

文章目录
- 本文内容
- 将Transformer看成黑盒
- Transformer的推理过程
- Transformer的训练过程
- Pytorch中的nn.Transformer
* - nn.Transformer简介
- nn.Transformer的构造参数详解
- Transformer的forward参数详解
– - nn.Transformer的使用
- 实战:使用nn.Transformer实现一个简单的Copy任务
- 参考资料:
本文内容
Transformer是个相对复杂的模型,可能有些人和我一样,学了也不会用,或者感觉自己懂了,但又不懂。本文将Transformer看做一个黑盒,然后讲解Pytorch中nn.Transformer的使用。
本文包含内容如下:
- Transformer的训练过程讲解
- Transformer的推理过程讲解
- Transformer的入参和出参讲解
- nn.Transformer的各个参数讲解
- nn.Transformer的mask机制详解
- 实战:使用nn.Transformer训练一个copy任务。
你可以在该项目找到本文的源码
开始之前,我们先导入要用到的包:
import math
import random
import torch
import torch.nn as nn
将Transformer看成黑盒
这是一张经典的Transformer模型图:


我们现在将其变成黑盒,将其盖住:

我们现在再来看下Transformer的输入和输出:

这里是一个翻译任务中transformer的输入和输出。transformer的输入包含两部分:
- inputs: 原句子对应的tokens,且是完整句子。一般0表示句子开始(
<bos></bos>),1表示句子结束(<eos></eos>),2为填充(<pad></pad>)。填充的目的是为了让不同长度的句子变为同一个长度,这样才可以组成一个batch。在代码中,该变量一般取名 src。 - outputs(shifted right):上一个阶段的输出。虽然名字叫outputs,但是它是输入。最开始为0(
<bos></bos>),然后本次预测出”我”后,下次调用Transformer的该输入就变成<bos> 我</bos>。在代码中,该变量一般取名 tgt。
Transformer的输出是一个概率分布。
; Transformer的推理过程
这里先讲Transformer的推理过程,因为这个简单。其实通过上面的讲解,你可能已经清楚了。上面是Transformer推理的第一步,紧接着第二步如图:

Transformer的推理过程就是这样一遍一遍调用Transformer,直到输出 <eos></eos>或达到句子最大长度为止。
通常真正在实战时,Transformer的Encoder部分只需要执行一遍就行了,这里为了简单起见,就整体重新执行。
Transformer的训练过程
在Transformer推理时,我们是一个词一个词的输出,但在训练时这样做效率太低了,所以我们会将target一次性给到Transformer(当然,你也可以按照推理过程做),如图所示:

从图上可以看出,Transformer的训练过程和推理过程主要有以下几点异同:
- 源输入src相同:对于Transformer的inputs部分(src参数)一样,都是要被翻译的句子。
- 目标输入tgt不同:在Transformer推理时,tgt是从
<bos></bos>开始,然后每次加入上一次的输出(第二次输入为<bos> 我</bos>)。但在训练时是一次将”完整”的结果给到Transformer,这样其实和一个一个给结果上一致(可参考该篇的Mask Attention部分)。这里还有一个细节,就是tgt比src少了一位,src是7个token,而tgt是6个token。这是因为我们在最后一次推理时,只会传入前n-1个token。举个例子:假设我们要预测<bos> 我 爱 你 <eos></eos></bos>(这里忽略pad),我们最后一次的输入tgt是<bos> 我 爱 你</bos>(没有<eos></eos>),因此我们的输入tgt一定不会出现目标的最后一个token,所以一般tgt处理时会将目标句子删掉最后一个token。 - 输出数量变多:在训练时,transformer会一次输出多个概率分布。例如上图,
我就的等价于是tgt为<bos></bos>时的输出,爱就等价于tgt为<bos> 我</bos>时的输出,依次类推。当然在训练时,得到输出概率分布后就可以计算loss了,并不需要将概率分布再转成对应的文字。注意这里也有个细节,我们的输出数量是6,对应到token就是我 爱 你 <eos> <pad> <pad></pad></pad></eos>,这里少的是<bos></bos>,因为<bos></bos>不需要预测。计算loss时,我们也是要和的这几个token进行计算,所以我们的label不包含<bos></bos>。代码中通常命名为tgt_y
当得到transformer的输出后,我们就可以计算loss了,计算过程如图:

; Pytorch中的nn.Transformer
nn.Transformer简介
在Pytorch中已经为我们实现了Transformer,我们可以直接拿来用,但nn.Transformer和我们上图的还是有点区别,具体如图:

Transformer并没有实现 Embedding和 Positional Encoding和最后的 Linear+Softmax部分,这里我简单对这几部分进行说明:
- Embedding: 负责将token映射成高维向量。例如将123映射成
[0.34, 0.45, 0.123, ..., 0.33]。通常使用nn.Embedding来实现。但nn.Embedding的参数并不是一成不变的,也是会参与梯度下降。关于nn.Embedding可参考文章Pytorch nn.Embedding的基本使用 - Positional Encoding:位置编码。用于为token编码增加位置信息,例如
I love you这三个token编码后的向量并不包含其位置信息(love左边是I,右边是you这个信息)。这个位置信息还挺重要的,有和没有真的是天差地别。 - Linear+Softmax:一个线性层加一个Softmax,用于对nn.Transformer输出的结果进行token预测。如果把Transformer比作CNN,那么nn.Transformer实现的就是卷积层,而
Linear+Softmax就是卷积层后面的线性层。
这里我先简单的演示一下 nn.Transformer的使用:
embedding = nn.Embedding(10, 128)
transformer = nn.Transformer(d_model=128, batch_first=True)
src = torch.LongTensor([[0, 3, 4, 5, 6, 7, 8, 1, 2, 2]])
tgt = torch.LongTensor([[0, 3, 4, 5, 6, 7, 8, 1, 2]])
outputs = transformer(embedding(src), embedding(tgt))
outputs.size()
torch.Size([1, 9, 128])
Transformer输出的Shape和tgt编码后的Shape一致。在训练时,我们会把transformer的所有输出送给Linear,而在推理时,只需要将最后一个输出送给Linear即可,即
outputs[:, -1]。
nn.Transformer的构造参数详解
Transformer构造参数众多,所以我们还需要将黑盒稍微打开一下:
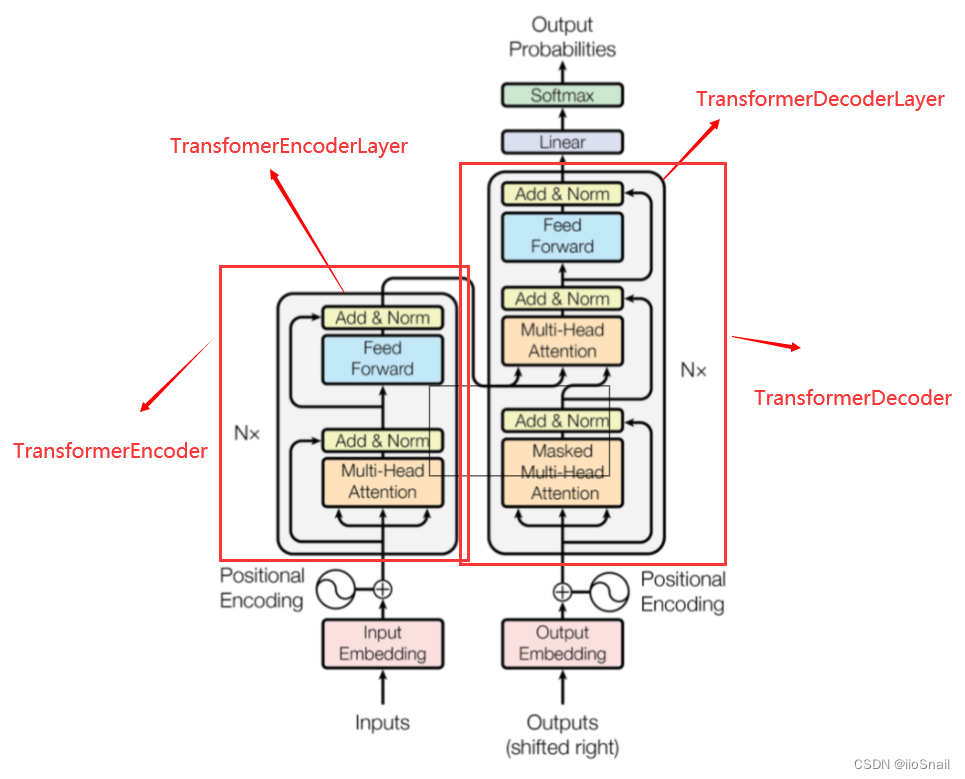
nn.Transformer主要由两部分构成: nn.TransformerEncoder和 nn.TransformerDecoder。而 nn.TransformerEncoder又是由多个 nn.TransformerEncoderLayer堆叠而成的,图中的 Nx就是要堆叠多少层。 nn.TransformerDecoder同理。
下面是nn.Transformer的构造参数:
- d_model: Encoder和Decoder输入参数的特征维度。也就是词向量的维度。默认为512
- nhead: 多头注意力机制中,head的数量。关于Attention机制,可以参考这篇文章。注意该值并不影响网络的深度和参数数量。默认值为8。
- num_encoder_layers: TransformerEncoderLayer的数量。该值越大,网络越深,网络参数量越多,计算量越大。默认值为6
- num_decoder_layers:TransformerDecoderLayer的数量。该值越大,网络越深,网络参数量越多,计算量越大。默认值为6
- dim_feedforward:Feed Forward层(Attention后面的全连接网络)的隐藏层的神经元数量。该值越大,网络参数量越多,计算量越大。默认值为2048
- dropout:dropout值。默认值为0.1
- activation: Feed Forward层的激活函数。取值可以是string(“relu” or “gelu”)或者一个一元可调用的函数。默认值是relu
- custom_encoder:自定义Encoder。若你不想用官方实现的TransformerEncoder,你可以自己实现一个。默认值为None
- custom_decoder: 自定义Decoder。若你不想用官方实现的TransformerDecoder,你可以自己实现一个。
- layer_norm_eps:
Add&Norm层中,BatchNorm的eps参数值。默认为1e-5 - batch_first:batch维度是否是第一个。如果为True,则输入的shape应为(batch_size, 词数,词向量维度),否则应为(词数, batch_size, 词向量维度)。默认为False。 这个要特别注意,因为大部分人的习惯都是将batch_size放在最前面,而这个参数的默认值又是False,所以会报错。
- norm_first – 是否要先执行norm。例如,在图中的执行顺序为
Attention -> Add -> Norm。若该值为True,则执行顺序变为:Norm -> Attention -> Add。
; Transformer的forward参数详解
Transformer的forward参数需要详细解释,这里我先将其列出来,进行粗略解释,然后再逐个进行详细解释:
- src: Encoder的输入。也就是将token进行Embedding并Positional Encoding之后的tensor。 必填参数。 Shape为(batch_size, 词数, 词向量维度)
- tgt: 与src同理,Decoder的输入。 必填参数。 Shape为(词数, 词向量维度)
- src_mask: 对src进行mask。 不常用。 Shape为(词数, 词数)
- tgt_mask:对tgt进行mask。 常用。 Shape为(词数, 词数)
- memory_mask – 对Encoder的输出memory进行mask。 不常用。 Shape为(batch_size, 词数, 词数)
- src_key_padding_mask:对src的token进行mask. 常用。 Shape为(batch_size, 词数)
- tgt_key_padding_mask:对tgt的token进行mask。 常用。 Shape为(batch_size, 词数)
- memory_key_padding_mask:对tgt的token进行mask。 不常用。 *Shape为(batch_size, 词数)
上面的所有mask都是
0代表不遮掩,-inf代表遮掩。另外,src_mask、tgt_mask和memory_mask是不需要传batch的。
补充:上面的说法是pytorch1.11版本。我发现1.11版本key_padding_mask可以用 True/False,但1.12版本key_padding_mask好像只能是 True/False,其中 True表示遮掩,而 False表示不遮掩(这个可不要弄混了,这个和Transformer原论文实现正好相反,如果弄反了,会造成结果为 nan)。
上面说了和没说其实差不多,重要的是每个参数的是否常用和其对应的Shape(这里我默认 batch_first=True)。 接下来对各个参数进行详细解释。
src和tgt
src参数和tgt参数分别为Encoder和Decoder的输入参数。它们是对token进行编码后,再经过Positional Encoding之后的结果。
例如:我们一开始的输入为: [[0, 3, 4, 5, 6, 7, 8, 1, 2, 2]],Shape为(1, 10),表示batch_size为1, 每句10个词。
在经过Embedding后,Shape就变成了(1, 10, 128),表示batch_size为1, 每句10个词,每个词被编码为了128维的向量。
src就是这个(1, 10, 128)的向量。tgt同理
src_mask、tgt_mask和memory_mask
要真正理解mask,需要学习Attention机制,可参考该篇。这里只做一个简要的说明。
在经过Attention层时,会让每个词具有上下文关系,也就是每个词除了自己的信息外,还包含其他词的信息。例如: 苹果 很 好吃和 苹果 手机 很 好玩,这两个 苹果显然指的不是同一个意思。但让 苹果这个词具备了后面 好吃或 手机这两个词的信息后,那就可以区分这两个 苹果的含义了。
在Attention中,我们有这么一个”方阵”,描述着词与词之间的关系,例如:
苹果 很 好吃
苹果 [[0.5, 0.1, 0.4],
很 [0.1, 0.8, 0.1],
好吃 [0.3, 0.1, 0.6],]
在上述矩阵中, 苹果这个词与自身, 很和 好吃三个词的关系权重就是 [0.5, 0.1, 0.4],通过该矩阵,我们就可以得到包含上下文的 苹果了,即
苹果 ′ = 苹果 × 0.5 + 很 × 0.1 + 好吃 × 0.4 \text{苹果}’ = \text{苹果}\times 0.5 + \text{很} \times 0.1 + \text{好吃} \times 0.4 苹果′=苹果×0.5 +很×0.1 +好吃×0.4
但在实际推理时,词是一个一个输出的。若 苹果很好吃是tgt的话,那么 苹果是不应该包含 很和 好吃的上下文信息的,所以我们希望为:
苹果 ′ = 苹果 × 0.5 \text{苹果}’ = \text{苹果}\times 0.5 苹果′=苹果×0.5
同理, 很字可以包含 苹果的上下信息,但不能包含 好吃,所以为:
很 ′ = 苹果 × 0.1 + 很 × 0.8 \text{很}’ = \text{苹果}\times 0.1 + \text{很} \times 0.8 很′=苹果×0.1 +很×0.8
那要完成这个事情,那只需要改变方阵即可:
苹果 很 好吃
苹果 [[0.5, 0, 0],
很 [0.1, 0.8, 0],
好吃 [0.3, 0.1, 0.6],]
而这个事情我们就可以使用mask掩码来完成,即:
苹果 很 好吃
苹果 [[ 0, -inf, -inf],
很 [ 0, 0, -inf],
好吃 [ 0, 0, 0]]
其中0表示不遮掩,而 -inf表示遮掩。(之所以这么定是因为这个方阵还要过softmax,所以会使 -inf变为0)。
所以,对于tgt_mask,我们只需要生成一个斜着覆盖的方阵即可,我们可以利用 nn.Transformer.generate_square_subsequent_mask来完成,例如:
nn.Transformer.generate_square_subsequent_mask(5)
tensor([[0., -inf, -inf, -inf, -inf],
[0., 0., -inf, -inf, -inf],
[0., 0., 0., -inf, -inf],
[0., 0., 0., 0., -inf],
[0., 0., 0., 0., 0.]])
通过上面的分析,src和memory一般是不需要进行mask的,所以不常用。
key_padding_mask
在我们的src和tgt语句中,除了本身的词外,还包含了三种token: <bos></bos>, <eos></eos> 和 <pad></pad>。这里面的 <pad></pad>只是为了改变句子长度,方便将不同长度的句子组成batch而进行填充的。该token没有任何意义,所以在计算Attention时,也不想让它们参与,所以也要mask。而对于这种mask就需要用到key_padding_mask这个参数了。
例如,我们的src为 [[0, 3, 4, 5, 6, 7, 8, 1, 2, 2]],其中2是 <pad></pad>,所以我们的 src_key_padding_mask就应为 [[0, 0, 0, 0, 0, 0, 0, 0, -inf, -inf]],即将最后两个2给掩盖住。
tgt_key_padding_mask同理。但 memory_key_padding_mask就没有必要用了。
在Transformer的源码中或其他实现中,tgt_mask和tgt_key_padding_mask是合在一起的,例如:
[[0., -inf, -inf, -inf], # tgt_mask
[0., 0., -inf, -inf],
[0., 0., 0., -inf],
[0., 0., 0., 0.]]
+
[[0., 0., 0., -inf]] # tgt_key_padding_mask
=
[[0., -inf, -inf, -inf], # 合并之后的
[0., 0., -inf, -inf],
[0., 0., 0., -inf],
[0., 0., 0., -inf]]
nn.Transformer的使用
接下来我们来简单的使用一下 nn.Transformer:
首先我们定义src和tgt:
src = torch.LongTensor([
[0, 8, 3, 5, 5, 9, 6, 1, 2, 2, 2],
[0, 6, 6, 8, 9, 1 ,2, 2, 2, 2, 2],
])
tgt = torch.LongTensor([
[0, 8, 3, 5, 5, 9, 6, 1, 2, 2],
[0, 6, 6, 8, 9, 1 ,2, 2, 2, 2],
])
接下来定义一个辅助函数来生成src_key_padding_mask和tgt_key_padding_mask:
def get_key_padding_mask(tokens):
key_padding_mask = torch.zeros(tokens.size())
key_padding_mask[tokens == 2] = -torch.inf
return key_padding_mask
src_key_padding_mask = get_key_padding_mask(src)
tgt_key_padding_mask = get_key_padding_mask(tgt)
print(tgt_key_padding_mask)
tensor([[0., 0., 0., 0., 0., 0., 0., 0., -inf, -inf],
[0., 0., 0., 0., 0., 0., -inf, -inf, -inf, -inf]])
然后通过Transformer内容方法生成 tgt_mask:
tgt_mask = nn.Transformer.generate_square_subsequent_mask(tgt.size(-1))
print(tgt_mask)
tensor([[0., -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf],
[0., 0., -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf],
[0., 0., 0., -inf, -inf, -inf, -inf, -inf, -inf, -inf],
[0., 0., 0., 0., -inf, -inf, -inf, -inf, -inf, -inf],
[0., 0., 0., 0., 0., -inf, -inf, -inf, -inf, -inf],
[0., 0., 0., 0., 0., 0., -inf, -inf, -inf, -inf],
[0., 0., 0., 0., 0., 0., 0., -inf, -inf, -inf],
[0., 0., 0., 0., 0., 0., 0., 0., -inf, -inf],
[0., 0., 0., 0., 0., 0., 0., 0., 0., -inf],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]])
之后就可以定义Embedding和Transformer进行调用了:
embedding = nn.Embedding(10, 128)
transformer = nn.Transformer(d_model=128, batch_first=True)
outputs = transformer(embedding(src), embedding(tgt),
tgt_mask=tgt_mask,
src_key_padding_mask=src_key_padding_mask,
tgt_key_padding_mask=tgt_key_padding_mask)
print(outputs.size())
torch.Size([2, 10, 128])
实战:使用nn.Transformer实现一个简单的Copy任务
任务描述:让Transformer预测输入。例如,输入为 [0, 3, 4, 6, 7, 1, 2, 2],则期望的输出为 [0, 3, 4, 6, 7, 1]。
首先,我们定义一下句子的最大长度:
max_length=16
定义PositionEncoding类,不需要知道具体什么意思,直接拿过来用即可。
class PositionalEncoding(nn.Module):
"Implement the PE function."
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1)
div_term = torch.exp(
torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model)
)
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer("pe", pe)
def forward(self, x):
"""
x 为embedding后的inputs,例如(1,7, 128),batch size为1,7个单词,单词维度为128
"""
x = x + self.pe[:, : x.size(1)].requires_grad_(False)
return self.dropout(x)
定义我们的Copy模型:
class CopyTaskModel(nn.Module):
def __init__(self, d_model=128):
super(CopyTaskModel, self).__init__()
self.embedding = nn.Embedding(num_embeddings=10, embedding_dim=128)
self.transformer = nn.Transformer(d_model=128, num_encoder_layers=2, num_decoder_layers=2, dim_feedforward=512, batch_first=True)
self.positional_encoding = PositionalEncoding(d_model, dropout=0)
self.predictor = nn.Linear(128, 10)
def forward(self, src, tgt):
tgt_mask = nn.Transformer.generate_square_subsequent_mask(tgt.size()[-1])
src_key_padding_mask = CopyTaskModel.get_key_padding_mask(src)
tgt_key_padding_mask = CopyTaskModel.get_key_padding_mask(tgt)
src = self.embedding(src)
tgt = self.embedding(tgt)
src = self.positional_encoding(src)
tgt = self.positional_encoding(tgt)
out = self.transformer(src, tgt,
tgt_mask=tgt_mask,
src_key_padding_mask=src_key_padding_mask,
tgt_key_padding_mask=tgt_key_padding_mask)
"""
这里直接返回transformer的结果。因为训练和推理时的行为不一样,
所以在该模型外再进行线性层的预测。
"""
return out
@staticmethod
def get_key_padding_mask(tokens):
"""
用于key_padding_mask
"""
key_padding_mask = torch.zeros(tokens.size())
key_padding_mask[tokens == 2] = -torch.inf
return key_padding_mask
model = CopyTaskModel()
这里简单的尝试下我们定义的模型:
src = torch.LongTensor([[0, 3, 4, 5, 6, 1, 2, 2]])
tgt = torch.LongTensor([[3, 4, 5, 6, 1, 2, 2]])
out = model(src, tgt)
print(out.size())
print(out)
torch.Size([1, 7, 128])
tensor([[[ 2.1870e-01, 1.3451e-01, 7.4523e-01, -1.1865e+00, -9.1054e-01,
6.0285e-01, 8.3666e-02, 5.3425e-01, 2.2247e-01, -3.6559e-01,
....
-9.1266e-01, 1.7342e-01, -5.7250e-02, 7.1583e-02, 7.0782e-01,
-3.5137e-01, 5.1000e-01, -4.7047e-01]]],
grad_fn=<nativelayernormbackward0>)
</nativelayernormbackward0>
没什么问题,那就接着定义损失函数和优化器,因为是多分类问题,所以用CrossEntropyLoss:
criteria = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=3e-4)
接着再定义一个生成随时数据的工具函数:
def generate_random_batch(batch_size, max_length=16):
src = []
for i in range(batch_size):
random_len = random.randint(1, max_length - 2)
random_nums = [0] + [random.randint(3, 9) for _ in range(random_len)] + [1]
random_nums = random_nums + [2] * (max_length - random_len - 2)
src.append(random_nums)
src = torch.LongTensor(src)
tgt = src[:, :-1]
tgt_y = src[:, 1:]
n_tokens = (tgt_y != 2).sum()
return src, tgt, tgt_y, n_tokens
generate_random_batch(batch_size=2, max_length=6)
(tensor([[0, 7, 6, 8, 7, 1],
[0, 9, 4, 1, 2, 2]]),
tensor([[0, 7, 6, 8, 7],
[0, 9, 4, 1, 2]]),
tensor([[7, 6, 8, 7, 1],
[9, 4, 1, 2, 2]]),
tensor(8))
开始进行训练:
total_loss = 0
for step in range(2000):
src, tgt, tgt_y, n_tokens = generate_random_batch(batch_size=2, max_length=max_length)
optimizer.zero_grad()
out = model(src, tgt)
out = model.predictor(out)
"""
计算损失。由于训练时我们的是对所有的输出都进行预测,所以需要对out进行reshape一下。
我们的out的Shape为(batch_size, 词数, 词典大小),view之后变为:
(batch_size*词数, 词典大小)。
而在这些预测结果中,我们只需要对非部分进行,所以需要进行正则化。也就是
除以n_tokens。
"""
loss = criteria(out.contiguous().view(-1, out.size(-1)), tgt_y.contiguous().view(-1)) / n_tokens
loss.backward()
optimizer.step()
total_loss += loss
if step != 0 and step % 40 == 0:
print("Step {}, total_loss: {}".format(step, total_loss))
total_loss = 0
Step 40, total_loss: 3.570814609527588
Step 80, total_loss: 2.4842987060546875
...略
Step 1920, total_loss: 0.4518987536430359
Step 1960, total_loss: 0.37290623784065247
在完成模型训练后,我们来使用一下我们的模型:
model = model.eval()
src = torch.LongTensor([[0, 4, 3, 4, 6, 8, 9, 9, 8, 1, 2, 2]])
tgt = torch.LongTensor([[0]])
for i in range(max_length):
out = model(src, tgt)
predict = model.predictor(out[:, -1])
y = torch.argmax(predict, dim=1)
tgt = torch.concat([tgt, y.unsqueeze(0)], dim=1)
if y == 1:
break
print(tgt)
tensor([[0, 4, 3, 4, 6, 8, 9, 9, 8, 1]])
可以看到,我们的模型成功预测了src的输入。
参考资料:
nn.Transformer官方文档: https://pytorch.org/docs/stable/generated/torch.nn.Transformer.html
层层剖析,让你彻底搞懂Self-Attention、MultiHead-Attention和Masked-Attention的机制和原理: https://blog.csdn.net/zhaohongfei_358/article/details/122861751
Original: https://blog.csdn.net/zhaohongfei_358/article/details/126019181
Author: iioSnail
Title: Pytorch中nn.Transformer的使用详解与Transformer的黑盒讲解
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/711910/
转载文章受原作者版权保护。转载请注明原作者出处!