

一、原理:
以一个二分类为例(y = -1,1):希望支持向量间的距离尽可能远。
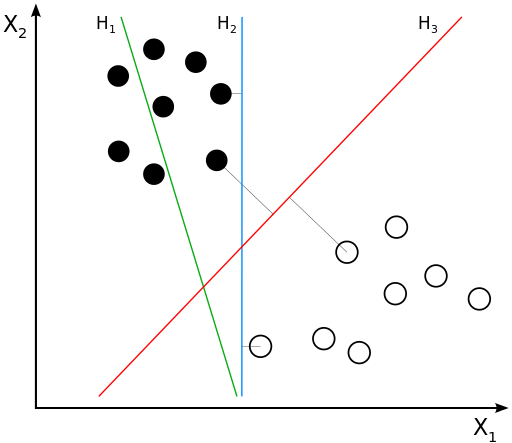

我们可以看到上面三个方法的效果:
分类效果H1无法完成分类H2robost性较差(在新的数据集上健壮性较差)H3最稳健
1.SVM与其他分类器不同:
其他分类器将所有样本视为同样作用,而支持向量机 仅重视几个支持向量(很少的样本)。
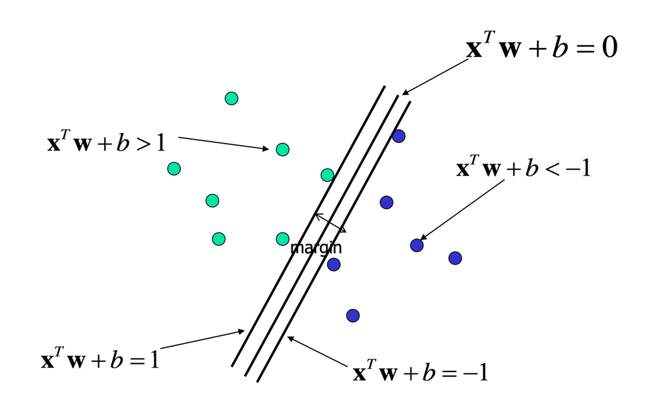
2.利用 凸优化原理:

3.维数 超过样本样本数是ok的
SVM支持高维分类
4.训练 多个label的原理:
比如有1,2,3个类别,那么可以训练3个SVM模型
; 二、当两个类看似不一定可分时:
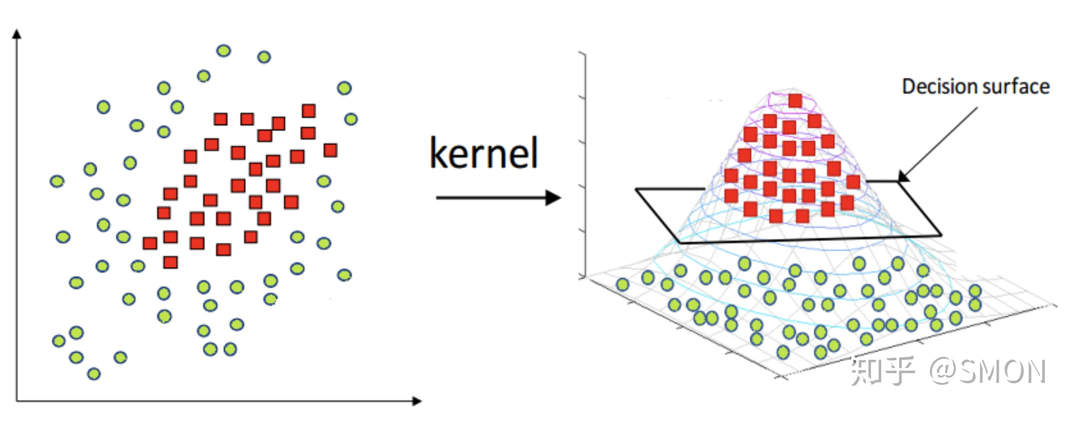
高维数据或者线性不可分数据利用 核函数映射到高维,直观理解如图:
三、代码示例
1.简单示例
from sklearn import svm
x = [[0, 0], [1, 1], [3, 3], [4, 4]]
y = [0, 1, 1, 1]
clf = svm.SVC()
clf.fit(x, y)
print(clf.predict([[2., 2.]]))
print(clf.support_vectors_)
2.SVM可视化

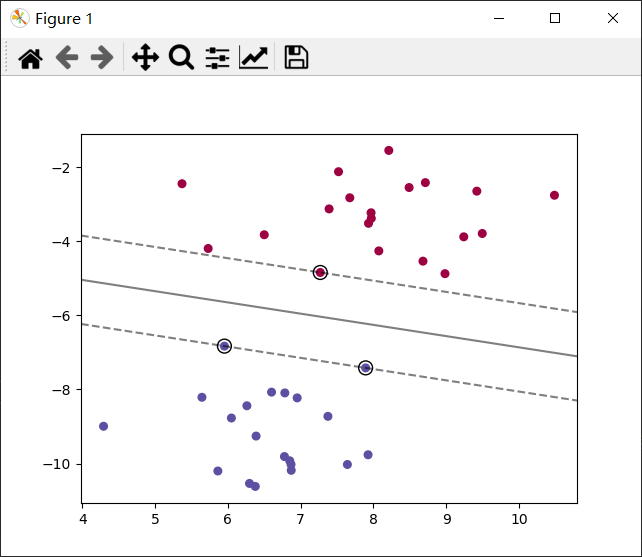
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm
from sklearn.datasets import make_blobs
x, y = make_blobs(n_samples=40, centers=2, random_state=6)
print(np.concatenate((x, y.reshape(-1, 1)), axis=1))
clf = svm.SVC(kernel="linear", C=1000)
clf.fit(x, y)
plt.scatter(x[:, 0], x[:, 1], c=y, s=30, cmap=plt.cm.Spectral)
ax = plt.gca()
xlim = ax.get_xlim()
print(xlim)
ylim = ax.get_ylim()
print(ylim)
xx = np.linspace(xlim[0], xlim[1], 30)
yy = np.linspace(ylim[0], ylim[1], 30)
YY, XX = np.meshgrid(yy, xx)
xy = np.vstack([XX.ravel(), YY.ravel()]).T
z = clf.decision_function(xy).reshape(XX.shape)
ax.contour(
XX, YY, z, colors="k", levels=[-1, 0, 1], alpha=0.5, linestyles=["--", "-", "--"]
)
ax.scatter(
clf.support_vectors_[:, 0],
clf.support_vectors_[:, 1],
s=100,
linewidth=1,
facecolors="none",
edgecolors="k",
)
plt.show()
3.具体实例:
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
data = pd.read_csv("D:\\university\\211term\\数据挖掘\\PDMBook\\第三章 分类模型\\3.8 SVM\\SVM.csv")
print(data.columns)
x = data[[
'Alcohol', 'Malic acid', 'Ash',
'Alcalinity of ash', 'Magnesium',
'Total phenols', 'Flavanoids',
'Nonflavanoid phenols',
'Proanthocyanins', 'Color intensitys',
'Hue', 'OD280/OD315 of diluted wines',
'Proline'
]]
y = data['label']
x_train, x_test, y_train, y_test = train_test_split(
x, y, test_size=0.1
)
from sklearn.svm import SVC
from sklearn.model_selection import GridSearchCV
svc = SVC()
paramGrid = dict(
kernel=['linear', 'poly', 'rbf', 'sigmoid']
)
gridSearchCV = GridSearchCV(
svc, paramGrid,
cv=3, verbose=1, n_jobs=5,
return_train_score=True
)
grid = gridSearchCV.fit(x_train, y_train)
print('最好的得分是: %f' % grid.best_score_)
print('最好的参数是:')
for key in grid.best_params_.keys():
print('%s=%s' % (key, grid.best_params_[key]))
best_model = grid.best_estimator_
print(best_model.predict(x_test))
s = pd . Series(best_model.predict(x_test),
index=y_test.index)
print(s-y_test)
print(np.sum(s-y_test == 0))
print(best_model.score(x_test, y_test))
4.学习到的编程细节:
1.函数:np.concatenate,
2.网格搜索
Original: https://blog.csdn.net/qq_57082933/article/details/121347801
Author: Angel Q.
Title: 支持向量机(SVM)原理及实现
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/699300/
转载文章受原作者版权保护。转载请注明原作者出处!