

主成分分析(PCA)应用——特征提取/人脸识别(上)
序
我在另一篇文章《无监督学习与主成分分析(PCA)》中已经讲过关于PCA的原理,以及它的其中一个应用—— 降维。那么本篇文章我来说一下PCA的另一个应用—— 特征提取。
特征提取背后的思想是,可以找到一种数据表示,比给定的原始表示更适合分析。特征提取很有用,它的一个很好的应用实例就是最近几年很火的 人脸(图像)识别。
考虑到有很多小伙伴不了解图像的处理,所以我们分成上下两篇来进行讲解。
本篇先讲解图像的基础以及python通常是如何处理图像的。
数据来源
LFW – People (Face Recognition):https://www.kaggle.com/atulanandjha/lfwpeople?select=pairs.txt


这是kaggle网站上一个专门用来做人脸识别的数据集,收录了网站上超过13000张人脸图片。好的,那么接下来把这份图片数据集下载下来并解压。
PS:下载下来的图片保存在lfw-funneled.tgz文件里,”.tgz”是一种压缩文件的格式,所以我们只要解压缩就可以了。
解压完毕后,我们就可以看见图片存储在以每人的名字所命名的文件里,每个文件夹包含数量不同的照片,而每个照片又分别以名字+数字的名字命名,方便我们使用。
; 数据整理
我们每拿到一份新数据,一定要对数据进行整理, 了解数据的基本信息,譬如数据量,如何命名,数据维度等。
import os
all_folds = os.listdir(r'C:\Users\Administrator\Desktop\源数据-分析\lfw_funneled')
all_folds = [x for x in all_folds if '.' not in x]
print(len(all_folds))
n=os.listdir('C:\\Users\\Administrator\\Desktop\\源数据-分析\\lfw_funneled\\Richard_Gere\\')
print(n[0])
os模块是一个python中专门用来遍历文件的第三方模块,具体原理就不在这里赘述了,感兴趣的朋友可以自己搜一下。那么运行上述代码后,我们就可以得知在lfw_funneled文件夹中,一共有5749文件,也就是说一共有5749个人的人脸图像,并且每个人的图像均是以名字+数字的方式来命名的.jpg图像文件。
那么接下来我们再看下每个人都有多少张人脸图像,代码如下所示:
import pandas as pd
numbers_img=pd.DataFrame(columns=["文件名称","图片数量"])
for i in range(len(all_folds)):
path = 'C:\\Users\\Administrator\\Desktop\\源数据-分析\\lfw_funneled\\'+all_folds[i]
all_files = os.listdir(path)
numbers_img.loc[i]=[all_folds[i],len(all_files)]

这样一来,我们就知道了每个人有多少张人脸图像,也方便我们接下来进行数据集的选取和划分。
可以看出数据非常庞大,我们不可能对所有数据进行机器学习(电脑硬件达不到)。同时我们还要降低 数据倾斜对模型精度的影响,那么我们这里只选取图片数量为10的人脸来当作数据集。

PS:如果某人的人脸出现次数过多的话,会造成数据倾斜,大大影响特征提取。
图像处理
基础介绍
这里先简单说一下什么是图像。图像由 像素组成,通常存储为 红绿蓝(RGB)强度(三维维度)。图像中的对象通常由上千个像素组成,它们只有放在一起才有意义。而我们所需要做的便是读取图像,将图像的像素转化为numpy数组,然后再通过操作numpy数组来去处理图像,最后再还原。
python里面有一个 PIL的第三方模块,是专门用来处理数据的,如下图所示:

一般的像素值是以三维的形式存储的,其中有一个维度是专门用来存储像素颜色的。考虑到接下来的数据处理速度及提高模型精度,我们便剔除颜色维度,用图像的 灰度值版本来进行处理,代码如下所示:

; 图像操作
1.图片转换成灰度值
好的,图像的基础处理方法讲解完了,接下来我们便对选出来的包含150张图片的数据集依次进行处理,代码如下所示:
from PIL import Image
import numpy as np
image_arr_list=[]
flat_arr_list=[]
target_list=[]
for m in range(len(img_10["文件名称"])):
file_address='C:\\Users\\Administrator\\Desktop\\源数据-分析\\lfw_funneled\\'+img_10["文件名称"][m]+"\\"
image_name=os.listdir(file_address)
for n in image_name:
image=Image.open(file_address+n)
image=image.convert('L')
image_arr=np.array(image,"f")
flat_arr=image_arr.ravel()
image_arr_list.append(image_arr)
flat_arr_list.append(flat_arr)
target_list.append(m)
faces_dict={"images":np.array(image_arr_list),"data":np.array(flat_arr_list),"target":np.array(target_list)}
将读取的像素信息转化为numpy数组后,分别存储在各自对应的列表里面,并组合成一个字典,方便接下来的使用。接下来简单讲解一下:
- 读取的RGB像素值如果直接转化为numpy数组的话会是三维数组,转换为一维数组后是可以用作接下来的机器学习的,但会大大降低训练速度。
- 灰度值转化成的numpy数组是一个二维数组,如果直接用于机器学习的话是没有办法读取使用的,所以需要用.ravel()来将二维数组转化为一维数组,也就是将两行的数据强行拉成一行数据。
- 如果数据集的标签值(目标值)”target”是文本的话,在接下来的训练部分中,机器便会无法识别,并报错,所以需要转换为数字。并且 为了对应前面特征值的维度(数据维度是150行),这里需要将target也转换成numpy数组。
- 这里之所以存储成字典,而不是DataFrame格式,也是因为存储维度的问题。如果存储成DataFrame的话,便需要62500(每张图片的像素数量是250×250)列来存储每个像素,这样的DataFrame太大了,不利于后面的处理,所以这里就以numpy数组的形式存储成字典。
这里再说一下字典中的”images”,”data”的维度,如下所示:
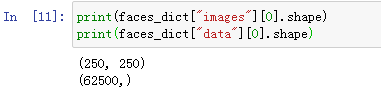
图片的像素是以250×250的二维numpy数组的形式存储在”images”中,而为了接下来的机器学习,便将二维数组转换为一维numpy数组存储在”data”中(250×250=62500)。
PS:可以通过矩阵变换,将原有的一维数组还原成二维灰度值,具体原理就不多说了,代码如下:
shape=image_arr.shape
vector=np.matrix(flat_arr)
arr2=np.asarray(vector).reshape(shape)
2.灰度值还原成图片
接下来,我们可以把灰度值再还原成图片,代码如下所示:
from matplotlib import pyplot as plt
i = 0
plt.figure(figsize=(45, 30))
for img in faces_dict["images"]:
plt.subplot(15,10,i+1)
plt.imshow(img, cmap="gray")
plt.xticks([])
plt.yticks([])
plt.xlabel(faces_dict["target"][i])
i=i+1
plt.show()

总结
好的,关于python处理图像方面的基础便先说道这里。总的来说,便是利用numpy函数来存储组成图像的像素信息,之后通过操作numpy数组来去达到变换图像的目的。
下一篇,我会讲解关于人脸识别的模型训练,以及PCA对训练过程的优化。
个人博客:https://www.yyb705.com/
欢迎大家来我的个人博客逛一逛,里面不仅有技术文,也有系列书籍的内化笔记。
有很多地方做的不是很好,欢迎网友来提出建议,也希望可以遇到些朋友来一起交流讨论。
Original: https://blog.csdn.net/weixin_43580339/article/details/118222281
Author: yb705
Title: 主成分分析(PCA)应用——特征提取_人脸识别(上)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/699574/
转载文章受原作者版权保护。转载请注明原作者出处!