

文章目录
*
– 零、Opencv简介
– 一、图像处理入门(读取、显示、转换、拆分合并、保存)
–
+ 1.1 直接显示图像
+ 1.2 使用cv2.imread读取图像
+ 1.3 显示图像属性
+ 1.4 显示图像
+
* 1.4.1 imshow(notebook不兼容,IDLE中运行)
* 1.4.2 namedWindow调整窗口尺寸(notebook不兼容,IDLE中运行)
* 1.4.3 使用Matplotlib显示图像(notebook兼容)
+ 1.5 图像通道的拆分和合并(cv2.split&cv2.merge)
+ 1.6 图像的色彩空间转换(cv.cvtColor)
+
* 1.6.2 图像的颜色空间转换公式
* 1.6.3 色彩空间转换函数cv.cvtColor()
+ 1.7 修改单个通道
+ 1.8 保存图片(cv2.imwrite)
+ 1.9 图片拼接和拷贝.copy()
– 二、基本图像操作
–
+ 2.1 访问单个像素
+ 2.2 修改图像像素
+ 2.3 裁剪图像
+ 2.4 调整图像大小cv2.resize
+ 2.5 图像翻转cv2.flip
– 三、 为图像添加注释(画线、圆、矩形和文本注释)
–
+ 3.1 画条线cv2.line
+ 3.2 画个圆cv2.circle
+ 3.3 画个矩形cv2.rectangle
+ 3.4 添加文本注释cv2.putText
+ 3.5 添加中文注释
– 四、基本图像增强(数值运算)
–
+ 4.1 加法 (cv2.add)
+
* 4.1.1 图像与标量相加/亮度
* 4.1.2 图像的加法运算
* 4.1.3 图像的加权加法cv2.addWeight(渐变切换)
+ 4.2 乘法/对比度(cv2.multiply)
+ 4.3 使用np.clip处理溢出
+ 4.4 图像阈值(cv2.threshold)
+
* 4.4.1 阈值处理基础
* 4.4.2 固定阈值处理函数cv.threshold
* 4.4.3 全局阈值处理 Otsu 方法(可跳过本节)
* 4.4.4 自适应阈值处理函数cv.adaptiveThreshold
* 4.4.5 应用:乐谱阅读器
+ 4.5 按位运算
+ 4.6 图像的叠加:制作coca-cola彩色Logo
– 六、使用OpenCV编写视频
–
+ 6.1 cv2.VideoCapture读取视频
+ 6.2 读取并显示一帧
+ 6.3 播放视频
+ 6.4 使用OpenCV编写视频cv.VideoWriter
– 八、图片对齐(略)
– 九、创建全景(略)
– 十、HDR(略)
– 十一 、目标追踪( GOTURN)
–
+ 11.1 读取视频,定义函数
+ 11.2 GOTURN原理简介
+ 11.3 创建Tracker实例
+ 11.4 视频处理
+ 11.5 读取帧并追踪目标
– 十三、SSD目标检测(略)
– 十四、人体姿态估计(略)
参考:
- opencv官方免费课程(含视频、代码)(验证之后可以下载,资源大概一个G,包含14章代码和YouTube视频)


- CSDN帖子《【youcans的OpenCV例程200篇】总目录》
; 零、Opencv简介
Opencv(Open Source Computer Vision Library)是一个基于开源发行的跨平台计算机视觉库,它实现了图像处理和计算机视觉方面的很多通用算法,已成为计算机视觉领域最有力的研究工具。在这里我们要区分两个概念:图像处理和计算机视觉的区别:图像处理侧重于”处理”图像–如增强,还原,去噪,分割等等;而计算机视觉重点在于使用计算机来模拟人的视觉,因此模拟才是计算机视觉领域的最终目标。
OpenCV用C++语言编写,它具有C ++,Python,Java和MATLAB接口,并支持Windows,Linux,Android和Mac OS, 如今也提供对于C#、Ch、Ruby,GO的支持。
OpenCV发展历史
- OpenCV 0.X
OpenCV于1999年由Intel建立,如今由Willow Garage公司提供支持。
1999年1月,CVL项目启动。主要目标是人机界面,能被UI调用的实时计算机视觉库,为Intel处理器做了特定优化。
2000年6月,第一个开源版本OpenCV alpha 3发布。
2000年12月,针对linux平台的OpenCV beta 1发布。 - OpenCV 1.X
OpenCV 最初基于C语言开发,API也都是基于C的,面临内存管理、指针等C语言固有的麻烦。
2006年10月, 正式发布OpenCV 1.0版本,同时支持mac os系统和一些基础的机器学习方法,如神经网络、随机森林等,来完善对图像处理的支持。
2009年9月,OpenCV 1.2(beta2.0)发布。 -
OpenCV 2.X
当C++流行起来,OpenCV 2.x发布,其尽量使用C++而不是C,但是为了向前兼容,仍保留了对C API的支持。
2009年9月2.0 beta发布,主要使用CMake构建。
2010年3月:2.1发布
2010年12月6日,OpenCV 2.2发布
2011年8月,OpenCV 2.3发布。
2012年4月2日,发布OpenCV 2.4. -
OpenCV 3.X
随着3.x的发布,1.x的C API将被淘汰不再被支持,以后C API可能通过C++源代码自动生成。3.x与2.x不完全兼容,与2.x相比,主要的不同之处在于OpenCV 3.x 的大部分方法都使用了OpenCL加速。
2014年8月, 3.0 alpha发布,除大部分方法都使用OpenCL加速外,3.x默认包含以及使用IPP(一套跨平台的软件函数库)
2017年8月,发布3.3版本,OpenCV开始支持C++ 11构建,同时加强对神经网络的支持。 - OpenCV 4.X
2018年10月4.0.0发布,OpenCV开始需要支持C++11的编译器才能编译,同时对几百个基础函数使用”wide universal intrinsics”重写,极大改善了opencv处理图像的性能。
一、图像处理入门(读取、显示、转换、拆分合并、保存)
本章将帮助您迈出使用OpenCV学习图像处理和计算机视觉的第一步。你将通过一些简单的例子学习一些重要的课程。在本章中,您将了解以下内容:
- 读取图像
- 检查图像属性,如数据类型和形状
- Numpy中图像的矩阵表示
- 彩色图像和分割/合并图像通道
- 使用matplotlib显示图像
- 保存图像
windows安装opencv:
pip install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple
或者查看官网安装方式(conda安装)
1.1 直接显示图像
import cv2
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from IPython.display import Image
我们将使用以下图片作为示例,使用ipython图像函数来加载和显示图像。
Image(filename='checkerboard_18x18.png')
Image(filename='checkerboard_84x84.jpg')

1.2 使用 cv2.imread 读取图像
OpenCV可以使用使用cv2.imread函数读取不同类型的图像(JPG、PNG等)。您可以加载灰度图像、彩色图像,也可以使用Alpha通道加载图像。其语法为:
retval = cv.imread(filename[, flags])
读取模式:ImreadModes
cv2.imread()从指定文件加载图像并返回该图像的矩阵。- 目前支持的文件格式:
- Windows 位图 – * .bmp,* .dib
- JPEG 文件 – * .jpeg, .jpg,.jpe
- JPEG 2000文件 – * .jp2
- 便携式网络图形 – * .png
- WebP – * .webp
- 便携式图像格式 – * .pbm, .pgm, .ppm * .pxm,* .pnm
- TIFF 文件 – * .tiff,* .tif
参数说明:
retval:读取的 OpenCV 图像,nparray 多维数组。如果无法读取图像(文件丢失,权限不正确,格式不支持或无效),该函数返回一个空矩阵None(此时不报错)。filename:读取图像的文件路径和文件名,绝对路径相对路径都行。flags:读取图片的方式,可选项1或cv2.IMREAD_COLOR:始终将图像转换为 3 通道BGR彩色图像,默认方式0或cv2.IMREAD_GRAYSCALE:始终将图像转换为单通道灰度图像。
灰度图像有256个灰度级,用数值区间[0,255]来表示,其中255表示为纯白色,0表示为纯黑色。256个灰度级的数值恰好可以用一个字节(8位二进制值)来表示-1或cv2.IMREAD_UNCHANGED:按原样返回加载的图像(使用Alpha通道)2或cv2.IMREAD_ANYDEPTH:在输入具有相应深度时返回16位/ 32位图像,否则将其转换为8位4或cv2.IMREAD_ANYCOLOR:以任何可能的颜色格式读取图像- 注意事项:
- OpenCV 读取图像文件,返回值是一个nparray 多维数组。OpenCV 对图像的任何操作,本质上就是对 Numpy 多维数组的运算。
- OpenCV 中彩色图像使用
BGR格式,而 PIL、PyQt、matplotlib 等库使用的是RGB格式。 - cv2.imread() 指定图片的存储路径和文件名,在 python3 中不支持中文和空格(但并不会报错)。必须使用中文时,可以使用 cv2.imdecode() 处理,参见扩展例程。
-
cv2.imread() 读取图像时默认忽略透明通道,但可以使用 CV_LOAD_IMAGE_UNCHANGED 参数读取透明通道。
-
简单示例:
cb_img = cv2.imread("checkerboard_18x18.png",0)
print(cb_img)
[[ 0 0 0 0 0 0 255 255 255 255 255 255 0 0 0 0 0 0]
[ 0 0 0 0 0 0 255 255 255 255 255 255 0 0 0 0 0 0]
[ 0 0 0 0 0 0 255 255 255 255 255 255 0 0 0 0 0 0]
[ 0 0 0 0 0 0 255 255 255 255 255 255 0 0 0 0 0 0]
[ 0 0 0 0 0 0 255 255 255 255 255 255 0 0 0 0 0 0]
[ 0 0 0 0 0 0 255 255 255 255 255 255 0 0 0 0 0 0]
[255 255 255 255 255 255 0 0 0 0 0 0 255 255 255 255 255 255]
[255 255 255 255 255 255 0 0 0 0 0 0 255 255 255 255 255 255]
[255 255 255 255 255 255 0 0 0 0 0 0 255 255 255 255 255 255]
[255 255 255 255 255 255 0 0 0 0 0 0 255 255 255 255 255 255]
[255 255 255 255 255 255 0 0 0 0 0 0 255 255 255 255 255 255]
[255 255 255 255 255 255 0 0 0 0 0 0 255 255 255 255 255 255]
[ 0 0 0 0 0 0 255 255 255 255 255 255 0 0 0 0 0 0]
[ 0 0 0 0 0 0 255 255 255 255 255 255 0 0 0 0 0 0]
[ 0 0 0 0 0 0 255 255 255 255 255 255 0 0 0 0 0 0]
[ 0 0 0 0 0 0 255 255 255 255 255 255 0 0 0 0 0 0]
[ 0 0 0 0 0 0 255 255 255 255 255 255 0 0 0 0 0 0]
[ 0 0 0 0 0 0 255 255 255 255 255 255 0 0 0 0 0 0]]
- 从网络读取图像:
import urllib.request as request
response = request.urlopen("https://profile.csdnimg.cn/8/E/F/0_youcans")
imgUrl = cv2.imdecode(np.array(bytearray(response.read()), dtype=np.uint8), -1)
plt.imshow(imgUrl)

- 读取中文路径的图像
报错TypeError: Image data of dtype object cannot be converted to float
imgFile = "images/测试图01.png"
img = cv2.imread(imgFile, flags=1)
plt.imshow(img)
使用 imdecode 可以读取带有中文的文件路径和文件名
img = cv2.imdecode(np.fromfile(imgFile, dtype=np.uint8), -1)
plt.imshow(img)

在AI stadio平台创建的notebook中,可以直接使用cv2.imread正确读取中文名图像。
1.3 显示图像属性
- img.ndim:查看图像的维数,彩色图像的维数为 3,灰度图像的维数为 2。
- img.shape:查看图像的形状,即图像栅格的行数(高度)、列数(宽度)、通道数。
- img.size:查看图像数组元素总数,灰度图像的数组元素总数为像素数量,彩色图像的数组元素总数为像素数量与通道数的乘积。
imgBGR = cv2.imread("../images/imgLena.tif", 1)
print("img shape is ", imgBGR.shape)
print("img size is ", imgBGR.size,'\n')
img_gry = cv2.imread("../images/imgLena.tif", 0)
print("img_gry shape is: ", img_gry.shape)
print("img_gry size is ", img_gry.size)
print("Data type of img is ", imgBGR.dtype)
img shape is (599, 1440, 3)
img size is 2587680
img_gry shape is: (599, 1440)
img_gry size is 862560
Data type of img is uint8
1.4 显示图像
1.4.1 imshow(notebook不兼容,IDLE中运行)
imshow函数用于在指定窗口中显示图像,其其语法为: None=cv2.imshow(winname,img)。
- notebook不兼容cv2的可视化,所以在notebook中运行此函数无法正常显示图片
winname为窗口名,img是 OpenCV 图像,nparray 多维数组
注意:
- 可以创建多个不同的显示窗口,每个窗口必须命名不同的 filename。
- 可以用
destroyWindow()函数关闭指定的显示窗口,也可以用destroyAllWindows()函数关闭所有的显示窗口。
示例:打开python自带的IDLE,输入以下代码:
import os
>>> os.chdir('E:\CV\opencv-python-free-course-code')
>>> print (os.getcwd())
E:\CV\opencv-python-free-course-code
>>> import cv2
>>> img=cv2.imread("images/imgLena.tif",-1)
>>> cv2.imshow("winname", img)
电脑自动弹出窗口winname,以原尺寸(1280×768)打开图片

1.4.2 namedWindow调整窗口尺寸(notebook不兼容,IDLE中运行)
namedWindow函数:用于创建一个具有合适名称和大小的窗口,以在屏幕上显示图像和视频。(默认情况下,图像以其原始大小显示)
函数语法为: None = cv.namedWindow( winname[, flags] )
参数:
- window_name:将显示图像/视频的窗口的名称
- flag: 表示窗口大小是自动设置还是可调整。
- WINDOW_NORMAL –允许手动更改窗口大小
- WINDOW_AUTOSIZE(Default) –自动设置窗口大小
- WINDOW_FULLSCREEN –将窗口大小更改为全屏
- 返回值:它不返回任何东西
-
图像窗口将在
waitKey()函数所设定的时长(毫秒)后自动关闭,waitKey(0)表示窗口显示时长为无限。 -
自动调整窗口
import cv2
path = '../images/imgLena.tif'
image = cv2.imread(path)
cv2.namedWindow("Display", cv2.WINDOW_AUTOSIZE)
cv2.imshow('Display', image)
key = cv2.waitKey(0)
cv2.destroyAllWindows()
- 使用
cv2.WINDOW_NORMAL,可手动调节窗口大小(弹出的窗口可以拉伸),也可按指定大小的窗口显示图像
cv2.namedWindow("Demo1", cv2.WINDOW_NORMAL)
cv2.resizeWindow("Demo2", 400, 300)
cv2.imshow('Demo1', image)
cv2.imshow('Demo2', image)
cv2.destroyAllWindows()
- 多个图像组合显示
retval = numpy.hstack((img1, img2, …))# 水平拼接
retval = numpy.vstack((img1, img2, …))# 垂直拼接
imgFile1 = "../images/imgLena.tif"
img1 = cv2.imread(imgFile1, flags=1)
imgFile2 = "../images/imgGaia.tif"
img2 = cv2.imread(imgFile2, flags=1)
imgStack = np.hstack((img1, img2))
cv2.imshow("Demo4", imgStack)
key = cv2.waitKey(0)

1.4.3 使用Matplotlib显示图像(notebook兼容)
- 使用plt模块显示图像,语法:
matplotlib.pyplot.imshow(img[, cmap]) img:图像数据,nparray 多维数组,对于 openCV(BGR)格式图像要先进行格式转换(OpenCV 使用 BGR 格式,matplotlib/PyQt 使用 RGB 格式)cmap:颜色图谱(colormap),默认为 RGB(A) 颜色空间- gray:灰度显示
- hsv:hsv 颜色空间
- plt.imshow() 可以直接显示 OpenCV 灰度图像,不需要格式转换,但需要使用
cmap=‘gray’进行参数设置 - plt.imshow() 可以使用 matplotlib 库中的各种方法绘图,如标题、坐标轴、插值等,详见matploblib Document。
import matplotlib.pyplot as plt
plt.imshow(cb_img)
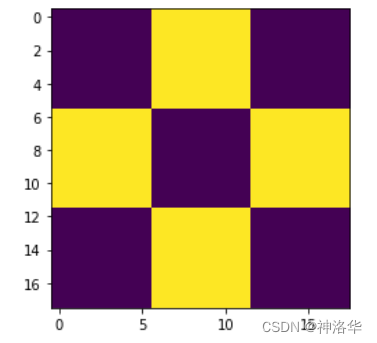
plt.imshow(cb_img, cmap='gray')

另一个例子:
cb_img_fuzzy = cv2.imread("checkerboard_fuzzy_18x18.jpg",0)
print(cb_img_fuzzy)
plt.imshow(cb_img_fuzzy,cmap='gray')
[[ 0 0 15 20 1 134 233 253 253 253 255 229 130 1 29 2 0 0]
[ 0 1 5 18 0 137 232 255 254 247 255 228 129 0 24 2 0 0]
[ 7 5 2 28 2 139 230 254 255 249 255 226 128 0 27 3 2 2]
[ 25 27 28 38 0 129 236 255 253 249 251 227 129 0 36 27 27 27]
[ 2 0 0 4 2 130 239 254 254 254 255 230 126 0 4 2 0 0]
[132 129 131 124 121 163 211 226 227 225 226 203 164 125 125 129 131 131]
[234 227 230 229 232 205 151 115 125 124 117 156 205 232 229 225 228 228]
[254 255 255 251 255 222 102 1 0 0 0 120 225 255 254 255 255 255]
[254 255 254 255 253 225 104 0 50 46 0 120 233 254 247 253 251 253]
[252 250 250 253 254 223 105 2 45 50 0 127 223 255 251 255 251 253]
[254 255 255 252 255 226 104 0 1 1 0 120 229 255 255 254 255 255]
[233 235 231 233 234 207 142 106 108 102 108 146 207 235 237 232 231 231]
[132 132 131 132 130 175 207 223 224 224 224 210 165 134 130 136 134 134]
[ 1 1 3 0 0 129 238 255 254 252 255 233 126 0 0 0 0 0]
[ 20 19 30 40 5 130 236 253 252 249 255 224 129 0 39 23 21 21]
[ 12 6 7 27 0 131 234 255 254 250 254 230 123 1 28 5 10 10]
[ 0 0 9 22 1 133 233 255 253 253 254 230 129 1 26 2 0 0]
[ 0 0 9 22 1 132 233 255 253 253 254 230 129 1 26 2 0 0]]

2. 使用pylab模块显示图像
import matplotlib.pylab as pylab
pylab.imshow(cb_img)
二者的区别:
pylab:结合了pyplot和numpy,将numpy导入了其命名空间中,对交互式使用来说比较方便,既可以画图又可以进行简单的计算,pylab表现的和matlab更加相似pyplot:相比pylab更加纯粹,如果只是打印图片,使用这个就行。
1.5 图像通道的拆分和合并(cv2.split&cv2.merge)
- 直接显示彩色图像
Image("coca-cola-logo.png")

2. 使用cv2读取彩色图像
coke_img = cv2.imread("coca-cola-logo.png",1)
print("Image size is ", coke_img.shape)
print("Data type of image is ", coke_img.dtype)
print("")
Image size is (700, 700, 3)
Data type of image is uint8
plt.imshow(coke_img)
上面显示的颜色与实际图像不同。这是因为matplotlib需要RGB格式的图像,而OpenCV则以BGR格式存储图像。因此,为了正确显示,我们需要反转图像的通道。
coke_img_channels_reversed = coke_img[:, :, ::-1]
plt.imshow(coke_img_channels_reversed)

cv2.split:将多通道arrays划分为多个单通道array。(spilt函数文档)cv2.merge:将多个array合并为一个多通道数组arrays。所有输入矩阵的大小必须相同。
- 直接用 imshow 显示返回的单通道对象,将被视为 (width, height) 形状的灰度图像
- 如果要正确显示某一颜色分量,需要增加另外两个通道值(置 0)转换为 BGR 三通道格式,再用 imshow 才能显示为拆分通道的颜色。
img_NZ_bgr = cv2.imread("New_Zealand_Lake.jpg",cv2.IMREAD_COLOR)
b,g,r = cv2.split(img_NZ_bgr)
plt.figure(figsize=[20,5])
plt.subplot(141);plt.imshow(r,cmap='gray');plt.title("Red Channel");
plt.subplot(142);plt.imshow(g,cmap='gray');plt.title("Green Channel");
plt.subplot(143);plt.imshow(b,cmap='gray');plt.title("Blue Channel");
imgZeros = np.zeros_like(img_NZ_bgr)
imgZeros[:,:,1] = g
cv2.imshow("channel G", imgZeros)
imgMerged = cv2.merge((b,g,r))
imgStack = np.stack((b, g, r), axis=2)
plt.subplot(144);plt.imshow(imgMerged[:,:,::-1]);plt.title("Merged Output");


1.6 图像的色彩空间转换(cv.cvtColor)
色彩空间是指通过多个(通常为 3个或4个)颜色分量构成坐标系来表示各种颜色的模型系统。色彩空间中的每个像素点均代表一种颜色,各像素点的颜色是多个颜色分量的合成或描述。
彩色图像可以根据需要映射到某个色彩空间进行描述。在不同的工业环境或机器视觉应用中,使用的色彩空间各不相同。
常见的色彩空间包括:GRAY 色彩空间(灰度图像)、XYZ 色彩空间、YCrCb 色彩空间、HSV 色彩空间、HLS 色彩空间、CIELab 色彩空间、CIELuv 色彩空间、Bayer 色彩空间等。
计算机显示器采用 RGB 色彩空间,数字艺术创作经常采用 HSV/HSB 色彩空间,机器视觉和图像处理系统大量使用 HSl、HSL色彩空间。各颜色分量的含义分别为:
RGB:红色(Red)、绿色(Green)、蓝色(Blue);HSV/HSB:色调(Hue)、饱和度(Saturation)和明度(Value/Brightness);HSl:色调(Hue)、饱和度(Saturation)和灰度(Intensity);HSL:包括色调(Hue)、饱和度(Saturation)和亮度(Luminance/Lightness)。
RGB 模型是一种加性色彩系统,色彩源于红、绿、蓝三基色。用于CRT显示器、数字扫描仪、数字摄像机和显示设备上,是当前应用最广泛的一种彩色模型。
1.6.2 图像的颜色空间转换公式
- R G B ⟷ G R A Y RGB \longleftrightarrow GRAY RGB ⟷GR A Y
GRAY 表示灰度图像,通常指 cv_8U 灰度图,有256个灰度级:0-255。
RGB → GRAY: g r a y = 0.299 ∗ R + 0.587 ∗ G + 0.114 ∗ B gray = 0.299R + 0.587G + 0.114*B g r a y =0.299 ∗R +0.587 ∗G +0.114 ∗B - R G B ⟷ H S V RGB \longleftrightarrow HSV RGB ⟷H S V

更多颜色空间转换公式,详见 OpenCV官方文档: OpenCV: Color conversions 。
; 1.6.3 色彩空间转换函数cv.cvtColor()
使用函数 cv.cvtColor()可以进行色彩空间类型转换,将图像从一个色彩空间转换到另一个色彩空间。例如,在进行图像的特征提取、距离计算时,往往先将图像从 RGB 色彩空间转换为灰度色彩空间。函数语法为:
cvtColor(src, code[, dst[, dstCn]]) -> dst
- src:输入图像,nparray 多维数组,8位无符号/ 16位无符号/单精度浮点数格式
- code:颜色空间转换代码,详见ColorConversionCodes
- dst:输出图像,大小和深度与 src 相同
- dstCn:输出图像的通道数,0 表示由src和code自动计算。
示例:
imgBGR = cv2.imread("../images/imgLena.tif", flags=1)
print(imgBGR.shape)
imgRGB = cv2.cvtColor(imgBGR, cv2.COLOR_BGR2RGB)
imgGRAY = cv2.cvtColor(imgBGR, cv2.COLOR_BGR2GRAY)
imgHSV = cv2.cvtColor(imgBGR, cv2.COLOR_BGR2HSV)
imgYCrCb = cv2.cvtColor(imgBGR, cv2.COLOR_BGR2YCrCb)
imgHLS = cv2.cvtColor(imgBGR, cv2.COLOR_BGR2HLS)
imgXYZ = cv2.cvtColor(imgBGR, cv2.COLOR_BGR2XYZ)
imgLAB = cv2.cvtColor(imgBGR, cv2.COLOR_BGR2LAB)
imgYUV = cv2.cvtColor(imgBGR, cv2.COLOR_BGR2YUV)
titles = ['BGR', 'RGB', 'GRAY', 'HSV', 'YCrCb', 'HLS', 'XYZ', 'LAB', 'YUV']
images = [imgBGR, imgRGB, imgGRAY, imgHSV, imgYCrCb,
imgHLS, imgXYZ, imgLAB, imgYUV]
plt.figure(figsize=(10, 8))
for i in range(9):
plt.subplot(3, 3, i + 1), plt.imshow(images[i], 'gray')
plt.title(titles[i])
plt.xticks([]), plt.yticks([])
plt.tight_layout()
plt.show()

1.7 修改单个通道
h,s,v = cv2.split(imgHSV)
plt.figure(figsize=[20,5])
plt.subplot(141);plt.imshow(h,cmap='gray');plt.title("H Channel");
plt.subplot(142);plt.imshow(s,cmap='gray');plt.title("S Channel");
plt.subplot(143);plt.imshow(v,cmap='gray');plt.title("V Channel");
plt.subplot(144);plt.imshow(imgRGB);plt.title("Original");

h_new = h+10
img_merged = cv2.merge((h_new,s,v))
img_rgb = cv2.cvtColor(img_merged, cv2.COLOR_HSV2RGB)
plt.figure(figsize=[20,5])
plt.subplot(141);plt.imshow(h,cmap='gray');plt.title("H Channel");
plt.subplot(142);plt.imshow(s,cmap='gray');plt.title("S Channel");
plt.subplot(143);plt.imshow(v,cmap='gray');plt.title("V Channel");
plt.subplot(144);plt.imshow(img_rgb);plt.title("Modified");

1.8 保存图片(cv2.imwrite)
函数 cv2.imwrite() 用于将图像保存到指定的文件。其语法为: retval = imwrite(filename, img[, params])
- 图像格式是根据文件扩展名选择的(有关扩展名列表,请参阅cv::imread)。
- 通常,使用此功能只能保存8位单通道或BGR 3通道图像,或 PNG/JPEG/TIFF 16位无符号单通道图像。
参数说明:
filename:要保存的文件的路径和名称,包括文件扩展名img:要保存的 OpenCV 图像,nparray 多维数组params:不同编码格式的参数,可选项。- cv2.CV_IMWRITE_JPEG_QUALITY:设置 .jpeg/.jpg 格式的图片质量,取值为 0-100(默认值 95),数值越大则图片质量越高;
- cv2.CV_IMWRITE_WEBP_QUALITY:设置 .webp 格式的图片质量,取值为 0-100;
- cv2.CV_IMWRITE_PNG_COMPRESSION:设置 .png 格式图片的压缩比,取值为 0-9(默认值 3),数值越大则压缩比越大。
- 其它详见Imwrite flags文档
retval:返回值,保存成功返回 True,否则返回 False。
注意:
- cv2.imwrite() 保存的是 OpenCV 图像(多维数组),不是 cv2.imread() 读取的图像文件,所保存的文件格式是由 filename 的扩展名决定的,与读取的图像文件的格式无关。
- 对 4 通道 BGRA 图像,可以使用 Alpha 通道保存为 PNG 图像。
-
cv2.imwrite() 指定图片的存储路径和文件名,在 python3 中不支持中文和空格(但并不会报错)。必须使用中文时,可以使用 cv2.imencode() 处理,参见扩展例程。
-
基本示例
imgBGR = cv2.imread("../images/imgLena.tif", flags=1)
cv2.imwrite('../images/SaveBGR.png', imgBGR)
SaveBGR=cv2.imread('SaveBGR.png',1)
plt.imshow(SaveBGR)

imgRGB = cv2.cvtColor(imgBGR, cv2.COLOR_BGR2RGB)
cv2.imwrite('../iamges/SaveRGB.png', imgRGB)
SaveRGB=cv2.imread('SaveRGB.png',1)
plt.imshow(SaveRGB)

可见:图像的原始格式和cv2默认读取的格式是倒序的,和cv2保存和格式也是倒序的。只不过一般我们读取的图片是RGB格式,所以cv2默认读取是BGR格式。如果图片本身就是BGR格式,默认读取就是正常的RGB格式。
- RGB默认读取→BGR,保存→RGB,默认读取→BGR
-
RGB默认读取→BGR,转为RGB→RGB,保存→BGR,默认读取→RGB
-
扩展示例:保存中文路径的图像
saveFile = "../images/测试图.jpg"
img_write = cv2.imencode(".jpg", imgBGR)[1].tofile(saveFile)
1.9 图片拼接和拷贝.copy()
- 图片拼接
用 Numpy 的数组堆叠方法可以进行图像的拼接,操作简单方便。
retval = numpy.hstack((img1, img2, ...))
retval = numpy.vstack((img1, img2, ...))
-
图像的拷贝
-
Python 中的 “复制” 有无拷贝、浅拷贝和深拷贝之分,
无拷贝相当于引用,浅拷贝只是对原变量内存地址的拷贝,深拷贝是对原变量(ndarray数组)的所有数据的拷贝。 - Numpy 直接赋值是无拷贝,np.copy() 方法是深拷贝,切片操作是特殊的浅拷贝。
- 直接赋值得到的新图像相当于引用,改变新图像的值时原图像的值也发生改变;np.copy() 方法复制图像(ndarray数组)得到的新图像才是深拷贝,改变复制图像的形状或数值,原来图像并不会发生改变。
二、基本图像操作
在本章中,我们将介绍如何执行图像转换,包括:
- 访问和操作图像像素
- 图像大小调整
- 裁剪
- 翻转
import cv2
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
from IPython.display import Image
%matplotlib inline
2.1 访问单个像素
像素是构成数字图像的基本单位,像素处理是图像处理的基本操作。对像素的访问、修改,可以使用Numpy 方法直接访问数组元素。
- 读取原始棋盘图像
cb_img = cv2.imread("checkerboard_18x18.png",0)
plt.imshow(cb_img, cmap='gray')
print(cb_img)
[[ 0 0 0 0 0 0 255 255 255 255 255 255 0 0 0 0 0 0]
[ 0 0 0 0 0 0 255 255 255 255 255 255 0 0 0 0 0 0]
[ 0 0 0 0 0 0 255 255 255 255 255 255 0 0 0 0 0 0]
[ 0 0 0 0 0 0 255 255 255 255 255 255 0 0 0 0 0 0]
[ 0 0 0 0 0 0 255 255 255 255 255 255 0 0 0 0 0 0]
[ 0 0 0 0 0 0 255 255 255 255 255 255 0 0 0 0 0 0]
[255 255 255 255 255 255 0 0 0 0 0 0 255 255 255 255 255 255]
[255 255 255 255 255 255 0 0 0 0 0 0 255 255 255 255 255 255]
[255 255 255 255 255 255 0 0 0 0 0 0 255 255 255 255 255 255]
[255 255 255 255 255 255 0 0 0 0 0 0 255 255 255 255 255 255]
[255 255 255 255 255 255 0 0 0 0 0 0 255 255 255 255 255 255]
[255 255 255 255 255 255 0 0 0 0 0 0 255 255 255 255 255 255]
[ 0 0 0 0 0 0 255 255 255 255 255 255 0 0 0 0 0 0]
[ 0 0 0 0 0 0 255 255 255 255 255 255 0 0 0 0 0 0]
[ 0 0 0 0 0 0 255 255 255 255 255 255 0 0 0 0 0 0]
[ 0 0 0 0 0 0 255 255 255 255 255 255 0 0 0 0 0 0]
[ 0 0 0 0 0 0 255 255 255 255 255 255 0 0 0 0 0 0]
[ 0 0 0 0 0 0 255 255 255 255 255 255 0 0 0 0 0 0]]

2. 访问单个像素
- 要访问numpy矩阵中的任何像素,必须使用矩阵表示法,例如matrix[r,c],其中r是行号,c是列号。还要注意,矩阵是0索引的。
- 例如,如果要访问第一个像素,则需要指定矩阵[0,0]。让我们看一些例子。我们将从左上角打印一个黑色像素,从上中心打印一个白色像素。
print(cb_img[0,0])
print(cb_img[0,6])
0
255
2.2 修改图像像素
cb_img_copy = cb_img.copy()
cb_img_copy[2,2] = 200
cb_img_copy[2,3] = 200
cb_img_copy[3,2] = 200
cb_img_copy[3,3] = 200
plt.imshow(cb_img_copy, cmap='gray')
print(cb_img_copy)
[[ 0 0 0 0 0 0 255 255 255 255 255 255 0 0 0 0 0 0]
[ 0 0 0 0 0 0 255 255 255 255 255 255 0 0 0 0 0 0]
[ 0 0 200 200 0 0 255 255 255 255 255 255 0 0 0 0 0 0]
[ 0 0 200 200 0 0 255 255 255 255 255 255 0 0 0 0 0 0]
[ 0 0 0 0 0 0 255 255 255 255 255 255 0 0 0 0 0 0]
[ 0 0 0 0 0 0 255 255 255 255 255 255 0 0 0 0 0 0]
[255 255 255 255 255 255 0 0 0 0 0 0 255 255 255 255 255 255]
[255 255 255 255 255 255 0 0 0 0 0 0 255 255 255 255 255 255]
[255 255 255 255 255 255 0 0 0 0 0 0 255 255 255 255 255 255]
[255 255 255 255 255 255 0 0 0 0 0 0 255 255 255 255 255 255]
[255 255 255 255 255 255 0 0 0 0 0 0 255 255 255 255 255 255]
[255 255 255 255 255 255 0 0 0 0 0 0 255 255 255 255 255 255]
[ 0 0 0 0 0 0 255 255 255 255 255 255 0 0 0 0 0 0]
[ 0 0 0 0 0 0 255 255 255 255 255 255 0 0 0 0 0 0]
[ 0 0 0 0 0 0 255 255 255 255 255 255 0 0 0 0 0 0]
[ 0 0 0 0 0 0 255 255 255 255 255 255 0 0 0 0 0 0]
[ 0 0 0 0 0 0 255 255 255 255 255 255 0 0 0 0 0 0]
[ 0 0 0 0 0 0 255 255 255 255 255 255 0 0 0 0 0 0]]

2.3 裁剪图像
img_NZ_bgr = cv2.imread("New_Zealand_Boat.jpg",cv2.IMREAD_COLOR)
img_NZ_rgb = img_NZ_bgr[:,:,::-1]
plt.figure(figsize=[20,5])
plt.subplot(141);plt.imshow(img_NZ_rgb);plt.title("RGB");
plt.subplot(142);plt.imshow(img_NZ_bgr);plt.title("BGR");

下面裁剪图片中间的某一部分:
Numpy 多维数组的切片是原始数组的
浅拷贝,切片修改后原始数组也会改变。推荐采用.copy()进行深拷贝,得到原始图像的副本。
cropped_region = img_NZ_rgb[200:400, 300:600].copy()
plt.imshow(cropped_region)

2.4 调整图像大小cv2.resize
resize函数可以调整图像的大小,其语法为: dst = resize( src, dsize[, dst[, fx[, fy[, interpolation]]]] )
参数说明:
scr/ dst:输入输出图像,二者类型相同dsize: 输出图像的大小,二元元组 (width, height)fx, fy:x 轴、y 轴上的缩放比例,可选项(dsize = None时)interpolation:插值方法,整型,可选项- cv2.INTER_LINEAR:双线性插值(默认方法)
- cv2.INTER_AREA:使用像素区域关系重采样,缩小图像时可以避免波纹出现
- cv2.INTER_NEAREST:最近邻插值
- cv2.INTER_CUBIC:4×4 像素邻域的双三次插值
-
cv2.INTER_LANCZOS4:8×8 像素邻域的Lanczos插值
-
使用
fx, fy指定缩放比例 - 使用dsize指定输出图像大小
- 保持高宽比的同时调整大小
resized_cropped_region_2x = cv2.resize(cropped_region,None,fx=2, fy=2)
resized_cropped_region = cv2.resize(cropped_region, dsize=(100,200), interpolation=cv2.INTER_AREA)
desired_width = 100
aspect_ratio = desired_width / cropped_region.shape[1]
desired_height = int(cropped_region.shape[0] * aspect_ratio)
dim = (desired_width, desired_height)
keep_aspect_ratio_region = cv2.resize(cropped_region, dsize=dim, interpolation=cv2.INTER_AREA)
plt.figure(figsize=[20,5])
plt.subplot(141);plt.imshow(resized_cropped_region_2x);plt.title("resized_cropped_region_2x");
plt.subplot(142);plt.imshow(resized_cropped_region);plt.title("(resized_cropped_region");
plt.subplot(143);plt.imshow(keep_aspect_ratio_region);plt.title("aspect ratio");

4. 显示裁剪图片真实大小
resized_cropped_region_2x = resized_cropped_region_2x[:,:,::-1]
cv2.imwrite("resized_cropped_region_2x.png", resized_cropped_region_2x)
Image(filename='resized_cropped_region_2x.png')

2.5 图像翻转cv2.flip
函数cv2.flip可以进行图像的翻转,包括水平翻转(沿x轴)、垂直翻转(沿y轴)和水平垂直翻转(两个轴同时翻转),函数语法为: dst=flip(src, flipCode[, src])
scr/ dst:输入输出图像flipCode:指定如何翻转的标志;0表示围绕x轴翻转,正值(例如,1)表示围绕y轴翻转。负值(例如-1)表示围绕两个轴翻转。
img = cv2.imread("../images/Fractal03.png")
imgFlip1 = cv2.flip(img, 0)
imgFlip2 = cv2.flip(img, 1)
imgFlip3 = cv2.flip(img, -1)
plt.figure(figsize=(9, 6))
plt.subplot(221), plt.axis('off'), plt.title("Original")
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
plt.subplot(222), plt.axis('off'), plt.title("Flipped Horizontally")
plt.imshow(cv2.cvtColor(imgFlip2, cv2.COLOR_BGR2RGB))
plt.subplot(223), plt.axis('off'), plt.title("Flipped Vertically")
plt.imshow(cv2.cvtColor(imgFlip1, cv2.COLOR_BGR2RGB))
plt.subplot(224), plt.axis('off'), plt.title("Flipped Horizontally & Vertically")
plt.imshow(cv2.cvtColor(imgFlip3, cv2.COLOR_BGR2RGB))
plt.show()

三、 为图像添加注释(画线、圆、矩形和文本注释)
在本章中,我们将介绍如何使用OpenCV注释图像。我们将学习如何对图像执行以下注释:
- 绘制线条
- 绘制圆
- 绘制矩形
- 添加文本
当您想在演示文稿中注释结果或演示应用程序时,这些工具非常有用。注释在开发和调试期间也很有用。
import cv2
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
%matplotlib inline
import matplotlib
matplotlib.rcParams['figure.figsize'] = (9.0, 9.0)
from IPython.display import Image
image = cv2.imread("Apollo_11_Launch.jpg", cv2.IMREAD_COLOR)
plt.imshow(image[:,:,::-1])

3.1 画条线cv2.line
使用cv2.line函数可以在图片上画条线,其语法为: img = cv2.line(img, pt1, pt2, color[, thickness[, lineType[, shift]]])。
参数说明:
- img:我们将在其上绘制线的图像
- pt1:线段的第一点(x,y位置)
- pt2:线段的第二个点
- color:将绘制的线的颜色
- thickness:指定线条厚度的整数,默认值为1,可选。如果设定为负值,会报错。
- lineType:线的类型,可选,默认值为8,表示8-connected line。通常,lineType使用cv2.LINE_AA(抗锯齿或平滑线)。
imageLine = image.copy()
cv2.line(imageLine, (200, 50), (400, 50), (255, 255, 0), thickness=2, lineType=cv2.LINE_AA);
plt.imshow(imageLine[:,:,::-1])

3.2 画个圆cv2.circle
使用 cv2.circle函数可以在图片上画个圆,其语法为: img = cv2.circle(img, center, radius, color[, thickness[, lineType[, shift]]])。其中 center, radius, color分别表示圆的圆心、半径和颜色。
imageCircle = image.copy()
cv2.circle(imageCircle, (290,485), 30, (0, 0, 255), thickness=2, lineType=cv2.LINE_AA);
plt.imshow(imageCircle[:,:,::-1])

3.3 画个矩形cv2.rectangle
使用cv2.rectangle函数可以在图像上绘制矩形,函数语法为: img = cv2.rectangle(img, pt1, pt2, color[, thickness[, lineType[, shift]]])。其中, pt1,pt2为矩形顶点,通常使用左上角和右下角顶点。
imageRectangle = image.copy()
cv2.rectangle(imageRectangle, (350, 310), (550,430), (255, 0, 255), thickness=2, lineType=cv2.LINE_8);
plt.imshow(imageRectangle[:,:,::-1])

3.4 添加文本注释cv2.putText
使用cv2.putText函数可以在图像上添加文本注释(不支持中文字符),其语法为 img = cv2.putText(img, text, org, fontFace, fontScale, color[, thickness[, lineType[, bottomLeftOrigin]]])。参数说明如下:
- text:要写入的文本字符串。
- org:图像中文本字符串的左下角。
- fontFace:字体类型
- fontScale:字体比例因子
imageText = image.copy()
text = "Apollo 11 Saturn V Launch, July 16, 1969"
fontFace = cv2.FONT_HERSHEY_PLAIN
cv2.putText(imageText,text,(150,580),fontFace, 2.3,(0,255,255),2,cv2.LINE_AA);
plt.imshow(imageText[:,:,::-1])

3.5 添加中文注释
在图像中添加中文字符,可以使用 python+opencv+PIL 实现,或使用 python+opencv+freetype 实现。
imgBGR = cv2.imread("../images/imgLena.tif")
from PIL import Image, ImageDraw, ImageFont
if (isinstance(imgBGR, np.ndarray)):
imgPIL = Image.fromarray(cv2.cvtColor(imgBGR, cv2.COLOR_BGR2RGB))
text = "OpenCV2021, 中文字体"
pos = (50, 20)
color = (255, 255, 255)
textSize = 40
drawPIL = ImageDraw.Draw(imgPIL)
fontText = ImageFont.truetype("font/simsun.ttc", textSize, encoding="utf-8")
drawPIL.text(pos, text, color, font=fontText)
imgPutText = cv2.cvtColor(np.asarray(imgPIL), cv2.COLOR_RGB2BGR)
cv2.imshow("imgPutText", imgPutText)
key = cv2.waitKey(0)

四、基本图像增强(数值运算)
图像处理技术利用数学运算获得不同的结果。通常,我们使用一些基本操作可以得到图像的简单增强。在本章中,我们将介绍:
- 算术运算,如加法、乘法
- 阈值和屏蔽(masking)
- 按位运算,如OR、AND、XOR
import cv2
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
%matplotlib inline
from IPython.display import Image
下面用opencv读取一张新西兰海岸照
img_bgr = cv2.imread("New_Zealand_Coast.jpg",cv2.IMREAD_COLOR)
img_rgb = cv2.cvtColor(img_bgr, cv2.COLOR_BGR2RGB)
Image(filename='New_Zealand_Coast.jpg')

4.1 加法 (cv2.add)
函数 cv2.add()用于图像的加法运算,其语法为 dst=cv2.add(src1, src2 [, dst[, mask[, dtype]])
scr1, scr2:进行加法运算的图像,或一张图像与一个 numpy array 标量mask:掩模图像,8位灰度格式;掩模图像数值为 0 的像素,输出图像对应像素的各通道值也为 0(被mask位置像素输出为0)。可选项,默认值为 None。dtype:图像数组的深度,即每个像素值的位数,可选项
需要注意的是,OpenCV 加法和 numpy 加法之间有区别:cv2.add() 是饱和运算(相加后如大于 255 则结果为 255),而 Numpy 加法是模运算。
4.1.1 图像与标量相加/亮度
本节讨论图像加法的简单操作——图像与标量相加,这会导致图像亮度的增加或减少,因为我们最终会对每个像素值增加或减少相同的值。(亮度会全局地增加/减少)
matrix = np.ones(img_rgb.shape, dtype = "uint8") * 50
img_rgb_brighter = cv2.add(img_rgb, matrix)
img_rgb_darker = cv2.subtract(img_rgb, matrix)
plt.figure(figsize=[18,5])
plt.subplot(131); plt.imshow(img_rgb_darker); plt.title("Darker");
plt.subplot(132); plt.imshow(img_rgb); plt.title("Original");
plt.subplot(133); plt.imshow(img_rgb_brighter);plt.title("Brighter");

另外,图像也可以与常数相加。下面进行常数相加和标量相加的对比:
Value =70
Scalar = np.ones((1, 3), dtype="float") * Value
imgAddV = cv2.add(img_bgr , Value)
imgAddS = cv2.add(img_bgr , Scalar)
print("Shape of scalar", Scalar)
for i in range(1, 6):
x, y = i*10, i*10
print("(x,y)={},{}, img_bgr:{}, imgAddV:{}, imgAddS:{}"
.format(x,y,img_bgr [x,y],imgAddV[x,y],imgAddS[x,y]))
Shape of scalar [[70. 70. 70.]]
(x,y)=10,10, img_bgr:[184 179 170], imgAddV:[254 179 170], imgAddS:[254 249 240]
(x,y)=20,20, img_bgr:[185 179 172], imgAddV:[255 179 172], imgAddS:[255 249 242]
(x,y)=30,30, img_bgr:[189 182 173], imgAddV:[255 182 173], imgAddS:[255 252 243]
(x,y)=40,40, img_bgr:[187 181 174], imgAddV:[255 181 174], imgAddS:[255 251 244]
(x,y)=50,50, img_bgr:[193 188 179], imgAddV:[255 188 179], imgAddS:[255 255 249]
plt.figure(figsize=[18,5])
plt.subplot(131), plt.title("1. img1"), plt.axis('off')
plt.imshow(cv2.cvtColor(img_bgr , cv2.COLOR_BGR2RGB))
plt.subplot(132), plt.title("2. img + constant"), plt.axis('off')
plt.imshow(cv2.cvtColor(imgAddV, cv2.COLOR_BGR2RGB))
plt.subplot(133), plt.title("3. img + scalar"), plt.axis('off')
plt.imshow(cv2.cvtColor(imgAddS, cv2.COLOR_BGR2RGB))
plt.show()

- 将图像与一个常数 value 相加,只是将 B 通道即蓝色分量与常数相加,而 G、R 通道的数值不变,因此图像发蓝。
- 将图像与一个标量 scalar 相加,”标量” 是指一个 1×3 的 numpy 数组,此时 B/G/R 通道分别与数组中对应的常数相加,因此图像发白。(数组中各元素可不相同)
4.1.2 图像的加法运算
img1 = cv2.imread("../images/imgB1.jpg")
img2 = cv2.imread("../images/imgB3.jpg")
imgAddCV = cv2.add(img1, img2)
imgAddNP = img1 + img2
plt.subplot(221), plt.title("1. img1"), plt.axis('off')
plt.imshow(cv2.cvtColor(img1, cv2.COLOR_BGR2RGB))
plt.subplot(222), plt.title("2. img2"), plt.axis('off')
plt.imshow(cv2.cvtColor(img2, cv2.COLOR_BGR2RGB))
plt.subplot(223), plt.title("3. cv2.add(img1, img2)"), plt.axis('off')
plt.imshow(cv2.cvtColor(imgAddCV, cv2.COLOR_BGR2RGB))
plt.subplot(224), plt.title("4. img1 + img2"), plt.axis('off')
plt.imshow(cv2.cvtColor(imgAddNP, cv2.COLOR_BGR2RGB))
plt.show()

- 图 3 是
cv2.add()饱和加法的结果,图 4 是numpy取模加法的结果。 - 饱和加法以 255 为上限,所有像素只会变的更白(大于原值);取模加法以 255 为模,会导致部分像素变黑 (小于原值)。
- 因此,一般情况下应使用 cv2.add 进行饱和加法操作,不宜使用 numpy 取模加法。
4.1.3 图像的加权加法cv2.addWeight(渐变切换)
函数 cv2.addWeight() 用于图像的加权加法运算,可以实现图像的叠加和混合。其语法为: dst=cv2.addWeighted(src1, alpha, src2, beta, gamma[, dst[, dtype]]) 。简单理解就是:d s t = s r c 1 ∗ a l p h a + s r c 2 ∗ b e t a + g a m m a dst = src1 * alpha + src2 * beta + gamma d s t =src 1 ∗a lp ha +src 2 ∗b e t a +g amma
alpha/beta:第一、二张图像 的权重,通常取为 0~1 之间的浮点数gamma: 灰度系数,图像校正的偏移量,用于调节亮度dtype:输出图像的深度,即每个像素值的位数,可选项,default=src1.depth()- 推荐取 beta=1-alpha, gamma=0
img1 = cv2.imread("../images/imgGaia.tif")
img2 = cv2.imread("../images/imgLena.tif")
imgAddW1 = cv2.addWeighted(img1, 0.2, img2, 0.8, 0)
imgAddW2 = cv2.addWeighted(img1, 0.5, img2, 0.5, 0)
imgAddW3 = cv2.addWeighted(img1, 0.8, img2, 0.2, 0)
plt.subplot(131), plt.title("1. a=0.2, b=0.8"), plt.axis('off')
plt.imshow(cv2.cvtColor(imgAddW1, cv2.COLOR_BGR2RGB))
plt.subplot(132), plt.title("2. a=0.5, b=0.5"), plt.axis('off')
plt.imshow(cv2.cvtColor(imgAddW2, cv2.COLOR_BGR2RGB))
plt.subplot(133), plt.title("3. a=0.8, b=0.2"), plt.axis('off')
plt.imshow(cv2.cvtColor(imgAddW3, cv2.COLOR_BGR2RGB))
plt.show()

不同尺寸图像的相加,可先将二者调整到同一尺寸,方法见本章4.6节。
4.2 乘法/对比度(cv2.multiply)
就像加法会导致亮度变化一样,乘法也可以用来提高图像的对比度。
对比度是图像像素值的差异。将像素值与常数相乘可以使差值变大或变小(如果乘法因子小于1)。
matrix1 = np.ones(img_rgb.shape) * 0.5
matrix2 = np.ones(img_rgb.shape) * 1.5
img_rgb_darker = np.uint8(cv2.multiply(np.float64(img_rgb), matrix1))
img_rgb_brighter = np.uint8(cv2.multiply(np.float64(img_rgb), matrix2))
plt.figure(figsize=[18,5])
plt.subplot(131); plt.imshow(img_rgb_darker); plt.title("Lower Contrast");
plt.subplot(132); plt.imshow(img_rgb); plt.title("Original");
plt.subplot(133); plt.imshow(img_rgb_brighter);plt.title("Higher Contrast");

右边图会发现图像的某些区域看到奇怪的颜色,这是因为相乘后某些像素值>255,已经溢出,这该如何处理呢?
4.3 使用np.clip处理溢出
img_rgb_higher = np.uint8(np.clip(cv2.multiply(np.float64(img_rgb), matrix2),0,255))
plt.figure(figsize=[18,5])
plt.subplot(131); plt.imshow(img_rgb_lower); plt.title("Lower Contrast");
plt.subplot(132); plt.imshow(img_rgb); plt.title("Original");
plt.subplot(133); plt.imshow(img_rgb_higher);plt.title("Higher Contrast");

4.4 图像阈值(cv2.threshold)
4.4.1 阈值处理基础
阈值就是临界值。根据阈值可将图像划分为多个区域,或提取图像中的目标物体,是最基本的阈值处理方法。图像阈值处理简单、直观,计算速度快,是图像处理的基础操作,在图像分割中处于核心地位。
例如,图像由暗色背景上的亮目标组成,目标像素和背景像素的灰度值组合构成两种主要模式,可以通过设定适当的阈值 T,将图像的像素划分为两类:灰度值大于 T 的像素集是目标,小于 T 的像素集是背景。
当 T 是应用于整幅图像的常数,称为 全局阈值处理;当 T 对于整幅图像发生变化时,称为 可变阈值处理。有时,对应于图像中任一点的 T 值取决于该点的邻域的限制,称为 局部阈值处理。
4.4.2 固定阈值处理函数cv.threshold
OpenCV 提供了函数 cv.threshold 可以对图像进行阈值处理。此函数可以将灰度图像转换为二值图像(将灰度大于阈值的像素点置为255,小于阈值的像素点置为0,得到二值图像,可以突出图像轮廓,把目标从背景中分割出来)。或用于消除噪声,即过滤出值太小或太大的像素。
二值图像在图像处理中有很多用例,最常见的用例之一是创建掩码。图像蒙版允许我们对图像的特定部分进行处理,使其他部分保持完整。
cv2.threshold函数语法为: retval, dst = cv2.threshold( src, thresh, maxval, type[, dst] )
参数说明:
dst:阈值变化后的图像,与src具有相同大小和类型以及通道数的输出数组。src:输入数组(多通道,8位或32位浮点,文档确实这么写的)。thresh:阈值。retval:阈值,浮点型maxval:用于THRESH_BINARY和THRESH_MINARY_INV阈值类型的最大值,一般取 255。type:阈值类型(请参见阈值类型)。- cv2.THRESH_BINARY:大于阈值时置 255,否则置 0
- cv2.THRESH_BINARY_INV:大于阈值时置 0,否则置 255
- cv2.THRESH_TRUNC:大于阈值时置为阈值 thresh,否则不变(保持原色)
- cv2.THRESH_TOZERO:大于阈值时不变(保持原色),否则置 0
- cv2.THRESH_TOZERO_INV:大于阈值时置 0,否则不变(保持原色)
- cv2.THRESH_OTSU:使用 OTSU 算法选择阈值
- 确切地说,只有 type 为
cv2.THRESH_BINARY或cv2.THRESH_BINARY_INV时输出为二值图像,其它变换类型时进行阈值处理但并不是二值处理。
特殊值THRESH_OTSU或THRESH_TRIANGLE可以与上述值之一组合。在这些情况下,函数使用Otsu或Triangle算法确定最佳阈值,并使用它代替指定的阈值。Otsu和Triangle方法仅用于8位单通道图像。
当图像中存在高斯噪声时,通常难以通过全局阈值将图像的边界完全分开。如果图像的边界是在局部对比下出现的,不同位置的阈值也不同,使用全局阈值的效果将会很差。如果图像的直方图存在明显边界,容易找到图像的分割阈值;但如果图像直方图分界不明显,则很难找到合适的阈值,甚至可能无法找到固定的阈值有效地分割图像。
img_read = cv2.imread("building-windows.jpg", 0)
retval, img_thresh = cv2.threshold(img_read, 100, 255, cv2.THRESH_BINARY)
plt.figure(figsize=[18,5])
plt.subplot(121); plt.imshow(img_read, cmap="gray"); plt.title("Original");
plt.subplot(122); plt.imshow(img_thresh, cmap="gray"); plt.title("Thresholded");
print(retval,img_thresh.shape)
(572, 800) 100.0 (572, 800)

4.4.3 全局阈值处理 Otsu 方法(可跳过本节)
当图像中的目标和背景的灰度分布较为明显时,可以对整个图像使用固定阈值进行全局阈值处理。 为了获得适当的全局阈值,可以基于灰度直方图进行迭代计算(详见【youcans 的 OpenCV 例程200篇】159. 图像分割之全局阈值处理),另一种改进算法是OTSU 方法(又称大津算法)。使用最大化类间方差(intra-class variance)作为评价准则,基于对图像直方图的计算,可以给出类间最优分离的最优阈值。
任取一个灰度值 T,可以将图像分割为两个集合 F 和 B,集合 F、B 的像素数的占比分别为 pF、pB,集合 F、B 的灰度值均值分别为 mF、mB,图像灰度值为 m,定义类间方差为:
I C V = p F ∗ ( m F − m ) 2 + p B ∗ ( m B − m ) 2 ICV = p_F * (m_F – m)^2 + p_B * (m_B – m)^2 I C V =p F ∗(m F −m )2 +p B ∗(m B −m )2
使类间方差 ICV 最大化的灰度值 T 就是最优阈值。因此,只要遍历所有的灰度值,就可以得到使 ICV 最大的最优阈值 T。
OpenCV 提供了函数 cv.threshold 可以对图像进行阈值处理,将参数 type 设为 cv.THRESH_OTSU,就可以使用使用 OTSU 算法进行最优阈值分割。
img = cv2.imread("../images/Fig1039a.tif", flags=0)
deltaT = 1
histCV = cv2.calcHist([img], [0], None, [256], [0, 256])
grayScale = range(256)
totalPixels = img.shape[0] * img.shape[1]
totalGray = np.dot(histCV[:,0], grayScale)
T = round(totalGray/totalPixels)
while True:
numC1, sumC1 = 0, 0
for i in range(T):
numC1 += histCV[i,0]
sumC1 += histCV[i,0] * i
numC2, sumC2 = (totalPixels-numC1), (totalGray-sumC1)
T1 = round(sumC1/numC1)
T2 = round(sumC2/numC2)
Tnew = round((T1+T2)/2)
print("T={}, m1={}, m2={}, Tnew={}".format(T, T1, T2, Tnew))
if abs(T-Tnew) < deltaT:
break
else:
T = Tnew
ret1, imgBin = cv2.threshold(img, T, 255, cv2.THRESH_BINARY)
ret2, imgOtsu = cv2.threshold(img, T, 255, cv2.THRESH_OTSU)
print(ret1, ret2)
plt.figure(figsize=(7,7))
plt.subplot(221), plt.axis('off'), plt.title("Origin"), plt.imshow(img, 'gray')
plt.subplot(222, yticks=[]), plt.title("Gray Hist")
histNP, bins = np.histogram(img.flatten(), bins=255, range=[0, 255], density=True)
plt.bar(bins[:-1], histNP[:])
plt.subplot(223), plt.title("global binary(T={})".format(T)), plt.axis('off')
plt.imshow(imgBin, 'gray')
plt.subplot(224), plt.title("OTSU binary(T={})".format(round(ret2))), plt.axis('off')
plt.imshow(imgOtsu, 'gray')
plt.tight_layout()
plt.show()

全局阈值处理还有一些其它改进方法,比如处理前先对图像进行平滑、基于边缘信息改进全局阈值处理等等。
4.4.4 自适应阈值处理函数cv.adaptiveThreshold
噪声和非均匀光照等因素对阈值处理的影响很大,例如光照复杂时 Otsu 算法等全局阈值分割方法的效果往往不太理想,需要使用 可变阈值处理。
可变阈值是指对于图像中的每个像素点或像素块有不同的阈值,如果该像素点大于其对应的阈值则认为是前景。可变阈值处理的基本方法,是 对图像中的每个点,根据其邻域的性质计算阈值。标准差和均值是对比度和平均灰度的描述,在局部阈值处理中非常有效。
局部阈值分割可以根据图像的局部特征进行处理,与图像像素位置、灰度值及邻域特征值有关。
cv.adaptiveThreshold为自适应阈值的二值化处理函数,可以通过比较像素点与周围像素点的关系动态调整阈值。函数语法: dst = cv.adaptiveThreshold( src, maxValue, adaptiveMethod, thresholdType, blockSize, C[, dst] )。可以 根据参数 adaptiveMethod确定自适应阈值的计算方法。
参数说明:
dst:与src大小和类型相同的目标图像。src:8位单通道图像。maxValue:为满足条件的像素指定的非零值,详见阈值类型说明。adaptiveMethod:要使用的自适应阈值算法- cv.ADAPTIVE_THRESH_MEAN_C:阈值是邻域的均值
- cv.ADAPTIVE_THRESH_GAUSSIAN_C:阈值是邻域的高斯核加权均值
- 其它请参考AdaptiveThresholdTypes。
thresholdType:阈值类型,必须是THRESH_BINARY或THRESH_MINARY_INV。cv2.THRESH_BINARY:大于阈值时置 maxValue,否则置 0cv2.THRESH_BINARY_INV:大于阈值时置 0,否则置 maxValueblockSize:用于计算像素阈值的像素邻域的尺寸,可以取3、5、7,依此类推。C: 偏移量,从平均值或加权平均值中减去该常数。
4.4.5 应用:乐谱阅读器
假设您想构建一个可以读取(解码)乐谱的应用程序。这类似于文本文档的光学字符识别(OCR,其目标是识别文本字符)。
在这两种应用程序中,处理管道的第一步是隔离文档图像中的重要信息(将其与背景分离)。这项任务可以通过阈值技术来完成。让我们看一个例子:
img_read = cv2.imread("Piano_Sheet_Music.png", 0)
retval, img_thresh_gbl_1 = cv2.threshold(img_read,50, 255, cv2.THRESH_BINARY)
retval, img_thresh_gbl_2 = cv2.threshold(img_read,130, 255, cv2.THRESH_BINARY)
img_thresh_adp = cv2.adaptiveThreshold(img_read, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 11, 7)
plt.figure(figsize=[18,15])
plt.subplot(221); plt.imshow(img_read, cmap="gray"); plt.title("Original");
plt.subplot(222); plt.imshow(img_thresh_gbl_1,cmap="gray"); plt.title("Thresholded (global: 50)");
plt.subplot(223); plt.imshow(img_thresh_gbl_2,cmap="gray"); plt.title("Thresholded (global: 130)");
plt.subplot(224); plt.imshow(img_thresh_adp, cmap="gray"); plt.title("Thresholded (adaptive)");

4.5 按位运算
位运算包括: cv2.bitwise_and(). 、 cv2.bitwise_or()、 cv2.bitwise_xor()和 cv2.bitwise_not()。比如and位运算语法为: dst = cv2.bitwise_and( src1, src2[, dst[, mask]] )
- src1:第一个输入数组或标量。
- src2:第二个输入数组或标量。
- mask:可选,8位单通道数组,指定哪些像素会被运算操作。
正常读取一张矩形图和一张圆形图:
img_rec = cv2.imread("rectangle.jpg", 0)
img_cir = cv2.imread("circle.jpg", 0)
plt.figure(figsize=[20,5])
plt.subplot(121);plt.imshow(img_rec,cmap='gray')
plt.subplot(122);plt.imshow(img_cir,cmap='gray')
print(img_rec.shape,img_cir.shape)
(200, 499) (200, 499)

下面依次进行and、or、xor操作
img_and = cv2.bitwise_and(img_rec, img_cir, mask = None)
img_or= cv2.bitwise_or(img_rec, img_cir, mask = None)
img_xor= cv2.bitwise_xor(img_rec, img_cir, mask = None)
img_not=cv2.bitwise_not(img_rec, img_cir, mask = None)
plt.figure(figsize=[10,5])
plt.subplot(221); plt.imshow(img_and,cmap="gray"); plt.title("AND");
plt.subplot(222); plt.imshow(img_or,cmap="gray"); plt.title("OR");
plt.subplot(223); plt.imshow(img_xor,cmap="gray"); plt.title("XOR");
plt.subplot(224); plt.imshow(img_not,cmap="gray"); plt.title("NOT");

4.6 图像的叠加:制作coca-cola彩色Logo
两张图像直接进行加法运算后图像的颜色会改变,通过加权加法实现图像混合后图像的透明度会改变,都不能实现图像的叠加。
实现图像的叠加,需要综合运用图像阈值处理、图像掩模、位操作和图像加法的操作。下面展示如何用背景图像填充可口可乐Logo的白色字母。
Image(filename='Logo_Manipulation.png')

- 读取logo图片和背景图片,调整后者尺寸使二者尺寸相同
- 对前景图片(logo)进行二值化处理,生成黑白掩模图像 mask及其反转掩模图像 mask_Inv
- 以黑白掩模 mask作为掩模,对背景图像进行位操作,得到叠加背景图片Add_Background(只得到彩色logo)
- 以反转掩模 mask_Inv作为掩模,对前景图像进行位操作,得到叠加前景图像Foreground;(只得到除logo之外的区域)
- 二者通过 cv2.add 加法运算,得到叠加图像
1.读取Logo图片
img_bgr = cv2.imread("coca-cola-logo.png")
img_rgb = cv2.cvtColor(img_bgr, cv2.COLOR_BGR2RGB)
logo_w,logo_h = img_rgb.shape[0],img_rgb.shape[1]
print(img_rgb.shape)
(700, 700, 3)
- 读取背景图片
img_background_bgr = cv2.imread("checkerboard_color.png")
img_background_rgb = cv2.cvtColor(img_background_bgr, cv2.COLOR_BGR2RGB)
aspect_ratio = logo_w / img_background_rgb.shape[1]
dim = (logo_w, int(img_background_rgb.shape[0] * aspect_ratio))
img_background_rgb = cv2.resize(img_background_rgb, dim, interpolation=cv2.INTER_AREA)
print(img_background_rgb.shape)
(700, 700, 3)
- 创建掩码mask
img_gray = cv2.cvtColor(img_rgb, cv2.COLOR_RGB2GRAY)
retval, img_mask = cv2.threshold(img_gray,127,255,cv2.THRESH_BINARY)
print(img_mask.shape)
- 反转mask
img_mask_inv = cv2.bitwise_not(img_mask)
plt.figure(figsize=[8,8])
plt.subplot(221); plt.imshow(img_rgb); plt.title("RGB");
plt.subplot(222); plt.imshow(img_background_rgb); plt.title("Background");
plt.subplot(223); plt.imshow(img_mask,cmap="gray"); plt.title("Mask");
plt.subplot(224); plt.imshow(img_mask_inv,cmap="gray"); plt.title("Mask_inv");

- mask图像加上背景
img_background = cv2.bitwise_and(img_background_rgb, img_background_rgb, mask=img_mask)
plt.imshow(img_background)
- 将前景与图像分开
img_foreground = cv2.bitwise_and(img_rgb, img_rgb, mask=img_mask_inv)
plt.imshow(img_foreground)
- 前景与背景相加得到最终结果
result = cv2.add(img_background,img_foreground)
plt.imshow(result)
cv2.imwrite("logo_final.png", result[:,:,::-1])
plt.figure(figsize=[15,5])
plt.subplot(141); plt.imshow(img_background); plt.title("Add_Background");
plt.subplot(142); plt.imshow(img_foreground); plt.title("Foreground");
plt.subplot(143); plt.imshow(result,cmap="gray"); plt.title("Result");

六、使用OpenCV编写视频
在构建应用程序时,保存工作的演示视频以及许多应用程序本身可能需要保存视频剪辑变得很重要。例如,在一个调查应用程序中,您可能必须在看到异常情况时立即保存视频剪辑。
在本章中,我们将描述如何使用openCV以 avi和 mp4格式保存视频。
6.1 cv2.VideoCapture读取视频
cv2.VideoCapture:
- 用于打开摄像头:
cap(捕获对象) = cv2.VideoCapture(“摄像头ID号”)。
”
摄像头ID号“就是摄像头的ID号码,默认值为-1,表示随机选取一个摄像头。
如果电脑有多个摄像头,则用数字0表示第一个,用数字1表示第二个,以此类推。所以,如果电脑只有一个摄像头,既可以用0,也可以用-1来作为摄像头的ID号。
- 用于读取视频:
cap(捕获对象) = cv2.VideoCapture(“filename”)
ret,frame = cap.read():按帧读取视频
- ret:布尔类型,如果读取帧是正确的则返回True,如果文件读取到结尾,它的返回值就为False
- frame:每一帧的图像,是个三维矩阵。
import cv2
import matplotlib.pyplot as plt
%matplotlib inline
source = './race_car.mp4'
cap = cv2.VideoCapture(source)
if (cap.isOpened()== False):
print("Error opening video stream or file")
6.2 读取并显示一帧
ret, frame = cap.read()
print(frame.shape)
plt.imshow(frame[...,::-1])
(1080, 1728, 3)

6.3 播放视频
下面的操作可以直接在当前notebook中播放视频:
from IPython.display import HTML
HTML("""
""")

6.4 使用OpenCV编写视频cv.VideoWriter
要编写视频,需要使用正确的参数创建视频编写器对象。函数语法为: VideoWriter object= cv.VideoWriter( filename, fourcc, fps, frameSize )
参数说明:
filename:输出视频文件的名称。fourcc:用于压缩帧的4字符编解码器代码。例如:VideoWriter::fourcc(’P’,’I’,’M’,’1’)是MPEG-1编解码器VideoSwriter::foorcc(’M’,’J’,’P’,’G’)是jpeg编解码器。- 可以通过fourcc页面在视频编解码器中获取编码列表。带有MP4容器的FFMPEG backend使用其他值作为fourcc代码,详情请参阅ObjectType。
fps:创建的视频流的帧速。frameSize:视频帧的大小。
frame_width = int(cap.get(3))
frame_height = int(cap.get(4))
out_avi = cv2.VideoWriter('race_car_out.avi',cv2.VideoWriter_fourcc('M','J','P','G'), 10, (frame_width,frame_height))
out_mp4 = cv2.VideoWriter('race_car_out.mp4',cv2.VideoWriter_fourcc(*'XVID'), 10, (frame_width,frame_height))
读取赛车视频中帧,并将其写入上一步中创建的两个对象,并在任务完成后释放对象。
while(cap.isOpened()):
ret, frame = cap.read()
if ret == True:
out_avi.write(frame)
out_mp4.write(frame)
else:
break
cap.release()
out_avi.release()
out_mp4.release()
原视频一共7s,其流帧速应该是ftp=30,创建的两个新的视频是21s(ftp=10)。
八、图片对齐(略)
第八章是图像对齐,主要是通过在两张图中找到关键点,再进行对齐,效果如下图所示:



最终结果如下:

具体的代码请查看源码,这里就不写了
; 九、创建全景(略)
代码量比较少,就放出来了。我主要也不是搞这个,就没有仔细研究了。
import cv2
import glob
import matplotlib.pyplot as plt
import math
imagefiles = glob.glob("boat/*")
imagefiles.sort()
images = []
for filename in imagefiles:
img = cv2.imread(filename)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
images.append(img)
num_images = len(images)
plt.figure(figsize=[30,10])
num_cols = 3
num_rows = math.ceil(num_images / num_cols)
for i in range(0, num_images):
plt.subplot(num_rows, num_cols, i+1)
plt.axis('off')
plt.imshow(images[i])

stitcher = cv2.Stitcher_create()
status, result = stitcher.stitch(images)
if status == 0:
plt.figure(figsize=[30,10])
plt.imshow(result)

十、HDR(略)

感觉就是处理异常曝光的图片,不研究,有兴趣的可以去看源码。
十一 、目标追踪( GOTURN)
本章将学习:
- 什么是追踪?
- 如何在计算机视图中跟踪。
-
Motion model and appearnace model.
-
OpenCV API Tracker Class。
什么是目标追踪?
目标追踪是跟踪视频序列中的对象。使用视频序列的帧和边界框来初始化跟踪算法,以指示我们感兴趣跟踪的目标的位置。追踪算法为所有后续帧输出一个边界框。
目标:给定对象的初始位置,跟踪后续帧中的位置

; 11.1 读取视频,定义函数
from IPython.display import HTML
HTML("""
""")
import cv2
import sys
import os
import matplotlib.pyplot as plt
from matplotlib.animation import FuncAnimation
from IPython.display import HTML
import urllib
video_input_file_name = "race_car.mp4"
def drawRectangle(frame, bbox):
p1 = (int(bbox[0]), int(bbox[1]))
p2 = (int(bbox[0] + bbox[2]), int(bbox[1] + bbox[3]))
cv2.rectangle(frame, p1, p2, (255,0,0), 2, 1)
def displayRectangle(frame, bbox):
plt.figure(figsize=(20,10))
frameCopy = frame.copy()
drawRectangle(frameCopy, bbox)
frameCopy = cv2.cvtColor(frameCopy, cv2.COLOR_RGB2BGR)
plt.imshow(frameCopy); plt.axis('off')
def drawText(frame, txt, location, color = (50,170,50)):
cv2.putText(frame, txt, location, cv2.FONT_HERSHEY_SIMPLEX, 1, color, 3)
11.2 GOTURN原理简介
GOTURN 是 Generic Object Tracking Using Regression Networks 的缩写,是一种基于深度学习的跟踪算法。 GOTURN 模型在数千个视频序列上进行训练,不需要在运行时执行任何学习。

如上图所示,
GOTURN 使用从数千个视频中剪切的一对帧来训练的,即 GOTURN 将两个裁剪的帧作为输入,并在第二帧中输出目标边界框。训练时:
- 在第一帧(也称为前一帧)中,目标的位置是已知的,并且该帧被裁剪成目标边界框的两倍大小,且第一个裁剪帧中,目标始终居中。
- 用于裁剪第一帧的边界框也用于裁剪第二帧。因为物体可能已经移动了,所以物体不在第二帧的中心。
- 训练卷积神经网络 (CNN) 以预测第二帧中边界框的位置。
GOTURN的网络结构

如上图所示,模型输入是两个帧。第一二行分别是当前帧和前一帧。
- 首先获取到上一帧的结果(第二行图),以中心为原点扩大一圈得到Rect,利用这个Rect裁剪当前帧
- 两帧都分别通过一组卷积层( CaffeNet 架构的前五个卷积层)
- 这些卷积层的输出(即 pool5 特征)被连接成一个长度为 4096 的向量,然后输入到 3 个全连接层。
- 最后一个全连接层最终连接到输出层,输出层包含代表边界框顶部和底部点的 4 个节点。
下面下载模型:
if not os.path.isfile('goturn.prototxt') or not os.path.isfile('goturn.caffemodel'):
print("Downloading GOTURN model zip file")
urllib.request.urlretrieve('https://www.dropbox.com/sh/77frbrkmf9ojfm6/AACgY7-wSfj-LIyYcOgUSZ0Ua?dl=1', 'GOTURN.zip')
!tar -xvf GOTURN.zip
os.remove('GOTURN.zip')
11.3 创建Tracker实例
首先要安装tracker包,版本号要和自己的opencv-python版本一致
pip install opencv-contrib-python==4.5.2.54
tracker_types = ['BOOSTING', 'MIL','KCF', 'CSRT', 'TLD', 'MEDIANFLOW', 'GOTURN','MOSSE']
tracker_type = tracker_types[2]
if tracker_type == 'BOOSTING':
tracker = cv2.legacy_TrackerBoosting.create()
elif tracker_type == 'MIL':
tracker = cv2.TrackerMIL_create()
elif tracker_type == 'KCF':
tracker = cv2.TrackerKCF_create()
elif tracker_type == 'CSRT':
tracker = cv2.legacy_TrackerCSRT.create()
elif tracker_type == 'TLD':
tracker = cv2.legacy_TrackerTLD.create()
elif tracker_type == 'MEDIANFLOW':
tracker = cv2.legacy_TrackerMedianFlow.create()
elif tracker_type == 'GOTURN':
tracker = cv2.TrackerGOTURN_create()
else:
tracker = cv2.legacy_TrackerMOSSE.create()
我还是卡在这一步,安装不了对应版本的tracker包,无法实例化tracker。下面只是给出代码,本人并没有跑通。
11.4 视频处理
读取视频并定义输出视频文件
video = cv2.VideoCapture(video_input_file_name)
ok, frame = video.read()
if not video.isOpened():
print("Could not open video")
sys.exit()
else :
width = int(video.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(video.get(cv2.CAP_PROP_FRAME_HEIGHT))
video_output_file_name = 'race_car-' + tracker_type + '.mp4'
video_out = cv2.VideoWriter(video_output_file_name,cv2.VideoWriter_fourcc(*'avc1'), 10, (width, height))
定义边界框
bbox = (1300, 405, 160, 120)
displayRectangle(frame,bbox)

初始化边界框
ok = tracker.init(frame, bbox)
11.5 读取帧并追踪目标
while True:
ok, frame = video.read()
if not ok:
break
timer = cv2.getTickCount()
ok, bbox = tracker.update(frame)
fps = cv2.getTickFrequency() / (cv2.getTickCount() - timer);
if ok:
drawRectangle(frame, bbox)
else :
drawText(frame, "Tracking failure detected", (80,140), (0, 0, 255))
drawText(frame, tracker_type + " Tracker", (80,60))
drawText(frame, "FPS : " + str(int(fps)), (80,100))
video_out.write(frame)
video.release()
video_out.release()
HTML("""
""")
HTML("""
""")
HTML("""
""")
十三、SSD目标检测(略)
十四、人体姿态估计(略)
Original: https://blog.csdn.net/qq_56591814/article/details/127275045
Author: 神洛华
Title: OpenCV官方教程节选
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/702944/
转载文章受原作者版权保护。转载请注明原作者出处!