

一、项目概述
本文是婴儿哭声分类识别系统化的主体部分,主要解决智能音频分类的问题。基于此目标,本文查找了大量资料,并做了大量实验,最后获得了一个婴儿哭声分类识别准确率相对较高的深度学习模型——迁移学习Urbansound数据模型。
本文将从问题出发,提出问题、分析问题、解决问题,讲解如何一步步地解决该问题,并最终获得满意的结果。
二、项目规划
1. 项目要点问题
- 婴儿哭声数据集——去哪找?
- 音频数据如何预处理?
- 音频如何分类?
- 神经网络结构如何设计?(DNN、DNN+CNN、迁移学习)
- 实验如何设计?
- …..
2. 项目开发工具
- 模型训练(GPU)——Colab
- 本地环境管理——Anaconda
- 本地开发——Pycharm
3.项目涉及代码
三、项目要点
1.婴儿哭声数据集
本项目遇到的第一个关键问题是数据集去哪里找?起初在网上找到一个音频共享网站,在这里找到了很多婴儿哭声的音频,但是,数量依旧还是很有限的,而且音频分类的标签是否准确也具有一定的不确定性,所以转而去找有没有现成的婴儿哭声数据集。
各大机器学习比赛网站、各个数据集网站、国内外音频分类相关论文等。终于,在 飞桨数据集中找到了有标签的婴儿啼哭数据集。打开数据集可以看到train和test两个文件夹,如图1所示。由于test文件夹中的音频没有标签,所以只能使用train文件夹数据进行训练,数据集类别如图2所示。


图1 数据集文件

图2 (train文件夹)训练集
- 训练集中共有数据918条,音频格式为wav,数据长度5s~30s不等。
2.音频处理
2.1 音频问题
解决了数据集问题,下一步就需要考虑音频数据问题:
- 数据量是否足够训练出符合要求的模型?
- 数据长度是否符合神经网络需要?
- 数据应该 如何送入网络?
- ……
2.2 解决音频问题
小编在研究生阶段研究的是图像处理,图像可以被看成是一个多维矩阵,具有长宽高,自然可以送入神经网络中,音频该如何处理呢?

查找资料发现,音频实际是以波的形式存在,若以时间为横轴、振幅为纵轴绘制图像,则如图3所示。
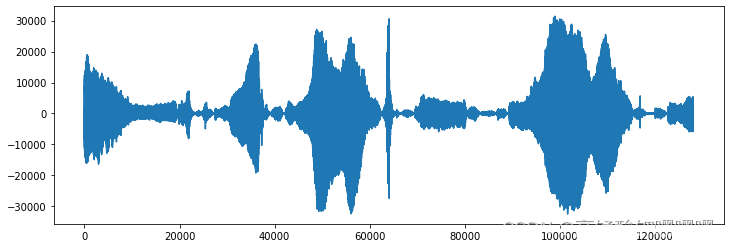
图3 波形图
通过查看原始音频文件数据存储发现,虽然音频文件同样可表现为张量数据(如图4所示),但在深度学习方面通常不会将其直接放入网络,通常的做法是将音频转换为频谱图(如图5所示)。频谱图是音频波的简洁”快照”,因为它是图像,所以非常适合输入到为处理图像而开发的基于CNN的架构中。图6展示了音频深度学习流程图。

图4 音频文件

图5 频谱图(spectrogram)
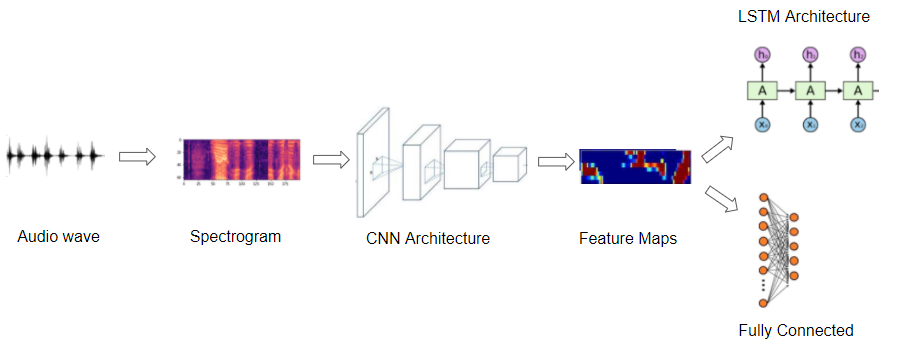
图6 音频深度学习流程图
3.深度学习网络结构
针对本项目,小编考虑了几种可能的深度学习网络结构,如全连接神经网络(DNN)、卷积神经网络(CNN+DNN)、迁移学习(vggish)。
4.音频数据
- 婴儿哭声音频
大家不难发现,其实,本文所使用的婴儿哭声数据集并不是标准的数据集,而且数据量也很小,在判断网络模型优劣方面并不具有权威性,所以本文将使用婴儿哭声测试集作为评估模型的一个参考,同时使用标准音频分类数据集(Urbansound8K)对模型进行辅助评估,并最终找到识别效果较好的深度学习分类模型。
- 实验数据集
本项目希望音频的最大长度不超过10s,故针对所使用的数据需要经过裁剪处理,并映射到指定长度。
Urbansound8K是包含10类声音的数据集,包括狗叫、汽车喇叭等声音,音频长度均在10s以内;
Babysound是一类包含6类声音的数据集,包括饿了、想睡觉等声音,音频长度为5s~30s不等(如图7所示),本项目将通过裁剪、分割不符合条件的音频,最终音频如图8所示。

图7 原始婴儿哭声音频

图8 分割之后的婴儿哭声音频数据
- 关于婴儿哭声数据集的测试集
由于分割后的婴儿哭声数据集数量依然很小(共2184条),并不足以满足训练集、验证集、测试集的各部分需求,所以本项目采用随机从 原始婴儿哭声数据集中(长度5s~30s的数据)抽取一定量的数据,并随机对抽到的每条数据进行裁剪,使得每条数据长度为10s,由此获得的有标签的294条音频数据将作为最终的婴儿哭声测试集。
四、实验
1. DNN网络
- DNN网络结构如图9所示;

图9 DNN网络结构
- Urbansound数据集在该网络中的表现如图10所示;

图10 Urbansound数据集在DNN网络中的表现
- 图11为Babysound数据集在该网络中的表现;

图11 Babysound数据集在DNN网络中的表现
- 图12为该模型在Babysound测试集上的准确率(0.8163265306122449)。

图12 婴儿哭声测试集在该模型上的准确率
2. DNN+CNN
- CNN卷积神经网络结构如图13所示;
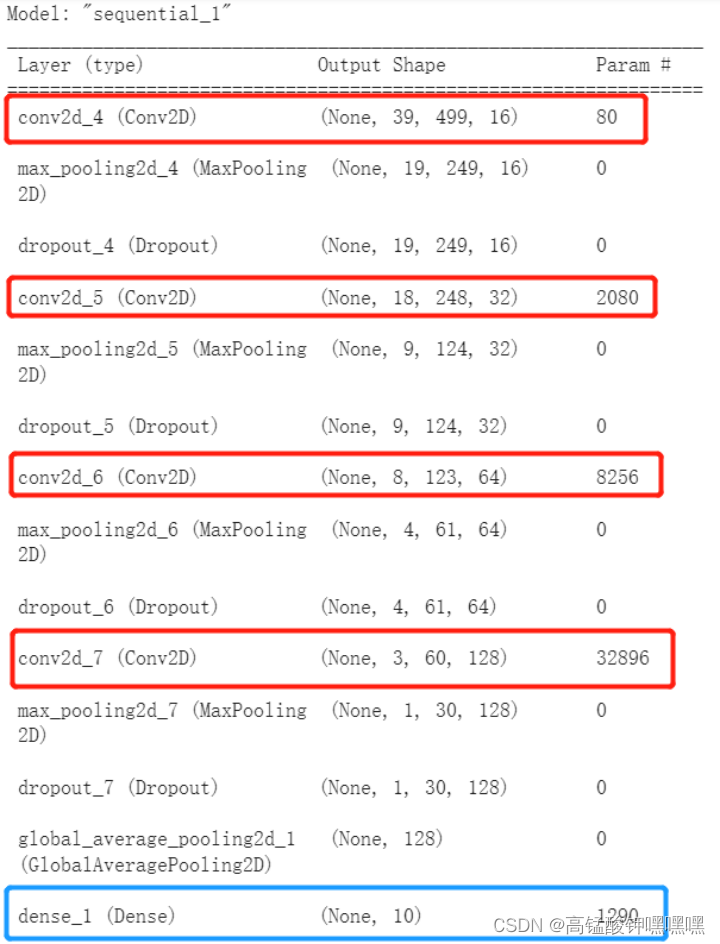
图13 CNN卷积神经网络结构
- Urbansound数据在CNN网络中的表现如图14所示;
图14 Urbansound数据在CNN网络中的表现
- Babysound数据在CNN网络中的表现如图15所示;

图15 Babysound数据在CNN网络中的表现
- CNN网络模型在Babysound测试上的准确率(0.9081632653061225)如图16所示;

图16 Babysound测试集在CNN网络模型中的准确率
- 在此网络结构下,通过迁移学习Urbansound数据集训练的模型,Babysound数据在此网络结构下的表现如图17所示;

图17 Babysound数据在迁移学习Urbansound数据模型的表现
- 迁移学习Urbansound模型在Babysound测试集上的准确率(0.9931972789115646)如图18所示。

图18 Babysound测试集在迁移学习Urbansound模型上的准确率
3. 迁移学习Vggish模型
Vggish模型是在YouTube的AudioSet数据预训练得到模型,VGGish支持从音频波形中提取具有语义的128维embedding特征向量,网络结构如图19所示。

图19 vggish网络结构
在迁移学习vggish模型的基础上,实验在网络后添加长短时记忆网络(Long Short Term Memory Network, LSTM)和一个全连接,最终将婴儿哭声数据分成6类,网络结构如图20所示。

图20 在vggish网络后添加短时记忆网络并添加一层全连接
图21展示了实验相关参数和实验结果;

图21 Babysound数据在迁移学习vggish网络模型上的表现
图22为vggish迁移模型在Babysound测试集上的准确率(0.8639455782312925)。

图22 Babysound测试集在迁移学习vggish模型上的准确率
4.实验结果汇总
表1 各模型在Babysound测试集中的准确率 深度网络在Babysound测试集中的准确率DNN网络模型0.8163265306122449迁移学习Urbansound的DNN网络模型0.5578231292517006CNN网络模型0.9081632653061225迁移学习Urbansound数据集的CNN网络模型
0.9931972789115646
迁移学习vggish模型0.8639455782312925
; 五、总结与下期预告
本文所述实验内容是婴儿哭声分类识别系统的主体部分,该部分涉及5种网络模型,分别是 DNN深度学习模型、 迁移学习Urbansound的DNN网络模型、 CNN深度学习模型、 迁移学习Urbansound数据模型和 迁移学习Vggish模型,其中迁移学习Urbansound数据模型在婴儿哭声测试集上的准确率最高,为 0.9931972789115646。
在之后的学习中,小编会将完整婴儿哭声分类识别系统(如图23所示)发布,敬请期待:
- 微信小程序——微信搜索🔍” 婴儿啼哭“或扫描图24;
- PC管理后台;
- 后端等。

图23 完整的项目结构图

图24 婴儿啼哭小程序
六、后记
项目开始于2022.03,从开始构思到完成本文提到的内容用时大概两周。本篇文章是我第一次尝试把做过的项目总结发布,希望能够通过写作戒骄戒躁、重拾信心。
回想做项目那几周真是难熬,项目截至日期的压力、身体还出现了问题,最难过的是这个时候最值得信赖的情感也出现了问题,失眠、抑郁、自闭….
项目从开始规划到完成本文内容、到完成整个系统、再到完成系统相关文档总用时一个月,真是应了那句话,打不倒我的只会让我更强大,梦想仍未实现,我等仍需努力!挺起胸膛,撑开旗帜,刀锋向前!
七、参考
- Audio Deep Learning Made Simple: Sound Classification, Step-by-Step
- Simple audio recognition: Recognizing keywords
- A Gentle Introduction to Audio Classification With Tensorflow
- 应用深度学习使用 Tensorflow 对音频进行分类
-
SENGUPTA, NANDINI, SAHIDULLAH, MD, SAHA, GOUTAM. Lung sound classification using cepstral-based statistical features[J]. Computers in Biology and Medicine,2016,75118-129. DOI:10.1016/j.compbiomed.2016.05.013.
八、更多下载
Original: https://blog.csdn.net/weixin_43028946/article/details/125556250
Author: 高锰酸钾嘿嘿嘿
Title: 婴儿哭声分类识别实现(准确率99.3%)(深度学习、迁移学习、音频分类、tensorflow)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/628928/
转载文章受原作者版权保护。转载请注明原作者出处!