

Bart模型应用实例及解析(一)————基于波士顿房价数据集的回归模型
- 前言
* - 一、数据集
– - 二、完整代码
- 三、代码运行结果及解析
– - 特别声明
前言
这里是在实战中使用Bart模型对数据进行建模及分析,如果有读者对如何建模以及建模函数的参数不了解,对建模后的结果里的参数不清楚的话,可以参考学习作者前面两篇文章内容。以便更好地理解模型、建模过程及思想。
R bartMachine包内bartMachine函数参数详解
https://blog.csdn.net/qq_35674953/article/details/115774921
BartMachine函数建模结果参数解析
https://blog.csdn.net/qq_35674953/article/details/115804662
提示:以下是本篇文章正文内容
一、数据集
1、数据集的获取
链接:https://pan.baidu.com/s/1bHUJpJqjN2lQ3N3DhrY_MQ
提取码:9prb
数据部分截图:
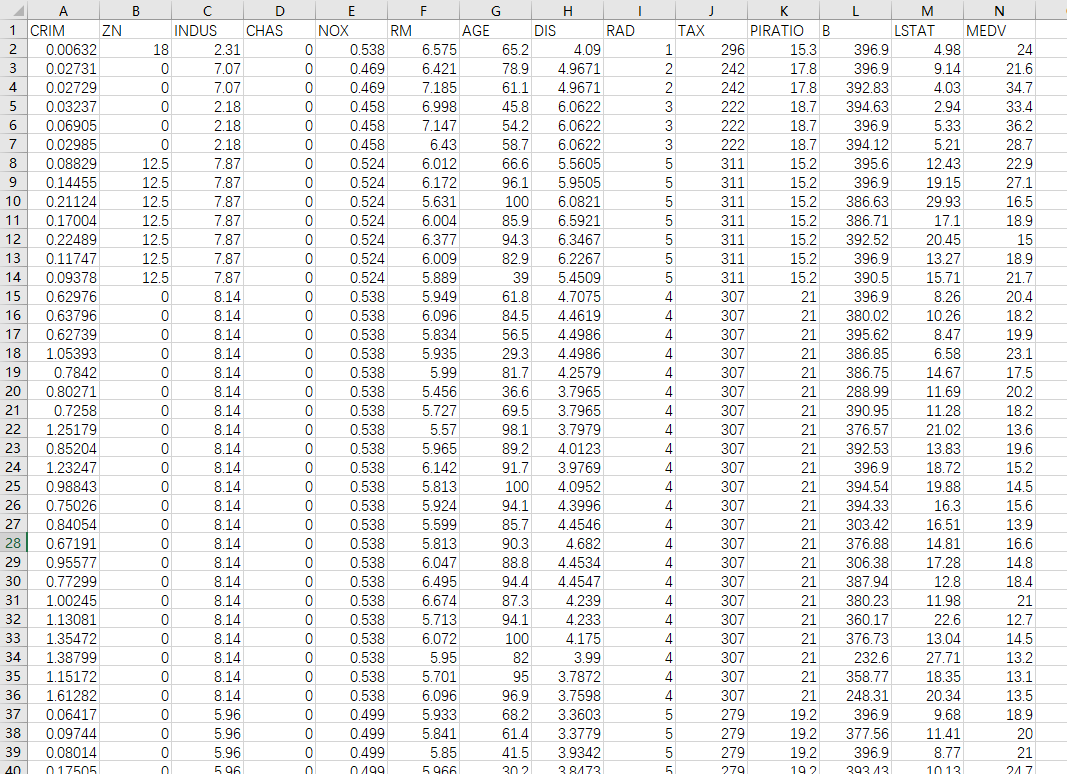

; 2、数据集变量名及意义
变量名意义CRIM城镇人均犯罪率。ZN占地面积超过25,000平方英尺的住宅用地比例。INDUS城镇非零售商用土地的比例。CHASCharles River虚拟变量(如果是河道,则为1;否则为0)。NOX一氧化氮浓度。RM住宅平均房间数。AGE1940 年之前建成的自用房屋比例。DIS到波士顿五个中心区域的加权距离。RAD辐射性公路的接近指数。TAX每 10000 美元的全值财产税率。PTRATIO城镇师生比例。B1000(Bk-0.63)^ 2,其中 Bk 指代城镇中黑人的比例。LSTAT人口中地位低下者的比例。MEDV自住房的平均房价,以千美元计。
二、完整代码
代码如下(示例):
options(java.parameters = "-Xmx10g")
library(ggplot2)
library(bartMachine)
library(reshape2)
library(knitr)
library(ggplot2)
library(GGally)
dataread.csv(file="C:/Users/LHW/Desktop/boston_housing_data.csv",header=T,sep=",")
head(data)
n=dim(data)
n
data1data[0,]
data2data[0,]
i=1
for (i in 1:n[1]) {
if(is.na(data[i,14])) {
data2 rbind(data.frame(data2),data.frame(data[i,]))
}else{
data1 rbind(data.frame(data1),data.frame(data[i,]))
}
print(i)
}
damelt(data1)
da1data.frame(da)
ggplot(da, aes(x=variable, y=value, fill=variable))+ geom_boxplot()+facet_wrap(~variable,scales="free")
cormat round(cor(data1[,1:13]), 2)
head(cormat)
melted_cormat melt(cormat)
head(melted_cormat)
get_upper_tri function(cormat){
cormat[lower.tri(cormat)] NA
return(cormat)
}
upper_tri get_upper_tri(cormat)
upper_tri
library(reshape2)
melted_cormat melt(upper_tri,na.rm = T)
ggplot(data = melted_cormat, aes(x=Var2, y=Var1, fill = value)) +
geom_tile(color = "white") +
scale_fill_gradient2(low = "blue", high = "red", mid = "white",
midpoint = 0, limit = c(-1, 1), space = "Lab",
name="Pearson\nCorrelation") +
theme_minimal() +
theme(axis.text.x = element_text(angle = 45, vjust = 1,
size = 12, hjust = 1)) +
coord_fixed() +
geom_text(aes(Var2, Var1, label = value), color = "black", size = 4)
set.seed(100)
index2=sample(x=2,size=nrow(data1),replace=TRUE,prob=c(0.9,0.1))
train2=data1[index2==1,]
head(train2)
x=train2[,-c(14)]
y=train2[,14]
data2=data1[index2==2,]
x.test_data=data2[,-c(14)]
head(data2)
xp=x.test_data
yp=data2[,14]
res = bartMachine(x,y,num_trees = 50,k=2,nu=3,q=0.9,num_burn_in = 50,num_iterations_after_burn_in = 1000,flush_indices_to_save_RAM = FALSE,seed = 1313, verbose = T)
print(res)
check_bart_error_assumptions(res, hetero_plot = "yhats")
plot_y_vs_yhat(res, Xtest = x, ytest = y,
credible_intervals = T, prediction_intervals = F,
interval_confidence_level = 0.95)
plot_y_vs_yhat(res, Xtest = xp, ytest = yp,
credible_intervals = T, prediction_intervals = F,
interval_confidence_level = 0.95)
bmcvbartMachineCV(X = x, y = y,
num_tree_cvs = c(50, 100,150), k_cvs = c(2, 3, 5),
nu_q_cvs = NULL, k_folds = 10, verbose = FALSE)
print(bmcv)
print(bmcv$cv_stats)
check_bart_error_assumptions(bmcv, hetero_plot = "yhats")
plot_y_vs_yhat(bmcv, Xtest = x, ytest = y,
credible_intervals = T, prediction_intervals = F,
interval_confidence_level = 0.95)
plot_y_vs_yhat(bmcv, Xtest = xp, ytest = yp,
credible_intervals = T, prediction_intervals = F,
interval_confidence_level = 0.95)
resp1 = predict(bmcv,data2[,1:13])
ccicalc_credible_intervals(bmcv, data2[,1:13],
ci_conf = 0.95)
resp1
cci
pcdplot_convergence_diagnostics(bmcv,
plots = c("sigsqs", "mh_acceptance", "num_nodes", "tree_depths"))
erextract_raw_node_data(bmcv, g = 1)
er
iviinvestigate_var_importance(bmcv, type = "trees",
plot = TRUE, num_replicates_for_avg = 5, num_trees_bottleneck = 20,
num_var_plot = Inf, bottom_margin = 10)
ivi
pdpd_plot(bmcv, 1,
levs = c(0.05, seq(from = 0.1, to = 0.9, by = 0.05), 0.95),
lower_ci = 0.025, upper_ci = 0.975, prop_data = 1)
head(x[,c(6,12,13,11,8,5,7)])
bmcv_s = bartMachine(x[,c(6,12,13,11,8,5,7)],y,num_trees = 100,k=2,nu=10,q=0.75,num_burn_in = 250,num_iterations_after_burn_in = 1000,flush_indices_to_save_RAM = FALSE,seed = 1313, verbose = T)
print(bmcv_s)
check_bart_error_assumptions(bmcv_s, hetero_plot = "yhats")
plot_y_vs_yhat(bmcv_s, Xtest = x[,c(6,12,13,11,8,5,7)], ytest = y,
credible_intervals = T, prediction_intervals = F,
interval_confidence_level = 0.95)
plot_y_vs_yhat(bmcv_s, Xtest = xp[,c(6,12,13,11,8,5,7)], ytest = yp,
credible_intervals = T, prediction_intervals = F,
interval_confidence_level = 0.95)
三、代码运行结果及解析
1.数据描述性分析
options(java.parameters = "-Xmx10g")
library(ggplot2)
library(bartMachine)
library(reshape2)
library(knitr)
library(ggplot2)
library(GGally)
dataread.csv(file="C:/Users/LHW/Desktop/boston_housing_data.csv",header=T,sep=",")
head(data)
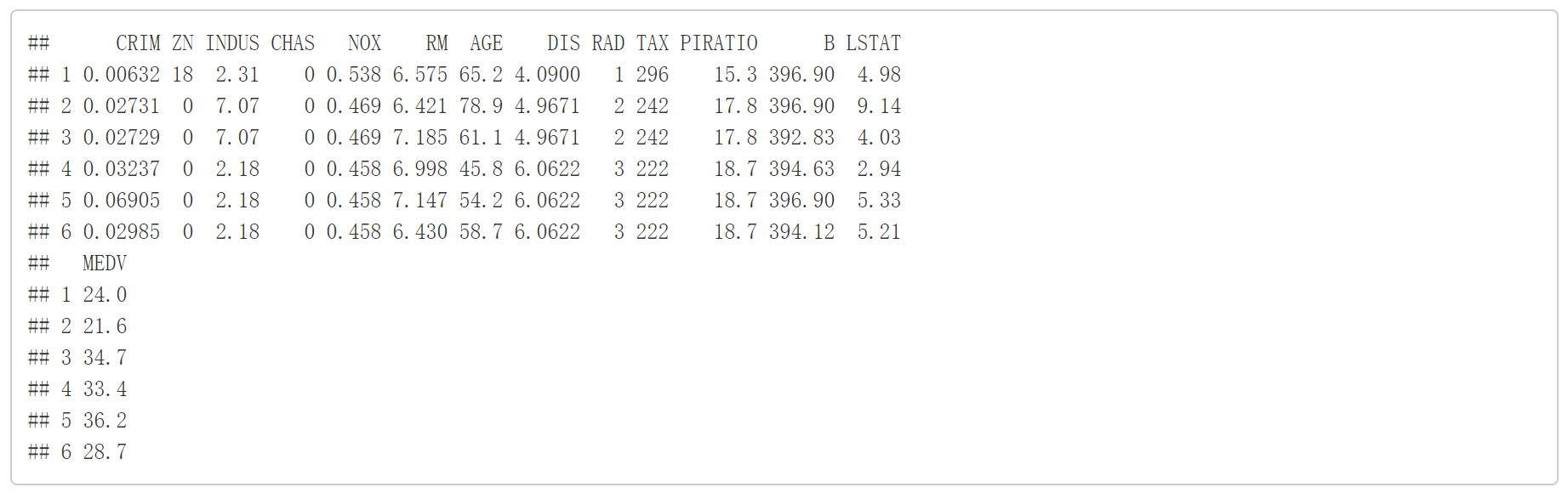
数据集前六行数据展示。
n=dim(data)
n

显示数据集维度,数据集十三个自变量,一个因变量(MEDV),一共十四列。506行数据样本。
data1data[0,]
data2data[0,]
i=1
for (i in 1:n[1]) {
if(is.na(data[i,14])) {
data2 rbind(data.frame(data2),data.frame(data[i,]))
}else{
data1 rbind(data.frame(data1),data.frame(data[i,]))
}
}
damelt(data1)
da1data.frame(da)
ggplot(da, aes(x=variable, y=value, fill=variable))+ geom_boxplot()+facet_wrap(~variable,scales="free")
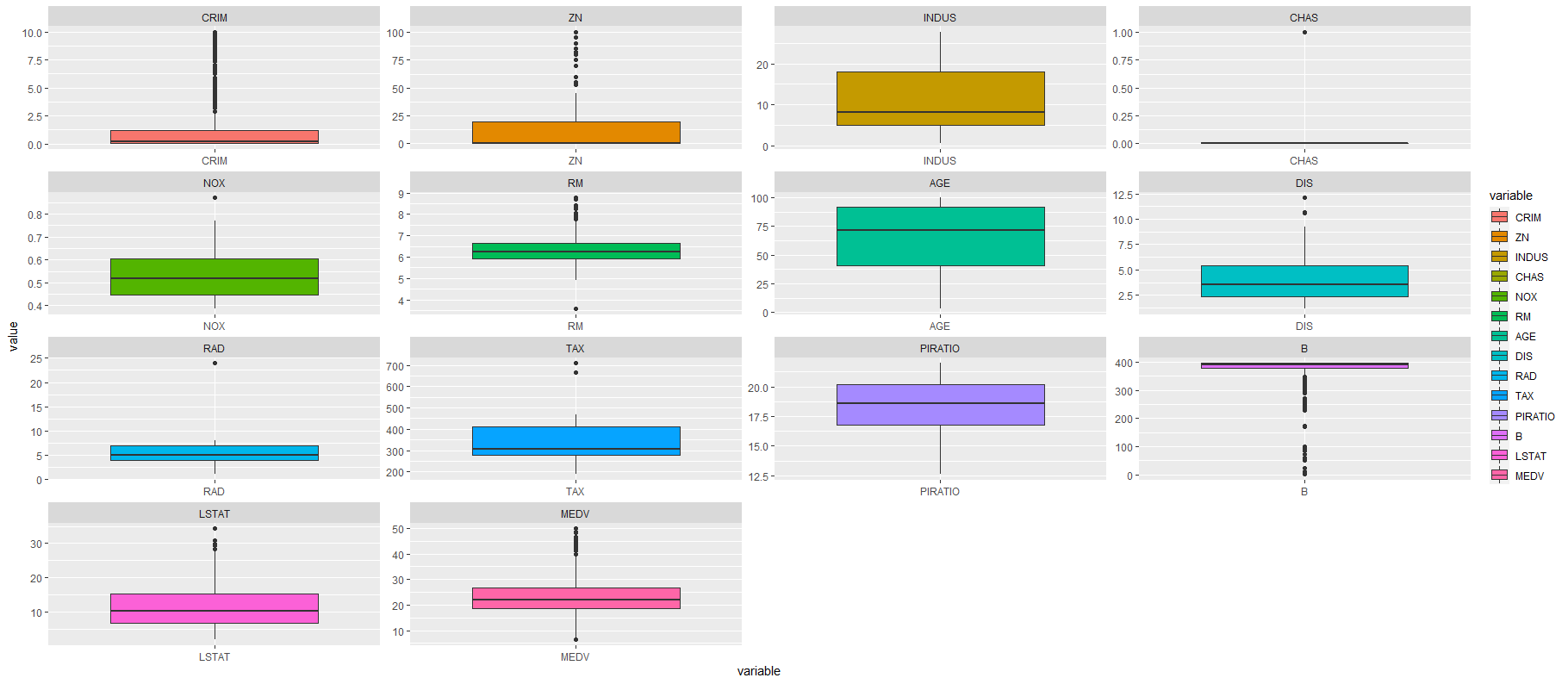
对数据的描述性统计,画出的十四列数据的箱线图。从图中可以看出变量(CRIM,ZN,CHAS,NOX,RM,DIS,RAD,TAX,B,LSTA,MEDV)有离群值,变量(CRIM,CHAS,NOX,RM,RAD,B)数据比较集中,变量(INDUS,AGE,RM,RAD,B)数据比较分散。
cormat round(cor(data1[,1:13]), 2)
head(cormat)
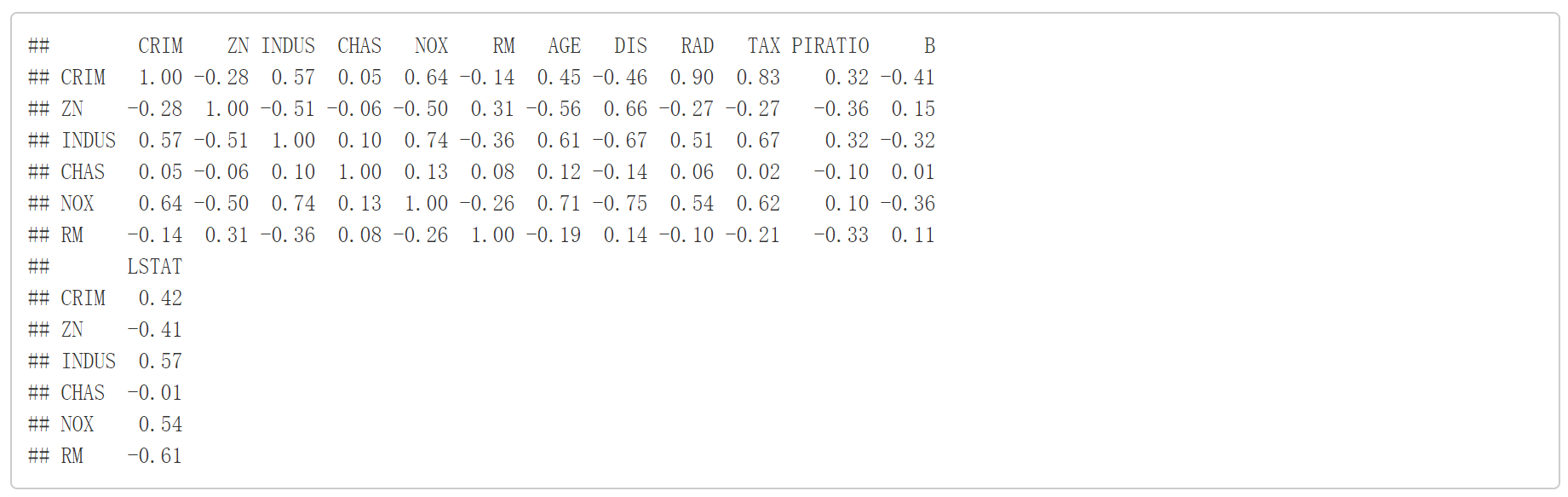
自变量的相关系数矩阵。
melted_cormat melt(cormat)
head(melted_cormat)

变换数据形式,以便用ggplot画图。
get_upper_tri function(cormat){
cormat[lower.tri(cormat)] NA
return(cormat)
}
upper_tri get_upper_tri(cormat)
upper_tri
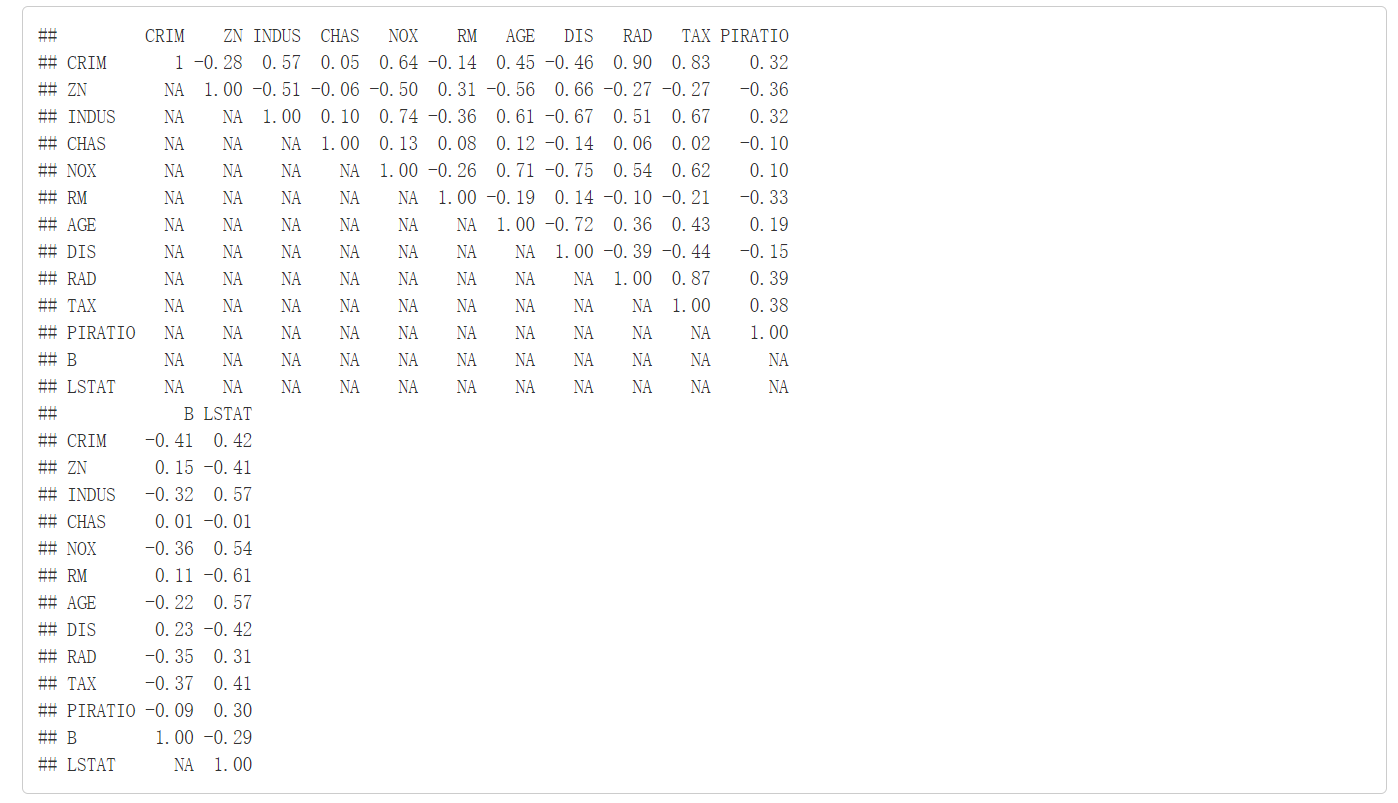
把自变量的相关系数矩阵一侧三角形的值转化为NA,方便画出相关系数热力图。
library(reshape2)
melted_cormat melt(upper_tri,na.rm = T)
ggplot(data = melted_cormat, aes(x=Var2, y=Var1, fill = value)) +
geom_tile(color = "white") +
scale_fill_gradient2(low = "blue", high = "red", mid = "white",
midpoint = 0, limit = c(-1, 1), space = "Lab",
name="Pearson\nCorrelation") +
theme_minimal() +
theme(axis.text.x = element_text(angle = 45, vjust = 1,
size = 12, hjust = 1)) +
coord_fixed() +
geom_text(aes(Var2, Var1, label = value), color = "black", size = 4)
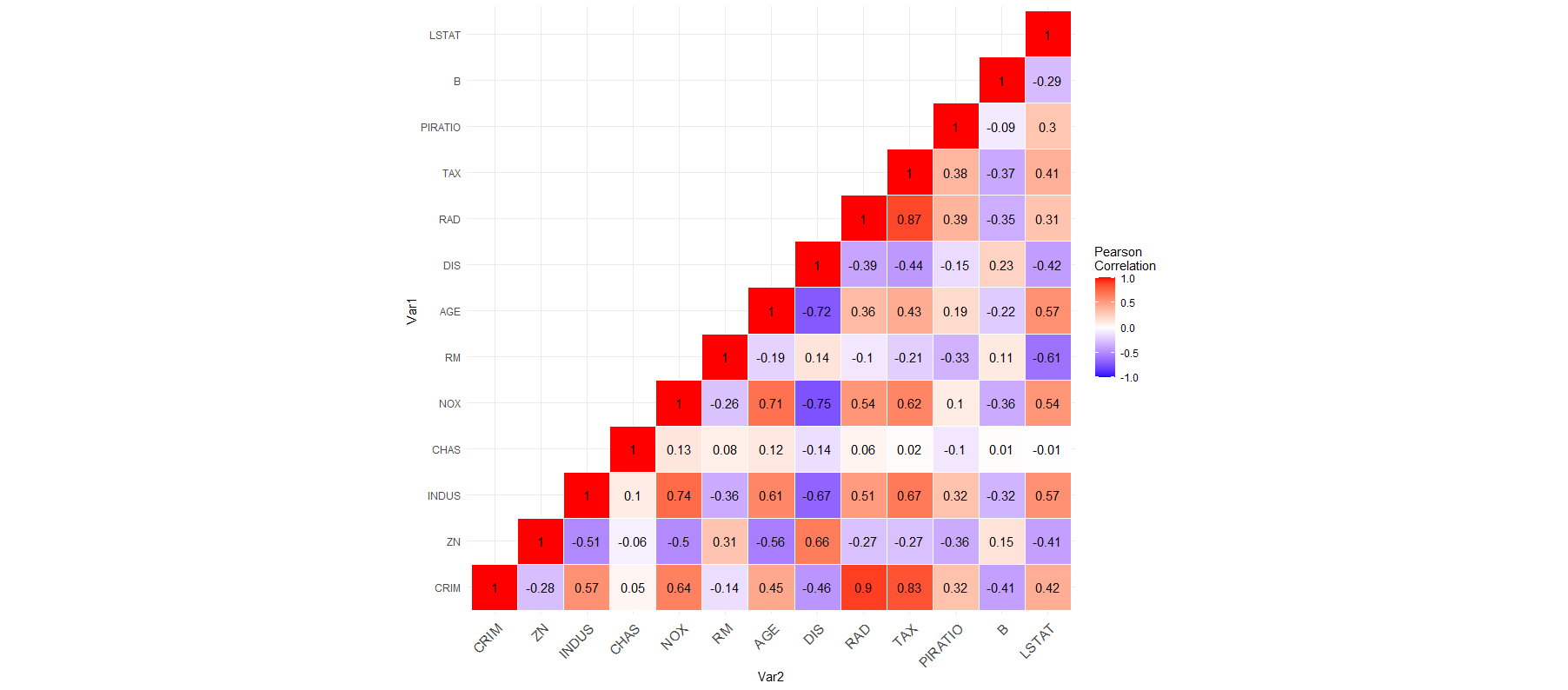
画出热力图,相关系数矩阵热力图,相关系数范围[-1,1],颜色越红,相关系数就越接近于1,正相关性越高;颜色越蓝,相关系数就越接近于-1,负相关性越高。从图中可以看出RAD与CRIM、TAX与CRIM,正相关性很高;DIS与AGE、DIS与NOX,负相关性很高。
2.建立Bart模型以及分析
set.seed(100)
index2=sample(x=2,size=nrow(data1),replace=TRUE,prob=c(0.9,0.1))
train2=data1[index2==1,]
head(train2)
x=train2[,-c(14)]
y=train2[,14]

训练集数据集展示。
data2=data1[index2==2,]
x.test_data=data2[,-c(14)]
head(data2)
xp=x.test_data
yp=data2[,14]
测试集数据集展示。
res = bartMachine(x,y,num_trees = 50,k=2,nu=3,q=0.9,num_burn_in = 50,num_iterations_after_burn_in = 1000,flush_indices_to_save_RAM = FALSE,seed = 1313, verbose = T)
print(res)

L2范数,也就是误差差值平方之和为826.44,预测值和真实值的误差没有特别大,说明预测的比较准确;伪R2值为0.9736,说明解释自变量对因变量的解释性很高,模型拟合效果很好。
check_bart_error_assumptions(res, hetero_plot = "yhats")
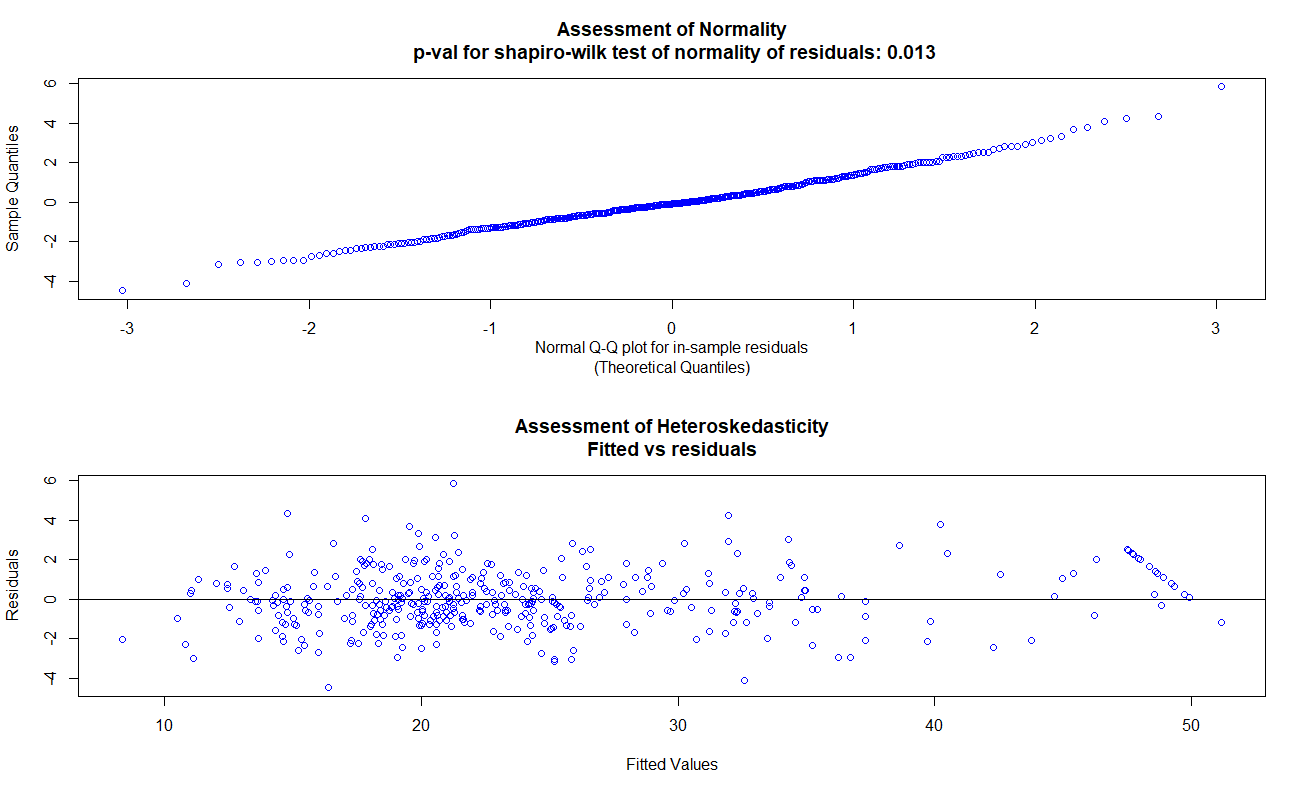
用Shapiro-Wilk检验方法,检验模型残差的正态性,画出残差散点图。从中可以看出检验p值为0.013小于0.05,拒绝原假设,说明残差不服从正态分布。
bmcvbartMachineCV(X = x, y = y,
num_tree_cvs = c(50, 100,150), k_cvs = c(2, 3, 5),
nu_q_cvs = NULL, k_folds = 10, verbose = FALSE)
print(bmcv)

L2范数,也就是误差差值平方之和为674.91,预测值和真实值的误差没有特别大,说明预测的比较准确;伪R2值为0.9785,说明解释自变量对因变量的解释性很高,模型拟合效果很好。
print(bmcv$cv_stats)
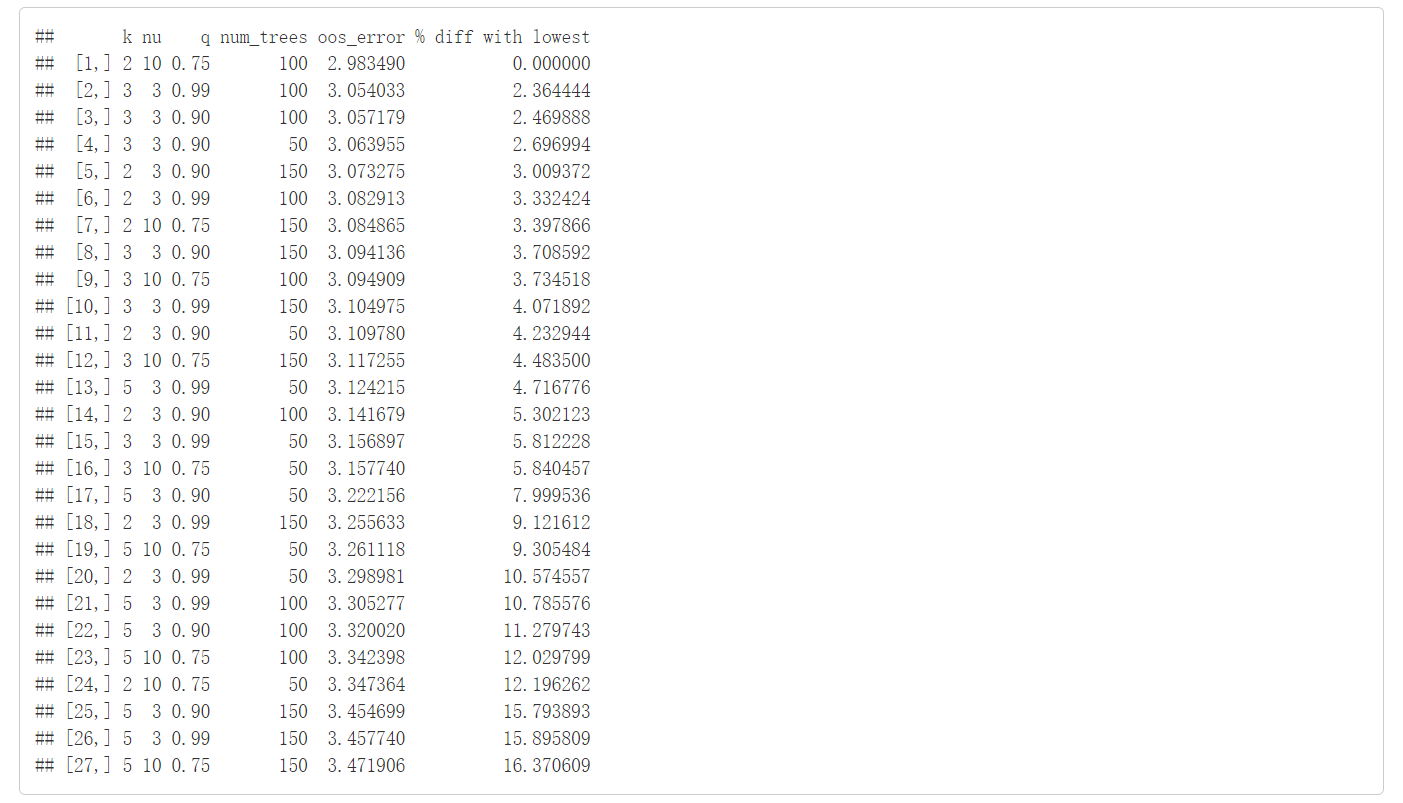
我们选取的是第一行参数进行建模。
check_bart_error_assumptions(bmcv, hetero_plot = "yhats")
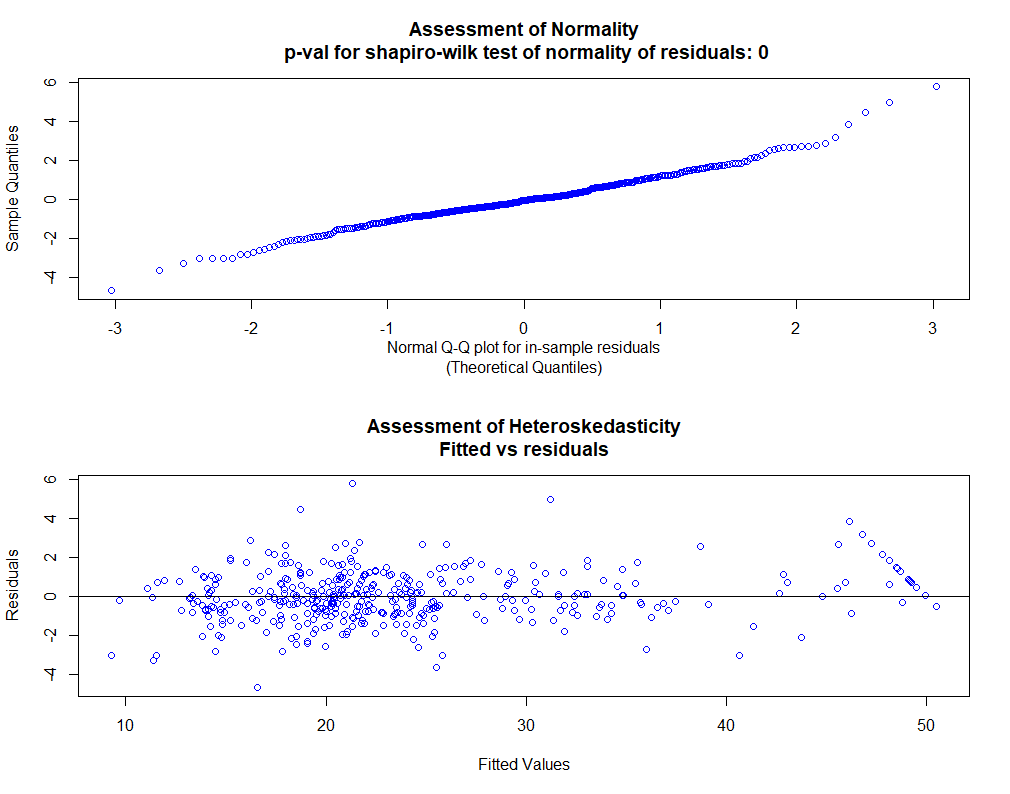
用Shapiro-Wilk检验方法,检验模型残差的正态性,画出残差散点图。从中可以看出检验p值为0小于0.05,拒绝原假设,说明残差不服从正态分布。
plot_y_vs_yhat(res, Xtest = x, ytest = y,
credible_intervals = T, prediction_intervals = F,
interval_confidence_level = 0.95)
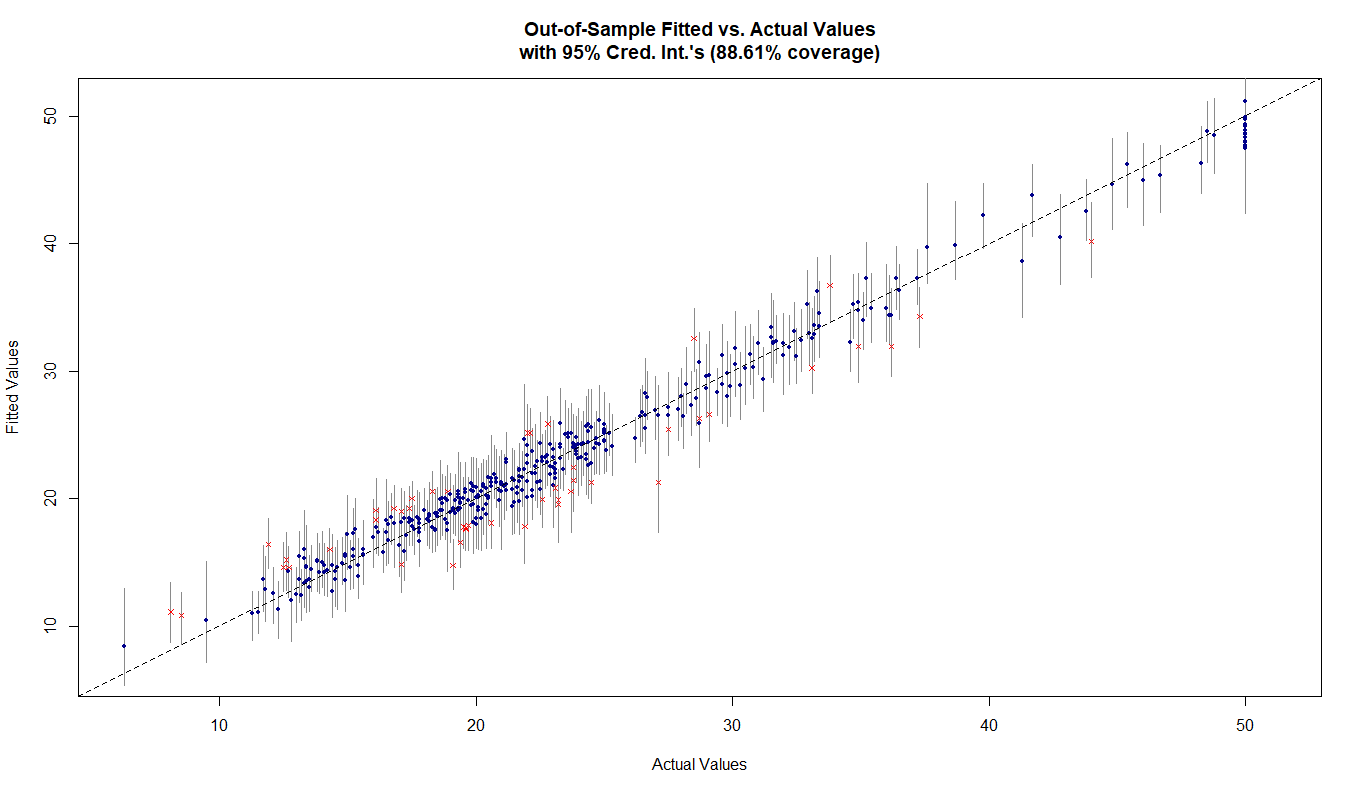
图中蓝色的点、和红叉是点估计,线段是区间估计。如果区间估计过平分线(平分线即真实值),则点为蓝色预测正确,反制则为红叉预测不正确。上图为模型对训练集因变量值的预测,从图中可以看出在95%的区间估计下的准确率为88.61%。说明模型训练拟合结果较好,但有可能过拟合。
plot_y_vs_yhat(res, Xtest = xp, ytest = yp,
credible_intervals = T, prediction_intervals = F,
interval_confidence_level = 0.95)
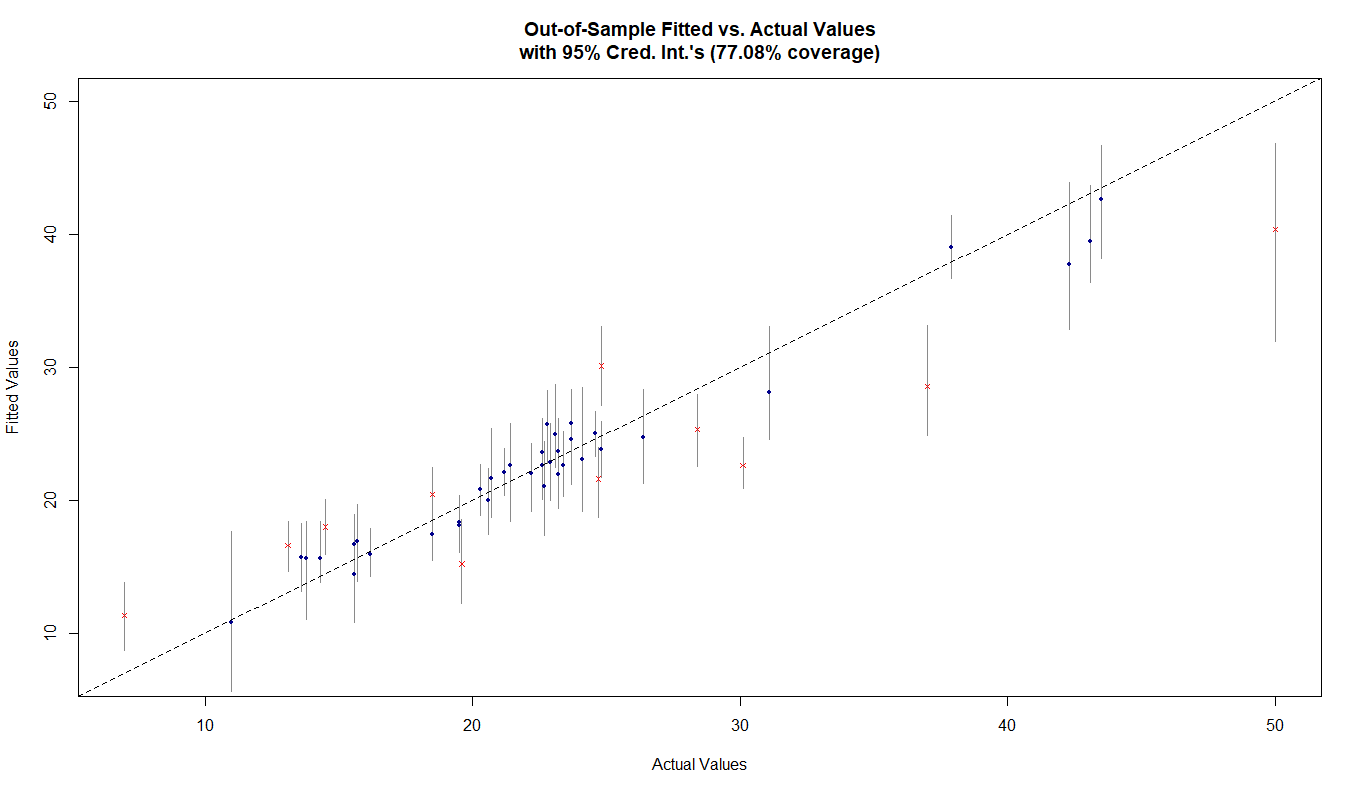
图中蓝色的点、和红叉是点估计,线段是区间估计。如果区间估计过平分线(平分线即真实值),则点为蓝色预测正确,反制则为红叉预测不正确。上图为模型对测试集因变量值的预测,从图中可以看出在95%的区间估计下的准确率为77.08%。说明模型训练拟合结果较好,对测试集的预测效果也相当不错,模型没有拟合。
plot_y_vs_yhat(bmcv, Xtest = x, ytest = y,
credible_intervals = T, prediction_intervals = F,
interval_confidence_level = 0.95)
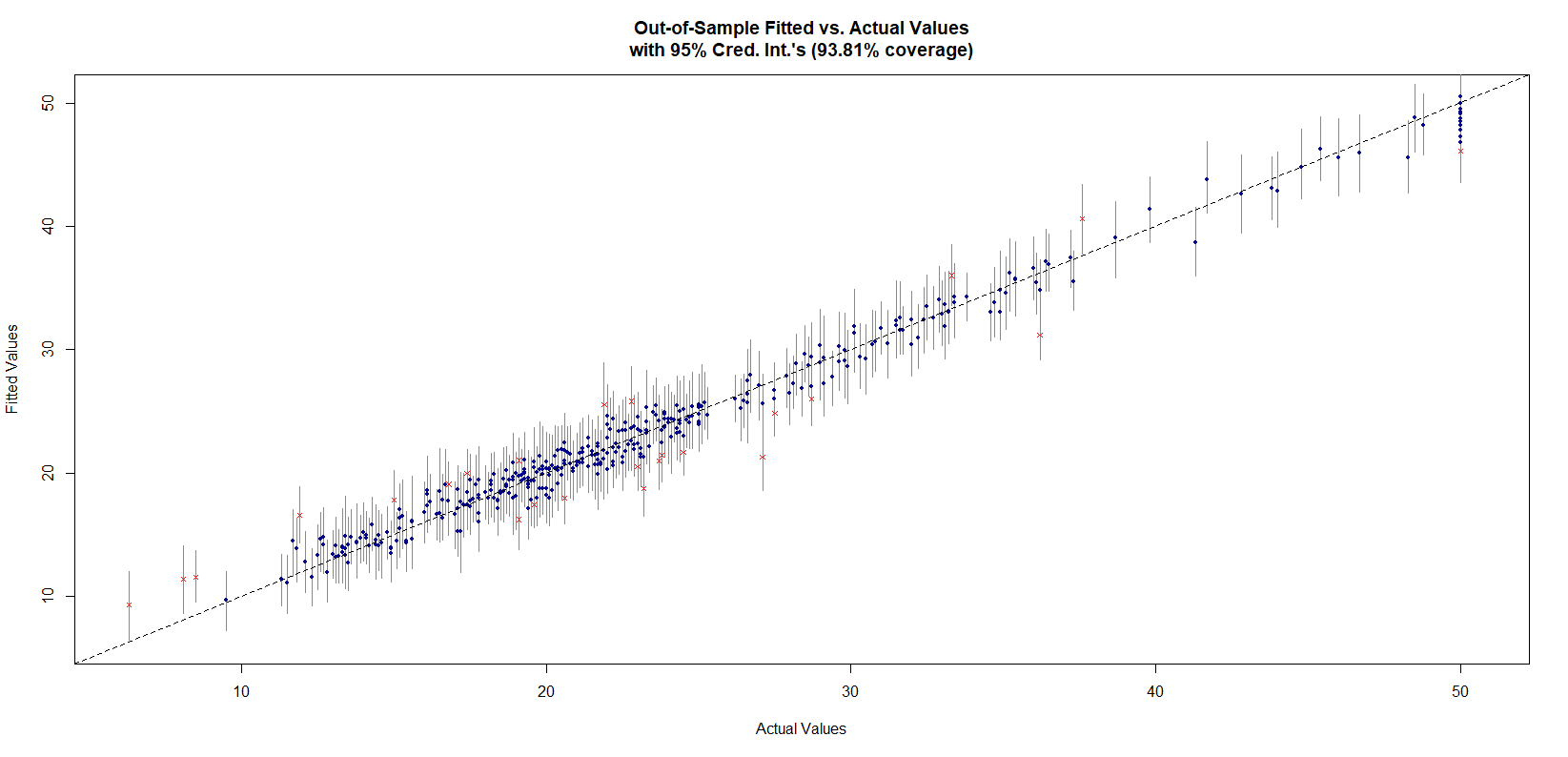
图中蓝色的点、和红叉是点估计,线段是区间估计。如果区间估计过平分线(平分线即真实值),则点为蓝色预测正确,反制则为红叉预测不正确。上图为模型对训练集因变量值的预测,从图中可以看出在95%的区间估计下的准确率为93.81%。说明模型训练拟合结果较好,但有可能过拟合。
plot_y_vs_yhat(bmcv, Xtest = xp, ytest = yp,
credible_intervals = T, prediction_intervals = F,
interval_confidence_level = 0.95)
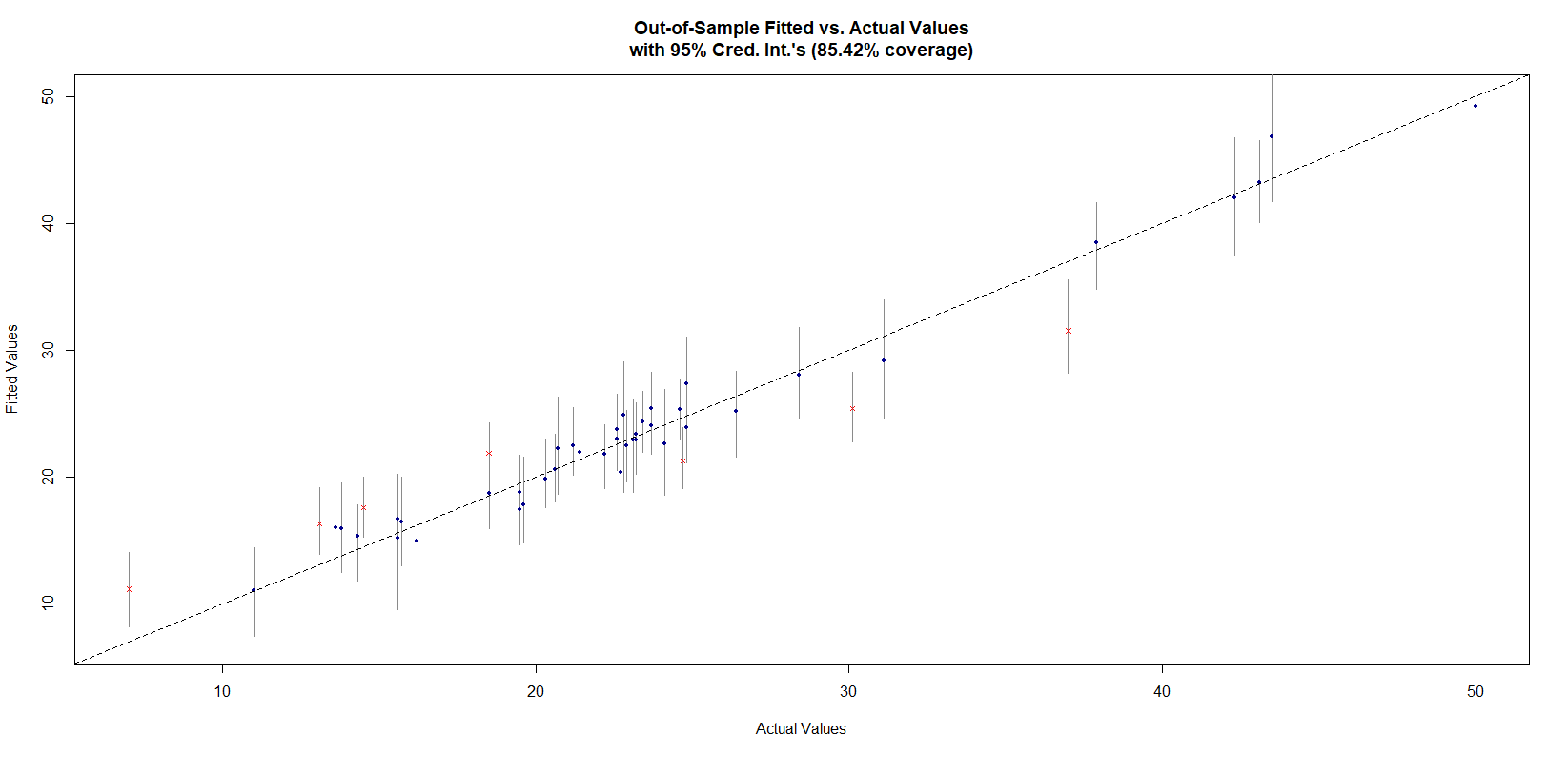
图中蓝色的点、和红叉是点估计,线段是区间估计。如果区间估计过平分线(平分线即真实值),则点为蓝色预测正确,反制则为红叉预测不正确。上图为模型对测试集因变量值的预测,从图中可以看出在95%的区间估计下的准确率为85.42%。说明模型训练拟合结果较好,对测试集的预测效果也相当不错,模型没有拟合。
resp1 = predict(bmcv,data2[,1:13])
ccicalc_credible_intervals(bmcv, data2[,1:13],
ci_conf = 0.95)
resp1
cci
部分结果:


上面第一张为对缺失值的点估计,上面第二张为对缺失值的区间估计。由上面的建模的结果来看,模型拟合效果很好,对缺失值的预测结果较为可信。
pcdplot_convergence_diagnostics(bmcv,
plots = c("sigsqs", "mh_acceptance", "num_nodes", "tree_depths"))
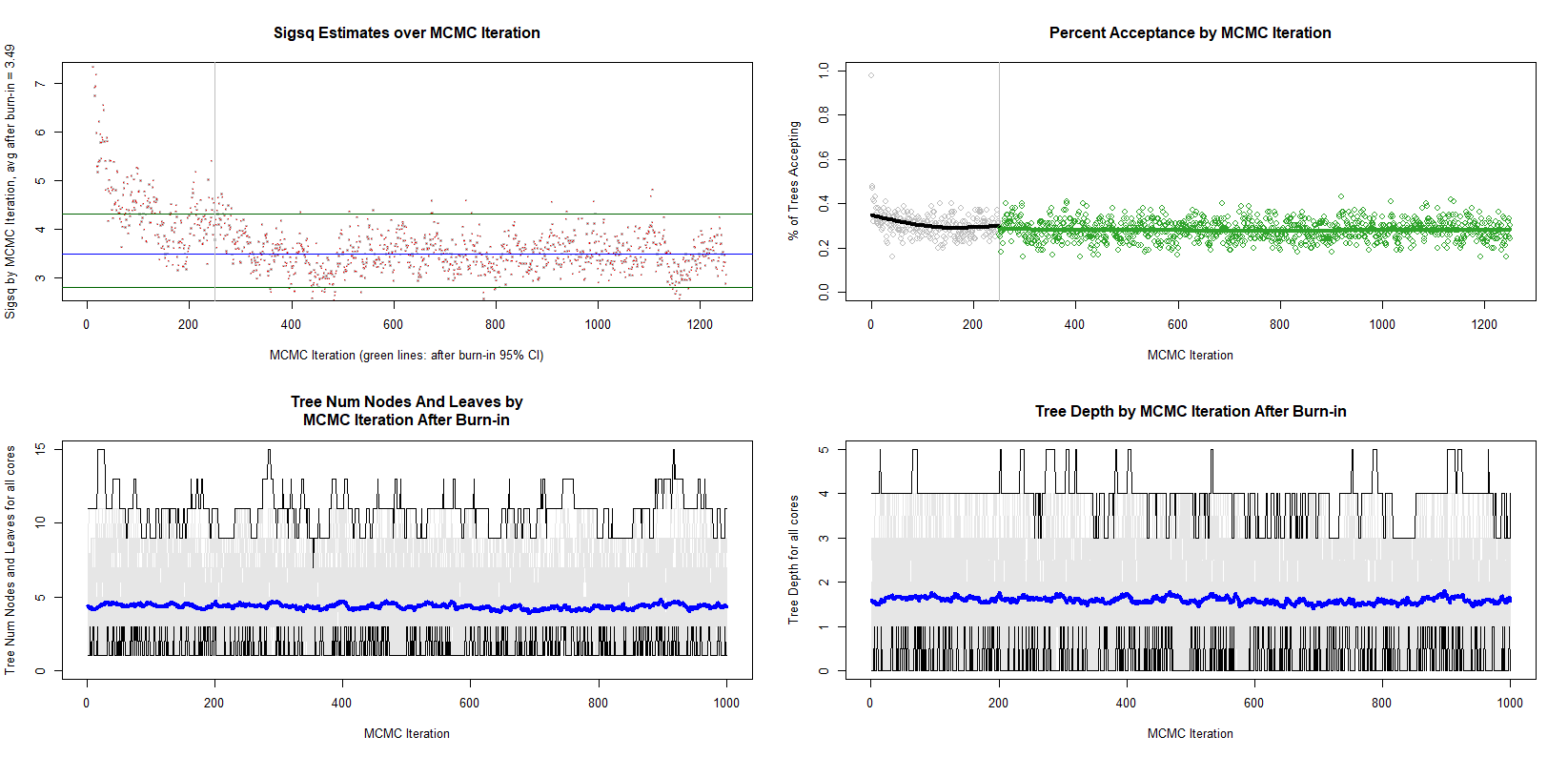
上图为评估 BART 模型的收敛和特征的一组图,竖线前是被丢弃的抽样样本。
“sigsqs”选项通过Gibbs样本数绘制的后验误差方差估计。这是评估MCMC算法收敛性的标准工具。从图中可以看出在300样本后,后验误差方差估计随着抽样样本增加较为稳定,三根横线为均值及置信区间;
“Percent acceptance”选项绘制每个吉布斯样本接受的Metropolis Hastings步骤的比例,从图中可以看出在300样本后,接受率随着抽样样本增加较为稳定;
“Tree Num nodes”选项根据Gibbs样本数绘制树和模型中每棵树上的平均节点数 ,节点数随着抽样样本增加较为稳定。蓝线是所有树上的平均节点数;
“tree depth”选项根据Gibbs样本数在树和模型中绘制每棵树的平均树深。蓝线是所有树上的平均节点数。
erextract_raw_node_data(bmcv, g = 1)
er
部分结果:

由于篇幅较长,这里只展示了第一棵树的部分信息,更多信息可以自己运行代码进行查看。
iviinvestigate_var_importance(bmcv, type = "trees",
plot = TRUE, num_replicates_for_avg = 5, num_trees_bottleneck = 20,
num_var_plot = Inf, bottom_margin = 10)
ivi
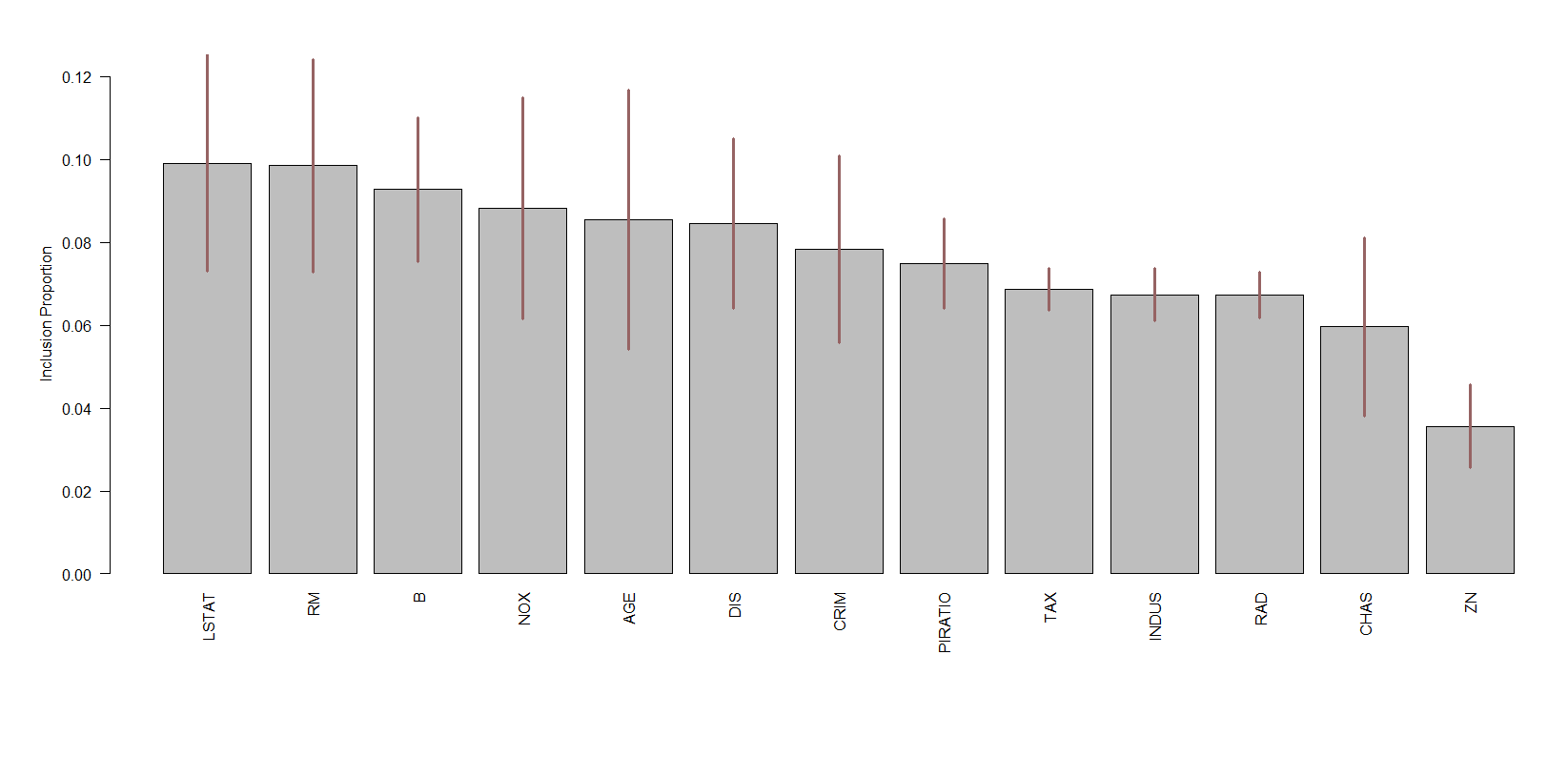
算出BART模型的变量被包含在树里的比例,了解不同协变量的相对影响。在图中,红条对应的是每一个变量比例的标准误差。用此来表示每一个变量的重要程度。
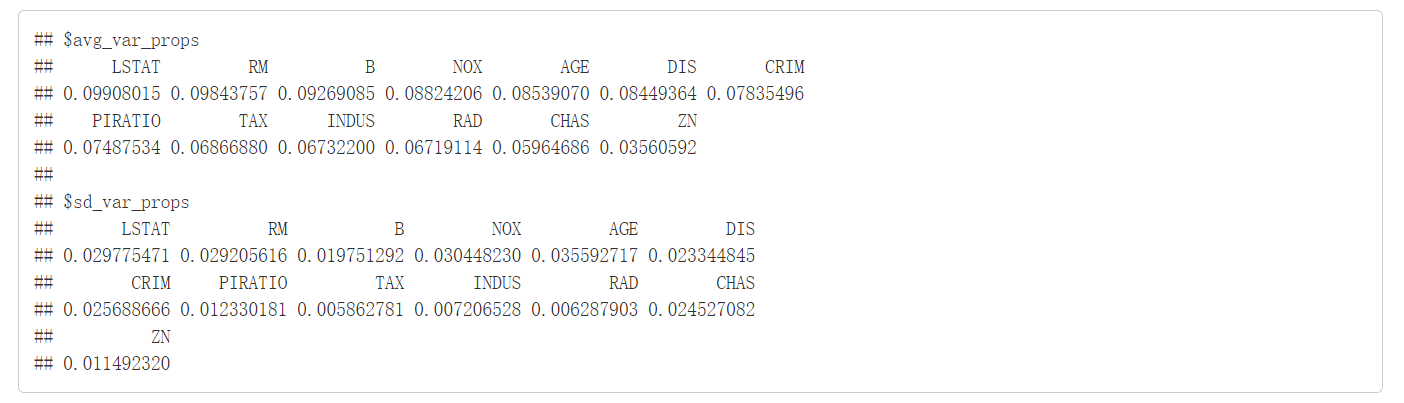
图中数据为每个变量比例的具体数值。
pdpd_plot(bmcv, 1,
levs = c(0.05, seq(from = 0.1, to = 0.9, by = 0.05), 0.95),
lower_ci = 0.025, upper_ci = 0.975, prop_data = 1)
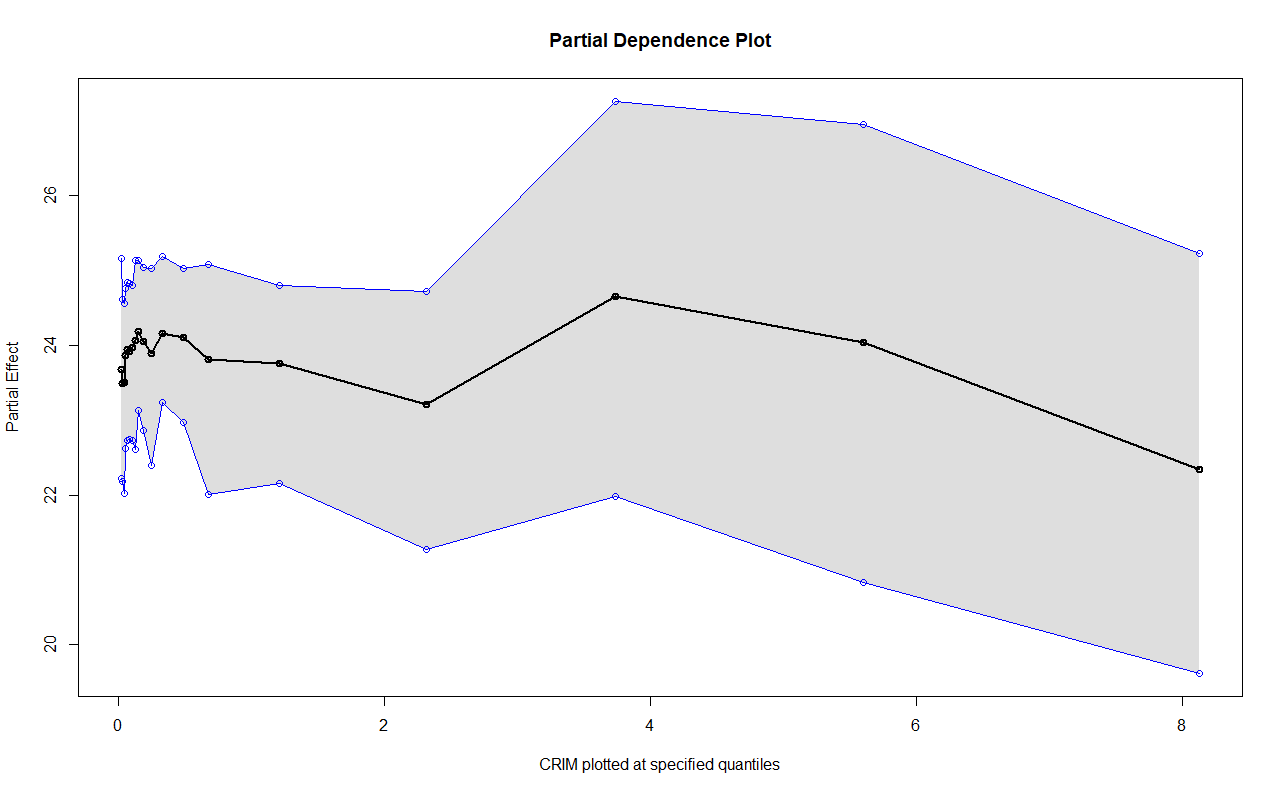
可以看出第一个变量,数据集中在0到0.3,其他变量不变,预测值随着自变量的增加,先减小后增大再减小。
3.变量选择
head(x[,c(6,12,13,11,8,5,7)])

选取BART模型的变量被包含在树里的比例高的前七个变量再进行建模。
bmcv_s = bartMachine(x[,c(6,12,13,11,8,5,7)],y,num_trees = 100,k=2,nu=10,q=0.75,num_burn_in = 250,num_iterations_after_burn_in = 1000,flush_indices_to_save_RAM = FALSE,seed = 1313, verbose = T)
print(bmcv_s)

L2范数,也就是误差差值平方之和为857.5,预测值和真实值的误差没有特别大,说明预测的比较准确;伪R2值为0.9726,说明解释自变量对因变量的解释性很高,模型拟合效果很好。
check_bart_error_assumptions(bmcv_s, hetero_plot = "yhats")
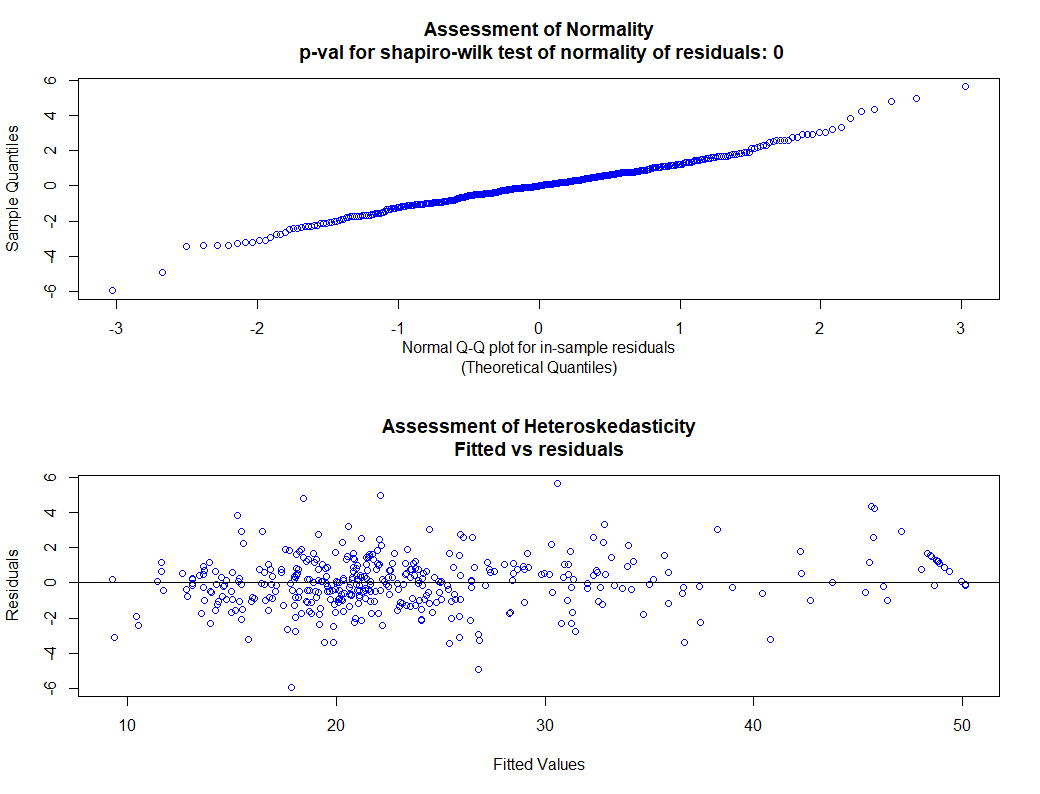
用Shapiro-Wilk检验方法,检验模型残差的正态性,画出残差散点图。从中可以看出检验p值为0小于0.05,拒绝原假设,说明残差不服从正态分布。
plot_y_vs_yhat(bmcv_s, Xtest = x[,c(6,12,13,11,8,5,7)], ytest = y,
credible_intervals = T, prediction_intervals = F,
interval_confidence_level = 0.95)

图中蓝色的点、和红叉是点估计,线段是区间估计。如果区间估计过平分线(平分线即真实值),则点为蓝色预测正确,反制则为红叉预测不正确。上图为模型对训练集因变量值的预测,从图中可以看出在95%的区间估计下的准确率为93.32%。说明模型训练拟合结果较好,但有可能过拟合。
plot_y_vs_yhat(bmcv_s, Xtest = xp[,c(6,12,13,11,8,5,7)], ytest = yp,
credible_intervals = T, prediction_intervals = F,
interval_confidence_level = 0.95)

图中蓝色的点、和红叉是点估计,线段是区间估计。如果区间估计过平分线(平分线即真实值),则点为蓝色预测正确,反制则为红叉预测不正确。上图为模型对训练集因变量值的预测,从图中可以看出在95%的区间估计下的准确率为81.25%。对测试集的预测效果也相当不错,模型没有拟合。
4.各模型效果对比
模型文中命名L2值伪R2值残差检验P值训练集预测准确率(%)测试集预测准确率(%)默认参数模型res826.440.97360.0126288.61%77.08%最佳先验参数模型bmcv674.910.97853e-593.81%85.42%变量选择后的模型bmcv_s857.50.97262e-593.32%81.25%
由不同模型对比可以看出,在交叉验证选择最佳参数后、选择变量后均对模型有了改进,预测效果变得更好。而且在选择变量后的模型,虽然只有七个变量,模型解释度以及预测准确率没有太大的变化。
特别声明
作者也是初学者,水平有限,文章中会存在一定的缺点和谬误,恳请读者多多批评、指正和交流!
Original: https://blog.csdn.net/qq_35674953/article/details/115975049
Author: 丢掉幻想;准备斗争
Title: Bart模型应用实例及解析(一)————基于波士顿房价数据集的回归模型
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/631464/
转载文章受原作者版权保护。转载请注明原作者出处!