

原文名称:Attention Is All You Need
原文链接:https://arxiv.org/abs/1706.03762
如果不想看文章的可以看下我在b站上录的视频:https://b23.tv/gucpvt
最近Transformer在CV领域很火,Transformer是2017年Google在 Computation and Language上发表的,当时主要是针对自然语言处理领域提出的(之前的RNN模型记忆长度有限且无法并行化,只有计算完t i t_i t i 时刻后的数据才能计算t i + 1 t_{i+1}t i +1 时刻的数据,但Transformer都可以做到)。在这篇文章中作者提出了 Self-Attention的概念,然后在此基础上提出 Multi-Head Attention,所以本文对 Self-Attention以及 Multi-Head Attention的理论进行详细的讲解。在阅读本文之前,建议大家先去看下李弘毅老师讲的Transformer的内容。本文的内容是基于李宏毅老师讲的内容加上自己阅读一些源码进行的总结。
文章目录
- 前言
- Self-Attention
- Multi-Head Attention
- Self-Attention与Multi-Head Attention计算量对比
- Positional Encoding
- 超参对比
前言
如果之前你有在网上找过self-attention或者transformer的相关资料,基本上都是贴的原论文中的几张图以及公式,如下图,讲的都挺抽象的,反正就是看不懂(可能我太菜的原因)。就像李弘毅老师课程里讲到的”不懂的人再怎么看也不会懂的”。那接下来本文就结合李弘毅老师课上的内容加上原论文的公式来一个个进行详解。


; Self-Attention
下面这个图是我自己画的,为了方便大家理解,假设输入的序列长度为2,输入就两个节点x 1 , x 2 x_1, x_2 x 1 ,x 2 ,然后通过Input Embedding也就是图中的f ( x ) f(x)f (x )将输入映射到a 1 , a 2 a_1, a_2 a 1 ,a 2 。紧接着分别将a 1 , a 2 a_1, a_2 a 1 ,a 2 分别通过三个变换矩阵W q , W k , W v W_q, W_k, W_v W q ,W k ,W v (这三个参数是可训练的,是共享的)得到对应的q i , k i , v i q^i, k^i, v^i q i ,k i ,v i(这里在源码中是直接使用全连接层实现的,这里为了方便理解,忽略偏执)。

其中
- q q q代表query,后续会去和每一个k k k进行匹配
- k k k代表key,后续会被每个q q q匹配
- v v v代表从a a a中提取得到的信息
- 后续q q q和k k k匹配的过程可以理解成计算两者的相关性,相关性越大对应v v v的权重也就越大
假设a 1 = ( 1 , 1 ) , a 2 = ( 1 , 0 ) , W q = ( 1 , 1 0 , 1 ) a_1=(1, 1), a_2=(1,0), W^q= \binom{1, 1}{0, 1}a 1 =(1 ,1 ),a 2 =(1 ,0 ),W q =(0 ,1 1 ,1 )那么:
q 1 = ( 1 , 1 ) ( 1 , 1 0 , 1 ) = ( 1 , 2 ) , q 2 = ( 1 , 0 ) ( 1 , 1 0 , 1 ) = ( 1 , 1 ) q^1 = (1, 1) \binom{1, 1}{0, 1} =(1, 2) , \ \ \ q^2 = (1, 0) \binom{1, 1}{0, 1} =(1, 1)q 1 =(1 ,1 )(0 ,1 1 ,1 )=(1 ,2 ),q 2 =(1 ,0 )(0 ,1 1 ,1 )=(1 ,1 )
前面有说Transformer是可以并行化的,所以可以直接写成:
( q 1 q 2 ) = ( 1 , 1 1 , 0 ) ( 1 , 1 0 , 1 ) = ( 1 , 2 1 , 1 ) \binom{q^1}{q^2} = \binom{1, 1}{1, 0} \binom{1, 1}{0, 1} = \binom{1, 2}{1, 1}(q 2 q 1 )=(1 ,0 1 ,1 )(0 ,1 1 ,1 )=(1 ,1 1 ,2 )
同理我们可以得到( k 1 k 2 ) \binom{k^1}{k^2}(k 2 k 1 )和( v 1 v 2 ) \binom{v^1}{v^2}(v 2 v 1 ),那么求得的( q 1 q 2 ) \binom{q^1}{q^2}(q 2 q 1 )就是原论文中的Q Q Q,( k 1 k 2 ) \binom{k^1}{k^2}(k 2 k 1 )就是K K K,( v 1 v 2 ) \binom{v^1}{v^2}(v 2 v 1 )就是V V V。接着先拿q 1 q^1 q 1和每个k k k进行match,点乘操作,接着除以d \sqrt{d}d 得到对应的α \alpha α,其中d d d代表向量k i k^i k i的长度,在本示例中等于2,除以d \sqrt{d}d 的原因在论文中的解释是”进行点乘后的数值很大,导致通过softmax后梯度变的很小”,所以通过除以d \sqrt{d}d 来进行缩放。比如计算α 1 , i \alpha_{1, i}α1 ,i :
α 1 , 1 = q 1 ⋅ k 1 d = 1 × 1 + 2 × 0 2 = 0.71 α 1 , 2 = q 1 ⋅ k 2 d = 1 × 0 + 2 × 1 2 = 1.41 \alpha_{1, 1} = \frac{q^1 \cdot k^1}{\sqrt{d}}=\frac{1\times 1+2\times 0}{\sqrt{2}}=0.71 \ \alpha_{1, 2} = \frac{q^1 \cdot k^2}{\sqrt{d}}=\frac{1\times 0+2\times 1}{\sqrt{2}}=1.41 α1 ,1 =d q 1 ⋅k 1 =2 1 ×1 +2 ×0 =0 .7 1 α1 ,2 =d q 1 ⋅k 2 =2 1 ×0 +2 ×1 =1 .4 1
同理拿q 2 q^2 q 2去匹配所有的k k k能得到α 2 , i \alpha_{2, i}α2 ,i ,统一写成矩阵乘法形式:
( α 1 , 1 α 1 , 2 α 2 , 1 α 2 , 2 ) = ( q 1 q 2 ) ( k 1 k 2 ) T d \binom{\alpha_{1, 1} \ \ \alpha_{1, 2}}{\alpha_{2, 1} \ \ \alpha_{2, 2}}=\frac{\binom{q^1}{q^2}\binom{k^1}{k^2}^T}{\sqrt{d}}(α2 ,1 α2 ,2 α1 ,1 α1 ,2 )=d (q 2 q 1 )(k 2 k 1 )T
接着对每一行即( α 1 , 1 , α 1 , 2 ) (\alpha_{1, 1}, \alpha_{1, 2})(α1 ,1 ,α1 ,2 )和( α 2 , 1 , α 2 , 2 ) (\alpha_{2, 1}, \alpha_{2, 2})(α2 ,1 ,α2 ,2 )分别进行softmax处理得到( α ^ 1 , 1 , α ^ 1 , 2 ) (\hat\alpha_{1, 1}, \hat\alpha_{1, 2})(α^1 ,1 ,α^1 ,2 )和( α ^ 2 , 1 , α ^ 2 , 2 ) (\hat\alpha_{2, 1}, \hat\alpha_{2, 2})(α^2 ,1 ,α^2 ,2 ),这里的α ^ \hat{\alpha}α^相当于计算得到针对每个v v v的权重。到这我们就完成了A t t e n t i o n ( Q , K , V ) {\rm Attention}(Q, K, V)A t t e n t i o n (Q ,K ,V )公式中s o f t m a x ( Q K T d k ) {\rm softmax}(\frac{QK^T}{\sqrt{d_k}})s o f t m a x (d k Q K T )部分。

上面已经计算得到α \alpha α,即针对每个v v v的权重,接着进行加权得到最终结果:
b 1 = α ^ 1 , 1 × v 1 + α ^ 1 , 2 × v 2 = ( 0.33 , 0.67 ) b 2 = α ^ 2 , 1 × v 1 + α ^ 2 , 2 × v 2 = ( 0.50 , 0.50 ) b_1 = \hat{\alpha}{1, 1} \times v^1 + \hat{\alpha}{1, 2} \times v^2=(0.33, 0.67) \ b_2 = \hat{\alpha}{2, 1} \times v^1 + \hat{\alpha}{2, 2} \times v^2=(0.50, 0.50)b 1 =α^1 ,1 ×v 1 +α^1 ,2 ×v 2 =(0 .3 3 ,0 .6 7 )b 2 =α^2 ,1 ×v 1 +α^2 ,2 ×v 2 =(0 .5 0 ,0 .5 0 )
统一写成矩阵乘法形式:
( b 1 b 2 ) = ( α ^ 1 , 1 α ^ 1 , 2 α ^ 2 , 1 α ^ 2 , 2 ) ( v 1 v 2 ) \binom{b_1}{b_2} = \binom{\hat\alpha_{1, 1} \ \ \hat\alpha_{1, 2}}{\hat\alpha_{2, 1} \ \ \hat\alpha_{2, 2}}\binom{v^1}{v^2}(b 2 b 1 )=(α^2 ,1 α^2 ,2 α^1 ,1 α^1 ,2 )(v 2 v 1 )

A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V {\rm Attention}(Q, K, V)={\rm softmax}(\frac{QK^T}{\sqrt{d_k}})V A t t e n t i o n (Q ,K ,V )=s o f t m a x (d k Q K T )V
Multi-Head Attention
刚刚已经聊完了Self-Attention模块,接下来再来看看Multi-Head Attention模块,实际使用中基本使用的还是Multi-Head Attention模块。原论文中说使用多头注意力机制能够联合来自不同head部分学习到的信息。 Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions.其实只要懂了Self-Attention模块Multi-Head Attention模块就非常简单了。
首先还是和Self-Attention模块一样将a i a_i a i 分别通过W q , W k , W v W^q, W^k, W^v W q ,W k ,W v得到对应的q i , k i , v i q^i, k^i, v^i q i ,k i ,v i,然后再根据使用的head的数目h h h进一步把得到的q i , k i , v i q^i, k^i, v^i q i ,k i ,v i均分成h h h份。比如下图中假设h = 2 h=2 h =2然后q 1 q^1 q 1拆分成q 1 , 1 q^{1,1}q 1 ,1和q 1 , 2 q^{1,2}q 1 ,2,那么q 1 , 1 q^{1,1}q 1 ,1就属于head1,q 1 , 2 q^{1,2}q 1 ,2属于head2。

看到这里,如果读过原论文的人肯定有疑问,论文中不是写的通过W i Q , W i K , W i V W^Q_i, W^K_i, W^V_i W i Q ,W i K ,W i V 映射得到每个head的Q i , K i , V i Q_i, K_i, V_i Q i ,K i ,V i 吗:
h e a d i = A t t e n t i o n ( Q W i Q , K W i K , V W i V ) head_i = {\rm Attention}(QW^Q_i, KW^K_i, VW^V_i)h e a d i =A t t e n t i o n (Q W i Q ,K W i K ,V W i V )
但我在github上看的一些源码中就是简单的进行均分,其实也可以将W i Q , W i K , W i V W^Q_i, W^K_i, W^V_i W i Q ,W i K ,W i V 设置成对应值来实现均分,比如下图中的Q通过W 1 Q W^Q_1 W 1 Q 就能得到均分后的Q 1 Q_1 Q 1 。
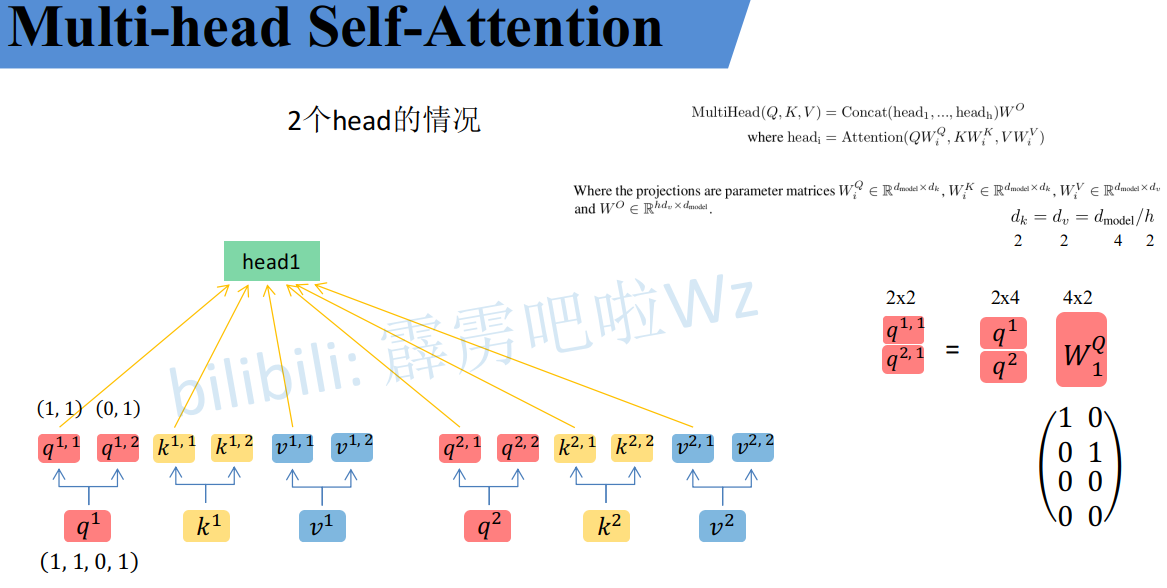
通过上述方法就能得到每个h e a d i head_i h e a d i 对应的Q i , K i , V i Q_i, K_i, V_i Q i ,K i ,V i 参数,接下来针对每个head使用和Self-Attention中相同的方法即可得到对应的结果。
A t t e n t i o n ( Q i , K i , V i ) = s o f t m a x ( Q i K i T d k ) V i {\rm Attention}(Q_i, K_i, V_i)={\rm softmax}(\frac{Q_iK_i^T}{\sqrt{d_k}})V_i A t t e n t i o n (Q i ,K i ,V i )=s o f t m a x (d k Q i K i T )V i

接着将每个head得到的结果进行concat拼接,比如下图中b 1 , 1 b_{1,1}b 1 ,1 (h e a d 1 head_1 h e a d 1 得到的b 1 b_1 b 1 )和b 1 , 2 b_{1,2}b 1 ,2 (h e a d 2 head_2 h e a d 2 得到的b 1 b_1 b 1 )拼接在一起,b 2 , 1 b_{2,1}b 2 ,1 (h e a d 1 head_1 h e a d 1 得到的b 2 b_2 b 2 )和b 2 , 2 b_{2,2}b 2 ,2 (h e a d 2 head_2 h e a d 2 得到的b 2 b_2 b 2 )拼接在一起。

接着将拼接后的结果通过W O W^O W O(可学习的参数)进行融合,如下图所示,融合后得到最终的结果b 1 , b 2 b_1, b_2 b 1 ,b 2 。

到这,
Multi-Head Attention的内容就讲完了。总结下来就是论文中的两个公式:M u l t i H e a d ( Q , K , V ) = C o n c a t ( h e a d 1 , . . . , h e a d h ) W O w h e r e h e a d i = A t t e n t i o n ( Q W i Q , K W i K , V W i V ) {\rm MultiHead}(Q, K, V) = {\rm Concat(head_1,…,head_h)}W^O \ {\rm where \ head_i = Attention}(QW_i^Q, KW_i^K, VW_i^V)M u l t i H e a d (Q ,K ,V )=C o n c a t (h e a d 1 ,…,h e a d h )W O w h e r e h e a d i =A t t e n t i o n (Q W i Q ,K W i K ,V W i V )
; Self-Attention与Multi-Head Attention计算量对比
在原论文章节3.2.2中最后有说两者的计算量其实差不多。 Due to the reduced dimension of each head, the total computational cost is similar to that of single-head attention with full dimensionality.下面做了个简单的实验,这个model文件大家先忽略哪来的。这个 Attention就是实现 Multi-head Attention的方法,其中包括上面讲的所有步骤。
- 首先创建了一个
Self-Attention模块(单头)a1,然后把proj变量置为Identity(Identity对应的是Multi-Head Attention中最后那个W o W^o W o的映射,单头中是没有的,所以置为Identity即不做任何操作)。 - 再创建一个
Multi-Head Attention模块(多头)a2,然后设置8个head。 - 创建一个随机变量,注意shape
- 使用fvcore分别计算两个模块的FLOPs
import torch
from fvcore.nn import FlopCountAnalysis
from model import Attention
def main():
a1 = Attention(dim=512, num_heads=1)
a1.proj = torch.nn.Identity()
a2 = Attention(dim=512, num_heads=8)
t = (torch.rand(32, 1024, 512),)
flops1 = FlopCountAnalysis(a1, t)
print("Self-Attention FLOPs:", flops1.total())
flops2 = FlopCountAnalysis(a2, t)
print("Multi-Head Attention FLOPs:", flops2.total())
if __name__ == '__main__':
main()
终端输出如下, 可以发现确实两者的FLOPs差不多, Multi-Head Attention比 Self-Attention略高一点:
Self-Attention FLOPs: 60129542144
Multi-Head Attention FLOPs: 68719476736
其实两者FLOPs的差异只是在最后的W O W^O W O上,如果把 Multi-Head Attentio的W O W^O W O也删除(即把 a2的proj也设置成Identity),可以看出两者FLOPs是一样的:
Self-Attention FLOPs: 60129542144
Multi-Head Attention FLOPs: 60129542144
Positional Encoding
如果仔细观察刚刚讲的Self-Attention和Multi-Head Attention模块,在计算中是没有考虑到位置信息的。假设在Self-Attention模块中,输入a 1 , a 2 , a 3 a_1, a_2, a_3 a 1 ,a 2 ,a 3 得到b 1 , b 2 , b 3 b_1, b_2, b_3 b 1 ,b 2 ,b 3 。对于a 1 a_1 a 1 而言,a 2 a_2 a 2 和a 3 a_3 a 3 离它都是一样近的而且没有先后顺序。假设将输入的顺序改为a 1 , a 3 , a 2 a_1, a_3, a_2 a 1 ,a 3 ,a 2 ,对结果b 1 b_1 b 1 是没有任何影响的。下面是使用Pytorch做的一个实验,首先使用 nn.MultiheadAttention创建一个 Self-Attention模块( num_heads=1),注意这里在正向传播过程中直接传入Q K V QKV Q K V,接着创建两个顺序不同的Q K V QKV Q K V变量t1和t2(主要是将q 2 , k 2 , v 2 q^2, k^2, v^2 q 2 ,k 2 ,v 2和q 3 , k 3 , v 3 q^3, k^3, v^3 q 3 ,k 3 ,v 3的顺序换了下),分别将这两个变量输入Self-Attention模块进行正向传播。
import torch
import torch.nn as nn
m = nn.MultiheadAttention(embed_dim=2, num_heads=1)
t1 = [[[1., 2.],
[2., 3.],
[3., 4.]]]
t2 = [[[1., 2.],
[3., 4.],
[2., 3.]]]
q, k, v = torch.as_tensor(t1), torch.as_tensor(t1), torch.as_tensor(t1)
print("result1: \n", m(q, k, v))
q, k, v = torch.as_tensor(t2), torch.as_tensor(t2), torch.as_tensor(t2)
print("result2: \n", m(q, k, v))
对比结果可以发现,即使调换了q 2 , k 2 , v 2 q^2, k^2, v^2 q 2 ,k 2 ,v 2和q 3 , k 3 , v 3 q^3, k^3, v^3 q 3 ,k 3 ,v 3的顺序,但对于b 1 b_1 b 1 是没有影响的。

为了引入位置信息,在原论文中引入了位置编码
positional encodings。 To this end, we add "positional encodings" to the input embeddings at the bottoms of the encoder and decoder stacks.如下图所示,位置编码是直接加在输入的a = { a 1 , . . . , a n } a={a_1,…,a_n}a ={a 1 ,…,a n }中的,即p e = { p e 1 , . . . , p e n } pe={pe_1,…,pe_n}p e ={p e 1 ,…,p e n }和a = { a 1 , . . . , a n } a={a_1,…,a_n}a ={a 1 ,…,a n }拥有相同的维度大小。关于位置编码在原论文中有提出两种方案,一种是原论文中使用的固定编码,即论文中给出的 sine and cosine functions方法,按照该方法可计算出位置编码;另一种是可训练的位置编码,作者说尝试了两种方法发现结果差不多(但在ViT论文中使用的是可训练的位置编码)。

超参对比
关于Transformer中的一些超参数的实验对比可以参考原论文的表3,如下图所示。其中:
- N表示重复堆叠Transformer Block的次数
- d m o d e l d_{model}d m o d e l 表示Multi-Head Self-Attention输入输出的token维度(向量长度)
- d f f d_{ff}d f f 表示在MLP(feed forward)中隐层的节点个数
- h表示Multi-Head Self-Attention中head的个数
- d k , d v d_k, d_v d k ,d v 表示Multi-Head Self-Attention中每个head的key(K)以及query(Q)的维度
- P d r o p P_{drop}P d r o p 表示dropout层的drop_rate

到这,关于Self-Attention、Multi-Head Attention以及位置编码的内容就全部讲完了,如果有讲的不对的地方希望大家指出。
Original: https://blog.csdn.net/qq_37541097/article/details/117691873
Author: 太阳花的小绿豆
Title: 详解Transformer中Self-Attention以及Multi-Head Attention
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/652072/
转载文章受原作者版权保护。转载请注明原作者出处!