

GSNet数据解读
- 原始数据
* - 1.
all_data.pkl - 2.
risk_mask.pkl - 3.
risk_adj.pkl - 4.
road_adj.pkl - 5.
poi_adj.pkl - 6.
grid_node_map.pkl - 数据理解
* - 维度
- 格式
- 如何读取四维数组?
* - 读空间分布
- 读时间分布
- 读其它分布
- 结语
之前很少用过多维数组,不知道怎么读取。今天阅读论文《Learning Spatial-Temporal Correlation from Geographical and Semantic Aspects for Traffic Accident Risk Forecasting(AAAI 2021)》时,文章提供的原始数据是4维的,正好研究一下。
原始数据
代码和原始数据:https://github.com/Echohhhhhh/GSNet
cd到nyc文件夹,可以看到数据的Readme文件。我做了部分修改和说明后,摘录如下:
可以发现,原始数据由one-hot的0/1数据、和数值类型的温度、风险数据组合而成
1. all_data.pkl
2013.1~2013.12,one time interval is 1h
shape(T, D, W, H),D=48
T is the time line
D is the feature vector, descripted as follows:
0:risk(numeric,sum)
1~24:time_period,(one-hot)
25~31:day_of_week,(one-hot)
32:holiday,(one-hot)
33~39:POI (numeric)
40:temperature (numeric)
41:Clear,(one-hot)
42:Cloudy,(one-hot)
43:Rain,(one-hot)
44:Snow,(one-hot)
45:Mist,(one-hot)
46:inflow(numeric)
47:outflow(numeric)
W*H denotes the spatial grids.
基于原始数据,作者还抽取了以下五种预处理后的数据。
2. risk_mask.pkl
shape(W,H)
top risk region mask
z
3. risk_adj.pkl
risk similarity graph adjacency matrix
shape (N,N)
4. road_adj.pkl
road similarity graph adjacency matrix
shape(N,N)
5. poi_adj.pkl
poi similarity graph adjacency matrix
shape(N,N)
6. grid_node_map.pkl
map graph data to grid data
shape (W*H,N)
df = pd.read_pickle("./grid_node_map.pkl")
d2 = pd.DataFrame(df).astype(int)
d3 = np.array(d2)
shape = d3.shape
for i in range(shape[0]):
for j in range(shape[1]):
if d3[i][j] == 1:
print(i,j)
print(shape)
数据理解
维度
T T T:时间轴(8760)
D D D: 特征数量(48),具体说明参见上文( all_data.pkl)的解释
W , H W,H W ,H: 网格的横纵坐标(20*20)
格式
pkl文件是python里面保存文件的一种格式,如果直接打开会显示一堆序列化的东西(二进制文件)。
常用于保存神经网络训练的模型或者各种需要存储的数据。一般而言,通过pandas可以读取为numpy数组。
如何读取四维数组?
四维数组不好直观在Excel等软件中展示。一个很显然的想法是进行 数据降维,固定某1-3个维度,展示其它维度的数据分布。
读空间分布
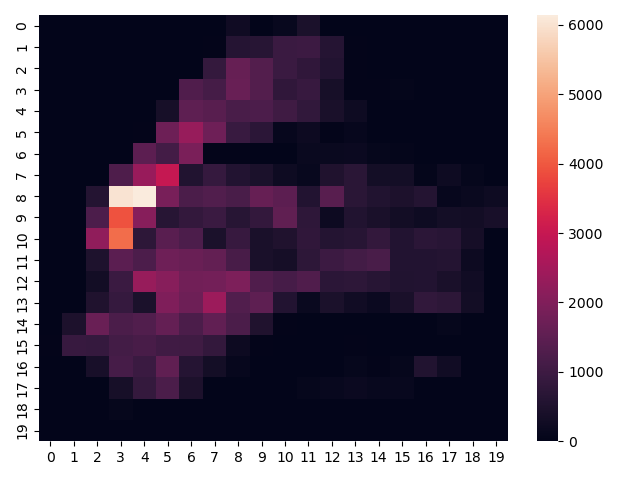
求每个网格在所有时间内的Accident次数总和分布,用热力图展示
import pandas as pd
import numpy as np
import seaborn as sb
df = pd.read_pickle("./all_data.pkl")
d_accident = df[:,0,:,:]
print(d_accident.shape)
d2 = sum(d_accident)
print(d2.shape)
d2 = pd.DataFrame(d2).astype(float)
print(d2.shape)
结果:可以发现,在某一地区,事故比较集中。

读时间分布
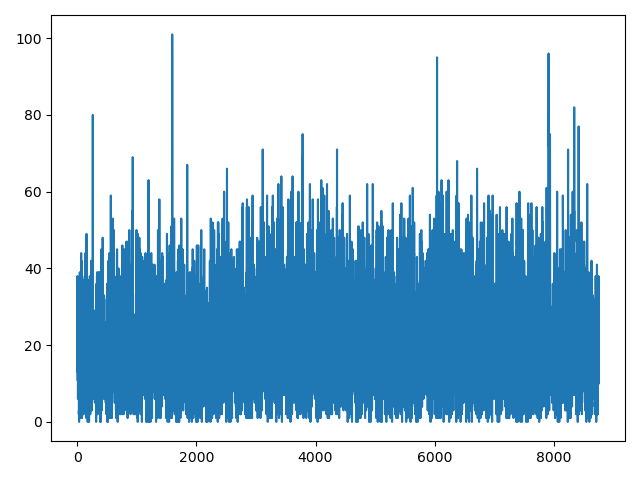
求每个时段在所有空间内的Accident次数总和分布,用折线图展示
d_3 = np.sum(d_accident,axis = 1)
print(d_3.shape)
d_4 = np.sum(d_3,axis = 1)
print(d_4.shape)
d4 = pd.DataFrame(d_4).astype(float)
import matplotlib.pyplot as plt
x = np.linspace(0,len(d4),len(d4))
plt.plot(x, d4.values)
plt.show()
结果: 可以发现事故在时间上具有一定的周期性,整体而言比较平稳。
读其它分布
可以考虑直接通过数组索引的方式,如 df[:,0,:,:]读取(0是事故的index)
结语
Data understanding是做任何数据科学项目的第一步;通过合适的数据可视化方法,可以直观的展现数据的趋势。
Original: https://blog.csdn.net/qq_41145832/article/details/120721276
Author: 朗泰乐
Title: 读懂GSnet(一):pandas读取pkl格式的多维数组,可视化理解时空数据
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/699950/
转载文章受原作者版权保护。转载请注明原作者出处!