

距离上一次半夜总结已经过了两天了,我已经完成了pandas学习,今天从头到尾总结一下
首先是最基础的读数据,创建数据,取数据
首先是创建数据,数据类型为
这一块要提出DataFrame和Series两个主要对象(注意大写
DataFrame是一个表,而表就有表头和索引
分别是行名和列名
pd.DataFrame({‘索引’:值}) 利用字典的声明方法来对列标签进行赋值命名
eg:
pd.DataFrame({‘Yes’: [50, 21], ‘No’: [131, 2]})
但我们通常也需要对行标签进行赋值命名,这里需要参数index
pd.DataFrame({‘行名’:值,’行名’:值,’行名’:值},index = [ ‘列名’ ,’列名’,’列名’]),注意这里用的是列表的方式命名,前者是字典
但值在给的时候也用的列表
eg:
pd.DataFrame({‘Bob’: [‘I liked it.’, ‘It was awful.’], ‘Sue’: [‘Pretty good.’, ‘Bland.’]}, index=[‘Product A’, ‘Product B’])
Series是一个列表,是DataFrame的一个列。
eg: pd.Series([1, 2, 3, 4, 5])”’注意数据的形式是列表”’
就像table(DataFrame)和list(Series)的关系一样
那么这么说,一个列来取数据是不需要列名的。但他可以有个总的名字,即name,也可以有索引,也就是行名
eg:pd.Series([30, 35, 40], index=['2015 Sales', '2016 Sales', '2017 Sales'], name='Product A')
上面是创建数据的过程,和一些参数index_col和
下面是读取数据的方法:
reviews = pd.read_csv(‘文件名’)
其实read_csv,csv指的是按逗号分割的文件名,即”Comma-Separated Values”
其中常用的参数:index_col = 0,取第0列作为索引(行名)
eg:
wine_reviews = pd.read_csv(“../input/wine-reviews/winemag-data-130k-v2.csv”, index_col=0)
读取数据的格式大小方法:
reviews .shape()
取前五行的方法
reviews.head()
可以总结到,index通常就是和行名有关
reviews = pd.read_csv(‘文件地址’)
那么我们读到了这样一个数据,我们如何对索引进行选择,分配,更改一些操作
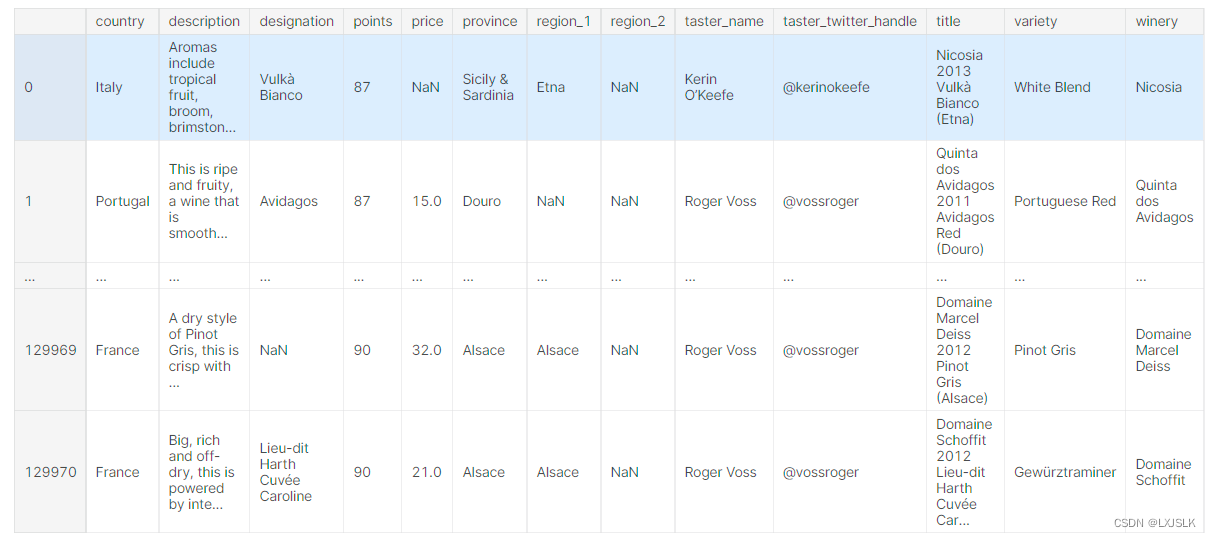

如果我要选取某一列的数据,我会
reviews.country,reviews.points
reviews[‘country’],reviews[‘points’]
对于reviews来说,country和points都是他的属性,我们这样可以访问他的属性
也可以用操作符访问
如果选取某一列某一行
reviews[‘country’][0]
返回的是country列和第0行的的值,这个值是’Italy’,是一个str
这里这个方法返回Series类型的列
通过索引的方式呢, 返回的肯定是某一行,我们有时候需要提取某一行的数据,可以用
index-based selection,也就是iloc方法
reviews.iloc[0],意思就是索引基于选择0行

iloc的访问方式很多,但访问方式是先行后列,这里面和上面python的访问方式不同
比如这里我要访问第一列
reviews.iloc[:,0] ''' : 本身也来自原生Python,它的意思是"一切"'''
或者说我要访问前3行的第0列
reviewsiloc[:3,0]
也可以选择最后五行向后计数
reviews[-5:]
Label-based selection ,也就是loc方法
loc方法也是先行后列
reviews.loc[0, 'country']
reviews.loc[:, ['taster_name', 'taster_twitter_handle', 'points']]
iloc和loc的区别需要记住
iloc在面对0:10选取的是0,…..,9
loc在面对0:10选取的是0,……,10
总之iloc是不取:后面的结尾,loc要取
操作索引的名字
set_index可以达到这个目的
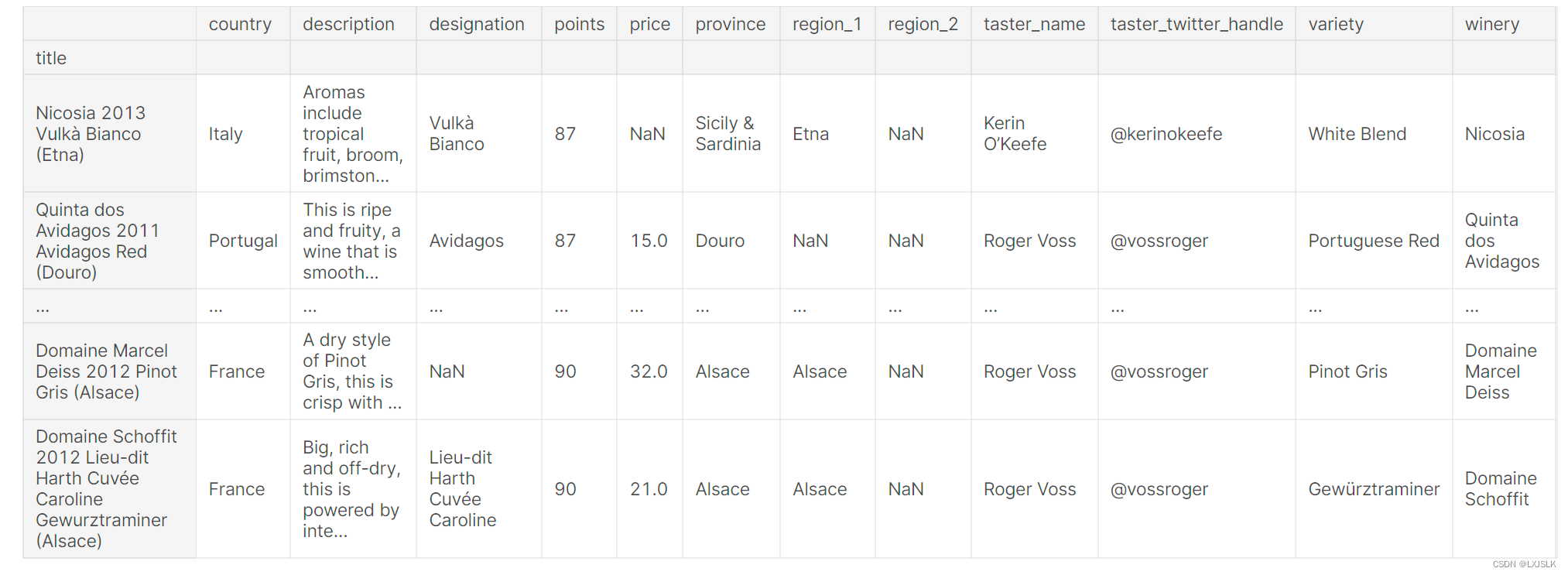
eg:reviews.set_index(“title”)
人家的意思:
如果你能为数据集提供一个比当前索引更好的索引,这是很有用的
This is useful if you can come up with an index for the dataset which is better than the current one.
我们将用属性访问的Series来进行操作
reviews.country == ‘Italy’
这里返回的是Series由布尔值组成

那么返回的布尔值就可以进行操作啦
这个结果可以在loc内部用来选择相关的数据
我们可以这样
reviews.loc[reviews.country == ‘Italy’]
这样可以取出来Italy的国家那几行
如果我们还想加上一些条件
reviews.loc[(reviews.country == ‘Italy’) & (reviews.points >= 90)]
取意大利国家的评分大于90分的行数
总的来说可以用Series的结果来对DataFrame进行一些操作,我们将如何处理DataFrame的问题转换为如何用属性进行运算来DataFrame
这里还有几种方式
reviews.country.isin([‘Italy’,’France’])
这里会返回哪些是意大利和法国的布尔值组成的Series
那么放进reviews.loc[reviews.country.isin([‘Italy’,’France’])]
我们便取出来所有想要的国家的行
还有两个方法分别是:notnull和isnull,notnull可以把非空值(NaN)的行选取出来
reviews.loc[reviews.price.notnull()]
上面是选取数据的过程我们知道了loc和iloc,也知道了loc和属性的方法联合进行访问的方法 ,下面是如何分配数据
最直接的方式
reviews['critic'] = 'everyone'
单独创建一个critic的列,赋值为everyone
reviews['index_backwards'] = range(len(reviews), 0, -1)
对index_backwards进行赋值,赋值是从reviews行数的最大值赋值,逐步递减1,直至为0
有时不仅需要读取和分配,我们还需要读取需要的数据,从上面对属性进行方法就可以知道,pandas自带一些对数据处理的方法
Summary functions
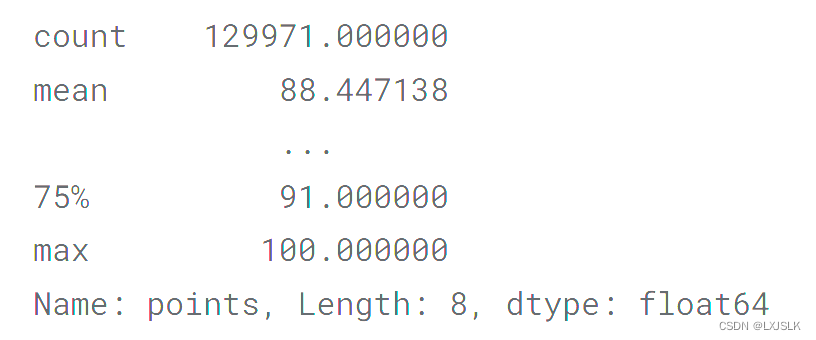
用describe方法对可以得到所有方法的结果
reviews.points.describe()
对于不同类型的值,describe会自动调整
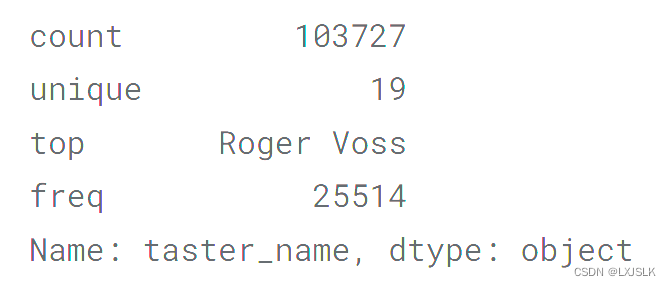
reviews.taster_name.describe()
reviews.taster_name.unique()
取出只出现了一次的值,返回的是一个array数组
reviews.taster_name.value_counts()
取出每一种值出现次数,返回Series,并且从大到小递减分布
Maps 映射,Maps能让我们将现有数据根据函数运算的新的数据,或者将格式进行转化
有两种Maps方法第一种是map,对Data列数据进行转换
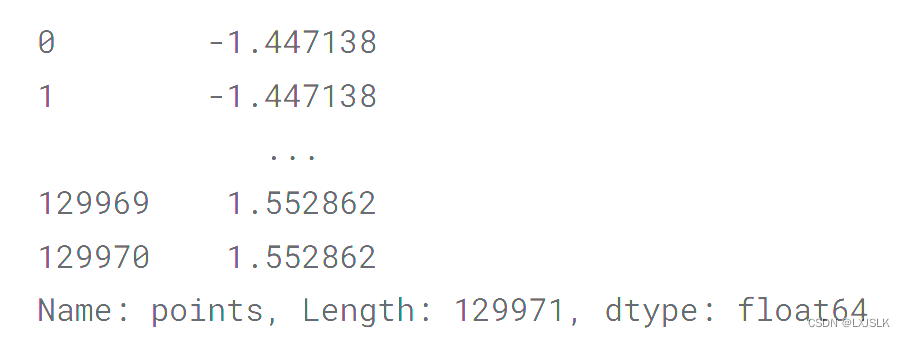
reviews_poionts_means= reviews.points.mean()
reviews.points.map(Lambda p: p -reviews_poionts_means)
将points对象里面的值全换成了和均值之间的差,map()返回的是一个Series,有map里申明的函数转换好后的值
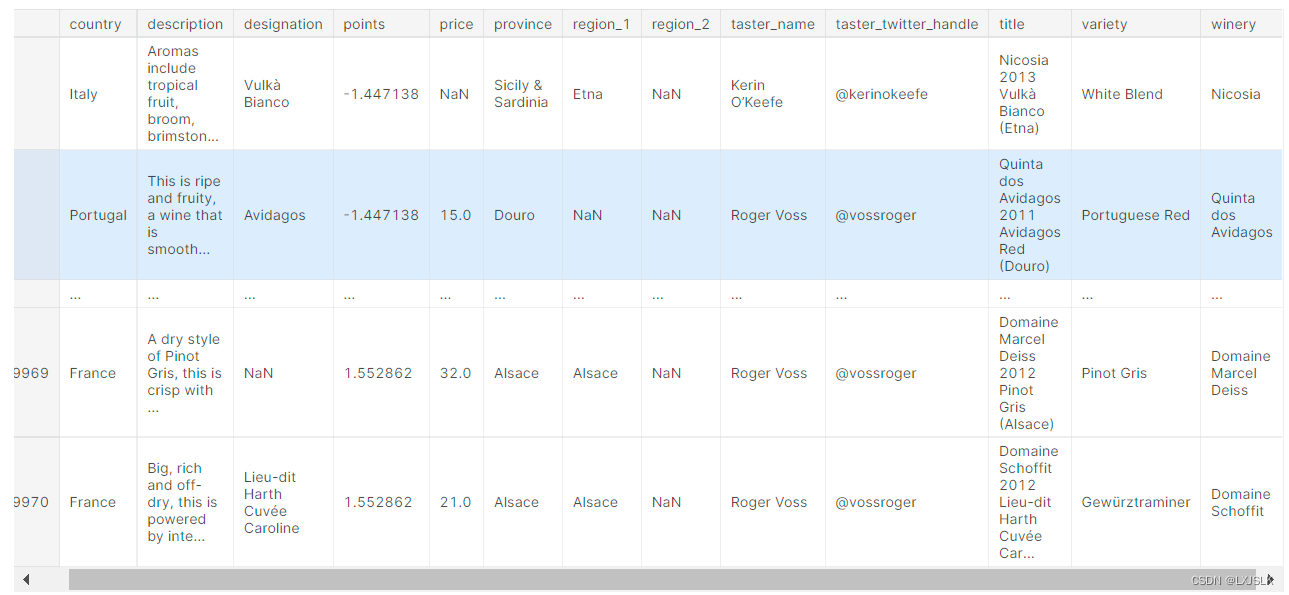
我们还有一种映射Maps方法,apply,apply可以将整个DataFrame转换并获得一个DataFrame
eg:
def remean_points(row):
row.points = row.points - review_points_mean
return row
reviews.apply(remean_points, axis='columns')
下面是用内置函数的方式进行直接转换,返回一个Series值
review_points_mean = reviews.points.mean()
reviews.points - review_points_mean
reviews.country + " - " + reviews.region_1

相比map和apply,后者操作迅速简单,但不能进行逻辑上的运算,更不能自定义
排序和分组操作
上述的map和apply都是对一个列进行操作,返回一个列,但有时候我们需要按照规律重新分组,这里就需要groupby()
eg:
reviews.groupby('points').points.count()
将reviews的分数和分数出现次数进行分组,分组的方式是由计数count决定,每一个分数总共出现了多少次
eg:
reviews.groupby('points').price.min()
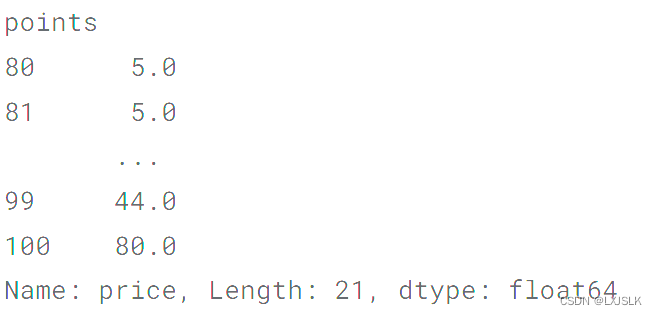
将reviews的points和该分数下最低的价格进行分组(这样才能一一对应)
您可以将我们生成的每个组看作DataFrame的一个切片,其中只包含具有匹配值的数据
而groupby()的参数,作为新的切片的索引
reviews.groupby('winery').apply(lambda df: df.title.iloc[0])
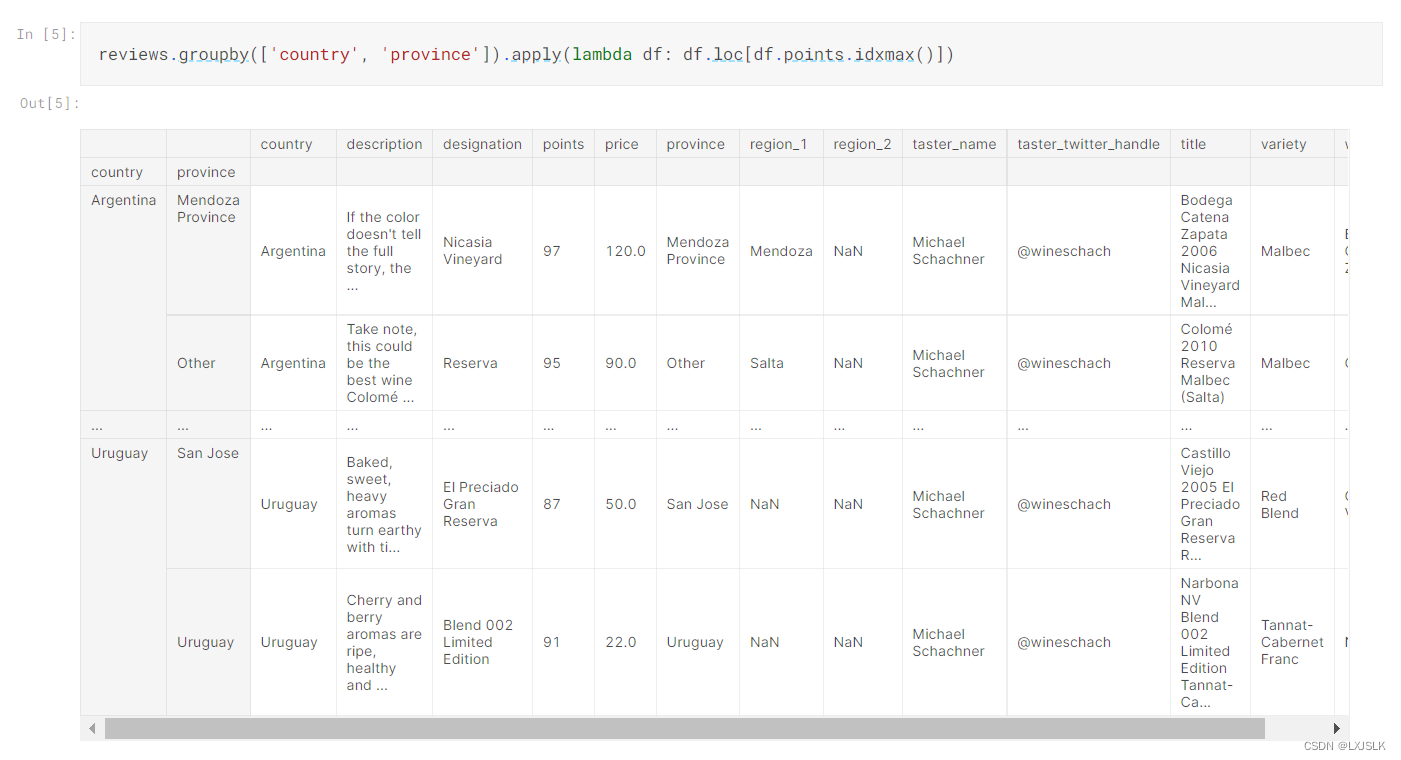
也可以进行更加精细的控制,增加多个新的列,并选取由其他列选取的行
review.groupby([‘country’,’province’]).apply(lambda df: df.loc[df.points.idmax()])
idmax方法返回points最大值的索引,索引送给loc定位,df输出改行
相比apply,agg能对属性运用多个方法。
eg:reviews.groupby(‘country’).price.agg([len,min,max])
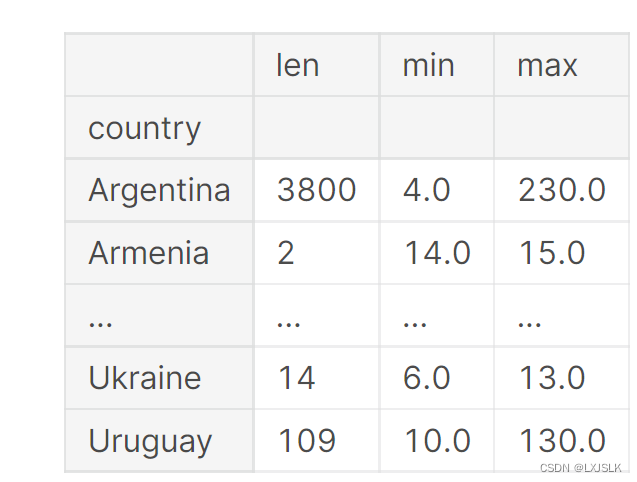
多索引
上述大多数DataFrame,Series只有一个索引,而groupby能为我们创立多索引,也叫 multi-index
和常规索引不同在于,他有多个级别
countries_reviewed = reviews.groupby([‘country’,’province’]).description.agg([len])
取每一个国家和省份对酒描述的长度len
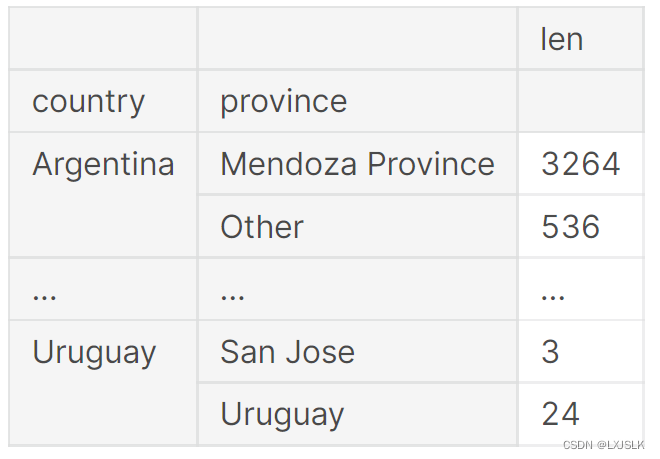

多索引有几种方法来处理它们的分层结构,这是单级索引所没有的。它们还需要两个级别的标签来检索值。
可以用reset_index()转换多索引为常规索引
countries_reviewed.reset_index()
上述都是由索引分组,下面为由值分组
Sorting
countries_reviewed = countries_reviewed.reset_index()
countries_reviewed.sort_values(by = ‘len’)#由description长度从小到大排序
countries_reviewed.sort_values(by = ‘len’,ascending = False)#长度由从大到小
countries_reviewed.sort_index()#由默认方式排序

可由多个列排序
countries_reviewed.sort_values(by = [‘len’,’country’])
数据类型和忽略值
DataFrame或Series中的列的数据类型称为dtype。
可以用dtype方法获取某一列的数据类型,比如说,
reviews.price.dtype

dtypes 可以返回所有DataFrame中的所有值的dtype
reviews.dtypes

要记住的一个特性(在这里非常清楚地显示了)是,完全由字符串组成的列没有自己的类型;相反,它们被赋予对象类型.
可以用astype方法转换类型。
reviews.points.astype(‘float64’)
有些值被给了NaN,Not a Number,并且类型是float64
pd.isnull()和pd.notnull()两个方法针对NaN数据
reviews[pd.isnull(reviews.country)]
取出国家列不清楚的reviews
fillna()可以将reviews里面的NaN数据填充为想要的值
reviews.region_2.fillna(‘Unknown’)
replace()可以将值不为null的替换为现在想要的
reviews.taster_twitter_handle.replace("@kerinokeefe", "@kerino")
replace()方法在这里值得一提,因为它可以方便地替换数据集中提供了某种哨值的缺失数据:诸如”未知”、”未披露”、”无效”等。
重命名和合并
不同来源的数据需要合并 您还将探索如何组合来自多个DataFrames和/或Series的数据。
重命名
rename() 下面是更改列名的例子
reviews.rename(columns = {‘points’:’score’})
更改行名的例子:
reviews.rename(index = {0:’first’,1:’second’})
更改行索引的名字,更改列索引的名字
reviews.rename_axis(‘wines’,axis = ‘rows’).rename_axis(‘fields’,axis = ‘columns’)
组合
concat()
当具有相同的列时。十分有用
canadian_youtube = pd.read_csv("../input/youtube-new/CAvideos.csv")
british_youtube = pd.read_csv("../input/youtube-new/GBvideos.csv")
pd.concat([canadian_youtube, british_youtube])
join()允许您组合具有共同索引的不同DataFrame对象。
left = canadian_youtube.set_index(['title', 'trending_date'])
right = british_youtube.set_index(['title', 'trending_date'])
left.join(right, lsuffix='_CAN', rsuffix='_UK')

merge()可以做的大部分工作也可以用join()更简单地完成,因此我们将忽略它,在这里只关注前两个函数
Original: https://blog.csdn.net/LXJSLK/article/details/127804382
Author: LXJSLK
Title: 在kaggle上的pandas学习总结
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/657306/
转载文章受原作者版权保护。转载请注明原作者出处!