

首先我们需要了解计算机中的彩色图片是怎么表示的?用一个三维的数组或者说列表就可以很简单的表示出计算机中的彩色图片。
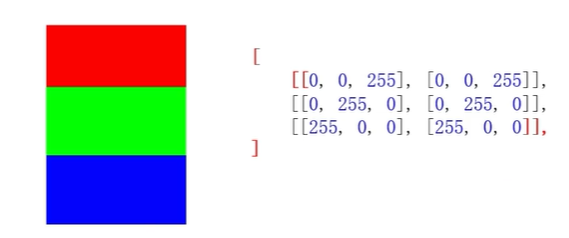

案例一:生成图片数据
"""
案例1 :使用OpenCV写入图片
"""
import numpy as np
import cv2
1.实例化代表图片的列表数据
image_list = [
[[0,0,255],[0,0,255]],
[[0,255,0],[0,255,0]],
[[255,0,0],[255,0,0]],
]
#2.把列表数据转换成numpy中的数组
image_arry=np.array(image_list)
#3.把转化好的数组对象写入到特定的文件中
cv2.imwrite('images/demo3x2.png',image_arry)
案例二:显示图片数据
"""
案例2 :使用opencv读取刚刚写入的图片,查看像素内容,查看形状或者说维度信息
"""
import cv2
#使用opency读取刚刚写入的图片, 查看像素内容,查看形状或者说维度信息
1.通过opencr库读取图片
src = cv2.imread('images/demo3x2.png')
2. 查看像素内容
print(src)
3. 查看维度信息
print(src.shape)#shape图片(长,宽,通道)
接下来我们需要知道,计算机中的灰度图像是怎样表示的,为什么要使用灰度图像?
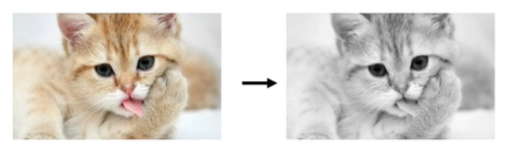
如图所示不是彩色的RGB图片,而是灰度图像,感觉不需要用RGB三个通道来表示,使用三个通道有点浪费;并且使用灰度图片失真并不大。
案例三:彩色图像(RGB)转灰度(GRAY)图像
"""
案例3 :彩色图像(RGB)转灰度(GRAY)图像
"""
import cv2
#把彩色图像转换为灰度图像,并看看灰度图像在计算机中又是怎样表示的。
1.读取彩色猫图
rgb_cat = cv2.imread("images/cat.png" )
2.把彩色图片转换为灰度图片
gray_cat = cv2.cvtColor(rgb_cat, cv2.COLOR_BGR2GRAY)
3.查看灰度图像的像素内容
print(gray_cat)
4.查看灰度图片的维度信息
print(gray_cat.shape)
5.保存灰度图像
cv2.imwrite("images/cat_gray.png",gray_cat)
回答问题:计算机中的灰度图像是用二维数组表示的,灰度图像起到了降维的作用,方便计算机快速处理。
案例实战四:人脸识别
人脸识别—安装包:
pip install cmake
pip install scikit-image
pip install dlib
pip install face_recognition
PS:为了加快速度安装时可以选择国内镜像
如:pip install face_recognition -i https://pypi.douban.com/simple
有些包的安装需要时间,不要着急,请耐心等待
安装时如果遇到dlib或者face_recognition安装报错,请参照:
pycharm在windows中如何安装dlib? – aidenzdly – 博客园
python镜像源安装face_recognition – 知乎
人脸识别—步骤
1.定位到人的脸部,并用绿色的框框把人的脸部框住
2.读取到数据库中的人名和面部特征
3.匹配拍摄到人的脸部特征和数据库中的面部特征,并用用户姓名标识.
4.定位和锁定目标人物,改使用红色的框框把目标人物的脸部框住
人脸识别—步骤1
代码解释: face_locations=face_recognition.face_locations(frame)
返回值:
一个元组列表,列表中的每个元组包含人脸的位置(top, right, bottom, left)
import face_recognition
import cv2
#打开摄像头,读取摄像头拍摄到的画面,
#定位到画面中人的脸部,并用绿色的框框把人的脸部框住
1.打开摄像头, 获取摄像头对象
video_capture = cv2.VideoCapture(0) # 0代表的是第一 个摄像:头
2.循环不停的去获取摄像头拍摄到的画面,并做进一 步的处理
while True:
# TODO还需要做进一步的处理
# 2.1获取摄像头拍摄到的画面
ret,frame = video_capture.read() # frame 摄像头所拍摄的画面,ret能否获取到画面
# 2.2从拍摄到的画面中提取出人的脸部所在区域(可能会有多个)
face_locations=face_recognition.face_locations(frame)#返回值是人像对角线上的两个点坐标
# 2.3循环遍历人的脸部所在区域,并画框
for top,right,bottom,left in face_locations:
#2.3.1 在人像所在区域画框
cv2.rectangle(frame,(left,top),(right,bottom),(0,255,0),2)#color(0,255,0) ==BGR;2表示线条宽度
# 2.4通过opencv把拍摄到的并画J框的画面展示出来
cv2.imshow("Video", frame)
# 2.5设定按q退HiWhile循环, 退出程序的这样一 个机制
if cv2.waitKey(1) & 0xFF == ord('q'):
break #退出while循环
3.退出程序的时候,释放摄像头或其他资源
video_capture.release()
cv2.destroyAllWindows()
运行结果:可以对人脸识别到人脸,并且画出框框

人脸识别—步骤2
读取到数据库中的人名和面部特征
import os
import face_recognition
import cv2
#读取到数据库中的人名和面部特征
#1.准备工作
face_databases_dir='face_databases'
user_names=[] #存储用户姓名
user_face_encodings=[] #村用户面部特征(一一对应的关系)
#2.正式共工
#2.1得到face_databases_dir文件夹下所有的文件
files=os.listdir(face_databases_dir)
#2.2 循环去取文件名进行进一步处理
for image_shot_name in files:
# 2.2.1 截取文件名的.前面那部分作为用户名存入user_names的列表中
user_name,_ =os.path.splitext(image_shot_name)
user_names.append(user_name)
# 2.2.2 读取图片文件中的面部特征信息存入user_faces_encodings列表中
image_file_name=os.path.join(face_databases_dir,image_shot_name) #face_databases/jason.jpg
image_file=face_recognition.load_image_file(image_file_name)
face_encoding=face_recognition.face_encodings(image_file)[0] #一张图片可能有多个头像,所以需要取数组第一个
user_face_encodings.append(face_encoding)
人脸识别-步骤3
用拍摄到人的脸部特征和数据库中的面部特征去匹配,并在用户头像的绿框_上方用用户的姓名做标识,未知用户统一使用Unkown
#打开摄像头,读取摄像头拍摄到的画面,
#定位到画面中人的脸部,并用绿色的框框把人的脸部框住
1.打开摄像头, 获取摄像头对象
video_capture = cv2.VideoCapture(0) # 0代表的是第一 个摄像:头
2.循环不停的去获取摄像头拍摄到的画面,并做进一 步的处理
while True:
# TODO还需要做进一步的处理
# 2.1获取摄像头拍摄到的画面# 2.1获取摄像头拍摄到的画面
ret,frame = video_capture.read() # frame 摄像头所拍摄的画面,ret能否获取到画面
# 2.2从拍摄到的画面中提取出人的脸部所在区域(可能会有多个)
# ['第一个人脸所在区域','第二个人脸所在区域'....]
face_locations=face_recognition.face_locations(frame)#返回值是人像对角线上的两个点坐标
#2.21 从所有人头像所在区域提取出脸部特征
#['第一个人脸对应的面部特征','第二个人脸对应的面部特征'....]
face_encodings=face_recognition.face_encodings(frame,face_locations)
# 2.22 定义用于存储拍摄到的用户姓名的列表
#['第一个人的姓名','第二个人的姓名'....] ,如果特征匹配不上数据库上的特征,则是Unknown
names=[]
#遍历face_encodings,和数据库中的面部特征做匹配
for face_encoding in face_encodings:
#compare_faces(['面部特征1','面部特征2','面部特征3'...], 未知面部特征 )
#compare_faces返回结果:
# 假如 未知的面部特征 和 面部特征1 匹配,和面部特征2 面部特征3不匹配===返回:[True,False,False]
# 假如 未知的面部特征 和 面部特征2 匹配,和面部特征1 面部特征3不匹配===返回:[False,True,False]
matchs=face_recognition.compare_faces(user_face_encodings,face_encoding)
#user_names存储结果==['第一个人的姓名','第二个人的姓名'....]
name="UnKnown"
for index,is_match in enumerate(matchs):
#[False, True, False]
# 0,False
# 1,True
# 2,False
if is_match:
name=user_names[index]
break
names.append(name)
# 2.3循环遍历人的脸部所在区域,并画框;在框框上标识人的姓名
#zip
#zip(['第1个人的位置','第2个人的位置'],['第1个人的姓名','第2个人的姓名'])
#for
#'第1个人的位置','第1个人的姓名'
#'第2个人的位置','第2个人的姓名'
print(names)
for (top,right,bottom,left),name in zip(face_locations,names):
#2.3.1 在人像所在区域画框
cv2.rectangle(frame,(left,top),(right,bottom),(0,255,0),2)#color(0,255,0) ==BGR;2表示线条宽度
font=cv2.FONT_HERSHEY_DUPLEX #字体
cv2.putText(frame,name,(left,top-10),font,0.5,(255,0,0),1)
# 2.4通过opencv把拍摄到的并画J框的画面展示出来
cv2.imshow("Video", frame)
人脸识别-步骤4
定位和锁定目标人物,改使用红色的框框把目标人物的脸部框住
这里附加上整体代码:
import os
import face_recognition
import cv2
#读取到数据库中的人名和面部特征
#1.准备工作
face_databases_dir='face_databases'
user_names=[] #存储用户姓名
user_face_encodings=[] #村用户面部特征(一一对应的关系)
boss_name=['jason']
#2.正式共工
#2.1得到face_databases_dir文件夹下所有的文件
files=os.listdir(face_databases_dir)
#2.2 循环去取文件名进行进一步处理
for image_shot_name in files:
# 2.2.1 截取文件名的.前面那部分作为用户名存入user_names的列表中
user_name,_ =os.path.splitext(image_shot_name)
user_names.append(user_name)
# 2.2.2 读取图片文件中的面部特征信息存入user_faces_encodings列表中
image_file_name=os.path.join(face_databases_dir,image_shot_name) #face_databases/jason.jpg
image_file=face_recognition.load_image_file(image_file_name)
face_encoding=face_recognition.face_encodings(image_file)[0] #一张图片可能有多个头像,所以需要取数组第一个
user_face_encodings.append(face_encoding)
print(user_names)
print(user_face_encodings)
#----------------------------
#用拍摄到人的脸部特征和数据库中的面部特征去匹配,并在用户头像的绿框_上方用用户的姓名做标识,未知用户统一使用Unkown
#打开摄像头,读取摄像头拍摄到的画面,
#定位到画面中人的脸部,并用绿色的框框把人的脸部框住
1.打开摄像头, 获取摄像头对象
video_capture = cv2.VideoCapture(0) # 0代表的是第一 个摄像:头
2.循环不停的去获取摄像头拍摄到的画面,并做进一 步的处理
while True:
# TODO还需要做进一步的处理
# 2.1获取摄像头拍摄到的画面
ret,frame = video_capture.read() # frame 摄像头所拍摄的画面,ret能否获取到画面
# 2.2从拍摄到的画面中提取出人的脸部所在区域(可能会有多个)
# ['第一个人脸所在区域','第二个人脸所在区域'....]
face_locations=face_recognition.face_locations(frame)#返回值是人像对角线上的两个点坐标
#2.21 从所有人头像所在区域提取出脸部特征
#['第一个人脸对应的面部特征','第二个人脸对应的面部特征'....]
face_encodings=face_recognition.face_encodings(frame,face_locations)
# 2.22 定义用于存储拍摄到的用户姓名的列表
#['第一个人的姓名','第二个人的姓名'....] ,如果特征匹配不上数据库上的特征,则是Unknown
names=[]
#遍历face_encodings,和数据库中的面部特征做匹配
for face_encoding in face_encodings:
#compare_faces(['面部特征1','面部特征2','面部特征3'...], 未知面部特征 )
#compare_faces返回结果:
# 假如 未知的面部特征 和 面部特征1 匹配,和面部特征2 面部特征3不匹配===返回:[True,False,False]
# 假如 未知的面部特征 和 面部特征2 匹配,和面部特征1 面部特征3不匹配===返回:[False,True,False]
matchs=face_recognition.compare_faces(user_face_encodings,face_encoding)
#user_names存储结果==['第一个人的姓名','第二个人的姓名'....]
name="UnKnown"
for index,is_match in enumerate(matchs):
#[False, True, False]
# 0,False
# 1,True
# 2,False
if is_match:
name=user_names[index]
break
names.append(name)
# 2.3循环遍历人的脸部所在区域,并画框;在框框上标识人的姓名
#zip
#zip(['第1个人的位置','第2个人的位置'],['第1个人的姓名','第2个人的姓名'])
#for
#'第1个人的位置','第1个人的姓名'
#'第2个人的位置','第2个人的姓名'
print(names)
for (top,right,bottom,left),name in zip(face_locations,names):
color=(0,255,0)
if name in boss_name:
#BGR
color=(0,0,255)
#2.3.1 在人像所在区域画框
cv2.rectangle(frame,(left,top),(right,bottom),color,2)#color(0,255,0) ==BGR;2表示线条宽度
font=cv2.FONT_HERSHEY_DUPLEX #字体
cv2.putText(frame,name,(left,top-10),font,0.5,color,1)
# 2.4通过opencv把拍摄到的并画J框的画面展示出来
cv2.imshow("Video", frame)
# 2.5设定按q退HiWhile循环, 退出程序的这样一 个机制
if cv2.waitKey(1) & 0xFF == ord('q'):
break #退出while循环
3.退出程序的时候,释放摄像头或其他资源
video_capture.release()
cv2.destroyAllWindows()
案例五:微信公众号运动传感器
目标:差分法原理、运动传感器的实现、基于微信公众平台的开发、代码封装和优化的过程:
面相过程->面相函数->面相对象
需求分析:正常情况下屏幕上显示绿色字体描述当前情况;当摄像头检测到有人闯入摄像头区域时,字体变红,用户通过微信平台接收到闯入信号。
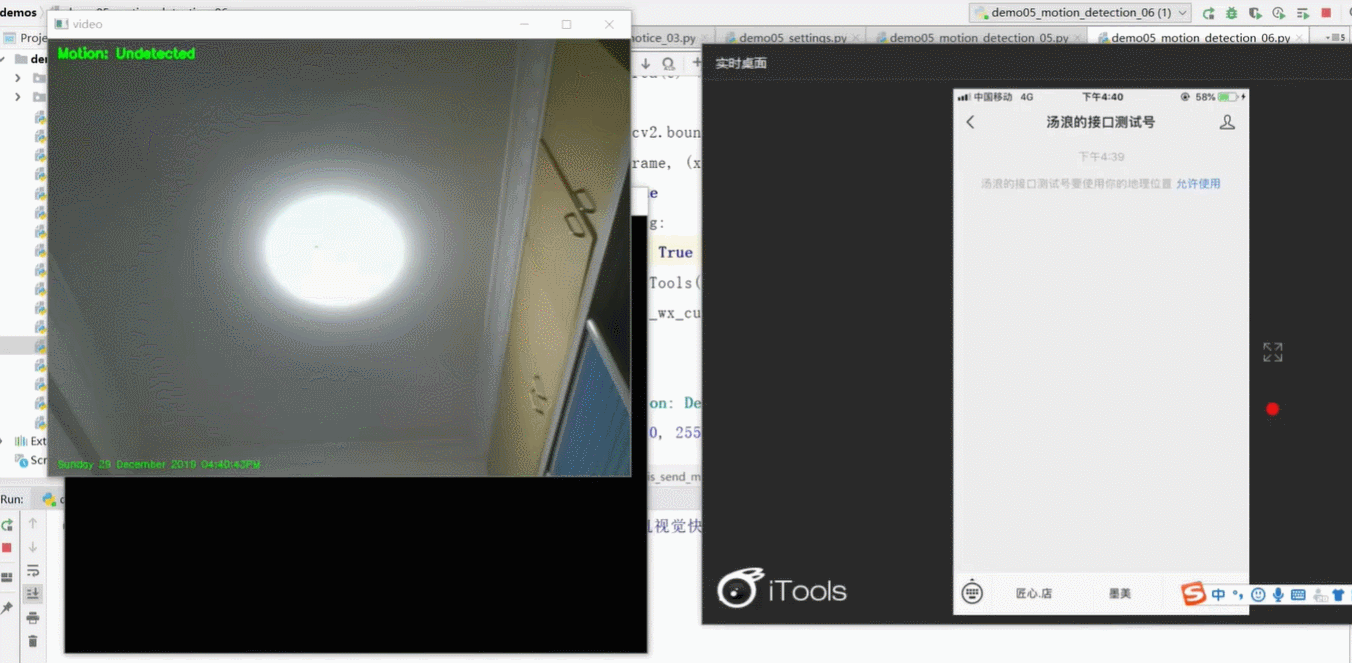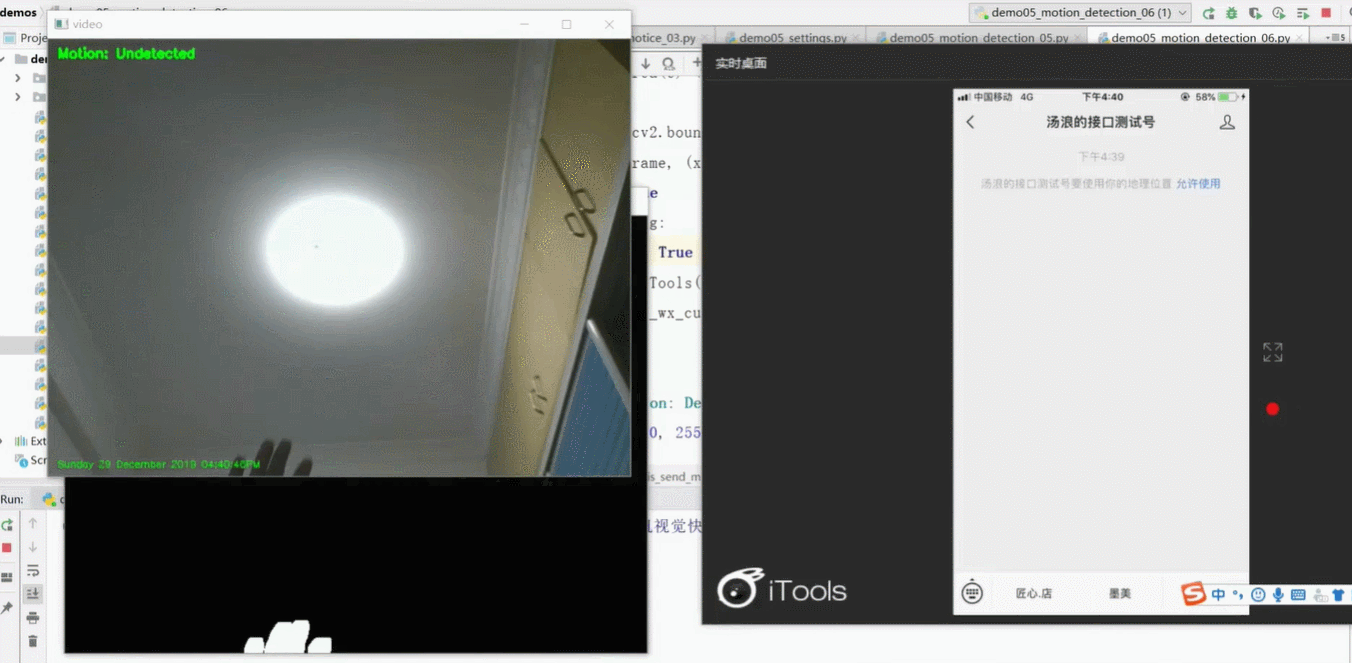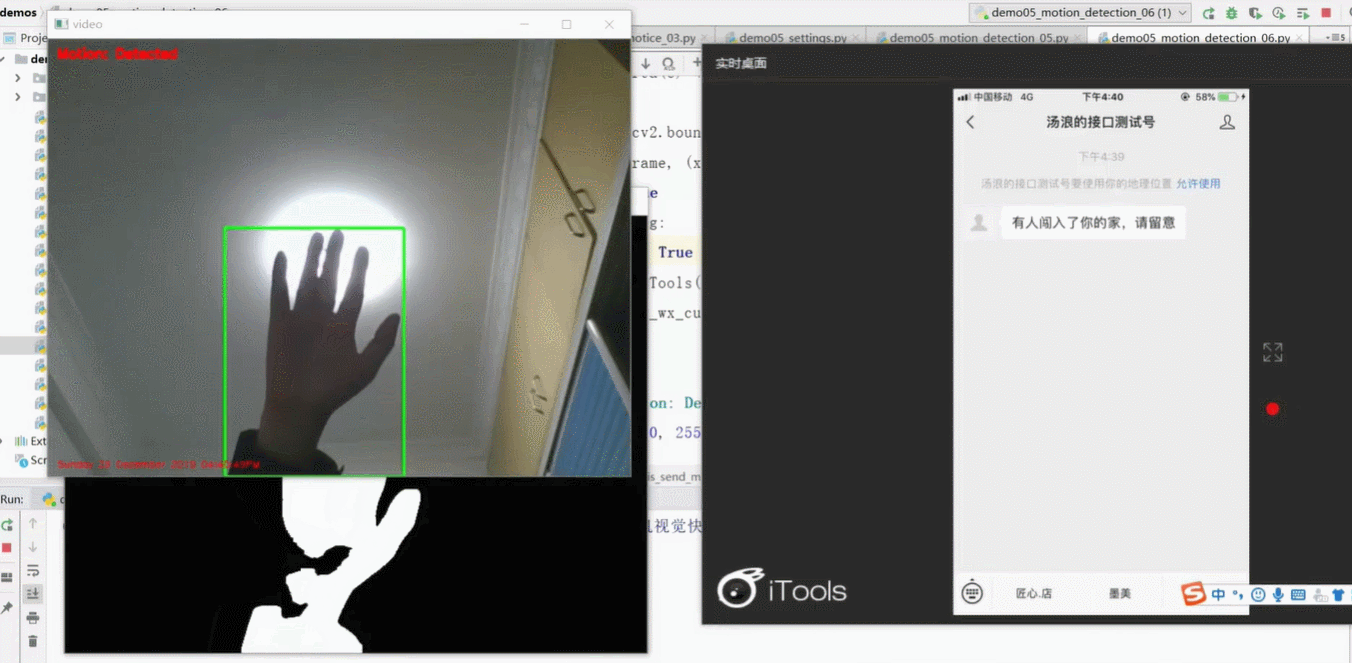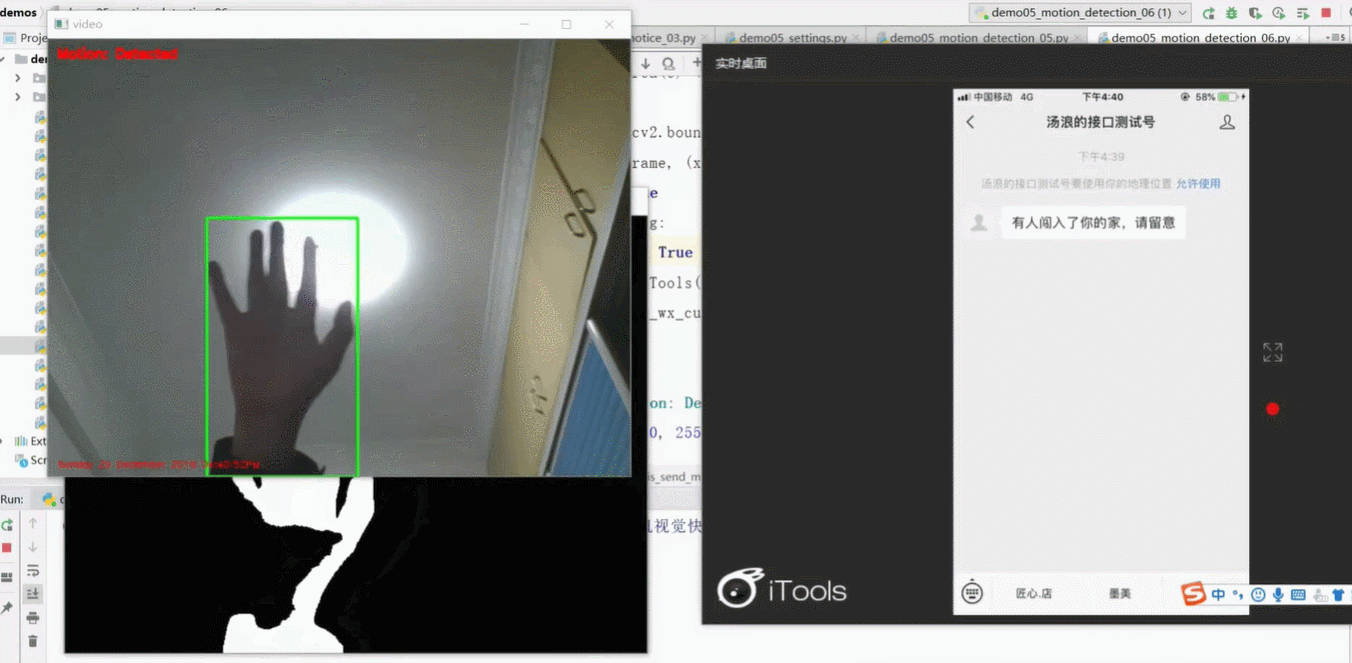
了解需求后,我们讨论第一个问题:如何实现探测+通知?
实现探测:差分法原理:找不同
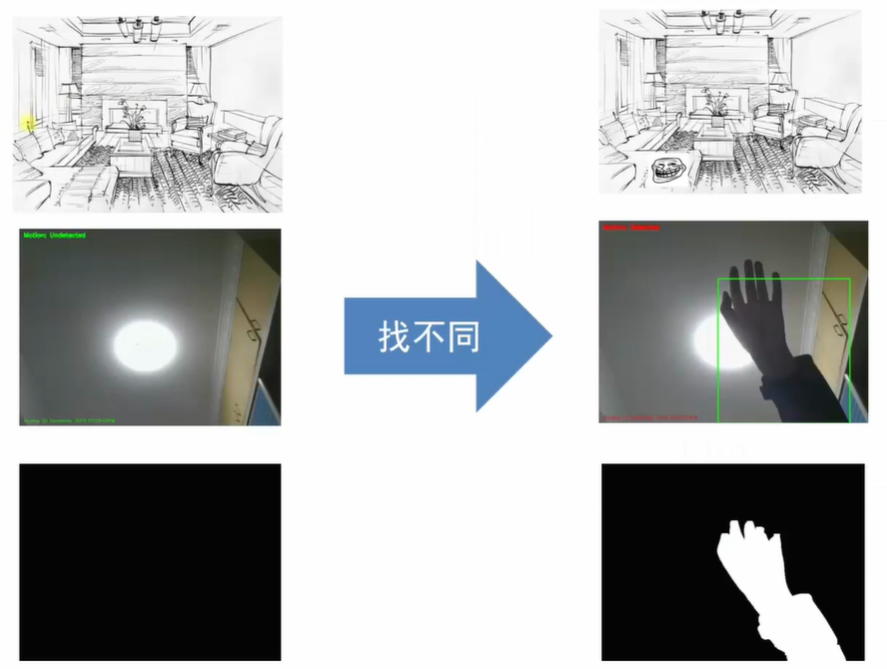
通过灰度图像的像素点寻找差异

如何实现通知?==微信公众平台
运动传感器-实现步骤
实现通知
1.准备微信公众号测试号
1).访 问微信公众平台网站https://mp.weixin.qq.com
2).查看服务号开发文档
3). 开始开发>接口测试号申请>进入微信公众帐号测试号电请系统
4).扫码登录即可
2.安装HTTP库request
pip install requests
3.编码实现
1).获取access_ token
2).发送客服文本消息
import json
import requests #HTTP库
#1. 获取access_token
#https请求方式: GET
https://api.weixin.qq.com/cgi-bin/token?grant_type=client_credential&appid=APPID&secret=APPSECRET
app_id='填写具体'
app_secret='填写具体'
url=f'https://api.weixin.qq.com/cgi-bin/token?grant_type=client_credential&appid={app_id}&secret={app_secret}'
resp=requests.get(url).json()
access_token=resp.get('access_token')
2. 利用access_token发送微信的通知
#http请求方式: POST
https://api.weixin.qq.com/cgi-bin/message/custom/send?access_token=ACCESS_TOKEN
url=f'https://api.weixin.qq.com/cgi-bin/message/custom/send?access_token={access_token}'
open_id='填写具体'
req_data={
"touser":open_id,
"msgtype":"text",
"text":
{
"content":"vernonjsn,有人闯入了您的家"
}
}
req_str=json.dumps(req_data)
req_str=json.dumps(req_data,ensure_ascii=False) #数据转为字符串数据
req_data=req_str.encode('utf-8')
requests.post(url,data=req_data)
requests.post(url,data=json.dumps(ensure_ascii=False).encode('utf-8'))
实现运动传感器+通知的步骤
◆展示拍摄画面及文字等
import cv2
import datetime
camera=cv2.VideoCapture(0) #打开摄像头
while True:
ret,frame=camera.read() #不停地去读取画面
gray_frame=cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY) #获取灰度图像(单通道处理更快)
gray_frame=cv2.GaussianBlur(gray_frame,(25,25),3) #高斯滤波消除噪点,参数:(图像,高斯核,高斯西格玛值)
#填写画面文字
cv2.putText(frame,"Motion : Undetected",(10,20),
cv2.FONT_HERSHEY_SIMPLEX,0.5,(0,255,0),2)
cv2.putText(frame,datetime.datetime.now().strftime("%A %d %B %Y %I:%M:%S%p"),
(10,frame.shape[0]-10),cv2.FONT_HERSHEY_SIMPLEX,
0.35,(0,255,0),1)
cv2.imshow('video',frame) #展示,名字是video
cv2.imshow('diff',gray_frame) #展示灰度图像
key=cv2.waitKey(1) & 0xFFf
if key==ord('q'):
break
camera.release() #释放摄像头资源
cv2.destroyAllWindows() #关闭opencv的窗口
运行结果:
◆得到灰度图像并展示
◆得到差分图像
◆应用差分法,动的地方,画绿色框框
◆如果探测到动的地方则修改文字内容为己探测到,并把文字颜色改为红色
◆在探测到东西的时候发送微信通知,为防止过多骚扰,只发送一一次。
最终代码:
import cv2
import datetime
from demo05_wx_notice_03 import WxTools
from demo06_setting import app_id,app_secret
#==========相比05添加发送微信提示======
camera=cv2.VideoCapture(0) #打开摄像头
background=None
es=cv2.getStructuringElement(cv2.MORPH_ELLIPSE,(5,4)) #使用结构化元素来做形态学膨胀(使图像更加连贯)
is_send_msg=False #默认未发送过通知
while True:
ret,frame=camera.read() #不停地去读取画面
gray_frame=cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY) #获取灰度图像(单通道处理更快)
gray_frame=cv2.GaussianBlur(gray_frame,(25,25),3) #高斯滤波消除噪点,参数:(图像,高斯核,高斯西格玛值)
#求背景图与其他灰度图图像值的差(找不同==差分法)
if background is None:
background=gray_frame
continue
diff=cv2.absdiff(background,gray_frame) #差分法
diff=cv2.threshold(diff,50,255,cv2.THRESH_BINARY)[1] #规定差分值小于50算一样,大于50算不一样;255表示白色,不同地方用白色表示;cv2.THRESH_BINARY,形态学膨胀(优化小的差值,让值更大更好区分)
diff=cv2.dilate(diff,es,iterations=3)
"""
findContours方法:发现图像中有多少个连续移动的物体
参数:diff.copy():拷贝一份diff,防止findContours方法修改了diff原图像影响展示
cv2.RETR_EXTERNAL:外部轮廓
cv2.CHAIN_APPROX_SIMPLE:连续(查找图像中所有连续物体)
"""
contours,hierarchy=cv2.findContours(diff.copy(),cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
#探测图像中所有动的物体,然后去遍历连续不同的物体,判断一下不同物体的大小
#如果不同物体差值大小小于2000忽略不计,如果差异大于200则获取坐标,画框框
is_detected=False
for c in contours:
if cv2.contourArea(c)
视频:https://www.bilibili.com/video/BV1c5411T7GA?p=6&spm_id_from=pageDriver
Original: https://blog.csdn.net/qingxiao__123456789/article/details/123898915
Author: VernonJsn
Title: OpenCV入门实战
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/704725/
转载文章受原作者版权保护。转载请注明原作者出处!