

文章目录
*
– 一、原理及流程
–
+ 1.1 概述
+ 1.2 算法描述
+ 1.3 算法流程
+ 1.4 TF-IDF
– 二、代码实现
–
+ 2.1 代码
+ 2.2 运行及结果
一、原理及流程
1.1 概述
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:eded1ce6-bc76-4f23-825e-670dec4e7c9c
[En]
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:b322c08e-de6f-44d1-8e8e-66c8b09eecda
250,000 张图像 ~ 310亿个图像对
– 每个图相对2秒 匹配 500台并行计算机需要1年才能完成计算
因此使用一种基于Bag-of-words models的Bof,即Bag of features。
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:1b40795c-4108-4dce-b3f5-91276d3e0050
[En]
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:e0dc22cb-64a1-4eb5-af68-b667c39fb640
1.2 算法描述
视觉词袋模型( Bag-of-features )是当前计算机视觉领域中较为常用的图像表示方法。
视觉词袋模型来源于词袋模型(Bag-of-words),词袋模型最初被用在文本分类中,将文档表示成特征矢量。它的基本思想是假定 对于一个文本,忽略其词序和语法、句法, 仅仅将其看做是一些词汇的集合, 而文本中的每个词汇都是独立的。简单说就是讲每篇文档都看成一个袋子 (因为里面装的都是词汇,
所以称为词袋,Bag of words即因此而来)然后看这个袋子里装的都是些什么词汇,将其分类。
如果文档中猪、 马、牛、羊、山谷、土地、拖拉机这样的词汇多些,而银行、大厦、汽车、公园这样的词汇少些, 我们就倾向于判断它是一 篇描绘乡村的文档,而不是描述城镇的。
Bag of Feature也是借鉴了这种思路,只不过在图像中,我们抽出的不再是一个个word, 而是 图像的关键特征Feature,所以研究人员将它更名为Bag of Feature.Bag of Feature在检索中的算法流程和分类几乎完全一样,唯一的区别在于,对于原始的BOF特征,也就是直方图向量,我们引入TF_IDF权值。
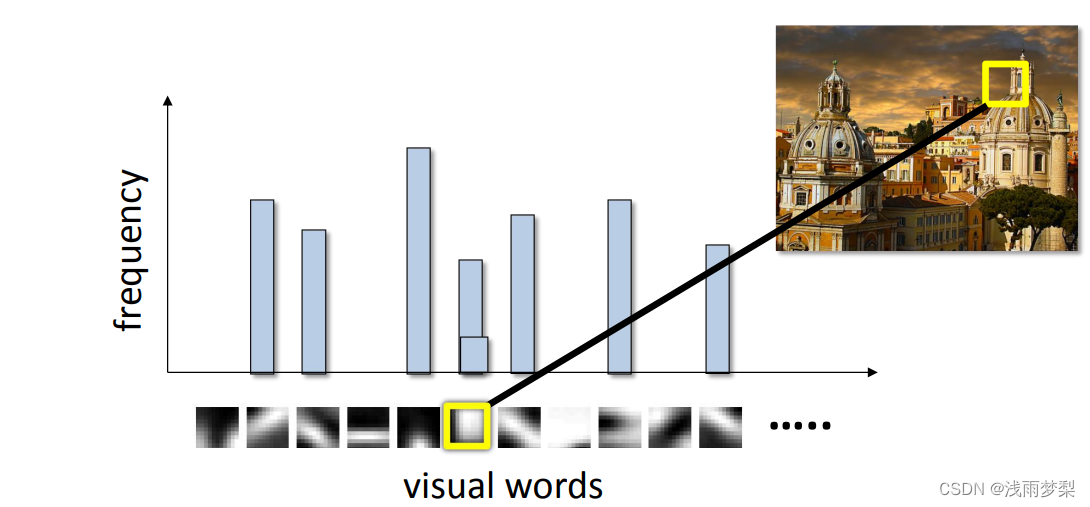

; 1.3 算法流程
1,特征提取
提取图像的基本特征

2,学习 “视觉词典(visual vocabulary)

[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:aabac542-f61b-4a5f-8bdb-dc7944da5294
[En]
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:6eb82f41-1d1a-414a-b9ec-d4ccea7c398e
可以使用K-means 聚类算法


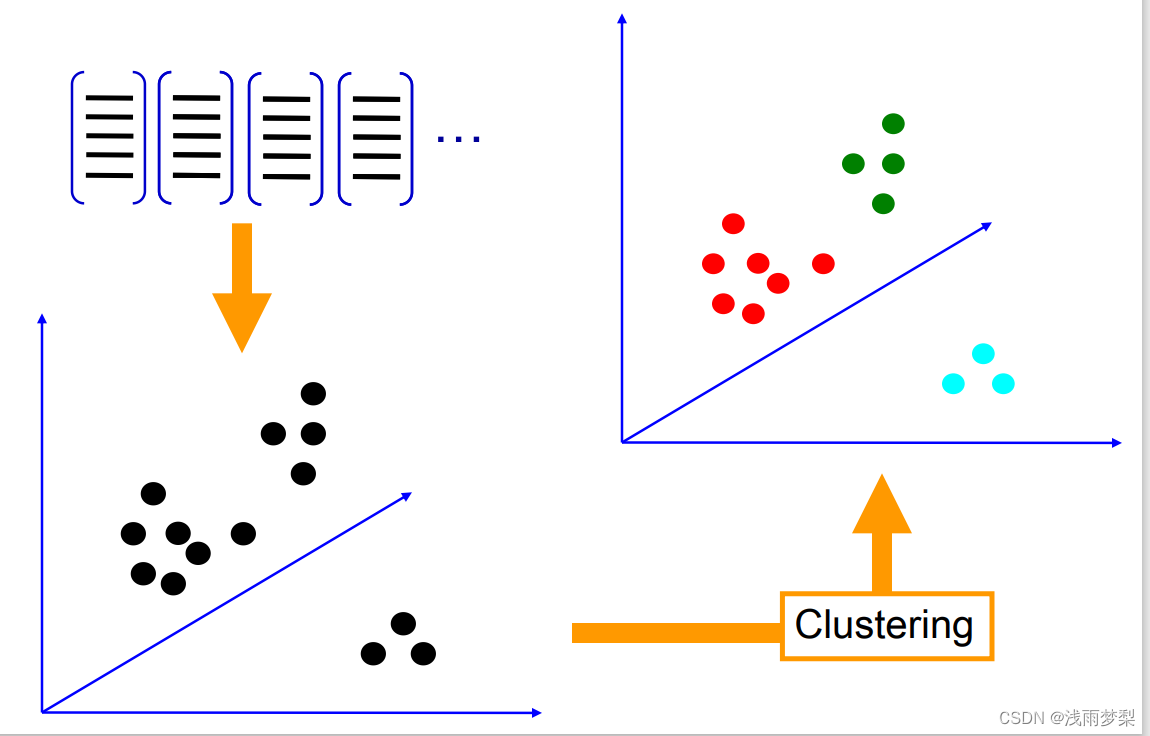
3,针对输入特征集,根据视觉词典进行量化

4,把输入图像转化成视觉单词(visual words)的频率直方图
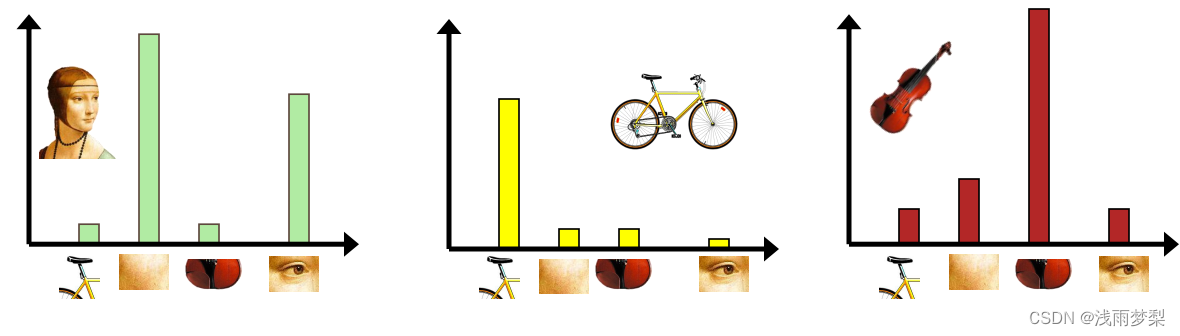
1.4 TF-IDF
根据特征投票应该赋予相应的权重。这些权重的设置就是TF-IDF
公式如下:
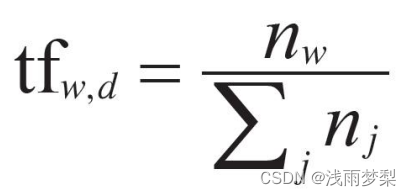

如果一个 关键词只在很少的网页中出现,我们通过它就 容易锁定搜索目标,它的 权重也就应该 大。反之如果一个词在大量网页中出现,我们看到它仍然 不是很清楚要找什么内容,因此它应该 小
; 二、代码实现
2.1 代码
1、给训练图像集生成词汇字典。生成字典之前要先提取图像的 SIFT特征点
import pickle
from PCV.imagesearch import vocabulary
from PCV.tools.imtools import get_imlist
from PCV.localdescriptors import sift
imlist = get_imlist('E:/CV/img/c6/')
nbr_images = len(imlist)
featlist = [imlist[i][:-3]+'sift' for i in range(nbr_images)]
for i in range(nbr_images):
sift.process_image(imlist[i], featlist[i])
voc = vocabulary.Vocabulary('ukbenchtest')
voc.train(featlist, 1000, 10)
with open('E:/CV/img/c6/vocabulary.pkl', 'wb') as f:
pickle.dump(voc, f)
print('vocabulary is:', voc.name, voc.nbr_words)
2、将图像添加到数据库
import pickle
from PCV.imagesearch import imagesearch
from PCV.localdescriptors import sift
import sqlite3
from PCV.tools.imtools import get_imlist
imlist = get_imlist('E:/CV/img/c6/')
nbr_images = len(imlist)
featlist = [imlist[i][:-3] + 'sift' for i in range(nbr_images)]
with open('E:/CV/img/c6/vocabulary.pkl', 'rb') as f:
voc = pickle.load(f)
indx = imagesearch.Indexer('testImaAdd.db', voc)
indx.create_tables()
for i in range(nbr_images)[:17]:
locs, descr = sift.read_features_from_file(featlist[i])
indx.add_to_index(imlist[i], descr)
indx.db_commit()
con = sqlite3.connect('testImaAdd.db')
print(con.execute('select count (filename) from imlist').fetchone())
print(con.execute('select * from imlist').fetchone())
3、图像检索测试
import pickle
from PCV.localdescriptors import sift
from PCV.imagesearch import imagesearch
from PCV.geometry import homography
from PCV.tools.imtools import get_imlist
imlist = get_imlist('E:/CV/img/c6/')
nbr_images = len(imlist)
featlist = [imlist[i][:-3] + 'sift' for i in range(nbr_images)]
with open('E:/CV/img/c6/vocabulary.pkl', 'rb') as f:
voc = pickle.load(f)
src = imagesearch.Searcher('testImaAdd.db', voc)
q_ind = 3
nbr_results = 5
res_reg = [w[1] for w in src.query(imlist[q_ind])[:nbr_results]]
print('top matches (regular):', res_reg)
q_locs, q_descr = sift.read_features_from_file(featlist[q_ind])
fp = homography.make_homog(q_locs[:, :2].T)
model = homography.RansacModel()
rank = {}
for ndx in res_reg[1:]:
locs, descr = sift.read_features_from_file(featlist[ndx])
matches = sift.match(q_descr, descr)
ind = matches.nonzero()[0]
ind2 = matches[ind]
tp = homography.make_homog(locs[:, :2].T)
try:
H, inliers = homography.H_from_ransac(fp[:, ind], tp[:, ind2], model, match_theshold=4)
except:
inliers = []
rank[ndx] = len(inliers)
sorted_rank = sorted(rank.items(), key=lambda t: t[1], reverse=True)
res_geom = [res_reg[0]] + [s[0] for s in sorted_rank]
print('top matches (homography):', res_geom)
imagesearch.plot_results(src, res_reg[:8])
imagesearch.plot_results(src, res_geom[:8])
2.2 运行及结果
1、图像及生成的sift特征点如下:
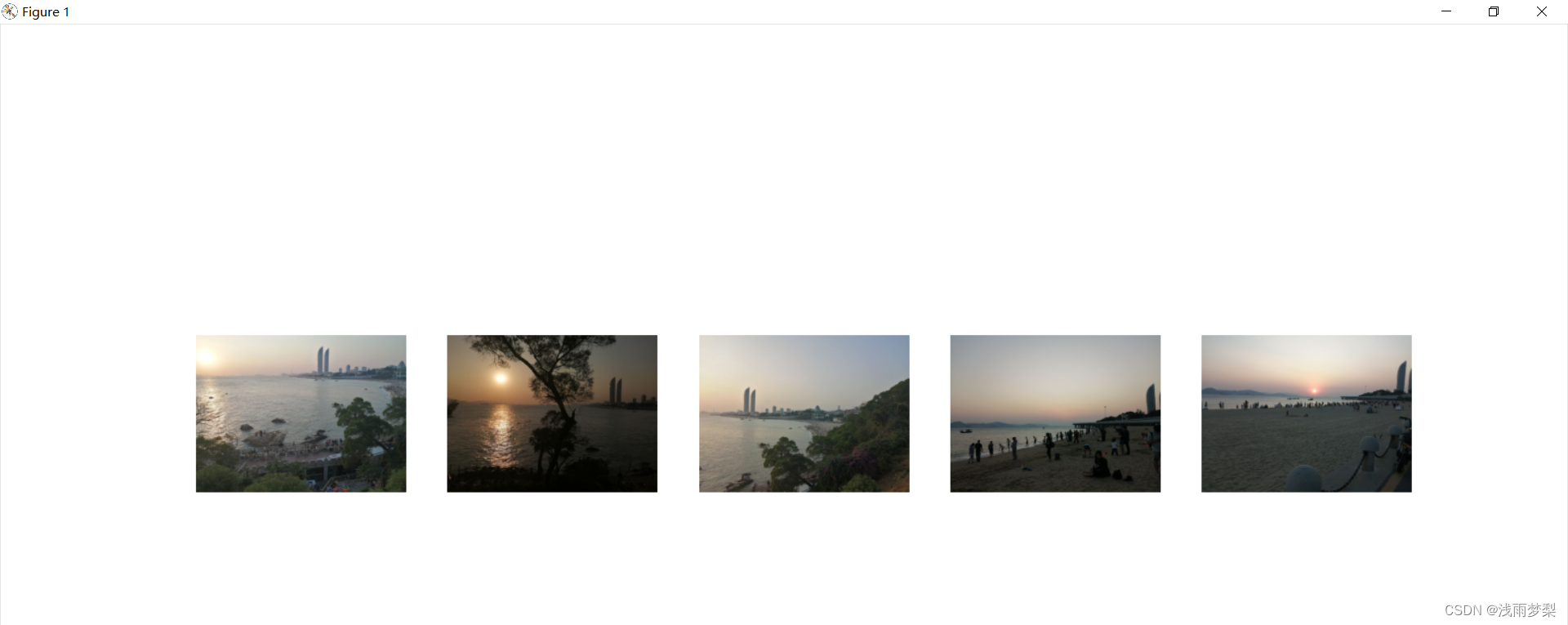
2、查询结果:查询图像在最左边,后面都是按图像列表检索的前5幅图像。
Original: https://blog.csdn.net/qq_45749702/article/details/125174673
Author: 浅雨梦梨
Title: 计算机视觉(五)图像检索与识别
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/563122/
转载文章受原作者版权保护。转载请注明原作者出处!