

目录
Convolutional With Anchor Boxes
资料
论文地址:https://arxiv.org/abs/1612.08242
pytorch代码:GitHub – longcw/yolo2-pytorch: YOLOv2 in PyTorch
网络模型原理
网络框架
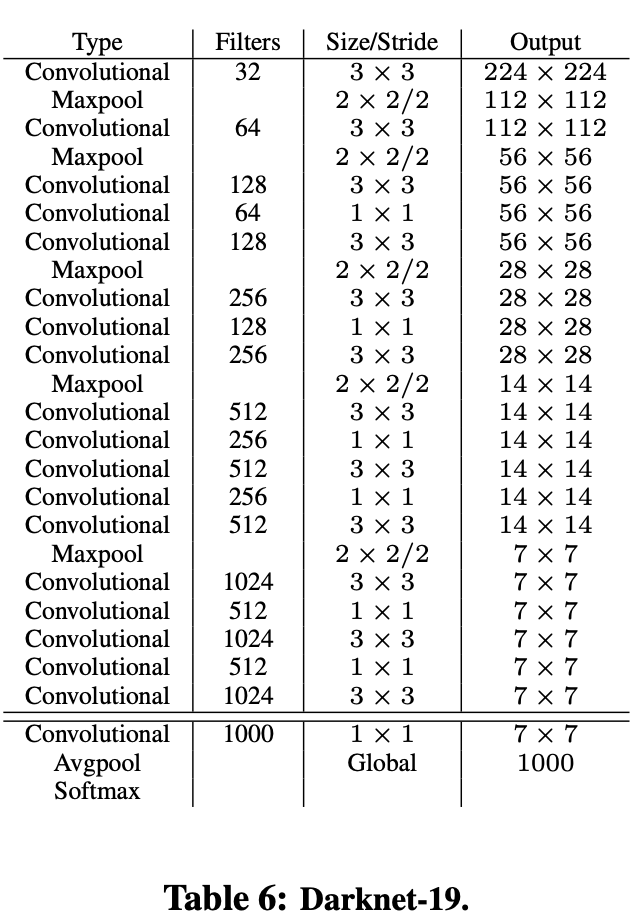

上图是仅分类的模型,模型通过1×1的卷积进行通道降维,3×3的卷积进行特征提取,采用Maxpool进行下采样,特征图尺寸长宽各减半。Darknet-19最终采用global avgpooling做预测。
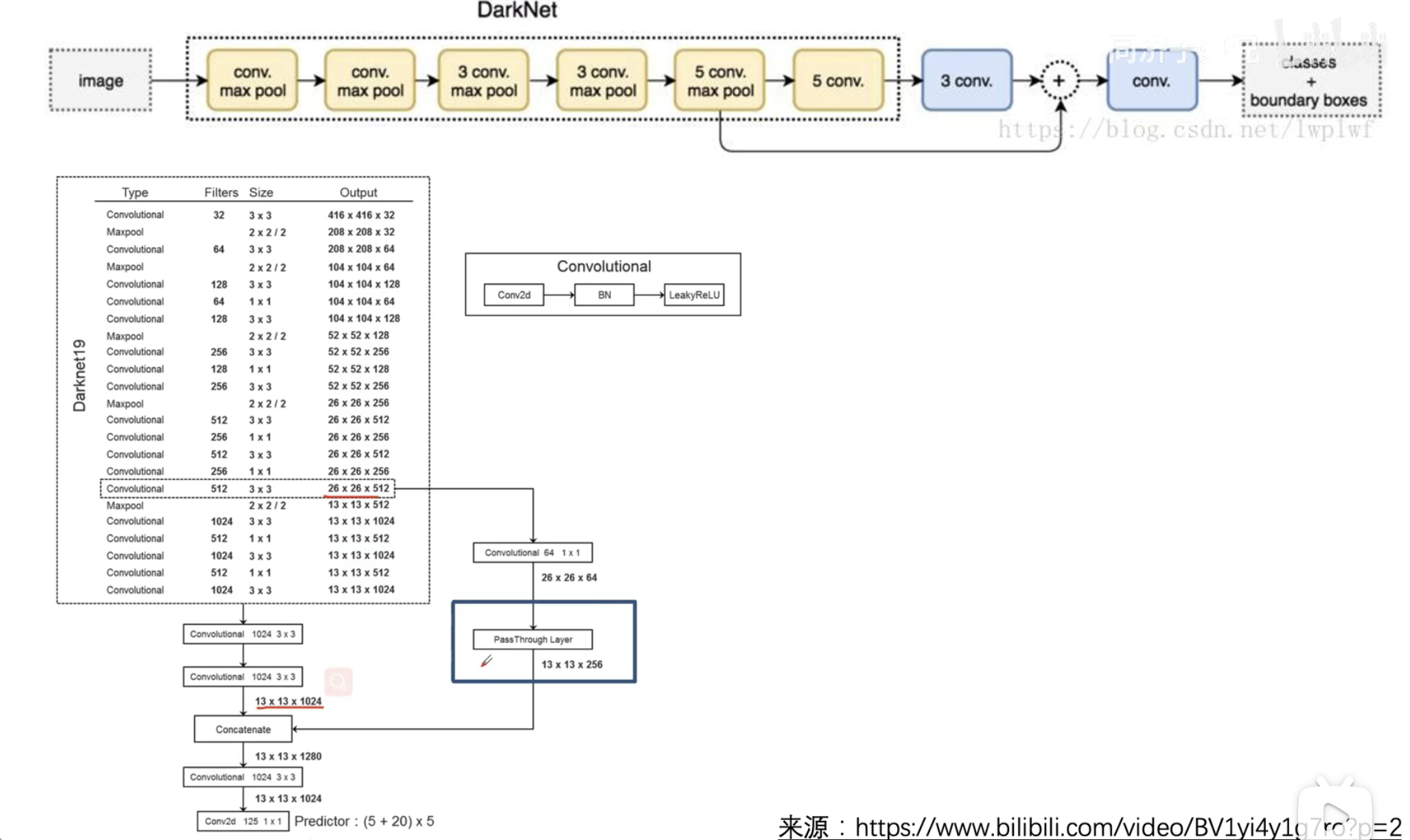
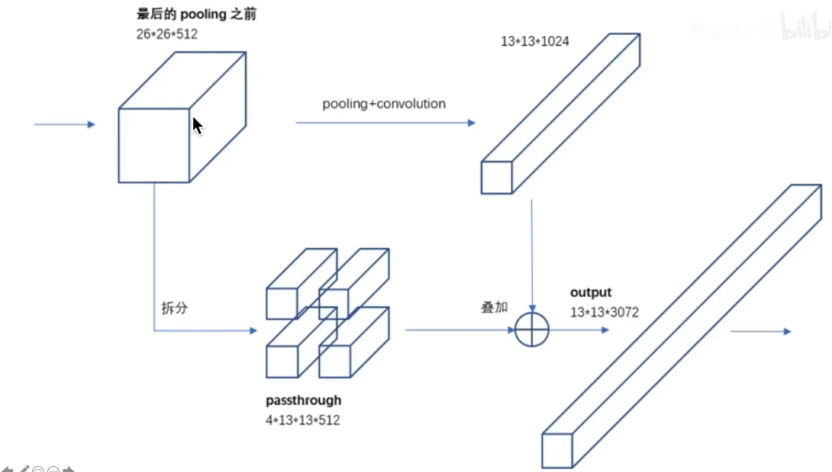
上图是yolov2的网络结构,前18层卷积结构和分类模型的前18层一样,第13个卷积层生成的特征图的尺寸为28x28x512,在这个卷积层接上paththrough结构。passthrough层与ResNet网络的shortcut类似,以前面更高分辨率的特征图为输入,然后将其连接到后面的低分辨率特征图上。前面的特征图维度是后面的特征图的2倍,passthrough层抽取前面层的每个2×2的局部区域,然后将其转化为channel维度,对于26x26x512的特征图,使用1×1的卷积降维到26x26x64(这部分论文中没有提到,但实际的代码是这样写的),经passthrough层处理之后就变成13x13x256的新特征图(特征图大小降低4倍,而channles增加4倍),这样就可以与后面的13x13x1024特征图连接在一起形成13x13x1280大小的特征图,网络最后使用了1×1的卷积将13x13x1280的特征降维到13x13x125,13x13x(5*(5+20))对应了13×13个grid cell,每个grid cell里面有5个anchor信息,每个anchor信息包含中心坐标x、y,框的长宽h、w,置信度c,以及对应的20个分类的概率。
相对于yoloV1的改进
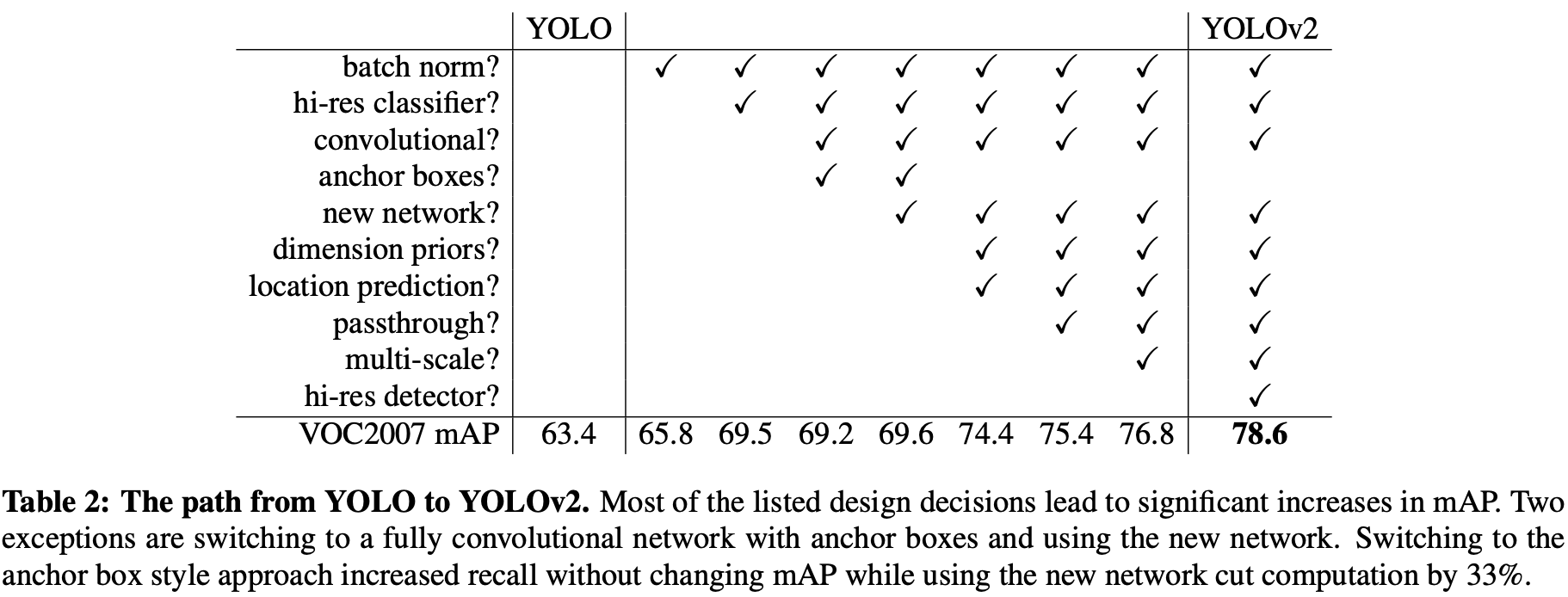
BN:YoloV2相较于YoloV1添加了BN层; Hi-res classifier:预训练模型使用了更大的分辨率的图像从224×224上升到448×448; convolutional+anchor boxes:移除了全连接层采用了卷积和anchor boxes来预测边界框; new network:采用了一个新的特征提取器Darknet19; dimension priors:采用k-means聚类方法对训练集中的边界做了聚类分析; location prediction:使用sigmoid函数处理偏移值,使预测的偏移值在(0,1)的范围内,约束在当前的cell内; passthrough:采用类似resnet中shortcut的连接特征的方式,使得相对低层的特征与高层特征相连,是特征更加丰富; multi-scale:由于yoloV2没有了全连接层,可以进行多尺度训练增加模型的鲁棒性; hi-res detector:采用高分辨率(544×544)的图片作为输入;
Batch Norm

引入BN层mAP从63.4提升到65.8,上图是BatchNorm的伪代码,算法的步骤:
1.求出批数据的均值;
2.求出批数据的方差;
3.对输入数据进行归一化;
4.引入缩放和平移变量得到最终结果。
深度神经网络主要就是为了学习训练数据的分布,并在测试集上达到很好的泛化效果,但是,如果我们每一个batch输入的数据都具有不同的分布,显然会给网络的训练带来困难。另一方面,对于神经网络的各层输出,由于它们经过了层内操作作用,其分布显然与各层对应的输入信号分布不同,而且差异会随着网络深度增大而增大,此现象称为Internal Covariate Shift。为了减小Internal Covariate Shift,可以对神经网络的每一层做归一化,假设将每一层输出后的数据都归一化到0均值,1方差,满足正太分布,但是,此时有一个问题,每一层的数据分布都是标准正太分布,导致其完全学习不到输入数据的特征,因为,费劲心思学习到的特征分布被归一化了,因此,直接对每一层做归一化显然是不合理的。BatchNorm引入了两个参数,缩放变量
和平移变量,先讨论比较差的情况,缩放变量和平移变量分别为标准差和均值,那么的结果就是最初的输入x,当BatchNorm起作用的时候,就保证了每一次数据经过归一化后还保留的有学习来的特征,同时又能完成归一化这个操作,加速训练。
添加BatchNorm的优点:
1.没有它之前,需要小心的调整学习率和权重初始化,但是有了BN可以放心的使用大学习率,但是使用了BN,就不用小心的调参了,较大的学习率极大的提高了学习速度;
2.Batchnorm本身上也是一种正则的方式,可以代替其他正则方式如dropout等;
3.batchnorm降低了数据之间的绝对差异,有一个去相关的性质,更多的考虑相对差异性,因此在分类任务上具有更好的效果。
High Resolution Classifier
ImageNet分类模型基本采用大小为224×224的图片作为输入,分辨率相对低一些,不利于检测模型。所以YOLOv1在采用224×224分类模型预训练后,将分辨率增加至448×448,并使用这个高分辨率在检测数据集上finetune。但是直接切换分辨率,检测模型可能难以快速适应高分辨率。所以YOLOv2增加了在ImageNet数据集上使用448×448输入来finetune分类网络这一中间过程(10 epochs),这可以使得模型在检测数据集上finetune之前已经适用高分辨率输入。使用高分辨率分类器后,YOLOv2的mAP从65.8到69.5。
Convolutional With Anchor Boxes
原来的YOLO是利用全连接层直接预测bounding box的坐标,而YOLOv2借鉴了Faster R-CNN的思想,引入anchor。首先将原网络的全连接层和最后一个pooling层去掉,使得最后的卷积层可以有更高分辨率的特征。在检测模型中,YOLOv2不是采用448×448的图片作为输入,而是采用416×416大小的图片。因为YOLOv2模型下采样的总步长为32 ,对于416×416大小的图片,最终得到的特征图大小为13×13,维度是奇数,这样特征图恰好只有一个中心位置。对于一些大物体,它们中心点往往落入图片中心位置,此时使用特征图的一个中心点去预测这些物体的边界框相对容易些(因为大的object一般会占据图像的中心,所以希望用一个center cell去预测,而不是4个center cell去预测),所以在YOLOv2设计中要保证最终的特征图有奇数个位置。
原来的YOLOV1算法将输入图像分成7×7的网格,每个网格预测两个bounding box,因此一共只有98个box,但是在YOLOv2通过引入anchor boxes,预测的box数量超过了1千(以输出feature map大小为1313为例,每个grid cell有9个anchor box的话,一共就是13139=1521个,当然由后面第4点可知,最终每个grid cell选择5个anchor box)。顺便提一下在Faster RCNN在输入大小为1000600时的boxes数量大概是6000,在SSD300中boxes数量是8732。显然增加box数量是为了提高object的定位准确率。作者的实验证明:虽然加入anchor使得MAP值下降了一点(69.5降到69.2),但是提高了recall(81%提高到88%),降低的是precision。
Dimension Clusters
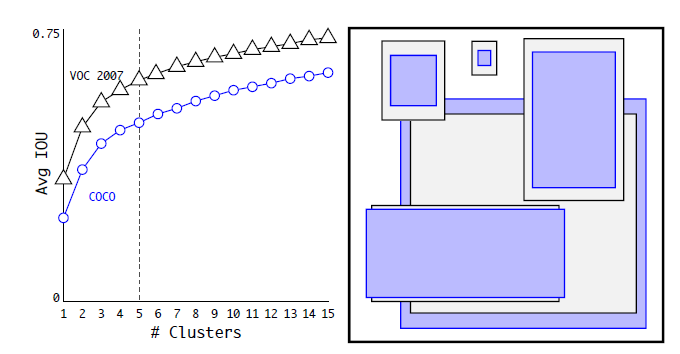
在Faster R-CNN和SSD中,先验框的维度(长和宽)都是手动设定的,带有一定的主观性。如果选取的先验框维度比较合适,那么模型更容易学习,从而做出更好的预测。因此,YOLOv2采用k-means聚类方法对训练集中的边界框做了聚类分析。因为设置先验框的主要目的是为了使得预测框与ground truth的IOU更好,到聚类中心的距离越小越好,但IOU值是越大越好,所以使用 1 – IOU,这样就 保证距离越小,IOU值越大,所以聚类分析时选用box与聚类中心box之间的IOU值作为距离指标:
下图为在VOC和COCO数据集上的聚类分析结果,随着聚类中心数目的增加,平均IOU值(各个边界框与聚类中心的IOU的平均值)是增加的,但是综合考虑模型复杂度和召回率,作者最终选取5个聚类中心作为先验框,其相对于图片的大小如右边图所示。
边界框聚类步骤:

New Network:Darknet-19
模型结构在网络框架部分介绍过,在ImageNet分类数据集上,Darknet-19的top-1准确度为72.9%,top-5准确度为91.2%,但是模型参数相对小一些。使用Darknet-19之后,YOLOv2的mAP值没有显著提升,但是计算量却可以减少约33%。
Direct location prediction
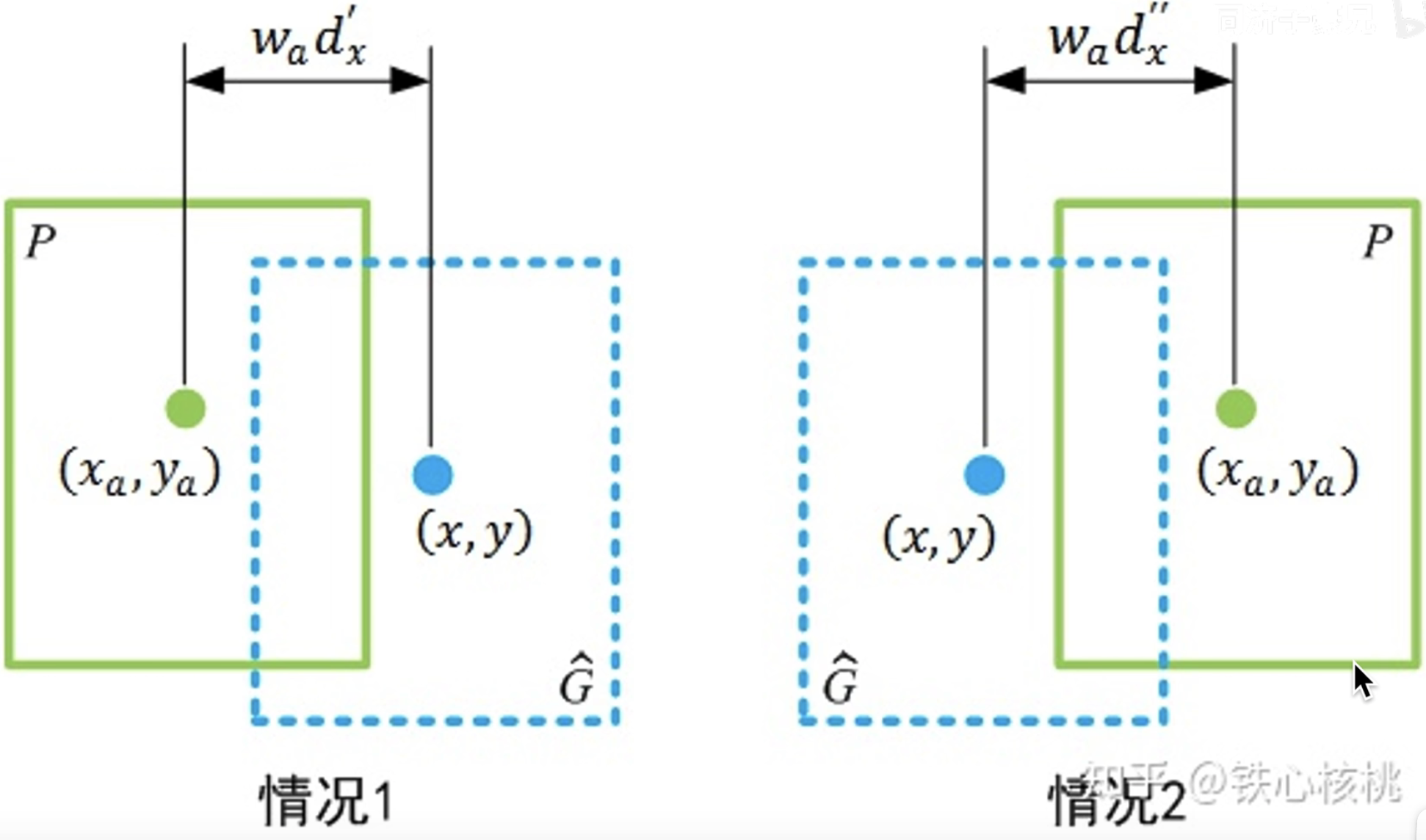
YOLOv2借鉴RPN网络使用anchor boxes来预测边界框相对先验框的offsets。边界框的实际中心位置(x,y),需要根据预测的坐标偏移值(
,),先验框的尺寸(,)以及中心坐标(,) 来计算:
但是上面的公式是无约束的,预测的边界框很容易向任何方向偏移,因此每个位置预测的边界框可以落在图片任何位置,这导致模型的不稳定性,在训练时需要很长时间来预测出正确的offsets。所以,YOLOv2弃用了这种预测方式,而是沿用YOLOv1的方法,就是预测边界框中心点相对于对应cell左上角位置的相对偏移值,为了将边界框中心点约束在当前cell中,使用sigmoid函数处理偏移值,这样预测的偏移值在(0,1)范围内(每个cell的尺度看做1)。总结来看,根据边界框预测的4个offsets
,, ,可以按如下公式计算出边界框实际位置和大小:
其中(
,)为cell的左上角坐标,如下图所示,在计算时每个cell的尺度为1,所以下图中绿色点的坐标点为(1,1)。由于sigmoid函数的处理,边界框的中心位置会约束在当前cell内部,防止偏移过多。由于sigmoid函数的处理,边界框的中心位置会约束在当前cell内部,防止偏移过多。其中和没有过多约束,因为物体的大小是不受限制的,所以框的大小也没有约束。而和是先验框的宽度与长度,前面说过它们的值也是相对于特征图大小的,在特征图中每个cell的长和宽均为1。这里记特征图的大小为(W,H),(在文中是(13,13)),这样我们可以将边界框相对于整张图片的位置和大小计算出来(4个值均在0和1之间):
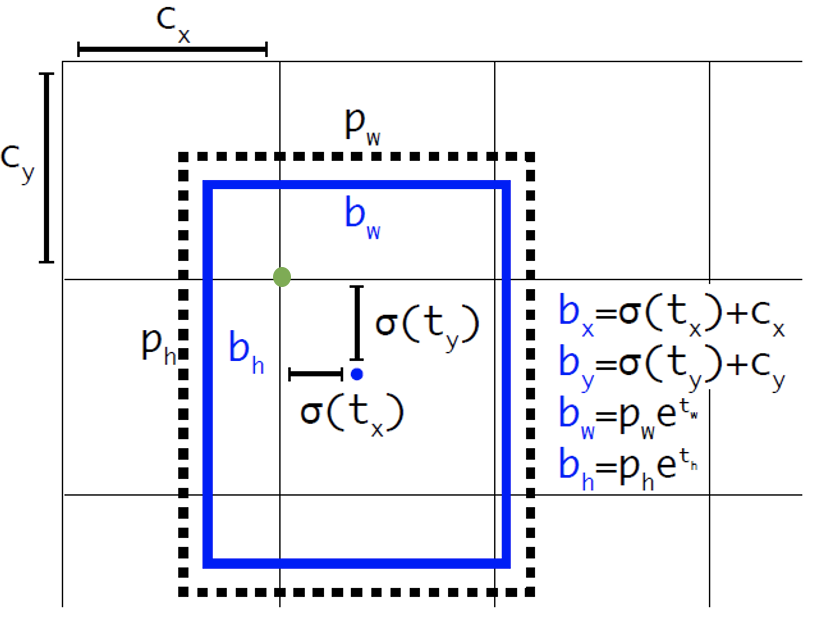
如果再将上面的4个值分别乘以图片的宽度和长度(像素点值)就可以得到边界框的最终位置和大小了。这就是YOLOv2边界框的整个解码过程。约束了边界框的位置预测值使得模型更容易稳定训练,结合聚类分析得到先验框与这种预测方法,YOLOv2的mAP值从69.6提升到74.4 。
PassThrough
在前面的网络框架部分写了一部分passthrough的内容,下图是passthrough的整理操作流程。
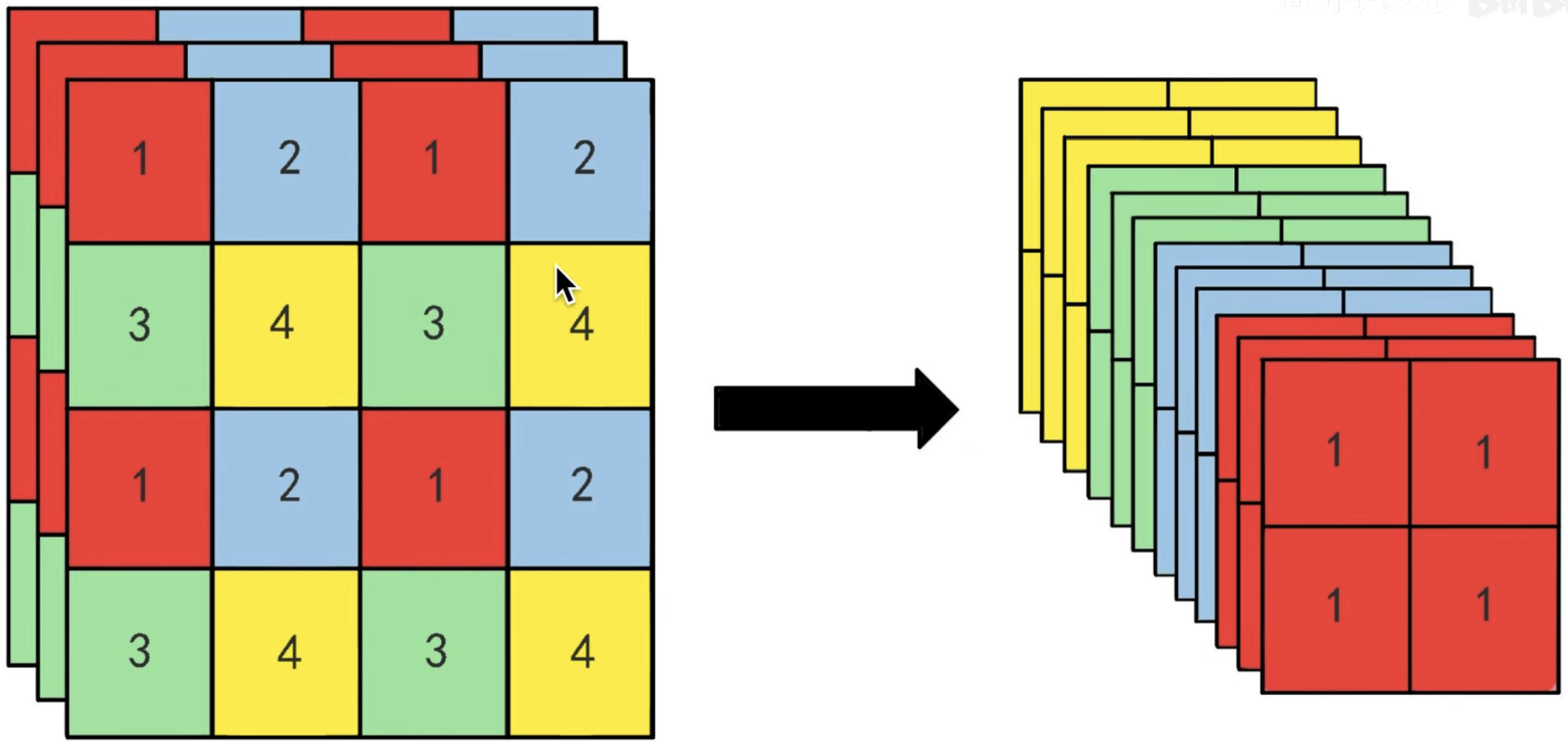
这里再写一下如何将26×26的特征图变换到13×13的。举个例子,如下图所示,原特征图是4x4x3的一个3维矩阵,采用交叉取数的方法,将相同的数单独形成一个2×2的三维矩阵,最终会有4个这样的矩阵,也就是前面所说的特征图长宽减半,深度增加4倍。这样就和更深的特征图保持相同的尺寸,可以进行融合,增加特征的丰富性。
Multi-Scale Training
由于YOLOv2模型中只有卷积层和池化层,所以YOLOv2的输入可以不限于416×416大小的图片。为了增强模型的鲁棒性,YOLOv2采用了多尺度输入训练策略,具体来说就是在训练过程中每间隔一定的iterations之后改变模型的输入图片大小。由于YOLOv2的下采样总步长为32,输入图片大小选择一系列为32倍数的值:{320, 352, …,608},输入图片最小为320×320,此时对应的特征图大小为10×10(不是奇数了,确实有点尴尬),而输入图片最大为608×608,对应的特征图大小为19×19。在训练过程,每隔10个iterations随机选择一种输入图片大小,然后只需要修改对最后检测层的处理就可以重新训练。
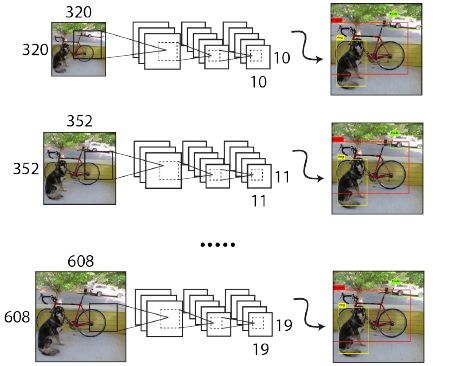
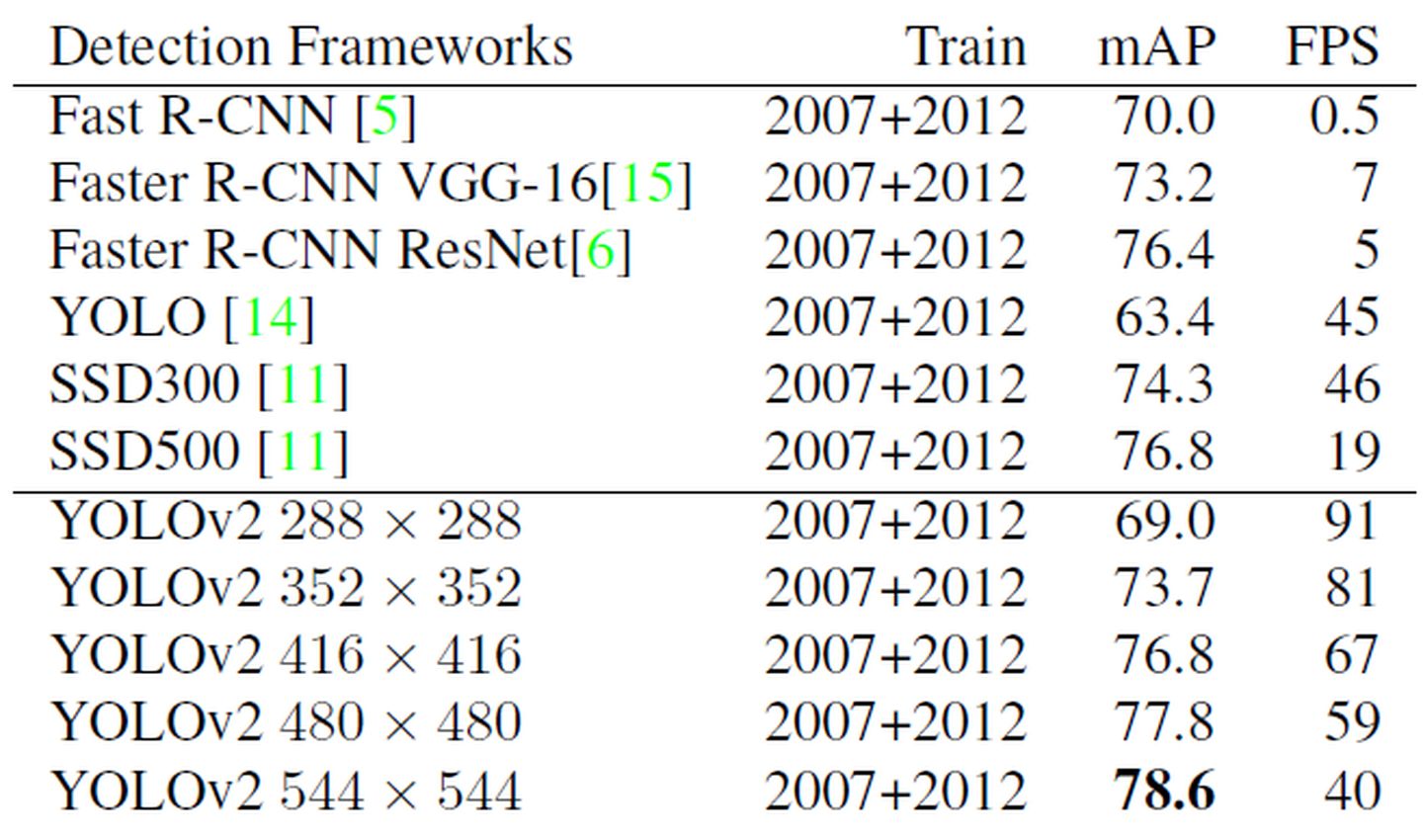
采用Multi-Scale Training策略,YOLOv2可以适应不同大小的图片,并且预测出很好的结果。在测试时,YOLOv2可以采用不同大小的图片作为输入,在VOC 2007数据集上的效果如下图所示。可以看到采用较小分辨率时,YOLOv2的mAP值略低,但是速度更快,而采用高分辨输入时,mAP值更高,但是速度略有下降,对于544×544,mAP高达78.6%。注意,这只是测试时输入图片大小不同,而实际上用的是同一个模型(采用Multi-Scale Training训练)。
Loss
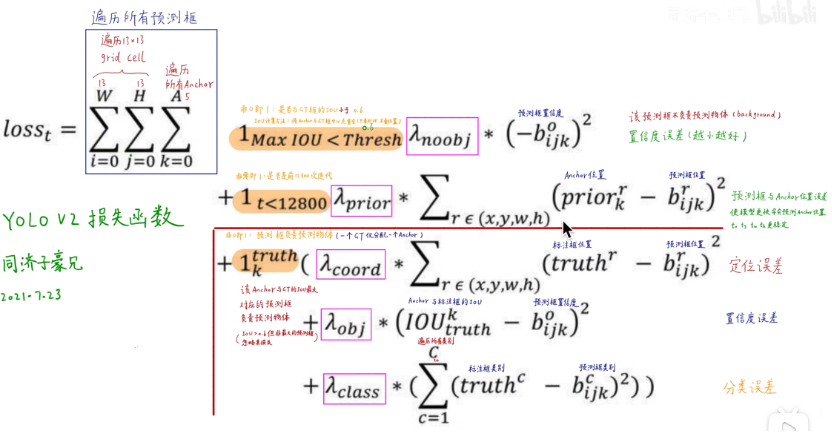
上式子中
是预测的置信度,是预测的位置信息,其中,是预测的框所属类别。是anchor的位置,因为每个cell中的五个anchor都是一样的,所以下角标只需要知道anchor属于这五个anchor的哪一个信息。是标注框的位置信息。是标注框的类别信息。是anchor与标注框的IOU。
loss由三部分组成,其中标黄的部分非0即1。
第一部分标黄部分,表示预测框与标注框的IOU如果小于阈值0.6这部分的值为1,反之为0,后面的
部分表示该预测框不负责预测物体,所以置信度越小越好;
第二部分标黄部分,表示是否前12800次迭代,后面的
表示anchor与预测框位置误差,可以使模型能够更快学会预测anchor位置,使得,,,更稳定;
第三部分标黄部分,表示预测框是否负责预测物体,该anchor与标注框的IOU最大对应的预测框负责预测物体(IOU>0.6但非最大的预测框忽略不计),其中
表示预测框与标注框的定位误差,表示预测框的置信度与标注框和anchor的IOU的误差,表示预测框的所属分类结果与标注框的分类信息的误差。其中各个都表示该项的权重,是已经定义好的超参数。
YOLOV2的训练
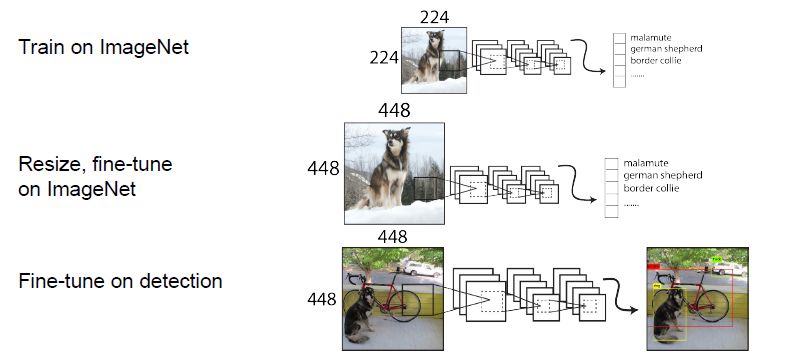
YOLOV2训练分为三个阶段:
第一阶段:第一阶段就是先在ImageNet分类数据集上预训练Darknet-19,此时模型输入为224×224,共训练160个epochs。
第二阶段:将网络的输入调整为448×448,继续在ImageNet数据集上finetune分类模型,训练10个epochs,此时分类模型的top-1准确度为76.5%,而top-5准确度为93.3%。
第三阶段:修改Darknet-19分类模型为检测模型,并在检测数据集上继续finetune网络。网络修改包括:移除最后一个卷积层、global avgpooling层以及softmax层,并且新增了三个3x3x1024卷积层,同时增加了一个passthrough层,最后使用1×1卷积层输出预测结果,输出的channels数为:num_anchors x (5 + num_classes),和训练采用的数据集有关系。
由于anchors数为5,对于VOC数据集输出的channels数就是125,而对于COCO数据集则为425。这里以VOC数据集为例,最终的预测矩阵为T(shape为(batch_size, 13, 13, 125)),可以reshape到(batch_size, 13, 13, 5, 25),其中T[:, :, :, :,0:4]为预测框的位置和大小,T[:, :, :, :,5]为预测框的置信度,T[:, :, :, :,5:]为类别预测值。
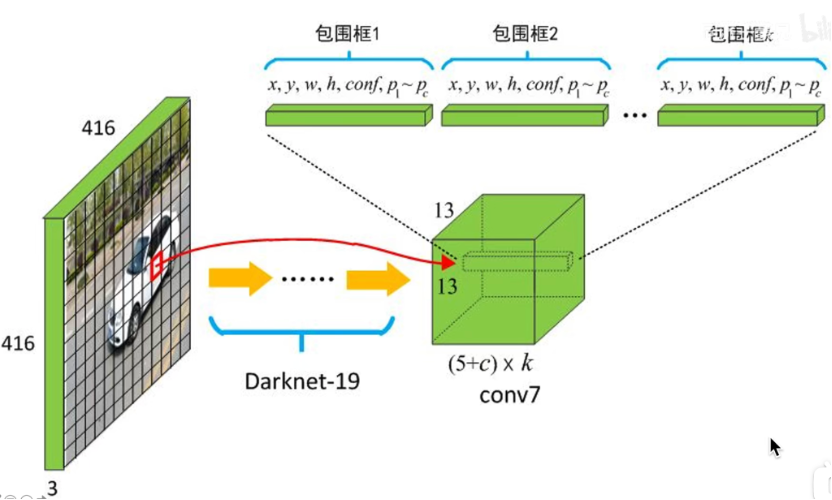
YOLO9000
YOLO9000是在YOLOv2的基础上提出的一种可以检测超过9000个类别的模型,其主要贡献点在于提出了一种分类和检测的联合训练策略。众多周知,检测数据集的标注要比分类数据集打标签繁琐的多,所以ImageNet分类数据集比VOC等检测数据集高出几个数量级。在YOLO中,边界框的预测其实并不依赖于物体的标签,所以YOLO可以实现在分类和检测数据集上的联合训练。对于检测数据集,可以用来学习预测物体的边界框、置信度以及为物体分类,而对于分类数据集可以仅用来学习分类,但是其可以大大扩充模型所能检测的物体种类。
作者选择在COCO和ImageNet数据集上进行联合训练,但是遇到的第一问题是两者的类别并不是完全互斥的,比如”Norfolk terrier”明显属于”dog”,所以作者提出了一种层级分类方法(Hierarchical classification),主要思路是根据各个类别之间的从属关系(根据WordNet)建立一种树结构WordTree,结合COCO和ImageNet建立的WordTree如下图所示:
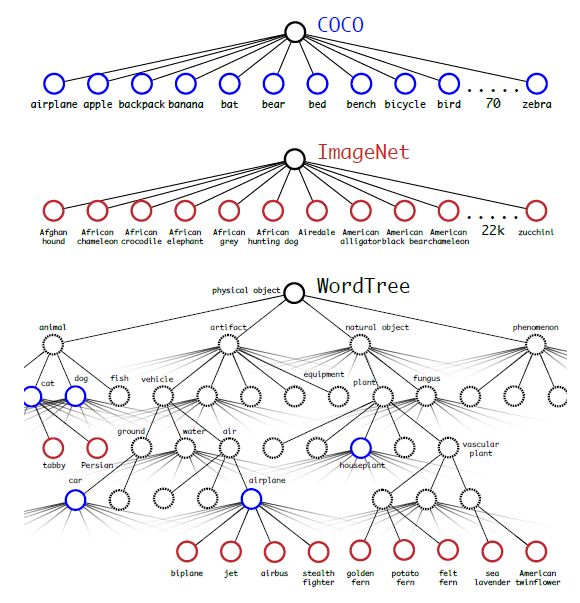
WordTree中的根节点为”physical object”,每个节点的子节点都属于同一子类,可以对它们进行softmax处理。在给出某个类别的预测概率时,需要找到其所在的位置,遍历这个path,然后计算path上各个节点的概率之积。
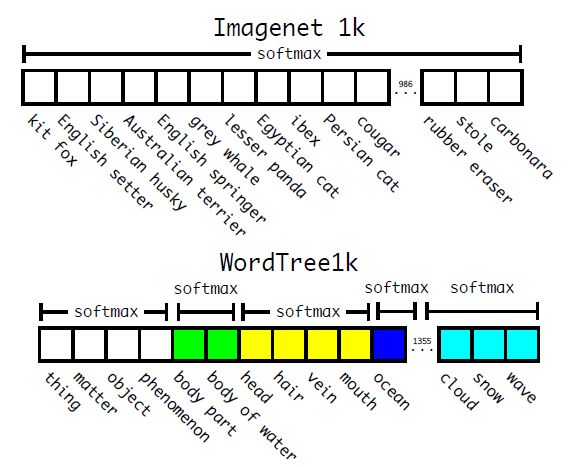
在训练时,如果是检测样本,按照YOLOv2的loss计算误差,而对于分类样本,只计算分类误差。在预测时,YOLOv2给出的置信度就是
,同时会给出边界框位置以及一个树状概率图。在这个概率图中找到概率最高的路径,当达到某一个阈值时停止,就用当前节点表示预测的类别。通过联合训练策略,YOLO9000可以快速检测出超过9000个类别的物体,总体mAP值为19.7%。
讨论
欢迎大家加群讨论

Reference
目标检测|YOLOv2原理与实现(附YOLOv3) – 知乎
深度学习中 Batch Normalization为什么效果好? – 知乎
YOLOv2、v3使用K-means聚类计算anchor boxes的具体方法_fu18946764506的博客-CSDN博客_yolov2 聚类
【精读AI论文】YOLO V2目标检测算法_哔哩哔哩_bilibili
Original: https://blog.csdn.net/qq_36076233/article/details/123083821
Author: Pywin
Title: YOLOV2网络模型
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/708705/
转载文章受原作者版权保护。转载请注明原作者出处!