

本文为打印机数据集的处理方法,以拍摄条件为25cm、顶光、0°的一组数据集为例。
目录
1.裁剪边框
该方法使用了OCR识别,即对文本资料进行扫描后对图像文件进行分析处理,获取文字及版面信息。
具体流程为:读取图像->预处理(转化为灰度图)->边缘检测->轮廓检测->轮廓近似->透视变换->OCR识别->保存图像
具体代码如下(文件读取为嵌套读取):
import numpy as np
import cv2
import os
def cv_show(name, img):
cv2.imshow(name, img)
cv2.waitKey(0)
cv2.destroyAllWindows()
def resize(image, width=None, height=None, inter=cv2.INTER_AREA):
dim = None
(h, w) = image.shape[:2]
if width is None and height is None:
return image
if width is None:
r = height / float(h)
dim = (int(w * r), height)
else:
r = width / float(w)
dim = (width, int(h * r))
resized = cv2.resize(image, dim, interpolation=inter)
return resized
def order_points(pts):
# 一共4个坐标点
rect = np.zeros((4, 2), dtype = "float32")
# 按顺序找到对应坐标0123分别是 左上,右上,右下,左下
# 计算左上,右下
s = pts.sum(axis = 1)
rect[0] = pts[np.argmin(s)]
rect[2] = pts[np.argmax(s)]
# 计算右上和左下
diff = np.diff(pts, axis = 1)
rect[1] = pts[np.argmin(diff)]
rect[3] = pts[np.argmax(diff)]
return rect
def four_point_transform(image, pts):
# 获取输入坐标点
rect = order_points(pts)
(tl, tr, br, bl) = rect
# 计算输入的w值,
widthA = np.sqrt(((br[0] - bl[0]) ** 2) + ((br[1] - bl[1]) ** 2))
widthB = np.sqrt(((tr[0] - tl[0]) ** 2) + ((tr[1] - tl[1]) ** 2))
maxWidth = max(int(widthA), int(widthB))
# 计算输入的h值
heightA = np.sqrt(((tr[0] - br[0]) ** 2) + ((tr[1] - br[1]) ** 2))
heightB = np.sqrt(((tl[0] - bl[0]) ** 2) + ((tl[1] - bl[1]) ** 2))
maxHeight = max(int(heightA), int(heightB))
# 变换后对应坐标位置
dst = np.array([
[0, 0],
[maxWidth - 1, 0],
[maxWidth - 1, maxHeight - 1],
[0, maxHeight - 1]], dtype = "float32")
# 计算变换矩阵,rect原始近视轮廓和目标轮廓的计算值
M = cv2.getPerspectiveTransform(rect, dst)
warped = cv2.warpPerspective(image, M, (maxWidth, maxHeight))
# 返回变换后结果
return warped
path="E://p"#数据集的地址
rootList = os.listdir(path)
for child in rootList:
savePath = "E://q"#数据集的保存地址
childpath=os.path.join(path,child)
childList=os.listdir(childpath)
saveDir=os.path.join(savePath,child)
try:
# 判断是否已经存在该目录
if not os.path.exists(saveDir):
# 目录不存在,进行创建操作
os.makedirs(saveDir) # 使用os.makedirs()方法创建多层目录
print("目录新建成功:" +saveDir)
else:
print("目录已存在!!!")
except BaseException as msg:
print("新建目录失败:" + msg)
for item in childList:
itemPath=os.path.join(childpath,item)
savePath=os.path.join(saveDir,item)
image = cv2.imread(itemPath)
if (itemPath.endswith(".jpg") == True):
# 得到比例供透视变换使用
ratio = image.shape[0] / 500
orig = image.copy()
# 将原图进行resize处理
image = resize(orig, height=500)
# 将图片进行预处理,转为灰度图
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 高斯滤波去除噪声
gray = cv2.GaussianBlur(gray, (5, 5), 0)
# 进行边缘检测
edged = cv2.Canny(gray, 75, 100)
# 轮廓检测
cnts = cv2.findContours(edged.copy(), cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)[0]
# 对检测的轮廓进行按照面积排序,并取出前五个
cnts = sorted(cnts, key=cv2.contourArea, reverse=True)[:5]
# 遍历轮廓
for c in cnts:
# 计算轮廓近似长度
# C表示输入的点集
# epsilon表示从原始轮廓到近似轮廓的最大距离,它是一个准确度参数
# True表示封闭的
peri = cv2.arcLength(c, True)
# 算出近似轮廓
approx = cv2.approxPolyDP(c, 0.02 * peri, True)
# 4个点的时候就拿出来(即是遍历的第一次)
if len(approx) == 4:
screenCnt = approx
# 画出轮廓
cv2.drawContours(image, [screenCnt], -1, (0, 255, 0), 2)
# 透视变换,转为方正的图像;输入原图,近似图,
warped = four_point_transform(orig, screenCnt.reshape(4, 2) * ratio)
# 转为灰度图
warped = cv2.cvtColor(warped, cv2.COLOR_BGR2GRAY)
# 阈值处理
# ref = cv2.threshold(warped, 100, 255, cv2.THRESH_BINARY)[1]
cv2.imwrite(savePath, warped)
cv2.waitKey(0)
运行之后,可得到以下效果图


(左图为处理前,右图为处理后)
ps:该处理方法可能会出现部分图片裁剪错误
2.分割数据集
将数据集按训练集和测试集6:1的比例分割,代码如下(文件读取为嵌套读取):
import os, random, shutil
def copyFile(fileDir,saveDir):
pathDir = os.listdir(fileDir)
print(pathDir)# 取图片的原始路径
filenumber = len(pathDir)
#rate = 0.01 # 自定义抽取图片的比例,比方说100张抽10张,那就是0.1
#picknumber = 1 # 按照rate比例从文件夹中取一定数量图片
sample = random.sample(pathDir, 1) # 随机选取picknumber数量的样本图片
#print(sample)
for name in sample:
shutil.move(os.path.join(fileDir, name), os.path.join(saveDir, name))
return
if __name__ == '__main__':
path = "E://dataset//train//25cm"#数据集路径
rootList = os.listdir(path)
for child in rootList:
savePath = "E://dataset//test//25cm"#测试集保存路径
childpath = os.path.join(path, child)
# childList = os.listdir(childpath)
saveDir = os.path.join(savePath, child)
try:
# 判断是否已经存在该目录
if not os.path.exists(saveDir):
# 目录不存在,进行创建操作
os.makedirs(saveDir) # 使用os.makedirs()方法创建多层目录
print("目录新建成功:" + saveDir)
else:
print("目录已存在!!!")
except BaseException as msg:
print("新建目录失败:" + msg)
copyFile(childpath,saveDir)
3.切割(256×256)
将图片切割成256×256的多张小图片,具体代码如下(文件读取为嵌套读取):
import cv2
import numpy as np
import random
import os
path="E://p"#数据集地址
rootList = os.listdir(path)
要分割后的尺寸
cut_width = 256
cut_length = 256
for child in rootList:
savePath = "E://q"#数据集保存的地址
childpath=os.path.join(path,child)
childList=os.listdir(childpath)
saveDir=os.path.join(savePath,child)
try:
# 判断是否已经存在该目录
if not os.path.exists(saveDir):
# 目录不存在,进行创建操作
os.makedirs(saveDir) # 使用os.makedirs()方法创建多层目录
print("目录新建成功:" +saveDir)
else:
print("目录已存在!!!")
except BaseException as msg:
print("新建目录失败:" + msg)
for item in childList:
itemPath=os.path.join(childpath,item)
if (itemPath.endswith(".jpg") == True):
# 读取要分割的图片,以及其尺寸等数据
picture = cv2.imread(itemPath)
(width, length, depth) = picture.shape
# 预处理生成0矩阵
pic = np.zeros((cut_width, cut_length, depth))
# 计算可以划分的横纵的个数
num_width = int(width / cut_width)
num_length = int(length / cut_length)
# for循环迭代生成
for i in range(0, num_width):
for j in range(0, num_length):
name_ID = random.randint(1, 10000000)
pic = picture[i * cut_width: (i + 1) * cut_width, j * cut_length: (j + 1) * cut_length, :]
result_path = str(name_ID) + '.jpg'
savePath=os.path.join(saveDir,result_path)
# savePath = os.path.join(saveDir,'{}_{}.jpg'.format(i + 1, j + 1))
cv2.imwrite(savePath, pic)
print("done!!!")
4.筛除
由于切割后的数据集中存在白色空白占比过大的图像,对训练产生影响,故将其筛除。
流程为:读取图像->预处理(转化为灰度图)->二值化->计算黑色像素点的占比->移除白色像素点占比大的图像
ps:阈值的选择十分重要,决定了效果的好坏!!!!!
具体代码如下(文件读取为嵌套读取):
import cv2
import numpy as np
import random
import os
from PIL import Image,ImageFile
from PIL import Image
import numpy as np, pandas as pd
from collections import Counter
import shutil
path="E://dataset//train_256x2561//25cm"#数据集的地址
rootList = os.listdir(path)
for child in rootList:
childpath=os.path.join(path,child)
print(childpath)
childList=os.listdir(childpath)
os.makedirs(childpath + "_garbage", 0o777, True)
for item in childList:
itemPath=os.path.join(childpath,item)
garbagePath=os.path.join(childpath + "_garbage", item)
if (itemPath.endswith(".jpg") == True):
img = cv2.imread(itemPath,cv2.IMREAD_GRAYSCALE)
x, y = img.shape[:2]
print(img.shape)
# 遍历灰度图,阈值大于150变黑
for i in range(x):
for j in range(y):
#color = random.randint(150, 200)
if img[i, j] > 160:
img[i, j] = 255
else:
img[i, j] = 0
black = 0
white = 0
# 遍历二值图,为0则black+1,否则white+1
for i in range(x):
for j in range(y):
if img[i, j] == 0:
black += 1
else:
white += 1
rate1 = white / (x * y)
rate2 = black / (x * y)
# round()第二个值为保留几位有效小数。
if rate2
运行之后,可得到以下效果图:
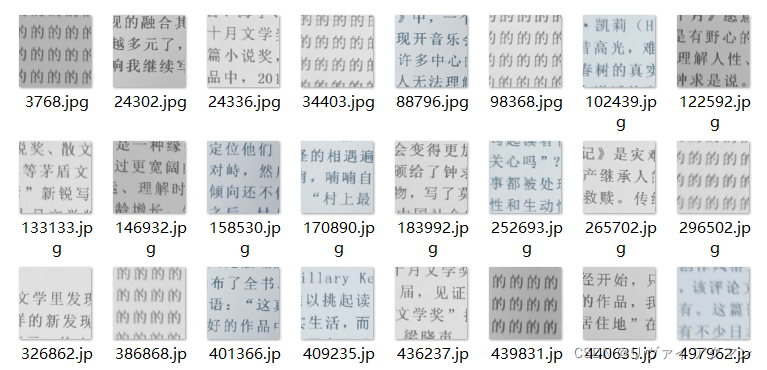
(左图为筛除后的数据集,右图为被筛除的图像)
5.图片重命名
具体代码如下(文件读取为嵌套读取):
import os
outer_path = 'E://dataset//datasets//25cm//train__256x256'
folderlist = os.listdir(outer_path) # 列举文件夹
for folder in folderlist:
inner_path = os.path.join(outer_path, folder)
total_num_folder = len(folderlist) # 文件夹的总数
# 打印文件夹的总数
filelist = os.listdir(inner_path) # 列举图片
i = 1
for item in filelist:
total_num_file = len(filelist) # 单个文件夹内图片的总数
if item.endswith('.jpg'):
src = os.path.join(os.path.abspath(inner_path), item) # 原图的地址
dst = os.path.join(os.path.abspath(inner_path), str(i) + '.jpg') # 新图的地址(这里可以把str(folder) + '_' + str(i) + '.jpg'改成你想改的名称)
try:
os.rename(src, dst)
print
'converting %s to %s ...' % (src, dst)
i += 1
except:
continue
Original: https://blog.csdn.net/qq_54979098/article/details/126275978
Author: リヴァイ·アクマン
Title: 细粒度分类——数据集制作
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/702785/
转载文章受原作者版权保护。转载请注明原作者出处!