

1 前言
我们在用Pytorch开发项目的时候,常常将项目代码分为数据处理模块、模型构建模块与训练控制模块。数据处理模块的主要任务是构建数据集。为方便深度学习项目构建数据集,Pytorch为我们提供了Dataset类。那么,假如现在已经有训练数据和标签,该怎么用Dataset类构建一个符合Pytorch规范的数据集呢?在刚开始学的时候,或许我们会上网找一些代码来参考。不过,有时我们找到的代码可能与自己的数据格式不一样,以至于在模仿着写的时候,不确定自己写的代码对不对。本人起初也有这样的体会,为此,本文就来说说我的领悟过程。我首先是学习在Pytorch中构建数据集的步骤。学会之后的感觉是,明白了在Pytorch中创建数据集的套路,但是不了解为什么要这么做。后来当我明白了其底层逻辑之后,写代码更有信心了。为此,本文将从两个方面进行介绍。首先介绍在Pytorch中构建数据集的步骤,然后介绍用Dataset类构建数据集的底层逻辑。
2 在Pytorch中构建数据集的步骤
下面用一个具体实例来说明拿到数据后,如何根据模型训练的需要来构建数据集。
- .实例一:图像二分类训练任务,识别1元纸币和100元纸币
如下图所示,现已有1元和100元纸币图像样本分别存放在”1″和”100″两个文件夹中。
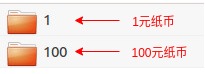

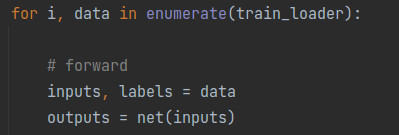
在构建数据集前,我们要先明确模型需要哪些输入数据,除了模型所需的输入数据,在训练时还需要哪些数据。在本例中,模型需要图像数据作为输入。除了图像数据,还需要与图像数据相对应的类别标签,以用它来计算loss。所以,如下图所示,inputs和labels分别是从列表data中得到的图像数据序列和类别标签序列。也就是说,我们构建数据集的应该包含这两部分数据。
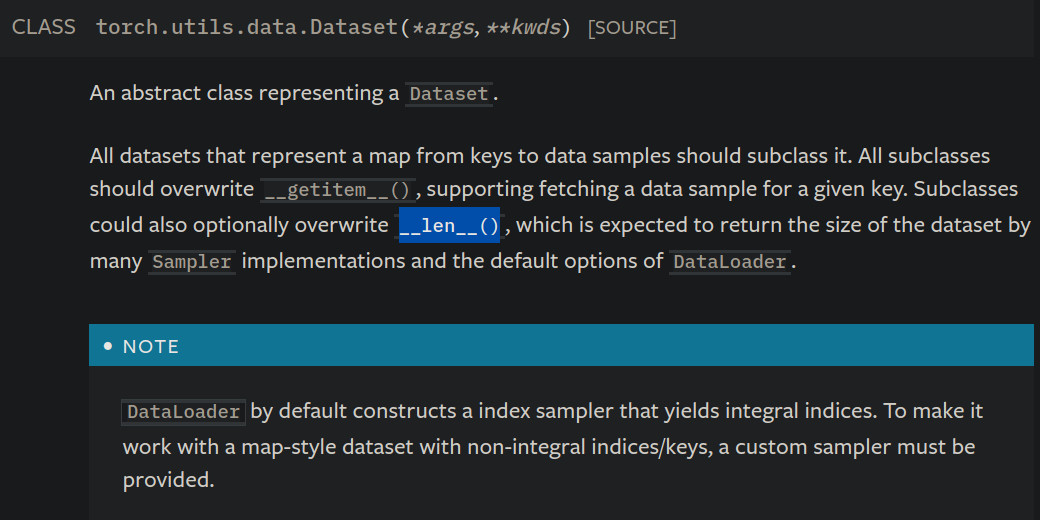
明确了需要构建什么数据后,下一步就是通过继承Pytorch的dataset类来编写自己的dataset类。Pytorch的dataset类是一个抽象类,继承dataset,需要实现它的__getitem__()方法和__len__()方法,下图是Pytorch官方文档中关于dataset类的说明。
除了实现上述两个方法外,我们还需写一个静态方法,用来构建数据列表,因为__getitem__( )要用到这个数据列表。
先上一份创建dataset的实例代码
class CashDataset(Dataset):
def __init__(self, data_dir, transform=None):
"""
纸币分类任务的Dataset
:param data_dir: str, 数据集所在路径
:param transform: torch.transform,数据预处理
"""
self.label_name = {"1": 0, "100": 1}
self.data_info = self.get_img_info(data_dir) # data_info存储所有图片路径和标签,在DataLoader中通过index读取样本
self.transform = transform
def __getitem__(self, index):
path_img, label = self.data_info[index]
img = Image.open(path_img).convert('RGB')
if self.transform is not None:
img = self.transform(img)
return img, label
def __len__(self):
return len(self.data_info)
@staticmethod
def get_img_info(data_dir):
data_info = list()
for root, dirs, _ in os.walk(data_dir):
# 遍历类别
for sub_dir in dirs:
img_names = os.listdir(os.path.join(root, sub_dir))
img_names = list(filter(lambda x: x.endswith('.jpg'), img_names))
# 遍历图片
for i in range(len(img_names)):
img_name = img_names[i]
path_img = os.path.join(root, sub_dir, img_name)
label = rmb_label[sub_dir]
data_info.append((path_img, int(label)))
return data_info
undefined
上面代码中的静态方法get_img_info(data_dir)就是用来构建数据列表的,它返回数据列表data_info,data_info中的元素由元组(图像路径,图像标签)构成。
在__getitem__(self, index)方法中,通过data_info中存储的文件路径去读取图像数据,最后返回索引下标为index的图像数据和标签。这里返回哪些数据主要是由训练代码中需要哪些数据来决定。也就是说,我们根据训练代码需要什么数据来重写__getitem__(self, index)方法并返回相应的数据。
最后还要重写__len__(self)方法。实现__len__(self)方法比较简单,只需一行代码,也就是返回数据列表的的长度,即数据集的样本数量。
下面对构建CashDataset类做个小结,主要步骤如下:
1) 确定训练代码需要哪些数据;
2) 重写__getitem__(self, index)方法,根据index返回训练代码所需的数据;
3) 编写静态方法,构建并返回数据列表data_info;
4) 重写__len__(self)方法,返回数据列表长度;
看到这里,也许会有两个困惑:
困惑1:在训练代码中是怎么调用到__getitem__( )的,是编写代码手动调用,还是Pytorch函数内部自动调用?
困惑2:getitem( )返回的数据是单个 (图像, 标签),为什么在训练代码中得到的数据格式不是[(图像1, 标签1), (图像2, 标签2),, …, (图像n, 标签n)]这种格式,而是[图像1, 图像2, …, 图像n]、[标签1, 标签2, …, 标签n] 这种格式?
要想知道这两个答案,就需要了解Pytorch调用CashDataset的底层逻辑。
3 用Dataset类构建数据集的底层逻辑
先上代码
构建CashDataset实例
train_data = CashDataset(data_dir=train_dir, transform=train_transform)
valid_data = CashDataset(data_dir=valid_dir, transform=valid_transform)
构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, batch_size=BATCH_SIZE)
如上面代码第六行所示,在创建DataLoader对象时,将数据集train_data作为参数传入DataLoader中。所以,我们大概能猜到应该是在DataLoader内部直接或间接地调用了__getitem__( )。DataLoader是Pytorch的数据加载器,下面让我们深入其内部看看它是怎样一步一步执行,最终调用到__getitem__( )。
在Pytorch官网可以查到Dataloader的构造方法有很多参数,我们这里主要关注其中四个,如下图所示。
DataLoader(dataset, batch_size=1, num_workers=0, shuffle=False)
dataset:需要载入的数据集
batch_size:批大小,即迭代器一次加载多少个样本
num_workers:使用多少个子进程来加载数据,0表示只在主进程中加载数据。Pytorch会根据此参数来判断是创建单进程SingleProcessDataLoaderIter类对象,还是创建多进程MultiProcessingDataLoaderIter类对象
shuffle:是否在每个epoch训练前打乱数据集中的样本顺序
为了能弄清dataloader的整个执行过程,需通过打断点、步进的方式进入到dataloader类内部。
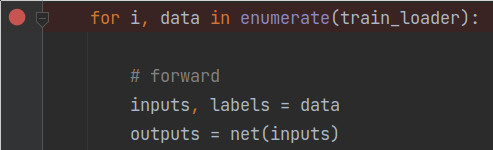
如上图所示,在for循环处打个断点,然后点击步进按钮,可以得到大致的执行流程,如下图所示。下图中冒号左侧是类名,冒号右侧是类方法,方框中只列出类方法中的主要代码。
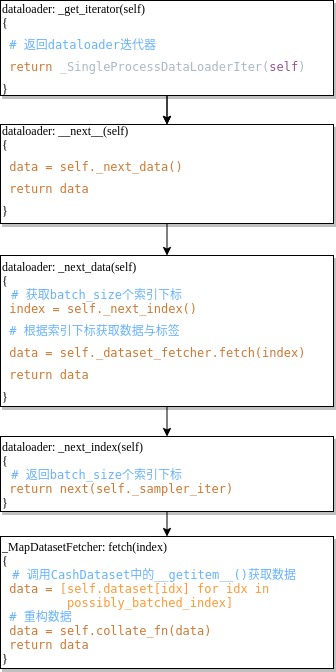
如上图最后一步所示,在_MapDatasetFetcher类中的fetch( )方法中,执行self.dataset[idx]会去调用_getitem__( )方法,以获取train_data中的数据。经过batch_size次循环得到数据列表data,再通过self.collate_fn( )方法重构data。也就是将 [(图像1, 标签1), (图像2, 标签2),, …, (图像n, 标签n)] 这种格式,变换为 [图像1, 图像2, …, 图像n]、[标签1, 标签2, …, 标签n] 这种格式。
4 总结
关于Pytorch如何调用CashDataset以获取训练数据的底层逻辑,可以概括为三点:Ⅰ) 由Dataloader创建一个迭代器dataloaderIter;Ⅱ) dataloaderIter通过调用sampler_iter得到一个batch_size的索引下标序列;Ⅲ) 在_MapDatasetFetcher类的fetch( )方法中调用__getitem__( ),以获取数据与类标签,再通过collate_fn( )重构数据列表。
Original: https://blog.csdn.net/rowevine/article/details/123631144
Author: 遥望山海
Title: 使用Pytorch中的Dataset类构建数据集的方法及其底层逻辑
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/705301/
转载文章受原作者版权保护。转载请注明原作者出处!