

前言:
前几天看完了pytorch入门教程,想着要做一个小玩意巩固一下知识点,然后又想着大半年没整活了,于是就想着和虚拟主播缝合起来,还能给自己增添一点动力
本人只是本科大一非计科专业,只是在课余时间了解了一点机器学习和计算机视觉的知识,所以学的比较慢,而且可能会有比较多的错误和理解不充分
在开始做时把这个小尝试大致分为:图像预处理,制作数据集,训练模型,测试模型的识别能力和可视化
由于并没有花大量时间制作数据集(于是就只做了24个数据,一共3类,每类8张图片),再加上模型是用的最最简单的全连接神经网络,再再加上数据太少,epoch设置的又比较大,理所应当地过拟合了,所以为了整活整的有效果,就把训练集拿过来测试了…初学者水平有限捏
这篇只是记录自己第一次动手做机器学习的小玩意,偏向记录自己在动手过程中的问题和收获
代码能跑是能跑,就是比较烂,本文讲的也不会太过详细和深刻
部分代码参考:https://discuss.pytorch.org/#main-container
https://pytorch.org/tutorials/
https://www.jianshu.com/p/2d9927a70594
图像预处理
我选取了正方形的图像,然后为了之后能够进行机器学习,用python里的OpenCV对图像进行压缩处理
然后设置好图像名字然后输出到对应的文件夹
在这里用到了python的 字符串格式化的知识,这一点我并不常用,很陌生…
当时参考了这个网站:https://www.jb51.net/article/232118.htm
用到的格式化输出在这篇链接网页的末尾
import cv2 as cv
from matplotlib import image
from numpy import number
for i in range (1,9):
number = f"{i}"
print(number)
image = cv.imread("D:\\Py workprojects\\the new funny file\\photo\\one\\%s.png"%number)
new_image = cv.resize(image,(100,100))
number = f"{i-1}"
cv.imwrite("D:\\Py workprojects\\the new funny file\\data\\train\\Diana\\%s.png"%number,new_image)
cv.imwrite("D:\\Py workprojects\\the new funny file\\last_data\\test\\Diana\\%s.png"%number,new_image)
for i in range (1,9):
number = f"{i}"
print(number)
image = cv.imread("D:\\Py workprojects\\the new funny file\\photo\\two\\%s.png"%number)
new_image = cv.resize(image,(100,100))
number = f"{i-1}"
cv.imwrite("D:\\Py workprojects\\the new funny file\\data\\train\\Taffy\\%s.png"%number,new_image)
cv.imwrite("D:\\Py workprojects\\the new funny file\\last_data\\test\\Taffy\\%s.png"%number,new_image)
for i in range (1,9):
number = f"{i}"
print(number)
image = cv.imread("D:\\Py workprojects\\the new funny file\\photo\\three\\%s.png"%number)
new_image = cv.resize(image,(100,100))
number = f"{i-1}"
cv.imwrite("D:\\Py workprojects\\the new funny file\\data\\train\\Wenjing\\%s.png"%number,new_image)
cv.imwrite("D:\\Py workprojects\\the new funny file\\last_data\\test\\Wenjing\\%s.png"%number,new_image)
到此第一个.py文件结束
制作数据集
在网上乱查时发现了一个制作数据集的小网站,看起来有实用价值,不过我最后没用的上
还是放出来:https://www.makesense.ai/
使用方法比较简单,这其实就是你手动分类后生成一个csv文件,记录着文件名和label,不用再自己写文件输出了,也就方便了这一点,不过他输出的label是带”[]”的
后来的参考是:https://www.jianshu.com/p/2d9927a70594
放代码:
from random import sample
import numpy as np
from torch import nn, relu
from skimage import io
from skimage import transform
import matplotlib.pyplot as plt
import os
import torch
import torchvision
from torch.utils.data import Dataset, DataLoader
from torchvision.transforms import transforms
from torchvision.utils import make_grid
class MyDataset(Dataset):
def __init__(self, root_dir, names_file, transform=None):
self.root_dir = root_dir
self.names_file = names_file
self.transform = transform
self.size = 0
self.names_list = []
if not os.path.isfile(self.names_file):
print(self.names_file + "does not exist!")
file = open(self.names_file)
for f in file:
self.names_list.append(f)
self.size += 1
def __len__(self):
return self.size
def __getitem__(self, idx):
image_path = self.root_dir + self.names_list[idx].split(" ")[0]
if not os.path.isfile(image_path):
print(image_path + "does not exist!")
return None
image = io.imread(image_path)
label = int(self.names_list[idx].split(" ")[1])
sample = {"image": image, "label": label}
if self.transform:
sample = self.transform(sample)
return image,label,sample
class Resize(object):
def __init__(self, output_size: tuple):
self.output_size = output_size
def __call__(self, sample):
image = sample['image']
image_new = transform.resize(image, self.output_size)
return {'image': image_new, 'label': sample['label']}
class ToTensor(object):
def __call__(self, sample):
image = sample['image']
image_new = np.transpose(image, (2, 0, 1))
return {'image': torch.from_numpy(image_new),
'label': sample['label']}
train_dataset = MyDataset(root_dir='./data/train',
names_file='./data/train/labels_train.txt',
transform=None)
transformed_trainset = MyDataset(root_dir='./data/train',
names_file='./data/train/labels_train.txt',
transform=transforms.Compose([Resize((100,100)),ToTensor()]))
trainset_dataloader = DataLoader(dataset=transformed_trainset,
batch_size=4,
shuffle=True,
num_workers=0)
testset_dataloader = DataLoader(dataset=transformed_trainset,
batch_size=4,
shuffle=True,
num_workers=0)
在这一部分遇见的问题还是比较多的
下面一一记录:
自定义数据集的返回值
由于在之后 可视化的需求(我对可视化了解很少,于是是照搬的前面链接文章的可视化方法),将上文文章中自定义数据集的返回值进行了更改
更改了这部分代码:
def __getitem__(self, idx):
image_path = self.root_dir + self.names_list[idx].split(" ")[0]
if not os.path.isfile(image_path):
print(image_path + "does not exist!")
return None
image = io.imread(image_path)
label = int(self.names_list[idx].split(" ")[1])
sample = {"image": image, "label": label}
if self.transform:
sample = self.transform(sample)
return image,label,sample
原文的return是只有sample,其实只有这个也可以用,不过在写分类器的时候用的是返回image和label
问题一:我对于后面加载数据时的train_dataset和trainset_dataloader之间的关系和使用不是太理解
也是因为这些在后面可视化过程中频繁出现报错,于是就通过加一个返回值笨拙地解决了这个问题
然后就是后面的实例化:
class Resize(object):
def __init__(self, output_size: tuple):
self.output_size = output_size
def __call__(self, sample):
image = sample['image']
image_new = transform.resize(image, self.output_size)
return {'image': image_new, 'label': sample['label']}
class ToTensor(object):
def __call__(self, sample):
image = sample['image']
image_new = np.transpose(image, (2, 0, 1))
return {'image': torch.from_numpy(image_new),
'label': sample['label']}
train_dataset = MyDataset(root_dir='./data/train',
names_file='./data/train/labels_train.txt',
transform=None)
transformed_trainset = MyDataset(root_dir='./data/train',
names_file='./data/train/labels_train.txt',
transform=transforms.Compose([Resize((28,28)),ToTensor()]))
trainset_dataloader = DataLoader(dataset=transformed_trainset,
batch_size=4,
shuffle=True,
num_workers=0)
testset_dataloader = DataLoader(dataset=transformed_trainset,
batch_size=4,
shuffle=True,
num_workers=0)
问题二:在这里留下的疑问点是transform和target_transform发挥的作用
在这里解决了之前的问题,batch_size是在数据集实例化时设置的
除此之外,对于Windows系统无法进行多进程num_workers=0即设置为0
训练模型
承接着上面的代码,下部分为
if torch.cuda.is_available:
device = "cuda"
print("cuda加速已开启")
else:
device = "cpu"
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(100*100*3, 512),
nn.ReLU(),
nn.Linear(512, 16),
nn.ReLU(),
nn.Linear(16,3)
)
def forward(self, x):
x = self.flatten(x).to(device)
logits = self.linear_relu_stack(x.float())
return logits
model = NeuralNetwork().to(device)
learning_rate = 1e-6
def train_loop(trainset_dataloader, model, loss_fn, optimizer):
size = len(trainset_dataloader)
for batch, (X,y,i) in enumerate(trainset_dataloader):
pred = model(X)
loss = loss_fn(pred, y.to(device))
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch % 1 == 0:
loss, current = loss.item(), (batch+1) * len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size*trainset_dataloader.batch_size:>5d}]")
def test_loop(testset_dataloader, model, loss_fn):
size = len(testset_dataloader)
num_batches = len(testset_dataloader)
test_loss, correct = 0, 0
with torch.no_grad():
for X, y, i in trainset_dataloader:
pred = model(X)
test_loss += loss_fn(pred, y.to(device)).item()
correct += (pred.argmax(1) == y.to(device)).type(torch.float).sum().item()
print(f"实际上是:\n{y}\n 机器预测的是:\n{pred.argmax(1)}")
test_loss /= num_batches*testset_dataloader.batch_size
correct /= size*testset_dataloader.batch_size
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
epochs = 10
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train_loop(trainset_dataloader, model, loss_fn, optimizer)
test_loop(testset_dataloader, model, loss_fn)
torch.save(model.state_dict(),'data_Vtuber_complete')
print("结束咧!")
这部分之前了解的比较多,从官网基础教程中复制后也只需要改改接口和很少的代码就能使用,需要注意的就是几部分:
cuda
if torch.cuda.is_available:
device = "cuda"
print("cuda加速已开启")
else:
device = "cpu"
我用的是30系N卡,所以可以设置cuda加速
神经网络
self.linear_relu_stack = nn.Sequential(
nn.Linear(100*100*3, 512),
nn.ReLU(),
nn.Linear(512, 16),
nn.ReLU(),
nn.Linear(16,3)
)
这就是用线性分类器和非线性激活函数连接的一个全连接神经网络
要注意的是,比如说我一共有N个类别,而且在这个网络之后不再有分类器来对特征值进行运算,那最后就应该用这个网络把图像(输入tensor)映射在N个值上面,由此能够预测出之后的图像属于哪一类
学习率
前面用的是梯度下降算法来进行参数的优化,在这里需要设置重要参数学习率的值
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
epochs
就是数据集学习几遍,过高会使模型过拟合
epochs = 10
测试模型的识别能力和可视化
前面模型构建完后,经过不停地调参,优化出一个还算满意的模型然后保存,用于下一个识别图像时进行读取
(其实这个调参使loss收敛是最最最重要的过程,这能让模型真正的有实用价值,我之后还需要学习这方面)
这部分代码和前面的差不多,只是把train的部分去掉了,增加了可视化的部分
import numpy as np
from torch import Tensor, nn, relu
from skimage import io
from skimage import transform
import matplotlib.pyplot as plt
import os
import torch
import torchvision
from torch.utils.data import Dataset, DataLoader
from torchvision.transforms import transforms
from torchvision.utils import make_grid
from zmq import device
class MyDataset(Dataset):
def __init__(self, root_dir, names_file, transform=None):
self.root_dir = root_dir
self.names_file = names_file
self.transform = transform
self.size = 0
self.names_list = []
if not os.path.isfile(self.names_file):
print(self.names_file + "does not exist!")
file = open(self.names_file)
for f in file:
self.names_list.append(f)
self.size += 1
def __len__(self):
return self.size
def __getitem__(self, idx):
image_path = self.root_dir + self.names_list[idx].split(" ")[0]
if not os.path.isfile(image_path):
print(image_path + "does not exist!")
return None
image = io.imread(image_path)
label = int(self.names_list[idx].split(" ")[1])
sample = {"image": image, "label": label}
if self.transform:
sample = self.transform(sample)
return image,label,sample
class Resize(object):
def __init__(self, output_size: tuple):
self.output_size = output_size
def __call__(self, sample):
image = sample['image']
image_new = transform.resize(image, self.output_size)
return {'image': image_new, 'label': sample['label']}
class ToTensor(object):
def __call__(self, sample):
image = sample['image']
image_new = np.transpose(image, (2, 0, 1))
return {'image': torch.from_numpy(image_new),
'label': sample['label']}
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(100*100*3, 512),
nn.ReLU(),
nn.Linear(512, 16),
nn.ReLU(),
nn.Linear(16,3)
)
def forward(self, x):
x = self.flatten(x).to(device)
logits = self.linear_relu_stack(x.float())
return logits
device = "cpu"
test_dataset = MyDataset(root_dir='./last_data/test',
names_file = './last_data/test/test.txt',
transform=None)
transformed_trainset = MyDataset(root_dir='./last_data/test',
names_file='./last_data/test/test.txt',
transform=transforms.Compose([Resize((100,100)),ToTensor()]))
testset_dataloader = DataLoader(dataset=transformed_trainset,
batch_size=1,
shuffle=True,
num_workers=0)
model = NeuralNetwork().to(device)
model.load_state_dict(torch.load('data_Vtuber_complete'))
model.eval()
def test_loop(testset_dataloader, model, loss_fn):
size = len(testset_dataloader)
num_batches = len(testset_dataloader)
test_loss, correct = 0, 0
with torch.no_grad():
plt.figure()
num = 0
for X, y ,i in testset_dataloader:
pred = model(X)
test_loss += loss_fn(pred, y.to(device)).item()
correct += (pred.argmax(1) == y.to(device)).type(torch.float).sum().item()
softmax_0=nn.Softmax(dim = 1)
result_tenor = softmax_0(pred)
result_np = np.array(result_tenor)
y_np = np.array(y)
pred_np = np.array(pred.argmax(1))
if y_np[0] == 0:
name_Vtuber = "Diana"
elif y_np[0] == 1:
name_Vtuber = "Wenjing"
elif y_np[0] == 2:
name_Vtuber == "Taffy"
if pred_np[0] ==0:
name_Vtuber_pre = "Diana"
elif pred_np[0] == 1:
name_Vtuber_pre = "Wenjing"
elif pred_np[0] == 2:
name_Vtuber_pre = "Taffy"
def show_images_batch(sample_batched):
images_batch, labels_batch =\
sample_batched['image'], sample_batched['label']
grid = make_grid(images_batch)
plt.title('The prediction result of AI is: {}'.format(name_Vtuber_pre))
plt.imshow(grid.numpy().transpose(1, 2, 0))
show_images_batch(i)
plt.axis('off')
plt.ioff()
plt.show()
test_loss /= num_batches*testset_dataloader.batch_size
correct /= size*testset_dataloader.batch_size
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
loss_fn = nn.CrossEntropyLoss()
epochs = 1
for t in range(epochs):
print(f"\n-------------------------------")
test_loop(testset_dataloader, model, loss_fn)
plt.pause(10)
print("结束咧!")
tips:我这里用回CPU是因为之后把tensor转化为np.array时提示要先塞进CPU里,试了一次不行后我懒得再查,所以索性用CPU了(这也是一个未来需要再查的小问题)
可视化
这段可视化基本上借鉴于前面制作数据集时的文章,还需要之后再学相关的知识
这段可视化是放在了test循环里面
softmax_0=nn.Softmax(dim = 1)
result_tenor = softmax_0(pred)
result_np = np.array(result_tenor)
y_np = np.array(y)
pred_np = np.array(pred.argmax(1))
if y_np[0] == 0:
name_Vtuber = "Diana"
elif y_np[0] == 1:
name_Vtuber = "Wenjing"
elif y_np[0] == 2:
name_Vtuber == "Taffy"
if pred_np[0] ==0:
name_Vtuber_pre = "Diana"
elif pred_np[0] == 1:
name_Vtuber_pre = "Wenjing"
elif pred_np[0] == 2:
name_Vtuber_pre = "Taffy"
def show_images_batch(sample_batched):
images_batch, labels_batch =\
sample_batched['image'], sample_batched['label']
grid = make_grid(images_batch)
plt.title('The prediction result of AI is: {}'.format(name_Vtuber_pre))
plt.imshow(grid.numpy().transpose(1, 2, 0))
show_images_batch(i)
plt.axis('off')
plt.ioff()
plt.show()
问题三:==之前自己可视化时出现的问题时维度问题,这个问题应该是在那个”def show_images_batch(sample_batched)”函数里解决了,没太看懂这部分,应该是用最后一行的transpose解决的,详细的留在之后再看 ==
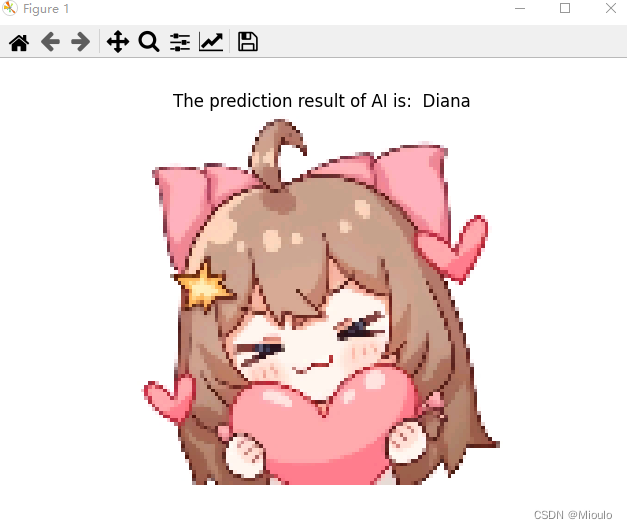
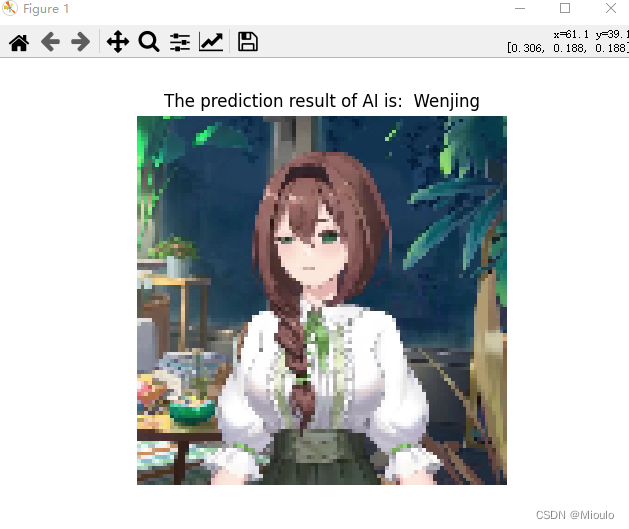
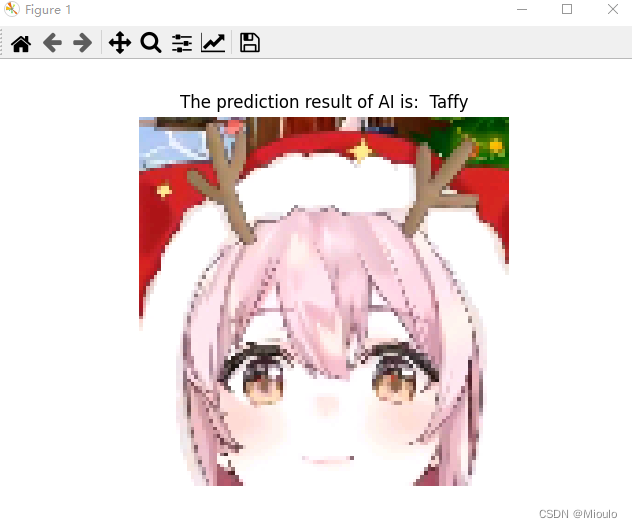
可视化效果
最后大致的实现效果如图:
每张图片会依次出现,点击X实现交互后会出现下一张图片

Original: https://blog.csdn.net/Mioulo/article/details/125938350
Author: Mioulo
Title: 【图像识别】训练一个最最简单的AI使其识别Vtuber
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/701985/
转载文章受原作者版权保护。转载请注明原作者出处!