

目录
语音识别的定义
语音识别:Automatic Speech Recognition(ASR)或Speech to Text(STT),将语音转换为文本的任务。
语音识别主要解决以下问题:
[En]
Speech recognition mainly solves the following problems:
- 将语音转换成文本。
- 解决机器”听清”问题。
- 处理声学和(部分)语言混淆。
[En]
deal with acoustic and (partial) linguistic confusion.*
- 解决常见问题:每个人的声音都能识别正确的文本。
[En]
solve common problems: everyone’s voice can recognize the correct text.*
狭义的语音识别不能解决以下问题:
[En]
Speech recognition in a narrow sense does not solve the following problems:
- 说话人识别。
- 副语言信息的分析和识别。
[En]
Analysis and recognition of paralanguage information.*
- 语言理解。
语音识别的常见评估标准:
[En]
Common evaluation criteria for speech recognition:
-
Accuracy(准确率)
-
音素错误率(Phone Error Rate)
- 词错误率(Word Error Rate,WER)
- 字错误率(Character Error Rate,CER)
-
句错误率(Sentence Error Rate,SER)
-
Efficiency(效率)
-
实时率(Real-time Factor,RTF)
错误率计算实例:
Ref:
THECATINTHEHAT
Hyp:
CATISONTHEGREENHAT
DEL SUB INS INS
该实例中,第一行为正确抄本,第二行为识别结果,第二列为一个删除错误,第四列为一个替换错误,第五列、第七列为插入错误,错误率:
 。
。
在计算错误率的过程中,我们一般会注意三种错误:插入错误、替换错误和删除错误。实际计算过程中的误差率可能大于100%。
[En]
In the process of calculating the error rate, we generally pay attention to three kinds of errors: insertion error, replacement error and deletion error. The error rate in the actual calculation process may be greater than 100%.
语音识别系统常见分类:
- 发言人:特定人、非特定人
[En]
Speaker: specific person, non-specific person*
- 语种:单一语种、多语种
- 词汇量:大、中、小
- 设备:云侧、端侧
- 距离:近讲、远讲
语音识别的重要性
语音识别是一项极具挑战性的任务,被誉为“人工智能皇冠上镶嵌的明珠”。
[En]
Speech recognition is a very challenging task, which is known as “the pearl embedded in the crown of artificial intelligence”.
语音识别具有快、易、Hands-Free的优点。
文本音译是音频内容分析和理解的第一步。
[En]
Text transliteration is the first step in audio content analysis and understanding.
语音识别是AIoT、只能服务的入口。
语音识别技术和应用广泛,能够满足自然的人机交互和内容理解与生成的需要。
[En]
The technology and application of speech recognition are extensive, which can meet the needs of natural human-computer interaction and content understanding and generation.
语音交互
语音交互中存在一个链条,叫Speech Chain,至少涉及两个人,具体如图所示。
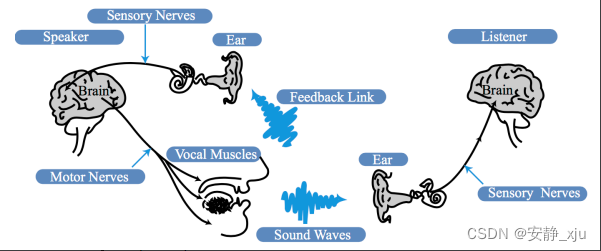
涉及三个Level:
语音生成
Speech Production:大脑
神经肌肉命令发音器官运动。
发音是由于声门的快速打开和关闭产生不同的声音造成的。
[En]
Pronunciation is caused by the rapid opening and closing of the glottis to produce different sounds.
- 声门振动的速度决定了声音的基本频率。
[En]
the speed of glottic vibration determines the basic frequency of the sound.*
- 嘴巴、鼻腔、舌头位置、口型等,决定声音的内容。
[En]
mouth, nasal cavity, tongue position, mouth shape, etc., determine the content of the sound.*
- 容量由肺部压缩空气的强度决定。
[En]
the volume is determined by the strength of compressed air in the lungs.*
浊音是由声带的振动引起的,其波形具有明显的周期性,所以人们可以感受到稳定高音的存在。
[En]
Voiced sound is caused by the vibration of vocal cords, and its waveform is obviously periodic, so people can feel the existence of stable treble.
当产生清晰的音调时,声带不会振动,其波形类似于白噪声,所以人们感觉不到稳定的高音的存在。
[En]
When a clear tone is produced, the vocal cords will not vibrate, and its waveform is similar to white noise, so people can not feel the existence of a stable treble.
音素(Phonemes)时一种语言中语音的”最小”单元。音素可以分为辅音(consonants)音素和元音(vowels)音素,不同的语言中音素的数量不完全相同。
音素的声学实现受到上下文的影响,一个音素往往会有不同的实现,这种现象叫做 同位异音(Allophone)。
词\语素(morpheme):一种语言中最小的具有语义的结构单元。
共振峰(formant)指在声音的频谱中能量相对集中的一些区域。
共振峰不仅是音质的决定因素,还反映了声道的物理特性。
[En]
Formants are not only the determinant of sound quality, but also reflect the physical characteristics of the sound channel.
* 共振峰是声道特别放大的波段,不同的元音会产生不同种类的放大或共鸣。
[En]
formants are bands that are particularly amplified by the vocal tract, and different vowels produce different kinds of amplification or resonance.*
协同发音(Coarticulation),人的发音过程中,受类似惯性的影响,每一个发音都会受到前面发音和后面发音的影响,这种影响被称为协同发音。音素在声学上的实现和上下文是强相关的,所以在语音识别的建模中常常会建立上下文相关模型。
音素抄本(Phonetic Transcription):一段语音对应的音素列表。音素抄本可以带或不带边界,其中的时间信息可以有人工标注或自动对齐获得。音素抄本是非常重要的,可服务于语音识别的声学建模。
音节是一个更大颗粒度的单位,元音和辅音结合构成一个音节。
- 元音前的辅音称为音节中心或辅音。
[En]
consonants before vowels are called syllable heads or consonants.
音节开头后面的元音和后面的辅音叫做元音。
[En]
The vowels after the head of a syllable and the consonants that follow are called vowels.*
- 韵母里的元音叫音节核。
- 随后的子音叫音节尾。
在汉语中,一个汉字的发音是一个有声调的音节,普通话中大约有1300个有声调的音节。如果去掉声调,即基本音节,普通话中大约有400个基本音节。
[En]
In Chinese, a Chinese character is pronounced as one syllable with tone, and there are about 1300 syllables with tone in Putonghua. If tones, that is, basic syllables are removed, there are about 400 basic syllables in Putonghua.
语音感知
Speech Perception:人耳
大脑。
人的耳朵由外耳、中耳和内耳组成:
[En]
The human ear consists of the outer ear, the middle ear and the inner ear:
- 外耳:定位声源并放大声音。
[En]
external ear: locate the sound source and amplify the sound.*
- 中耳:改变声阻抗并大声按压,以保护内耳。
[En]
Middle ear: change the acoustic impedance and press loudly to protect the inner ear.*
- 内耳:将信号转换到神经,将声压刺激转化为神经冲动。
[En]
the inner ear: transforms signals to the nerves, turning sound pressure stimulation into nerve impulses.*
语音感知的物理特征和人耳的听觉特征:
[En]
The physical characteristics of speech perception and the auditory characteristics of the human ear:
Phyisical Quantity物理量Perceptual Quantity感知量Intensity声强Loundness响度Fundamental Frequency基频Pitch音高或音调Spectral Shape频谱形状Timbre音色或音品Onset/offset time Timing Phase difference in binaural hearing双耳听觉上的相位差Location定位
其中,Loundness响度、Pitch音高或音调和Timbre音色或音品为声音三要素(主观心理量)。
响度:人主观感受不同频率成分声音的物理量。
- 人耳对不同频率声音的反应参差不齐。
[En]
the response of the human ear to sound at different frequencies is uneven.*
- 听力阈值:人耳能听到的声音的响度。
[En]
hearing threshold: the loudness of a sound that is just audible to the human ear.*
- 痛阈值:引起耳朵疼痛的声音的响度。
[En]
pain threshold: the loudness of sound that causes pain to the ear.*
音色:又称音品,由声音波形的谐波频谱和包络决定。
- 由声音波形的基频产生的音调称为音高,每个谐波的微小振动产生的声音称为泛音。
[En]
the pitch produced by the fundamental frequency of the sound waveform is called the pitch, and the sound produced by the small vibration of each harmonic is called overtone.*
- 单一频率的音调称为纯音,有和声的音调称为复调。
[En]
the tone of a single frequency is called pure tone, and the tone with harmonics is called polyphony.*
- 每个音调都有一个固有的频率和不同的响度泛音。
[En]
each pitch has an inherent frequency and different loudness overtones.*
- 声音波形的谐波比例和随时间的衰减决定了各种声源的音色特征。
[En]
the proportion of the harmonics of the sound waveform and the attenuation over time determine the timbre characteristics of various sound sources.*
音调:人耳对于频率的感知,是非线性的,近似对数函数。
音调和频率之间的近似关系:
。
为物理频率,为音调,单位是美(Mel)。
掩蔽效应(Masking):一种心理声学现象,是由人耳对声音频率分辨机制决定的。是指一个较强声音的附近,相对较弱的声音使不易被人耳察觉,即被强音所掩蔽。
- 同时掩蔽:强烈的纯音掩盖了同时出现在其附近的弱纯音。
[En]
simultaneous masking: a strong pure tone masks a weak pure tone that occurs at the same time in its vicinity.*
- 异时掩蔽:相邻声音之间也存在时间掩蔽。
[En]
metachronous masking: there is also masking between adjacent sounds in time.*
- 屏蔽阈值是时间、频率和声压级的函数。
[En]
the masking threshold is a function of time, frequency and sound pressure level.*
语音识别的挑战性
语音识别是一项极具挑战性的任务,在许多方面都具有很强的变异性。如下表所示。
[En]
Speech recognition is a very challenging task with strong variability in many aspects. As shown in the table below.
因素 可变性
规模词表大小,复杂/困惑度,书面化或口语化?说话人倾向于特定说话人?适应到某个(群)说话人的特性声学环境噪声,干扰人声,信道条件(麦克风、传输空间、空间声学)讲话风格连续或孤立词?有计划有准备?即兴对话?大声或轻声细语?口音/方言识别各种口音?语种中文,英文,5000+语种,混杂等
说话人内部和说话人之间的可变性,说话人内部说话风格和状态的可变性,以及说话人之间口音和说话风格的可变性。
[En]
The variability within and between speakers, the variability of speech style and state within the speaker, and the variability of accent and speaking style between speakers.
信道具有不同的麦克风特性、不同的采样率、传输编码等变异性。
[En]
The channel has different characteristics of microphones, different sampling rates, transmission coding and other variability.
环境具有一定的变异性,如距离衰减、噪声、混响、人声干扰等。
[En]
The environment has some variability, such as distance attenuation, noise, reverberation, interference of human voice and so on.
此外还有更加具有挑战性的场景,以CHiME-5为例,该场景具有多说话人完全自由对话、实际家具声学场景、远讲、说话人移动、语音交叠等特点。
语音识别的发展历史
早期:1950-1960年代,该阶段处于语音识别的研究早期。研究人员提出了一些个别方法,引入了许多重要的思想和概念。受限于方法、计算能力、数据等因素,该阶段主要针对小词表语音识别进行研究,且缺乏大规模测试。
现代语音识别的诞生:1970-1980年代,这个阶段将语音识别做成了统计学习的任务,几乎忽略了所有有关于语音学和语言学的专家知识。这个阶段提出了许多语音识别的关键技术,如EM算法、N-gram等等。此阶段,语音识别开始尝试中大词表的系统。
平稳发展期:1990-2000年代,GMM-HMM框架成为语音识别的主导框架,声学建模开始考虑基于上下文相关的模型,语言模型使用n-gram从大量文本中统计概率关系,数据量逐步增大,任务复杂程度逐步增大。此外,判别式学习/区分性训练技术也推动了语音识别的进步。
在稳步发展期和稳步发展期之后,技术一直在提高,但语音识别的准确率却鲜有提高。直到2006年,语音识别进入深度学习时代。
[En]
In the period of steady development and after the period of steady development, the technology has been improving, but the accuracy of speech recognition has rarely improved. Until 2006, speech recognition entered the era of deep learning.
语音识别的深度学习时代
2006年,多伦多大学Geoffrey Hinton教授在Nature上发表论文,为神经网络提供了有效的预训练算法,标志着语音识别进入深度学习时代。
这个阶段,声学架构从GMM-HMM转变为DNN-HMM,语言模型也转变为ngram+NNLM。
在深度学习时代,语音识别错误率在众多Benchmark上取得新低,目前在IBM,Switchboard数据集上词错误率已达到5.0%,此外,语音系统开始逐步从混合系统(Hybrid)发展到端到端系统。
现代语音识别框架
统计模型:
如果
是指声学特征向量(观测向量)的序列,表示一个单词序列,则最有可能的单词序列由以下公式计算而来:
应用贝叶斯定理推导:
其中,
为声学模型,为语言模型。
现代的统计模型使用声学模型、语言模型、发音词典,通过给定的声学特征向量X,获取最有可能的词序列
。
端到端系统:用一个神经网络直接讲输入声学特征向量X映射为词序列
。
语料库与工具包
英文数据:
- TIMIT:音素识别,LDC版权
- WSJ:新闻播报,LDC版权
- Switchboard:电话对话,LDC版权
- Librispeech:有声读物,1000小时,开源(http://openslr.org/12/)
- AMI:会议,开源(http://openslr.org/16/)
- TED-LIUM:演讲,开源(http://openslr.org/19/)
- CHiME-4:平板远讲,需申请
- CHiME-5/6:聚会聊天,需申请
中文数据:
- THCHS-30,30小时,开源(http://openslr.org/18/)
- HKUST,150小时,电话对话,LDC版权
- AIShell-1,178小时,开源(http://openslr.org/33/)
- AIShell-2,1000小时,开源需申请(http://www.aishelltech.com/aishell_2)
- aidatatang_200zh,200小时,开源(http://openslr.org/62/)
- MAGICDATA,755小时,开源(http://openslr.org/68/)
工具包:
- HTK:http://htk.eng.cam.ac.uk/(C)
- Kaldi:http://kaldi-asr.org/(C++,Python)(目前使用最广泛的工具包)
- ESPNet:https://github.com/espnet/(Pytorch based)(主要针对端到端系统)
- Lingvo:https://github.com/tensorflow/lingvo.git(Tensorflow based)
另附:语音识别入门第一节:思维导图-深度学习文档类资源-CSDN下载
如需转载敬请声明。
Original: https://blog.csdn.net/u010207220/article/details/125542887
Author: 安静_xju
Title: 语音识别入门第一节:语音识别概述
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/498509/
转载文章受原作者版权保护。转载请注明原作者出处!