

四. 神经网络与误差反向传播
1. 人工神经网络的架构
1.1 什么是神经网络
- 神经网络:大量(结构简单,功能接近的)神经元节点按一定体系架构连接成的网状结构
- 神经网络的作用:分类、模式识别、连续值预测,建立输入与输出的映射关系
1.2 人工神经元
如图所示:
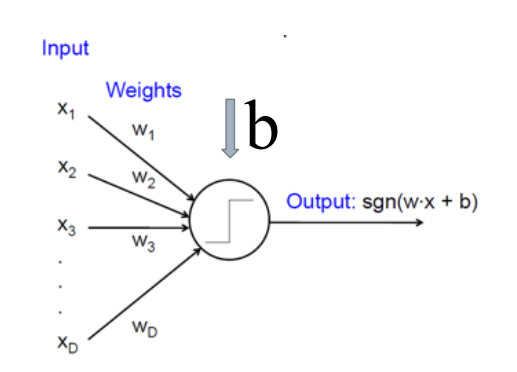

每个神经元都是一个结构相似的独立单元,它接受前一层传来的数据,并将这些数据的加权和输入非线性作用函数中,最后将非线性作用函数的输出结果传递给后一层。
非线性函数f f f,称为激活函数:
y = f ( w t x ) = f ( ∑ i = 1 d w i x i ) y = f(w^tx)=f(\sum_{i=1}^{d}w_ix_i)y =f (w t x )=f (i =1 ∑d w i x i )
; 1.3 激活函数
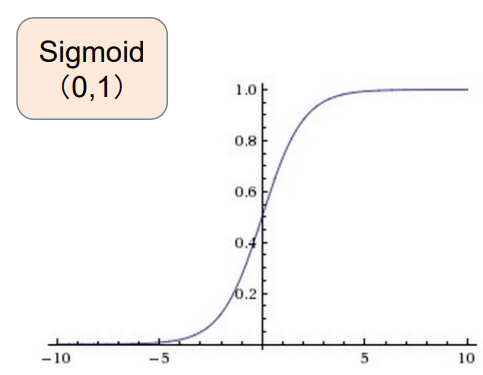
三个常见的激活函数
- Sigmoid
σ ( x ) = 1 1 + e − x \sigma(x)=\frac{1}{1+e^-x}σ(x )=1 +e −x 1
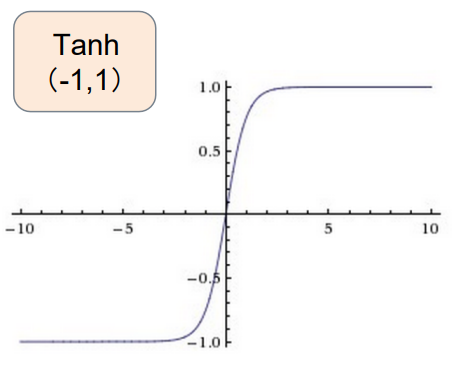
- Tanh(x)
t a n h ( x ) = e x − e − x e x + e − x = 2 σ ( 2 x ) − 1 tanh(x)=\frac{e^x-e^{-x}}{e^x+e^{-x}}=2\sigma(2x)-1 t anh (x )=e x +e −x e x −e −x =2 σ(2 x )−1
- Relu
f ( x ) = m a x ( 0 , x ) f(x)=max(0,x)f (x )=ma x (0 ,x )
1.4 简单的求导基础
链式求导:
( f ( g ( x ) ) ) ′ = f ′ ( g ( x ) ) g ′ ( x ) (f(g(x)))’=f'(g(x))g'(x)(f (g (x )))′=f ′(g (x ))g ′(x )
写成另一种形式:
d y d x = d y d z ⋅ d z d x \frac{dy}{dx}=\frac{dy}{dz}\cdot\frac{dz}{dx}d x d y =d z d y ⋅d x d z
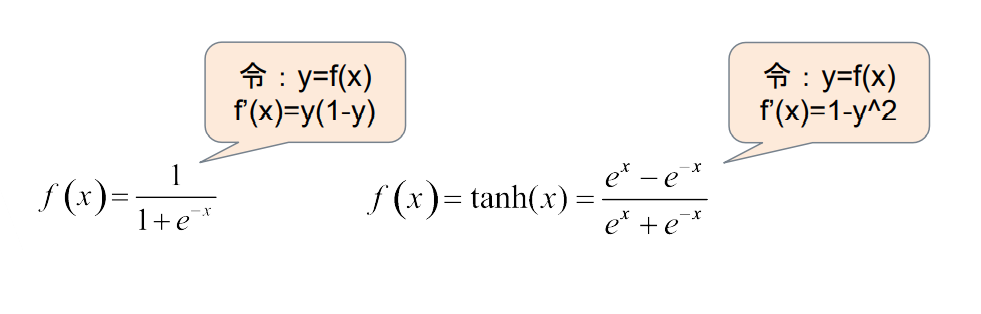
; 1.5 人工神经网络
- 基础神经网络
- 神经元
- 输入向量x x x
- 权重向量w w w
- 偏置标量b b b
- 激活函数
- 浅网络
- 3~5层
- 梯度下降
- BP后向传播
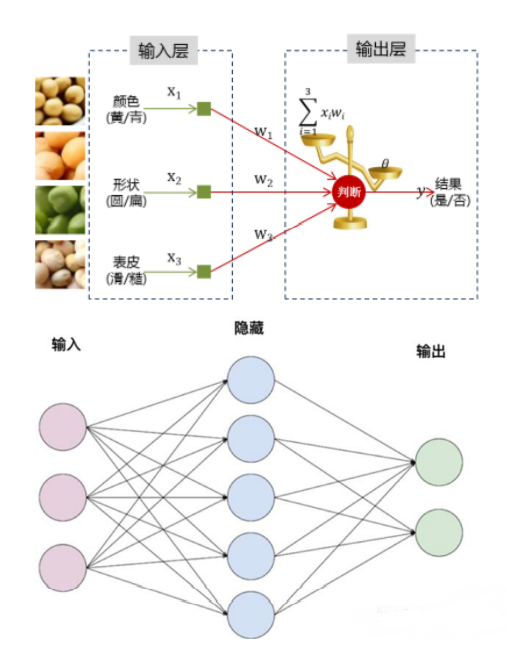
1.6 层的理解
层实现了输入控件到输出空间的线性或非线性变换。
我们举个例子,假设输入是碳原子和氧原子,我们输出三个变量。我们可以通过改变权重的值获得若干个不同物质。
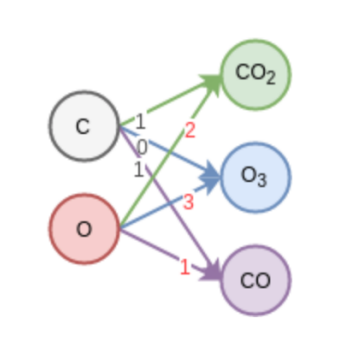
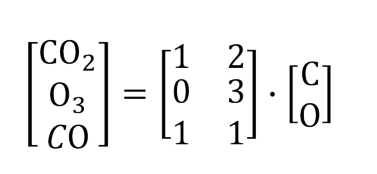
右侧的节点数决定了想要获得多少种不同的新物质。
; 1.7 前向(前馈)神经网络
FNN (Feedforward Neural Networks)
- 前馈神经网络是人工神经网络的一种,各神经元从输入层开始,接收前一级的输出,并输出到下一级,直至输出层。整个神经网络中无反馈,可用一个有向无环图表示。
- 前馈神经网络采用一种单项多层结构。其中每一层包含若干个神经元,同一层的神经元之间没有互相连接,层间信息的传送只沿一个方向进行。
- 第一层为输入层,第二层为隐藏层,最后一层为输出层。其中隐藏层可以是一层也可以是多层。
2. 目标函数与梯度下降
2.1 目标函数
前面介绍了前馈神经网络,那我们的前馈神经网络的目标是什么呢?
- 对于一系列训练样本x x x
- 期望输出t = ( t 1 , … , t c ) t=(t_1,\dots,t_c)t =(t 1 ,…,t c ),网络实际输出z = ( z 1 , … , z c ) z=(z_1,\dots,z_c)z =(z 1 ,…,z c )
那此时我们的目标函数就是:
J ( w ) = 1 2 ∣ ∣ t − z ∣ ∣ 2 = 1 2 ∑ k = 1 c ( t k − z k ) 2 J(w)=\frac{1}{2}||t-z||^2=\frac{1}{2}\sum_{k=1}^{c}(t_k-z_k)^2 J (w )=2 1 ∣∣t −z ∣∣2 =2 1 k =1 ∑c (t k −z k )2
那我们如何计算目标函数的最小值呢?
2.2 Delta学习规则
Delta学习规则是一种有监督学习算法,该算法根据神经元的实际输出与期望输出差别来调整连接权,其数学表达式如下:
△ W i j = a ∗ ( d i − y i ) x j ( t ) \triangle W_{ij}=a\ast(d_i-y_i)x_j(t)△W ij =a ∗(d i −y i )x j (t )
其中:
- △ W i j \triangle W_{ij}△W ij 表示神经元j j j到神经元i i i的连接权重增量
- d j d_j d j 是神经元i i i的期望输出
- y i y_i y i 是神经元i i i的实际输出
- x j x_j x j 表示神经元j j j的状态
- a a a表示学习速度的常数
2.3 梯度下降
大多数机器学习算法和深度学习算法都涉及到的优化,优化是指通过改变x x x来使某个函数f ( x ) f(x)f (x )最大化或者最小化,通常以最小化f ( x ) f(x)f (x )指代大多数问题。
我们把需要最大化或者最小化的函数称为目标函数或准则。当我们要将其最小化时,我们把它称为代价函数,损失函数或误差函数。
我们假设一个损失函数用于举例说明。
J ( θ ) = 1 2 ∑ i = 1 m ( h θ ( x ) − y ) 2 J(\theta)=\frac{1}{2}\sum_{i=1}^m(h_\theta(x)-y)^2 J (θ)=2 1 i =1 ∑m (h θ(x )−y )2
其中:
h θ ( x ) = θ 0 + θ 1 x 1 + θ 2 x 2 + ⋯ + θ n x n h_\theta(x)=\theta_0+\theta_1x_1+\theta_2x_2+\cdots+\theta_nx_n h θ(x )=θ0 +θ1 x 1 +θ2 x 2 +⋯+θn x n
然后使它最小化。
在高维的情况下,损失函数求导之后等于0,这个方程组太难求解,也有可能不可解,所以一般情况不使用这个方法
我们知道曲面上方向导数的最大值方向就代表了梯度的方向
方向导数:
∂ Z ∂ l ⃗ ∣ ( x 0 , y 0 ) = lim t → 0 1 t [ f ( x 0 + t cos α , y 0 + t cos β ) − f ( x 0 , y 0 ) ] \frac{\partial Z}{\partial\vec{l}}\mid_{(x_0,y_0)}=\lim_{t\to0}\frac{1}{t}[f(x_0+t\cos\alpha,y_0+t\cos\beta)-f(x_0,y_0)]∂l ∂Z ∣(x 0 ,y 0 )=t →0 lim t 1 [f (x 0 +t cos α,y 0 +t cos β)−f (x 0 ,y 0 )]
∂ Z ∂ l ⃗ ∣ ( x 0 , y 0 ) = f x ( x 0 , y 0 ) cos α + f y ( x 0 , y 0 ) cos β \frac{\partial Z}{\partial\vec{l}}\mid_{(x_0,y_0)}=f_x(x_0,y_0)\cos\alpha+f_y(x_0,y_0)\cos\beta ∂l ∂Z ∣(x 0 ,y 0 )=f x (x 0 ,y 0 )cos α+f y (x 0 ,y 0 )cos β
那我们应该沿着梯度的反方向进行权重的更新,可以有效地找到全局的最优解,θ i \theta_i θi 的更新过程可以描述为:
θ j : = θ j − α ∂ ∂ θ j J ( θ ) \theta_j:=\theta_j-\alpha\frac{\partial}{\partial\theta_j}J(\theta)θj :=θj −α∂θj ∂J (θ)
∂ ∂ θ j J ( θ ) = ∂ ∂ θ j ⋅ 1 2 ( h θ ( x ) − y ) 2 = ( h θ ( x ) − y ) ⋅ ∂ ∂ θ j ( h θ ( x ) − y ) = ( h θ ( x ) − y ) ⋅ ∂ ∂ θ j ( ∑ i = 1 m θ i x i − y ) = ( h θ ( x ) − y ) x j \begin{aligned} \frac{\partial}{\partial\theta_j}J(\theta)&=\frac{\partial}{\partial\theta_j}\cdot\frac{1}{2}(h_\theta(x)-y)^2\ &=(h_\theta(x)-y)\cdot\frac{\partial}{\partial\theta_j}(h_\theta(x)-y)\ &=(h_\theta(x)-y)\cdot\frac{\partial}{\partial\theta_j}(\sum_{i=1}^{m}\theta_ix_i-y)\ &=(h_\theta(x)-y)x_j \end{aligned}∂θj ∂J (θ)=∂θj ∂⋅2 1 (h θ(x )−y )2 =(h θ(x )−y )⋅∂θj ∂(h θ(x )−y )=(h θ(x )−y )⋅∂θj ∂(i =1 ∑m θi x i −y )=(h θ(x )−y )x j
换一个角度来想,损失函数中一般有两种参数,一种是控制输入信号量的权重w w w,另一种是调整函数与真实值距离的偏差b b b,那我们要做的就是通过梯度下降的方法,不断地调整w w w与b b b,使得损失函数值越来越小。
通过计算梯度我们可以知道w w w的移动方向,那我们接下来就要知道应该前进多少,这里我们用到学习率(Learning Rate)这个概念,通过学习率可以计算前进的距离。
我们用w i w_i w i 表示初始权重,w i + 1 w_{i+1}w i +1 表示更新后的权重,α \alpha α表示学习率。
w i + 1 = w i − α ⋅ d L d w i w_{i+1}=w_i-\alpha\cdot\frac{dL}{dw_i}w i +1 =w i −α⋅d w i d L
梯度下降中重复此式,直至损失函数收敛不变,在这里α \alpha α值过大,有可能会错过损失函数最小值,α \alpha α过小,会导致迭代次数过多,耗费过多时间。以下是全部过程。
- for i=0 → \to → 训练数据个数
- 计算第i个训练数据的权重w w w和偏差b b b相对于损失函数的梯度。在这里得到每一个训练数据的权重和偏差的梯度值。
- 计算所有训练数据权重w w w的梯度总和
- 计算所有训练数据偏差b b b的梯度总和
- 上面的计算结束之后
- 使用上面2,3的值计算所有样本w , b w,b w ,b的梯度的平均值
- 使用下面的式子,更新每个样本的w w w与b b b w i + 1 = w i − α × d L d w i b i + 1 = b i − α × d L d b i w_{i+1}=w_i-\alpha\times\frac{dL}{dw_i}\ b_{i+1}=b_i-\alpha\times\frac{dL}{db_i}w i +1 =w i −α×d w i d L b i +1 =b i −α×d b i d L
- 重复上面的步骤直至损失函数收敛不变
2.4 梯度下降的衍生
- 小批量样本梯度下降(Mini Batch GD)
这个算法在每次梯度下降的过程中,只选取一部分的样本数据进行梯度计算,比如整体样本百分之一的数据。在数据量较大的项目中,可以明显地减少梯度计算的时间。
- 随机梯度下降(Stochastic GD)
随机梯度下降算法之随机抽取一个样本进行梯度计算,由于每次梯度下降迭代只计算一个样本的梯度,因此运算时间会比MGD还少很多,但由于训练数据量太小,因此下降路径容易受到训练数据自身噪音的影响。
3. 误差反向传播
我们先来回顾一下梯度下降。
下图是一个表示参数w w w与目标函数J ( w ) J(w)J (w )的关系图,红色部分是表示J ( w ) J(w)J (w )有着比较高的取值,需要能够让J ( w ) J(w)J (w )的值尽量的低。也就是深蓝色的部分。w 1 , w 2 w_1,w_2 w 1 ,w 2 表示w w w向量的两个维度。
先确定一个初始点,将w w w按照梯度下降的方向进行调整,这样就会使得J ( w ) J(w)J (w )向着更低的方向进行变化,如图所示,算法的结束将是在w w w下降到无法继续下降为止(不一定是无法下降,有时候也会停止在局部最低点或是其他情况)。
根据前面的介绍,式子如下:
w m + 1 = w m + △ w m = w m − α ∂ J ∂ w w_{m+1}=w_m+\triangle w_m=w_m-\alpha\frac{\partial J}{\partial w}w m +1 =w m +△w m =w m −α∂w ∂J

; 3.1 输出层权重改变量
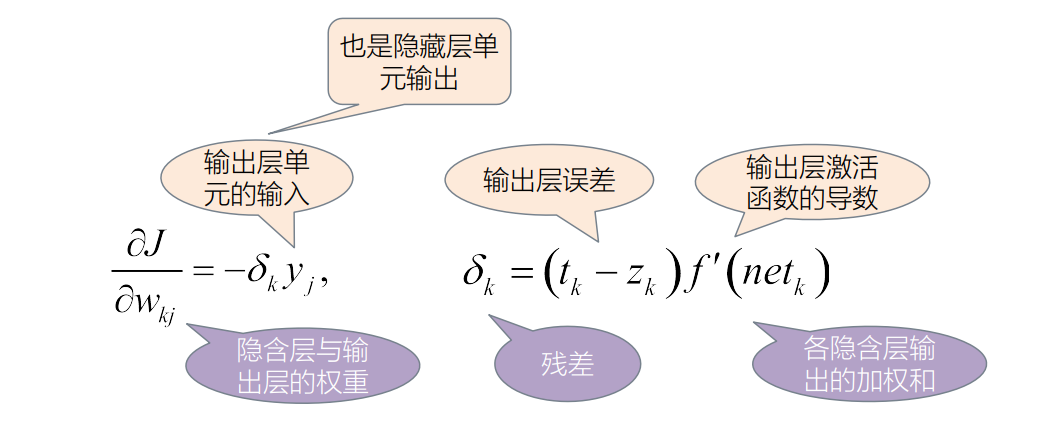
输出层的权重改变量其实就是一个偏导数的表达:
∂ J ∂ w k j = ∂ J ∂ n e t k ⋅ ∂ n e t k ∂ w k j \frac{\partial J}{\partial w_{kj}}=\frac{\partial J}{\partial net_k}\cdot\frac{\partial net_k}{\partial w_{kj}}∂w kj ∂J =∂n e t k ∂J ⋅∂w kj ∂n e t k
那么这里的∂ J ∂ w k j \frac{\partial J}{\partial w_{kj}}∂w kj ∂J 如何理解呢?
w k j w_{kj}w kj 是隐藏层到输出层的权重,那么目标函数对w k j w_{kj}w kj 的偏导也就是隐藏层权重的改变量,这里先不考虑学习率也就是步长,就先直接将这个偏导数当作改变量。
这里:
J ( w ) = 1 2 ∣ ∣ t − z ∣ ∣ 2 = 1 2 ∑ k = 1 c ( t k − z k ) 2 J(w)=\frac{1}{2}||t-z||^2=\frac{1}{2}\sum_{k=1}^c(t_k-z_k)^2 J (w )=2 1 ∣∣t −z ∣∣2 =2 1 k =1 ∑c (t k −z k )2
w k j w_{kj}w kj 在这里表示的并不是很明显,那我们就考虑通过一个中间函数使用链式求导法则将其关联起来。隐藏层与输出层的图示如下:
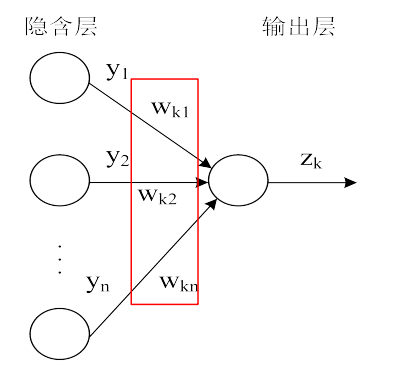
其中输出层的总输入为n e t k net_k n e t k
n e t k = ∑ j = 1 n H w k j y j net_k = \sum_{j=1}^{n_H}w_{kj}y_j n e t k =j =1 ∑n H w kj y j
那么:
∂ n e t k ∂ w k j = y j \frac{\partial net_k}{\partial w_{kj}}=y_j ∂w kj ∂n e t k =y j
我们知道了其中的一部分,那我们继续来看另外一部分,目标函数对n e t k net_k n e t k 求偏导,关系还不是很直观,我们再使用输出将其链接起来。输出层的输入为n e t k net_k n e t k ,输出为z k z_k z k ,他们两个的关系就是一个激活函数,所以通过输出层的输出可以很好的将目标函数与输出层的输入链接起来。
∂ J ∂ n e t k = ∂ J ∂ z k ⋅ ∂ z k ∂ n e t k = − ( t k − z k ) ⋅ f ′ ( n e t k ) \frac{\partial J}{\partial net_k}=\frac{\partial J}{\partial z_k}\cdot\frac{\partial z_k}{\partial net_k}=-(t_k-z_k)\cdot f'(net_k)∂n e t k ∂J =∂z k ∂J ⋅∂n e t k ∂z k =−(t k −z k )⋅f ′(n e t k )
令:δ k = ( t k − z k ) f ′ ( n e t k ) \delta_k=(t_k-z_k)f'(net_k)δk =(t k −z k )f ′(n e t k )
∂ J ∂ w k j = − ( t k − z k ) ⋅ f ′ ( n e t k ) ⋅ y j = − δ k y j \frac{\partial J}{\partial w_{kj}}=-(t_k-z_k)\cdot f'(net_k)\cdot y_j=-\delta_ky_j ∂w kj ∂J =−(t k −z k )⋅f ′(n e t k )⋅y j =−δk y j
在这里δ k \delta_k δk 就是输出层产生的残差。
3.2 隐藏层权重改变量
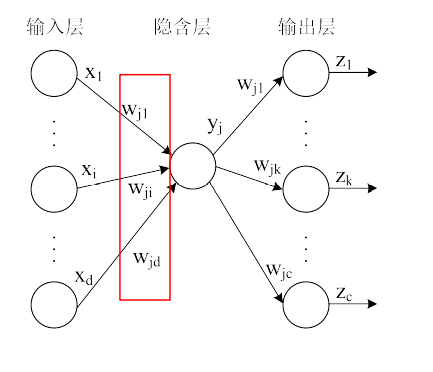
隐藏层的权重改变量自然就是目标函数对于隐藏层的输入的偏导了。
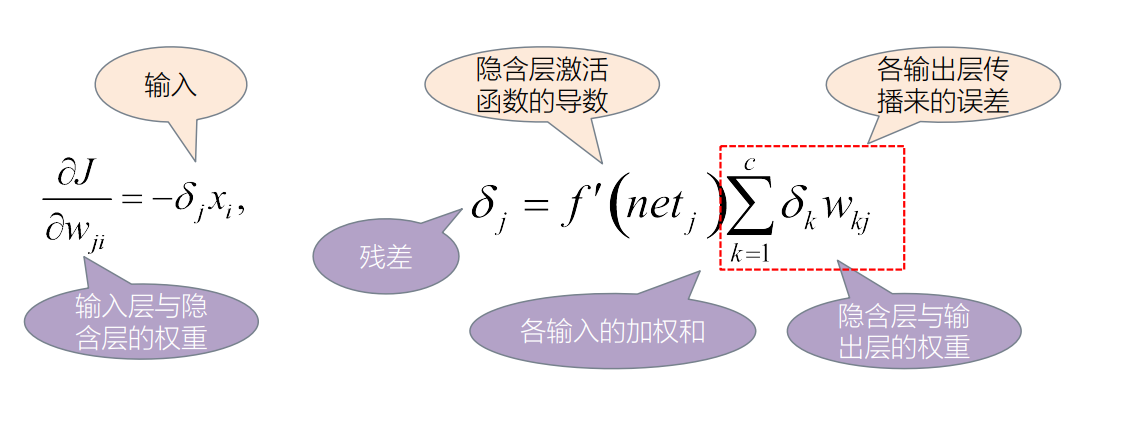
∂ J ∂ w j i = ∂ J ∂ y j ⋅ ∂ y j ∂ n e t j ⋅ ∂ n e t j ∂ w j i \frac{\partial J}{\partial w_{ji}}=\frac{\partial J}{\partial y_j}\cdot\frac{\partial y_j}{\partial net_j}\cdot\frac{\partial net_j}{\partial w_{ji}}∂w ji ∂J =∂y j ∂J ⋅∂n e t j ∂y j ⋅∂w ji ∂n e t j
其中y j y_j y j 为隐藏层单元输出,n e t j net_j n e t j 为隐藏层单元总输入。
n e t j = ∑ m = 1 d w j m x m net_j=\sum_{m=1}^d w_{jm}x_m n e t j =m =1 ∑d w jm x m
那隐藏层单元输出与隐藏层单元总输入之间的关系其实就是加上了一层激活函数,如下:
∂ y j ∂ n e t j = f ′ ( n e t j ) \frac{\partial y_j}{\partial net_j}=f'(net_j)∂n e t j ∂y j =f ′(n e t j )
最后一项隐藏层单元总输入与权重的关系可以在表达式中很明显地表达出来,如下:
∂ n e t j ∂ w j i = ∂ ∂ w j i ( ∑ m = 1 d w j m x m ) = x i \frac{\partial net_j}{\partial w_{ji}}=\frac{\partial}{\partial w_{ji}}(\sum_{m=1}^{d}w_{jm}x_m)=x_i ∂w ji ∂n e t j =∂w ji ∂(m =1 ∑d w jm x m )=x i
因为第一项目标函数与隐藏层单元输出的关系比较复杂所以放到最后来计算。
n e t k = ∑ j = 1 n H w k j y j net_k=\sum_{j=1}^{n_H}w_{kj}y_j n e t k =j =1 ∑n H w kj y j
∂ J ∂ y j = ∂ ∂ y j [ 1 2 ∑ k = 1 c ( t k − z k ) 2 ] = − ∑ k = 1 c ( t k − z k ) ∂ z k ∂ y j = − ∑ k = 1 c ( t k − z k ) ⋅ ∂ z k ∂ n e t k ⋅ ∂ n e t k ∂ y j = − ∑ k = 1 c ( t k − z k ) f ′ ( n e t k ) w k j \begin{aligned} \frac{\partial J}{\partial y_j}&=\frac{\partial}{\partial y_j}[\frac{1}{2}\sum_{k=1}^{c}(t_k-z_k)^2]\ &=-\sum_{k=1}^{c}(t_k-z_k)\frac{\partial z_k}{\partial y_j}\ &=-\sum_{k=1}^{c}(t_k-z_k)\cdot\frac{\partial z_k}{\partial net_k}\cdot\frac{\partial net_k}{\partial y_j}\ &=-\sum_{k=1}^{c}(t_k-z_k)f'(net_k)w_{kj} \end{aligned}∂y j ∂J =∂y j ∂[2 1 k =1 ∑c (t k −z k )2 ]=−k =1 ∑c (t k −z k )∂y j ∂z k =−k =1 ∑c (t k −z k )⋅∂n e t k ∂z k ⋅∂y j ∂n e t k =−k =1 ∑c (t k −z k )f ′(n e t k )w kj
那么:
∂ J ∂ w j i = − [ ∑ k = 1 c ( t k − z k ) f ′ ( n e t k ) w k j ] f ′ ( n e t j ) x i \frac{\partial J}{\partial w_{ji}}=-[\sum_{k=1}^{c}(t_k-z_k)f'(net_k)w_{kj}]f'(net_j)x_i ∂w ji ∂J =−[k =1 ∑c (t k −z k )f ′(n e t k )w kj ]f ′(n e t j )x i
这里我们令:
δ j = f ′ ( n e t j ) ∑ k = 1 c δ k w k j \delta_j=f'(net_j)\sum_{k=1}^{c}\delta_kw_{kj}δj =f ′(n e t j )k =1 ∑c δk w kj
那么:
∂ J ∂ w j i = − δ j x i \frac{\partial J}{\partial w_{ji}}=-\delta_jx_i ∂w ji ∂J =−δj x i
输出层与隐藏层的误差反向传播总结一下,如下图所示:
输出层:
隐藏层:
; 3.3 误差传播迭代公式
输出层与隐藏层的误差传播公式可以统一为:
- 权重增量 = -1 × \times ×学习步长× \times ×目标函数对权重的偏导
- 目标函数对权重的偏导数 = -1 × \times ×残差× \times ×当前层的输入
- 残差=当前层激活函数的导数× \times ×上层反传来的误差
- 上层反传来的误差= 上层残差的加权和
隐藏层的误差反向传播总结一下,如下图所示:
输出层:
[外链图片转存中…(img-oPPeWMR2-1665628829586)]
隐藏层:
[外链图片转存中…(img-4cxYHaj0-1665628829586)]
3.3 误差传播迭代公式
输出层与隐藏层的误差传播公式可以统一为:
- 权重增量 = -1 × \times ×学习步长× \times ×目标函数对权重的偏导
- 目标函数对权重的偏导数 = -1 × \times ×残差× \times ×当前层的输入
- 残差=当前层激活函数的导数× \times ×上层反传来的误差
- 上层反传来的误差= 上层残差的加权和
Original: https://blog.csdn.net/CavalierJHC/article/details/127296766
Author: CavalierJHC
Title: OpenCV笔记-神经网络与反向传播
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/703315/
转载文章受原作者版权保护。转载请注明原作者出处!