

YOLO3D:端到端3D点云输入的实时检测
前言
YOLO3D将YOLO应用于3D点云的目标检测,与Complex-YOLO(Complex-YOLO的解读从这进入)类似,不同的是将yolo v2的损失函数扩展到包括偏航角、笛卡尔坐标下的三维box以及直接回归box的高度。
论文: https://arxiv.org/abs/1808.02350
算法分析
模型输入
论文中将3D点云投影为鸟瞰图网格,创建两个网格映射如图。


第一个包含最大高度,其中每个网格单元(像素)值表示与该单元关联的最高点的高度。 第二个网格图表示点的密度,密度的计算参考MV3D(论文解读从此进入)。
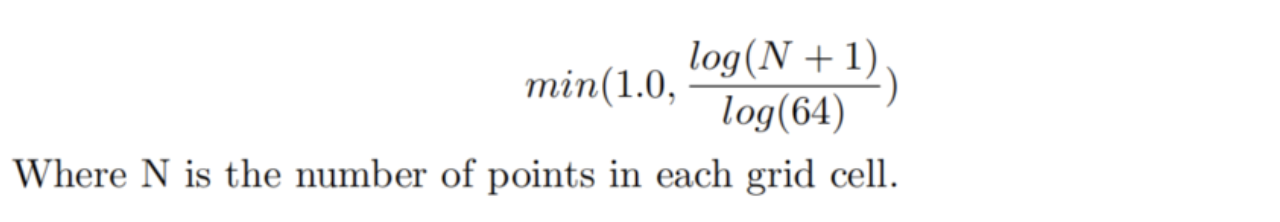
; 网络结构
论文的结构参考YOLO-v2架构,做了一些修改。
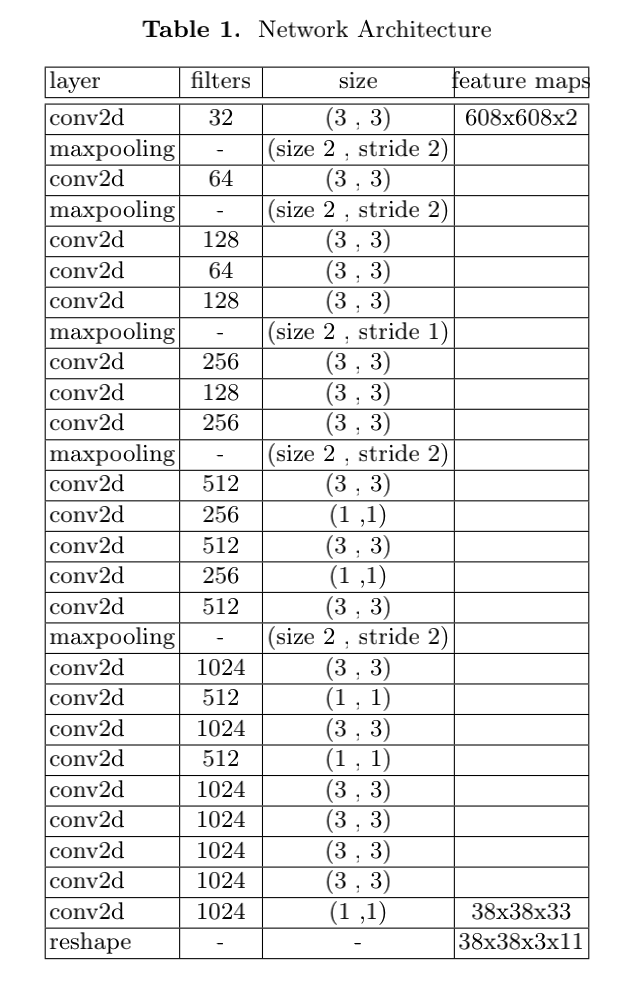
- 修改了一个最大池化层,将下采样从 32 改为 16,有了一个更大的网格,这有助于检测行人和骑自行车的人等小物体。
- 从模型中删除了skip connection,因为它会导致结果不太准确。
回归损失
3D box 回归
论文在原始YOLO v2中添加了两个回归项以生成 3D 边界框:中心的 z 坐标和框的高度。z 坐标的回归以类似于 x 和 y的回归的方式,通过 sigmoid 激活函数进行坐标。
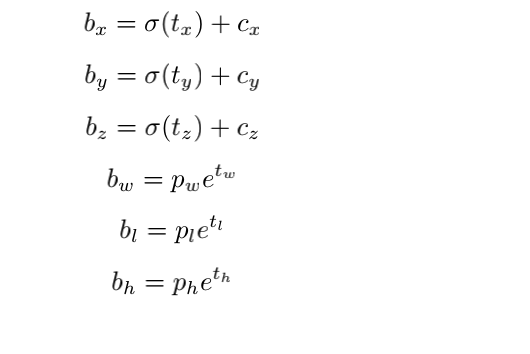
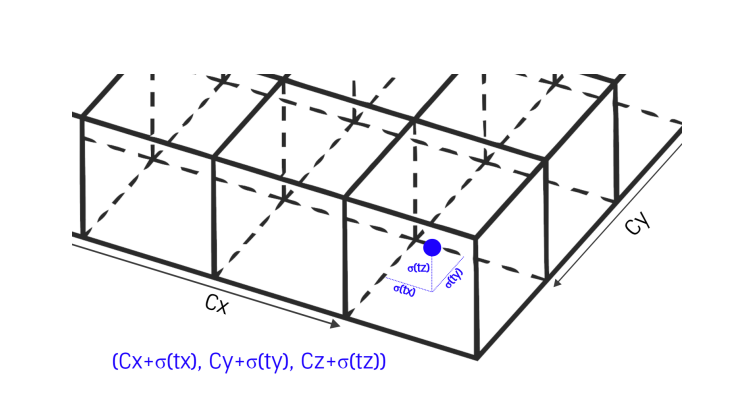
值得注意的是,虽然 x 和 y 通过在每个网格单元中预测 0 到 1 之间的值进行回归,定位该点位于该单元内的位置,但 z 的值仅映射到位于一个垂直网格单元内,如下图所示 . 选择将 z 值仅映射到一个网格而将 x 和 y 映射到多个网格单元的原因是 z 维度中值的可变性远小于 x 和 y 的可变性(大多数对象具有非常相似的框高程 )。
; 偏航角回归
论文中定义边界框的方向范围从 -π 到 π。 将该范围归一化为 -1 到 1,并调整我们的模型以通过单个回归数直接预测边界框的方向。 在损失函数中,计算地面实况和我们预测的角度之间的均方误差:

边界框损失函数
3D box的损失是2Dbox原始 YOLO 损失的扩展。偏航项的损失按照 上述计算。高度的损失是中宽度和长度损失的延伸。类似地,z 坐标的损失是 x 和 y 坐标损失的扩展。
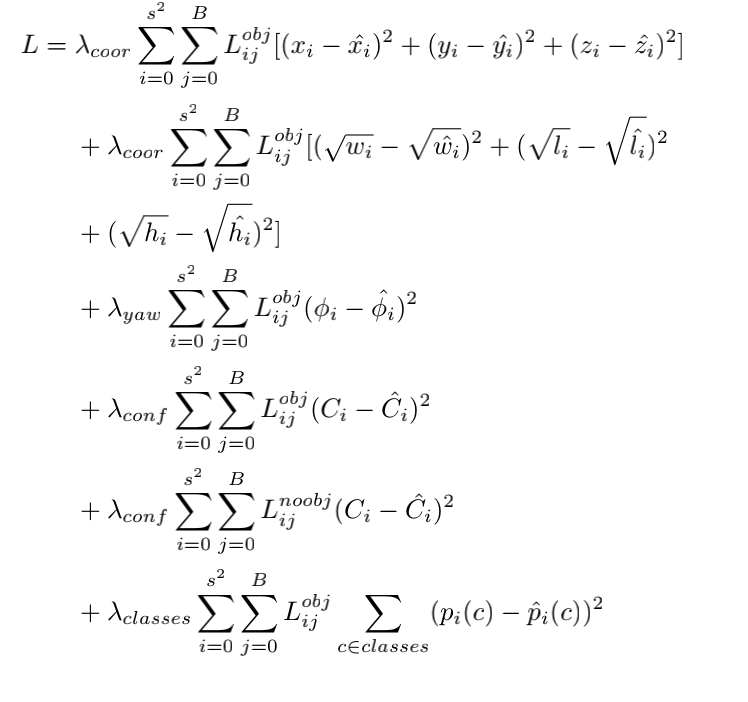
λ c o o r λcoor λc o o r :分配给坐标损失的权重,
λ c o n f λconf λc o n f :分配给预测置信度损失的权重,
λ y a w λyaw λy a w:分配给方向角损失的权重,
λ c l a s s e s λclasses λc l a s s e s :分配给损失的权重 类概率,
L i j o b j L^{obj}{ ij}L i j o b j :一个变量,它根据第 i 个和第 j 个位置中是否存在真实值框取 0 和 1 的值。如果有一个盒子,则为 1,否则为 0,
L i j n o o b j L^{noobj}{ ij}L i j n o o b j :与前一个变量相反。如果没有物体,则取值为 0,否则取值为 1,
x i , y i , z i x_i , y_i , z_i x i ,y i ,z i :地面实况坐标,
x i ^ , y i ^ , z i ^ \hat{x_i}, \hat{y_i}, \hat{z_i}x i ^,y i ^,z i ^ :地面实况和预测方向角,
φ i , φ i ^ φ_i, \hat{φ_i}φi ,φi ^ :地面实况和预测方向角 …等,
C i , C i ^ C_i, \hat{C_i}C i ,C i ^ : 真实情况和预测置信度,
w i , l i , h i w_i , l_i , h_i w i ,l i ,h i : 真实情况宽度、高度和盒子的长度,
w i , l i , h i w^i, l^i, h^i w i ,l i ,h i : 预测宽度、高度和长度框
p i ( c ) 、 p i ^ ( c ) p_i( c)、\hat{p_i}( c)p i (c )、p i ^(c ) 真实情况和预测的类别概率。
; 数据集处理
论文使用了 KITTI 基准数据集。 点云以每像素 0.1m 的分辨率在 2D 空间中投影为鸟瞰网格图,与MV3D使用相同的分辨率。
网格图表示的 LiDAR 空间范围为向右 30.4 米,向左 30.4 米,向前 60.8 米。 在上述分辨率为 0.1 的情况下使用此范围会导致每个通道的输入形状为 608×608。
LiDAR 空间中的高度剪裁在 +2m 和 -2m 之间,并缩放到 0 到 255 以表示为最大高度通道中的像素值。
训练
该网络以端到端的方式进行训练。 使用了动量为 0.9、权重衰减为 0.0005 的随机梯度下降。 将网络训练了 150 个 epoch,批量大小为 4。
对于前几个 epoch,将学习率从 0.00001 慢慢提高到 0.0001。 如果以高学习率开始,我们的模型通常会因梯度不稳定而发散。 再继续用 0.0001 训练 90 次,然后用 0.0005 训练 30 个时期,最后用 0.00005 训练最后 20 次。
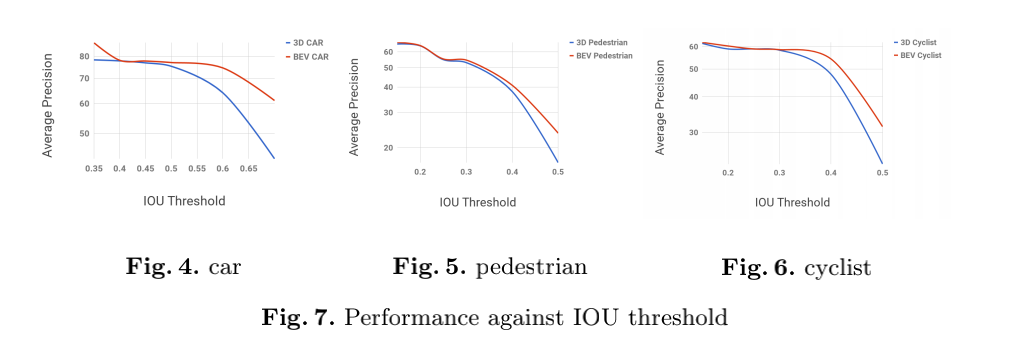
结果
参考:
论文阅读《YOLO3D: End-to-end real-time 3D Oriented Object Bounding Box Detection from LiDAR Point Cloud》
Original: https://blog.csdn.net/qingliange/article/details/122912653
Author: 城市黎明的烟火
Title: 【YOLO3D】:端到端3D点云输入的实时检测
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/533054/
转载文章受原作者版权保护。转载请注明原作者出处!