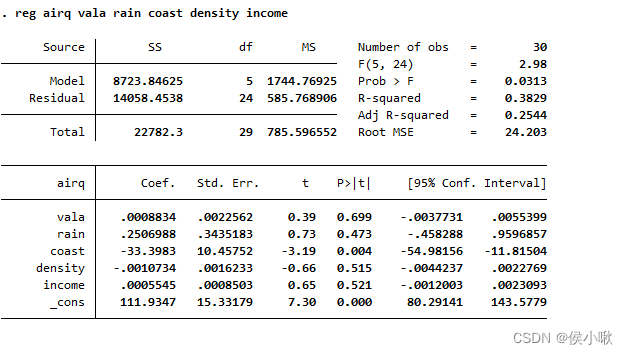
use airq,clear
(1)
reg airq vala rain coast density income
(2)
test income=0

(3)
test density income

(4)
test rain coast

(5)
test vala rain coast density income

本次分享就到这里,小啾感谢您的关注与支持!
🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ
Original: https://blog.csdn.net/weixin_48964486/article/details/124509952
Author: 侯小啾
Title: stata回归分析与系数检验专题【计量经济系列(三)】
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/692867/
转载文章受原作者版权保护。转载请注明原作者出处!