

最近在使用LSTM做基于THUCNews数据集的文本分类。之前用LSTM模型做10种新闻种类的分类时可以正常收敛,说明应该不是写错代码的原因,但是当我把新闻种类扩大到14种类别时,却出现了loss不下降的情况:
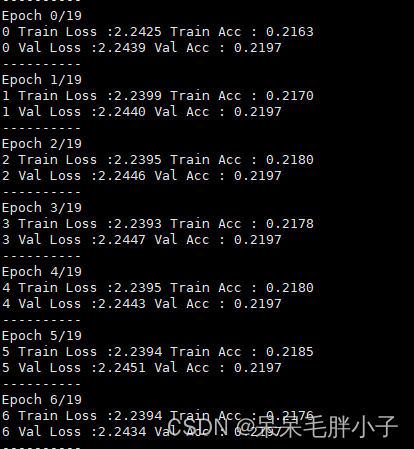

因为不知道是什么原因,所以希望能探究一下。
; 一、改变权重初始化方案
之前是让LSTM默认初始化,现在采用RNN常用的正交初始化,据说可以缓解梯度消失和梯度爆炸问题。
方法:
在初始化代码中加入:
nn.init.orthogonal_(self.lstm.weight_ih_l0)
nn.init.orthogonal_(self.lstm.weight_hh_l0)
结果
没有改善。
二、改变输入文本的最大长度
输入文本的长度直接影响到模型参数的多少,模型参数越多越难训练,可能会导致loss不下降的情况。
方法
之前分词后的文本截断到了500个词,此次把文本的长度截断到了50个。
结果
loss正常下降,且收敛速度很快,七个epoch之后在验证集上的准确率达到最高,为94.71%。
如果是用于短文本分类,减少文本的最大长度能够很好的改善loss不下降的问题,而且训练速度能够大大加快。
但是我最终要用LSTM去做长文本的分类,因此还需要找到其他的方法。
三、学习率的调整
一般来讲,学习率的调整是操作起来最简单,但是也可能是最麻烦的一件事情。我之前有过调了调学习率就让模型从不收敛到收敛的经历,但是这次并没有什么效果。
方法
调整学习率,在[0.0003,1]中不断尝试。学习率过大会直接导致loss飙升到200以上,在一定区间上调小学习率能降低loss,但是继续调小学习率loss无法继续下降了。折腾了半天,发现最佳的初始学习率是默认的0.001左右,但之后无论怎么调整都无法使loss按照正常状况下降了。
结果
没有改善。
四、文本长度的降维
我大概知道是因为模型的参数过多所以难以训练了,这样我们或许能通过对文本的长度进行降维来改善这种状况。降维我最先想到的是通过池化的方式,但是直接进行池化会丢失掉很多的信息,所以我在宽度为10的最大池化前面又加入了一层宽度为3的卷积层,这样增强了模型对局部特征的提取能力。
模型代码如下
class MergeNet2(nn.Module):
def __init__(self,vocab_size,pkernel_size,embedding_dim,kernel_size,hidden_dim,layer_dim,output_dim):
"""
:param vocab_size: 词典长度
:param pkernel_size: 池化层kernel宽度
:param embedding_dim: 词向量维度
:param kernel_size: 卷积池kernel宽度
:param hidden_dim: LSTM神经元的个数
:param layer_dim: LSTM层数
:param output_dim: 隐藏层的输出维度(分类的数量)
"""
super(MergeNet2,self).__init__()
self.embedding = nn.Embedding(vocab_size,embedding_dim)
self.conv = nn.Sequential(
nn.Conv1d(in_channels=embedding_dim,
out_channels=embedding_dim,
kernel_size=kernel_size),
nn.BatchNorm1d(embedding_dim),
nn.ReLU(inplace=True),
nn.MaxPool1d(kernel_size=(pkernel_size))
)
self.lstm = nn.LSTM(embedding_dim,hidden_dim,layer_dim,batch_first=True)
self.fc1 = nn.Linear(hidden_dim,output_dim)
def forward(self,x):
embeds = self.embedding(x)
embeds = embeds.permute(0, 2, 1)
conved = self.conv(embeds)
conved = conved.permute(0, 2, 1)
r_out,(h_n,h_c) = self.lstm(conved,None)
out = self.fc1(r_out[:,-1,:])
return out
结果
loss正常下降,九个epoch之后在验证集上的准确率达到最高,为94.95%。
总结
改进后模型显然已经不是一个纯粹的LSTM模型了,而是一个卷积和LSTM相结合的模型。对于长文本的输入,无论有多么长(我最多试过3000个词,这个时候的池化层宽度为20),只要合理调整池化层和卷积层的参数都能够使loss正常下降。比起单一的LSTM模型,改进后的模型对文本长度的限制更小,从而能更全面地提取长文本的特征,理论上比单一LSTM模型具有更好的准确率。
当然,本文的初衷并不是做模型的融合来提高准确率,或许在LSTM之前采用多层卷积并联或串联的方式能够得到更好的模型,但也要小心过拟合的问题。
Original: https://blog.csdn.net/qq_50700819/article/details/124525170
Author: 树影蛙
Title: LSTM在多分类中出现的loss不下降问题(pytorch实现)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/707548/
转载文章受原作者版权保护。转载请注明原作者出处!