

前言
训练模型时,一般我们会把模型model,数据data和标签label放到GPU显存中进行加速。
但有的时候GPU Memory会增加,有的时候会保持不变,以及我们要怎么清理掉一些用完的变量呢?
下面让我们一起来探究下原理吧!
一、pytorch训练模型
只要你把任何东西(无论是多小的tensor)放到GPU显存中,那么你至少会栈1000MiB左右的显存(根据cuda版本,会略有不同)。这部分显存是cuda running时固有配件必须要占掉的显存,你先训练过程汇总也是无法释放的。
import torch
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
x = torch.randn((2, 3), device=device)


现在我再放入一个比较大的tensor,GPU显存升到了1919MiB
y = torch.randn((200, 300, 200, 20), device=device)

也就是说当你有个新的东西加进去时,GPU显存会不断扩大。
二、batch训练模型时,GPU显存的容量会保持不变?
但是为什么我们像下面这样拿出一个个batch训练模型时,GPU显存的容量会保持不变的呢?
batch_loss = []
for epoch in range(self.epoch):
pbar = enumerate(tqdm(self.train_dataloader, desc="Training Bar"), 0)
for i, (inputs, labels) in pbar:
inputs = inputs.to(self.device)
labels = labels.to(self.device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
batch_loss.append(loss)
loss.backward()
optimizer.step()
这实际上跟cuda的内存管理有关,但你的一块内存不再由引用它的变量时,他就不再是Active memory。他会残留在一个队列中,如果下一次有新的东西进来,那就会把他挤出队列(FIFO),当然如果新进来的东西和你那部分空间的大小差不多,那么出去一块空间,又进来一块空间,那么看上去你的GPU显存就不会有增加,看上去是一直不变。这就解释了一个个batch训练模型时GPU显存不变的原因。
当然如果新加进来的东西很多,就是那些unactivate的memory全部被挤出还是放不下新的东西,那GPU的显存就会增加了。(有点类似C++中的capacity增加的情况)
实际运行中,我们会发现这个队列capacity会有个阈值(这个阈值好像不是固定的),当你还没到达这个阈值时不会触发垃圾回收机制(即清理unactivate memeory的空间)
也就是说我不断运行下面代码
y = torch.randn((200, 300, 200, 20), device=device)

这时再加入y,容量不再增加,会把原来unactivate的memory挤掉。
三、如何释放GPU显存空间
那么我们要怎么样释放掉空间呢
我们上面很多空间原来是被y指向的,后来y指向新的地方,那这些空间都是残留的,我们可以用下面命令继续释放(如果你想释放的话)
torch.cuda.empty_cache()
上述命令可能要运行多次才会释放空间,我运行了大概5次吧

残留内存成功被释放

现在这里面GPU显存 = 基础配置(1001MiB) + y(918MiB) + x(忽略不计)
最后我们再来把y这部分释放掉
令 y = 2,那么原来y所指的那部分显存空间就会变成unactivate,我们可以使用 torch.cuda.empty_cache()把这部分空间释放掉
最终只剩下基础配置的GPU显存占用(这部分已经无法释放了)

四、torch.cuda.memory_summary()查看显存信息
使用 print(torch.cuda.memory_summary())可以看到更多关于cuda显存的信息
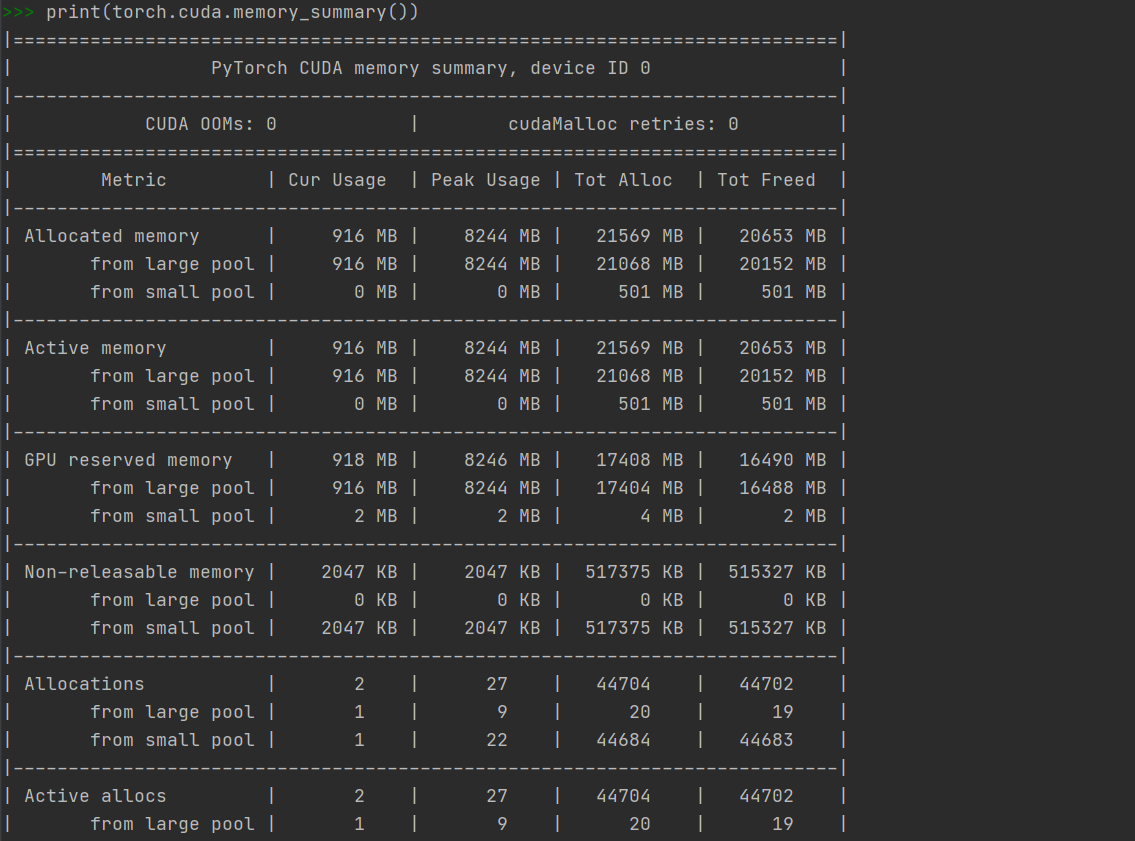
; 五、写在最后
经过上面的摸索,我感觉这部分内容跟操作系统的内存管理有点像,所以说计算机的那几门基础课真的很重要,大家都要好好学一学!
当然实际中cuda的显存管理肯定没有那么简单,有兴趣的同学可以继续探究下。
✨原创不易,还希望各位大佬支持一下 \textcolor{blue}{原创不易,还希望各位大佬支持一下}原创不易,还希望各位大佬支持一下
👍 点赞,你的认可是我创作的动力! \textcolor{green}{点赞,你的认可是我创作的动力!}点赞,你的认可是我创作的动力!
⭐️ 收藏,你的青睐是我努力的方向! \textcolor{green}{收藏,你的青睐是我努力的方向!}收藏,你的青睐是我努力的方向!
✏️ 评论,你的意见是我进步的财富! \textcolor{green}{评论,你的意见是我进步的财富!}评论,你的意见是我进步的财富!
Original: https://blog.csdn.net/qq_43827595/article/details/115722953
Author: 白马金羁侠少年
Title: Pytorch训练模型时如何释放GPU显存 torch.cuda.empty_cache()内存释放以及cuda的显存机制探索
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/709897/
转载文章受原作者版权保护。转载请注明原作者出处!