

内容涉及excel和SPSS
- 数据分析的分类
* - 数据分析流程
- 数据采集
- 数据分析职位
- 自定义单元格格式
- 数据分列
- 数据提取
- 数据合并
- 数据表格的规范化
- 一些常用函数
- 删除重复值
- 判断错误值
- 相同字段查找匹配
- 保护工作表和工作簿
- 高级筛选
- 条件格式
- 数据透视表
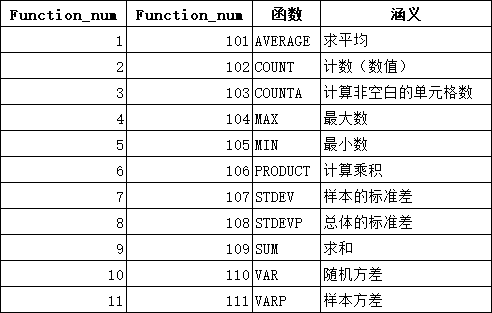
- 三组9个常用统计函数
- 筛选与隐藏状态下的数据统计
- 计算最值与排序
- 身份证
- 数据分析
- 数据呈现
- 数据分析报告
课件:链接:https://pan.baidu.com/s/1RgRm0d24okUkWudKEQ7Q2g
提取码:gntv
数据分析的分类
在统计学邻域,数据分为三类:
描述性统计分析对一组数据的各种基本特征进行分析,便于描述测量样本的各种特征,常用的方法包括对比分析、平均分析、交叉分析等,是复杂统计的基础探索性数据分析利用一定的分析方法返现数据中的隐藏特征规律,常用的分析方法包括相关分析、因子分析、回归分析、预测分析等,是一种高阶数据分析验证性数据分析利用分析方法验证假设的真伪准确性,比如顾客忠诚度,假设需要用购买频率、消费比例等指标来衡量,那么验证数据分析就是检验购买频率、消费比例等是否能反映出来
数据分析流程
确认分析目的明确分析思路数据采集数据输入数据整理数据处理数据分析数据呈现数据分析报告
数据采集
数据采集方式
公开出版物
中国统计年鉴、中国社会统计年鉴、中国人口统计年鉴、世界经济年鉴、世界发展报告
互联网
国家地方统计局网站、行业组织网站、政府机构网站、门户网站、企业网站、上市公司财报
数据库
市场调查
线下调查:电话、街头、座谈、轨迹
线上调查:线上调查问卷
数据分析职位
数据分析师需要懂管理、业务、心理学,与有关部门结合
自定义单元格格式
原始数据单元格显示数据自定义格式代码123一百二十三[DBNum1]123查佰贰拾叁[DBNum2]123123.00#0. 00123123.0#0.012. 2312. 23%0.00%1234561, 235#,##01234567890人民币1, 235百万”人民币”#,##0,”百万”河南中国移动河南分公司”中国移动”@”分公司”91优秀[>90]”优秀”;[>80]”及格”;”不及格”5959[>90][红色]0;[>80][绿色]0;[黄色]0
自定义单元格与TEXT函数使用:text(value,format_text)
value:数字值
format_text:设置所要的文本格式
举例:=text(b2,”[>=90] 优秀;[>=60] 及格;差”)
数据分列
LENB 与LEN 函数
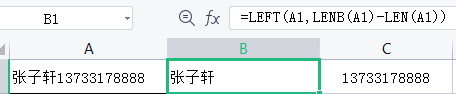
当姓名和电话号码都没有规律时,我们可以使用LENB 和LEN 函数,如图所示。
姓名公式=LEFT(A1,LENB(A1)-LEN(A1)),其中LENB(A1)代表A1单元格的字节总数
( 15),而LEN(A1)代表A1单元格的字符总数(12)。一个汉字是一个字符但是有两个字节,
所以LENB(A1)-LEN(A1)=15-12=3代表A1单元格的姓名汉字个数为3个。
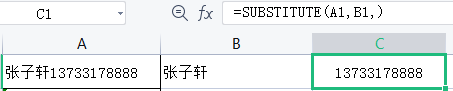
电话号码公式=SUBSTiTute(A1,B1,),即把A1单元格中 B1的部分替换为空。
MIDB、SEARCHB、LENB函数
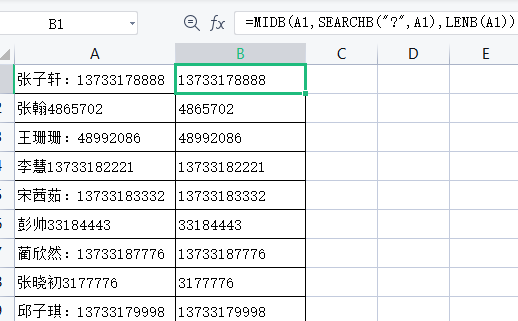
当姓名和电话号码没有规律,且姓名和电话号码中间还有不确定的其他字符时,就需要用MIDB+SEARCHB+LENB组合函数来实现,如图
电话号码公式= MIDB(A1,SEARCHB(“?”,A1),LENB(A1))
利用SEARCHB函数配合通配符”?”查找字符串中第1个半角字符的位置编号,再用MIDB函数提取电话号码。其中,姓名和电话号码中如果出现了全角的”:”,则也不会影响计算结果。
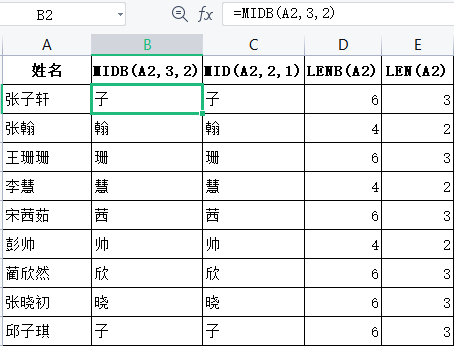
MIDB、SEARCHB、LENB这些带B的函数和MID、SEARCH、LEN这些不带B的函数的区别在哪里呢?
MIDB、 SEARCHB、 LENB函数会将每个双字节字符按2计数,而MID、SEARCH、 LEN函数会将每个字符按1计数,如下图所示。
; 数据提取
一列变多列
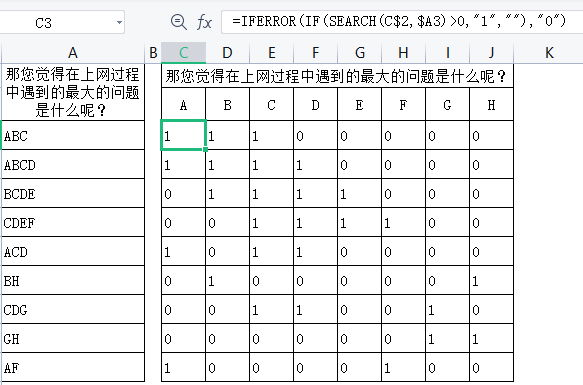
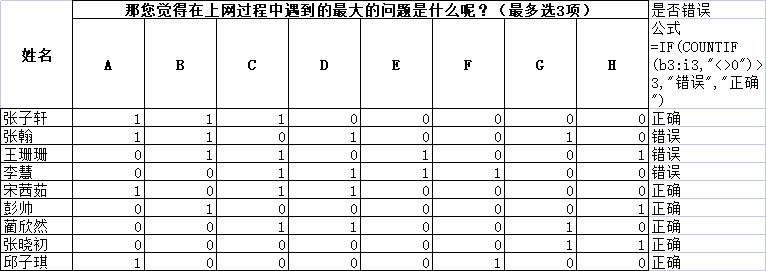
有一道多选题,共有A、B、C、 D、E、F、G、H这8个答案,由于没有采用二分法或
多重分类法录入,录入结果如左图中的A列所示,给数据处理和分析带来了不便。现需
进行数据整理,将A列转换为A、B、C、D、E、F、 G、H分别对应的8列,如果A列中出
现了答案,则在对应答案下方显示”1″;如果没有出现,则显示”0″。整理后的结果与二分
法录入的结果一致,如右图的C~J列所示。
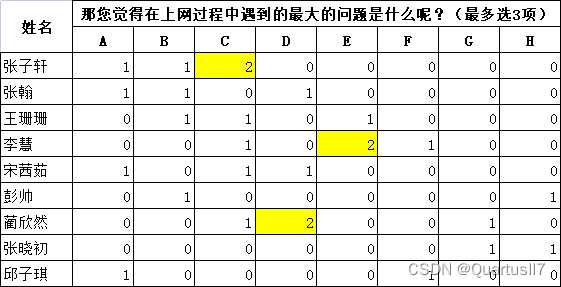
公式=IFERROR(IF(SEARCH(C$2,$A3)>0,"1",""),"0")
首先search函数:指定字符串在原始字符串中首次出现的位置:search(要查找的文本,在哪里查找,从第几个字符开始查找(可忽略))
if函数判断,有输出1,没有为错误值
iferror函数将错误值转换为”0″:iferror(被检查的值,被检查的值为错误时返回值)
提取不规则数据最后一部分内容
index语法:https://www.wps.cn/learning/course/detail/id/116.html?chan=pc_win_function
提取部分内容,保留部分内容
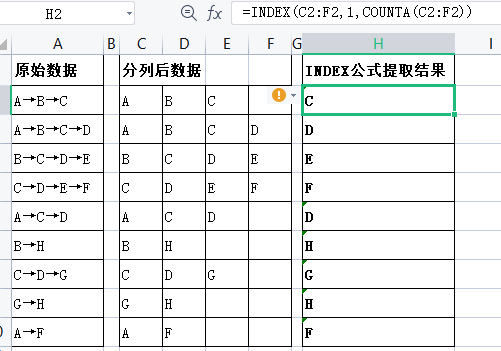
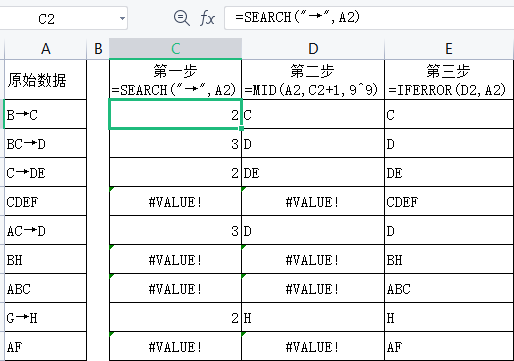
现有一列数据, 如果有箭头,则提取箭头后面的内容(箭头前后的字符长度不固定);如果没有箭头,则保留原内容; 如果单元格为空白,则保留空白,如图所示。
第一步,利用C2=SEARCH(“→”,A2)查找”→”为单元格的第几个字符。
第二步,利用D2=MID(A2,C2+1,9^9)将”→”后面的内容提取出来。
第三步,使用IFERROR函数将错误值转换为A列对应的单元格。
公式: =IFERROR(MID(A2,SEARCH(“→”,A2)+1,9^9),A2)
语法
MID(text,start_num,num_chars)
Text 是包含要提取字符的文本字符串。
Start_num 是文本中要提取的第一个字符的位置。文本中第一个字符的 start_num 为 1,以此类推。
Num_chars 指定希望 MID 从文本中返回字符的个数。
说明
■ 如果 start_num 大于文本长度,则 MID 返回空文本 ()。
■ 如果 start_num 小于文本长度,但 start_num 加上 num_chars 超过了文本的长度,则 MID 只返回至多直到文本末尾的字符。
■ 如果 start_num 小于 1,则 MID 返回错误值 #VALUE!。
■ 如果 num_chars 是负数,则 MID 返回错误值 #VALUE!。
数据合并

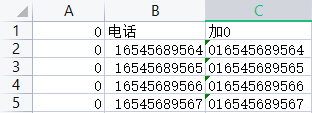
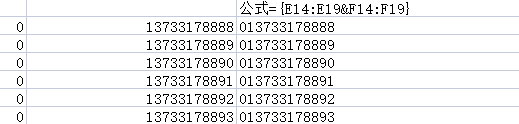
公式=E14:E19&F14:F19,按下shift+ctrl+enter组合键
符合条件的合并为一个单元格
符合条件单元格对应内容合并
现有一组学员成绩,需要将每个学员成绩为空白的科目统计出来,并用”、”隔开。首先,根据要求,利用IF函数,如果单元格为空格,则输出结果为科目名称十”、”;如果单元格不为空格,则输出结果为空值,所有F函数计算出来的结果用CONCATENATE函数合并。
在K2单元格中输入公式”= CONCATENATE(IF(B2=””,B$1&”、”iFIC2=”.C$1&、”,IF(D2=”,D$1&’、”),IF(E2=”),E$1&”、”,IF(F2=”F$1&、”,F(G2=”,G$1&”、””),
IF(H2=”,H$1&’、””.IF(12=”1$1&、”).IF(U2=”J$1&、””,。完成缺考科目的合并。
然后left(k2,len(k2)-1)
1.下拉菜单:
步骤:(1)选择I1:I2单元格区域定义名称”上网”,选择i3:i10单元格区域-右键-【定义名称】-输入”不上网”(2)选择c2:c10,【数据验证】(wps中数据-有效性)-【允许】-【序列】,在【来源】数据框中输入公式=indirect($a2),确定.。选择D2:D10,【数据验证】-【允许】-【序列】在【来源】数据框中输入公式=indirect($B2),确定。(3)C、D列可以根据A\B列的结果选择
2.身份证号:
选择区域-【数据】-【数据验证】-【验证条件】-【自定义】,在【公式】数值中输入公式=or(len(A2)=15,len(A2)=18),确定。
3.重复输入限制:
选择区域-【数据】-【数据验证】-【验证条件】-【自定义】,在【公式】数值中输入公式countif($a$2:$a$10,a2)=1,确定。



; 数据表格的规范化
1.二维表转换一维表
数据表一维形式最好,二维表需转换一维表
一维表:每一列是一个独立的参数,横向一个维度
二维表:每一列同类参数,横向纵向两个维度。
excel逆透视:二维->一维
数据-获取和转换-从表格-创建表-确定-选中最左列-单击-转换-逆透视其他列-单击开始-关闭并上载,完成。
使用WPS插入数据透视里多重合并计算区域,在形成的表格中,找到最后一个单元格,然后双击就可以将二维数据变成一维2.超级表:用的不多,自行百度
3.单元格规范化
1)自动换行
2)alt+enter,单击单元格,光标放在需要换行的地方
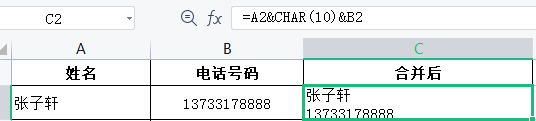
3)=A2&CHAR(10)&B2,CHAR(10)为换行符,公式完成后再单击【自动换行】 即可。外部数据导入会遇到单元格内容多行显示,这是需要这样:选择数据区域-【替换】-在【查找内容】-按住alt,小键盘输入10(显示的不是10,而是一个小点)-【替换】中不输入内容-单击【全部替换】-关闭-自动换行
一些常用函数
; 删除重复值
1.删除重复项
2.条件格式-重复值
3.高级筛选
操作步骤:选择需要除重的数据区域,[数据]-[高级筛选]-[将筛选结果复制到其
他位置」-[复制到]数值框中选择C1-勾选[选择不重复的记录],新得
到的数据即为不重复的数据。采用高级筛选最大的好处就是原始数据也保留下来。
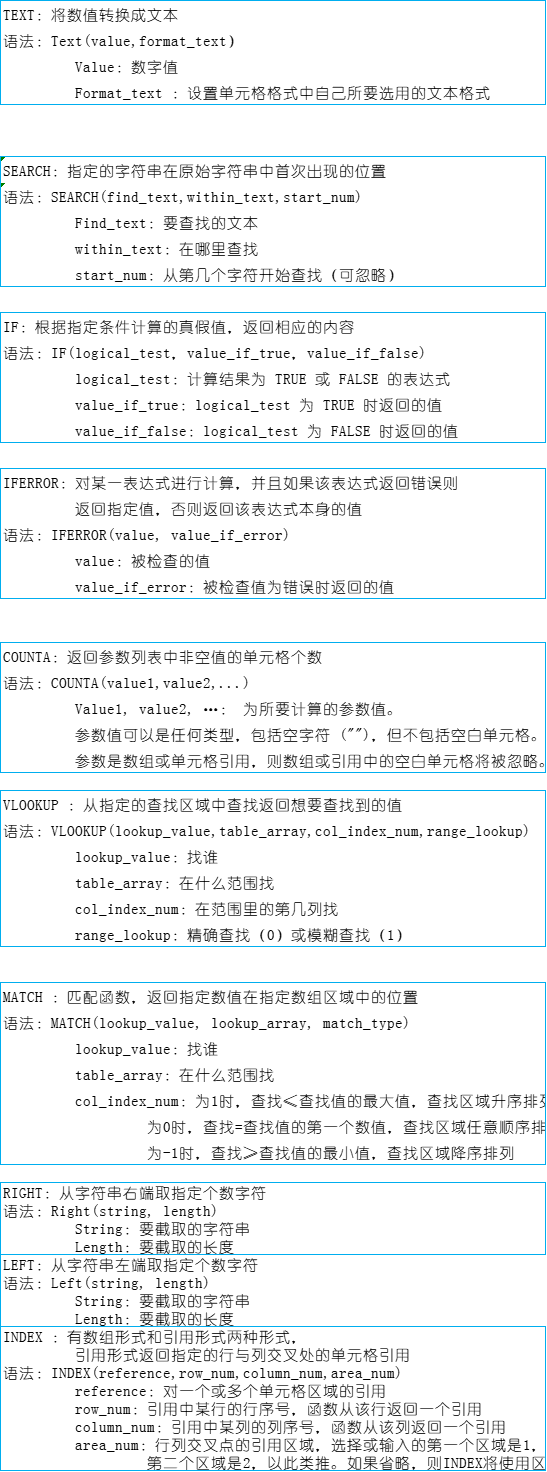
4.countif 函数
结果为1的第一次出现,2的第二次出现,3第三次出现
5.数据透视表
判断错误值
1.数据类型错误
f5健-定位条件-文本,可以找出数值型数据中文本数据
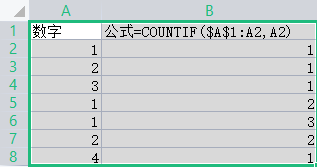
2.录入选项不符合要求
公式; =IF(COUNTIF(B3:l3,”<>0″)>3,”错误””正确”)
3.录入数值错误
录入数值错误在数据分析中十分常见。例如,采用多重分类法录入只有7个选项的多选题,录入代码为1-7, 录入结果中却出现了1~ 7以外的数字;采用二分法录入时只有0和1两个数字,录入结果中却出现了2、 3等数字。这时候我们就需要利用条件格式来检验是否存在逻辑错误的情况。
操作步骤:选择B3:i11单元格区域,[开始]-[条件格式]-[新建规则]-[使用公式确定要设置格式的单元格]- [为符合此公式的值设置格式]数值框中输入”=OR(B3=1,B3=0)=FALSE” (公式的含义是:当函数的任意- -个参 数为真时,返回TRUE ;否则返回false),修改【格式】中的填充颜色,确定完成。
; 相同字段查找匹配
1.VLOOKUP
VLOOKUP(
vlookup_value:找谁
table_array:在什么范围找
col_index_num:在范围的第几列找
range_lookup:0,1
)
函数的第三个参数是查找区域的第几列,函数的第四个参数为0或者false,为精确查找。当存在多条满足条件的记录时,vlookup函数只能返回第一条满足条件的记录。
2.vlookup函数进阶
(1)多列查找快速输入公式
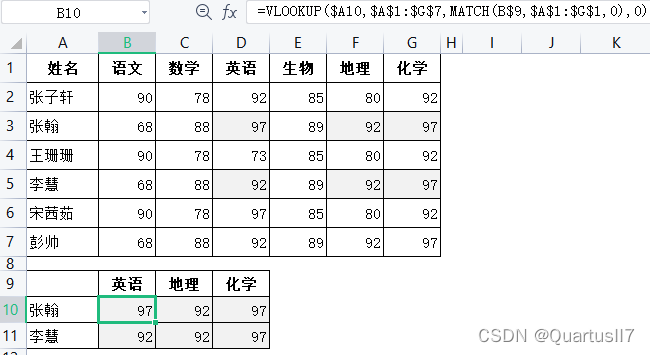
在进行多列查找时,查找区域为整个成绩区域;公式为=VLOOKUP($A10,$A$1:$G$7, ?,0),最重要的是要修改第3个参数的值,因为列在变化,第3个参数也在发生变化。
以”姓名”列为起始列,即第1列,”英语”在”姓名”后的第4列,那么第3个参数
应该是4,公式为=VLOOKUP($A10,$A$1:$G$7.4.0);”地理”在”姓名”后的第6列,
那么第3个参数应该是6,公式为=VLOOKUP($A10,$A$1:$G$7,6,0)。
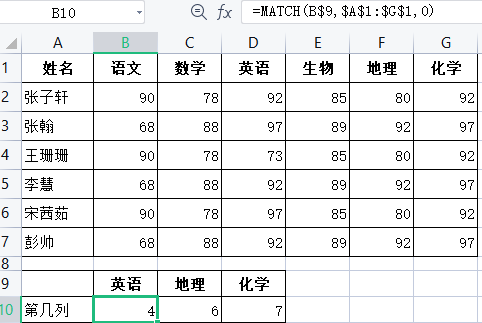
我们可以将第几列用其他函数的计算结果来实现,
4=MATCH(B$9,$A$1:$G$1,0);6=MATCHIC$9,$A$1:$G$1,0)以此类推,在B10单元格中输入最终公式”=VLOOKUP($A10,$A$1:$G$7, MATCH(B$9,$A$1:$G$1,0),0)“,分别向右和向下拖动公式,完成单元格匹配工作,如图$美元符号:
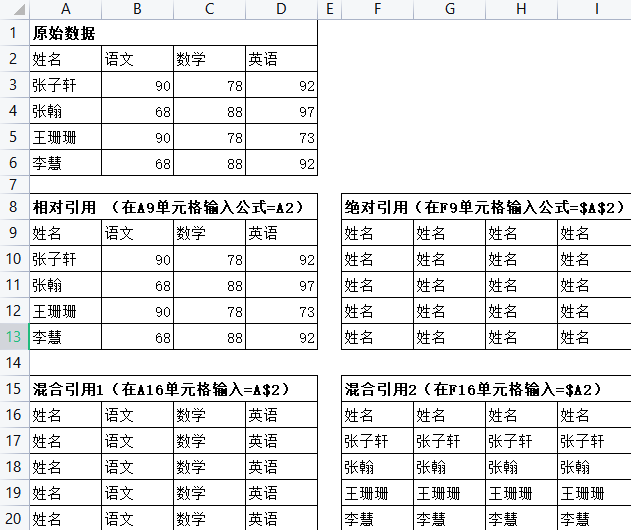
我们可以看出,相对引用没有 $ 符号,直接对单元格进行引用,当拖动单元格复制公式时,行号和列号均发生变化:而绝对引用有两个”$”符号,将行和列完全锁定,不管拖动到什么位置,引用的都是A2单元格,不会发生任何变化;混合引用A$2和 $A2 分别锁定行和列,不管拖动到什么位置,引用的行或者列不会发生变化,但是列或者行会随着拖动而改变。在编辑公式的过程中,直接单击单元格是相对引用,单击后按F4键则修改为绝对引用, 重复按F4键将依次在行绝对引用、列绝对引用、相对引用、绝对引用之间进行切换。
例如,引用A2,重复按F4键,A2 则依次改变为 $A$2、A$2、 $A2、A2。(2)vlookup数值区间模糊查找
数值模糊查找时,注意引用的数字区域必须由小到大排列,输出结果是和查找值最接近但比他小的那个值。
(3)使用通配符精确查找
vlookup函数的第一个参数支持通配符,使用通配符后相当于确定了查找条件,可以实现精确查找,查找结果也是返回首次满足条件的记录的相应值。
在E2单元格中输入公式=vlookup("*"&D2&"*",$A:$B,2,0)。查找结果如图(3)vlookup函数高级用法
1)从右往左查找
3. VLOOKUP函数高级用法
1)从右往左查找
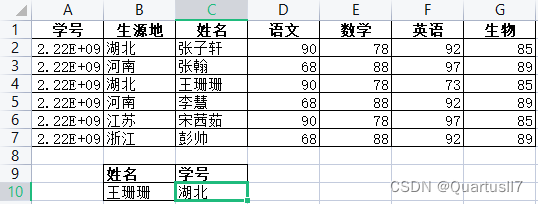
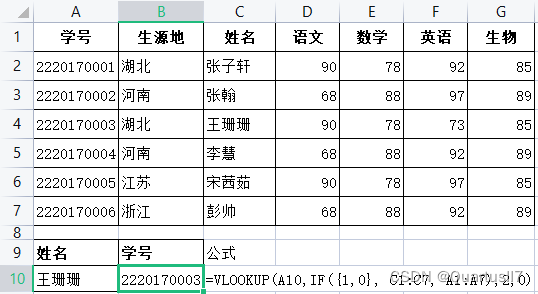
因为VLOOKUP函数的第3个参数必须为正数,所以从函数本身来理解只能实现从左往右的查找,于是很多人在遇到反向查找问题(从右往左查找)时,总是习惯粘贴复制调换位置。这当然是方法之一。还有一种方法是借用 INDEX+MATCH 函数实现,非常简单、方便。如需要根据学生姓名查找学生的生源地,在C10单元格中输入公式”=INDEX(B2:B7,MATCH(B10,C2:C7,0))”,
但是既然说到VLOOKUP函数,那我们就用VLOOKUP函数来实现反向查找。首先需要利用IF函数将B列和C列互换。公式:=lF({1,0},C1:C7, B1:B7)公式解读:这是一个数组公式,1相当于 TRUE, 0相当于 FALSE。当为1时,返回IF函数的第2个参数(C1:C7);当为0时,返回IF函数的第3个参数(B1:B7)B列和C列实现互换后,再直接使用VLOOKUP函数就可以实现反向查找。在 B10单元格中输入公式”=VLOOKUP(A10,iF({1,0}, C1:C7,B1:B7),2,0)”。
案例中两列是相邻的,如果是跨列查找,那该如何处理呢?还是同样的办法,先利用IF函数实现两列(查找值所在的列和需要匹配的值所在的列)位置互换,然后再利用VLOOKUP函数进行查找。需要注意的是,第3个参数查找列依旧为2,因为IF函数构建的是一张两列的数据表。如上图所示。
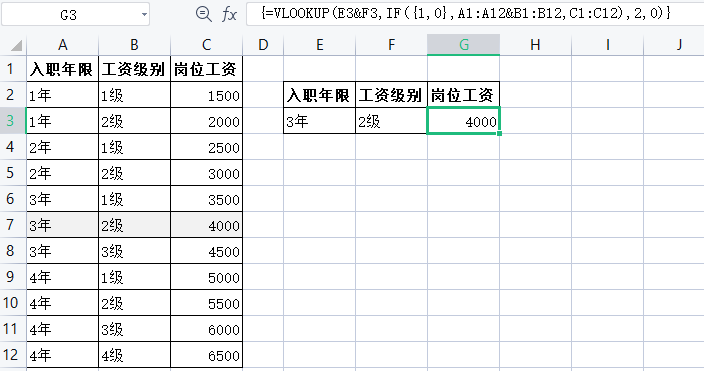
2)多条件查找
在有多个条件的情况下,我们通常需要将多个条件先合并,再利用IF函数第1个参数的数组特征重构原始数据。
在G3单元格中输入公式”=VLOOKUP(E3&F3,iF({1,0},A1:A12&B1:B12,C1:C12),2,0)”。其中,E3&F3:将多个条件合并; iF({1,0},A1:A12&B1:B12,C1:C12):利用IF函数第1个参数的数组特征,将多个条件合并后的内容与查询的列结合起来,组成新的两列数据。
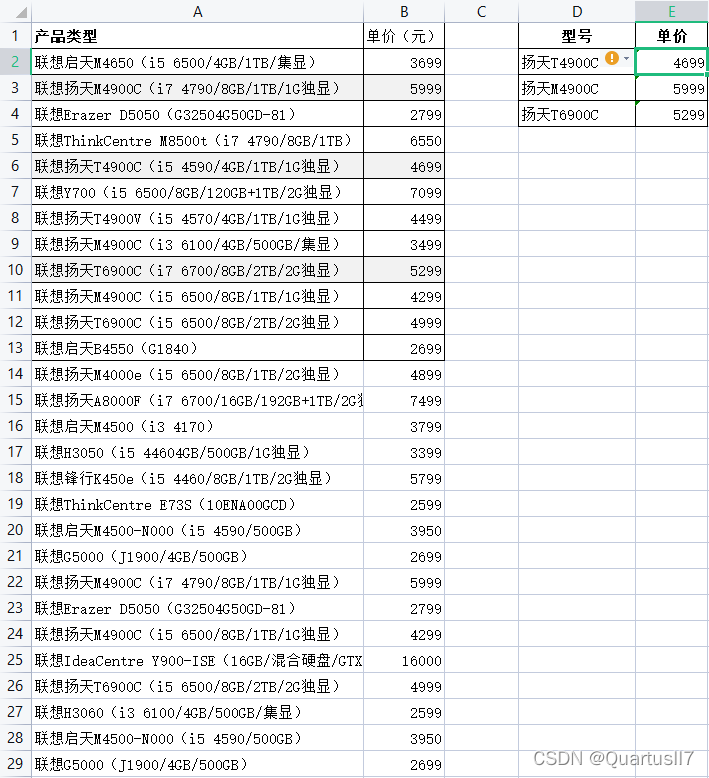
3)在合并单元格内进行查找
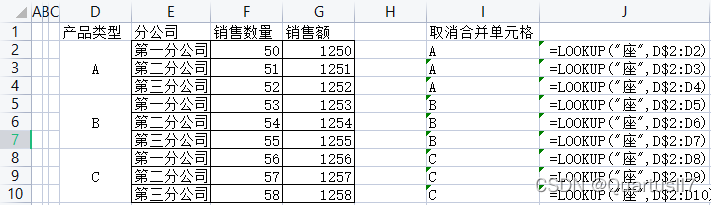
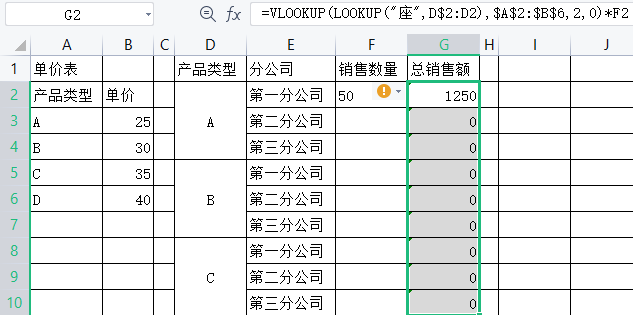
前面我们强调过,尽量避免在 Excel中进行单元格合并,但是在工作中我们还是会含有合并单元格的数据表。现有公司产品单价表及各分公司销售数据,需要根据左侧单价和各产品类型各分公司销售数量计算出总销售额。因为第2张表中”产品类型”被设置成了合并单元格,除每个合并区域的第1个单元格有数值外,其余均为空,因此无法直接在公司产品单价表中查找对应品种的单价。首先使用公式填充合并单元格中的空单元格,如图
在12单元格中输入公式”=LOOKUP(“座”,D$2:D2)”。
该公式为LOOKUP函数的特殊用法,在从 D2单元格开始不断向下扩大范围的单元格区域中查找”座”字,当找不到”座”字时,则返回区域中最后一个非空单元格名称,即对应的产品类型。
解释说明:由于LOOKUP函数查找汉字是按照汉语拼音的顺序来进行的,座(拼音zuo )是拼音中的最后一个,所以用”座”可以查找区域中最后一个单元格内容;同理,换为其他字符代码较大的汉字也可以查找。

保护工作表和工作簿
1.保护工作表
(1)打开【设置单元格格式】对话框,在【保护】选项卡中取消勾选【锁定】(2)按F5健定位”常量”单元格,按住CTRL选择需要的单元格区域,即可全选需要锁定的区域(3)打开【设置单元格格式】,在【保护】中勾选【锁定】后点击【确定】(4)【审阅】–【保护工作表】,勾选【选的锁定单元格】【选定未锁定的单元格,】输入密码(可不输),完成。
隐藏公式:第(3)步后勾选【隐藏】2.保护工作簿
保护工作表是针对工作表内容的保护,限制对工作表内容进行修改、复制、删除等操作 而保护工作簿是限制删除或增加工作表数量、修改工作表名称、隐藏工作表等。Excel|提供了两种保护工作簿的方式。
1)保护工作簿结构和窗口
操作步骤:[审阅)-[保护工作簿]-[保护结构和窗口]-勾选[结构]复选框,这样对工作簿就不能执行添加、移动、删除工作表、隐藏、重命名等操作了;如果同时勾选[窗口】复选框,则工作簿所在的窗口就无法移动和调整大小了。
2)用密码加密
【文件】–【保护工作簿】–【用密码进行加密】
高级筛选
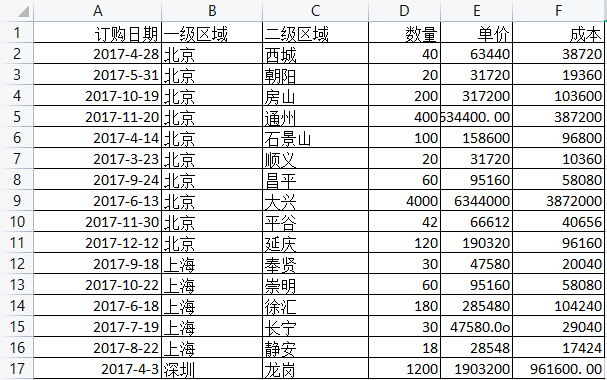
1.单个条件筛选:把4月份销售数据筛选出来
设置条件区域:订单日期
; 条件格式
1.满足条件的单元格突出显示
(1)包含关键字的单元格突出显示
操作步骤:选择区域–开始–条件格式–突出显示单元格规则–文本中包含–为包含以下文本的单元格设置格式–输入”关键字”
(2)前30%的单元格突出显示
操作步骤:选择区域–开始–条件格式–最前/最后规则–前10%–为值最大的那些单元格设置格式–数值框中将10%修改为30%,设置填充颜色
(3)重复值和唯一值突出显示
操作步骤:选择区域–开始–条件格式–突出显示单元格规则–重复值–为包含以下文本的单元格设置格式–重复/唯一,设置填充颜色
(4)空白单元格突出显示
操作步骤:选择区域–开始–条件格式–突出显示单元格规则–其他规则–只为满足以下条件的单元格设置格式–空值,设置填充颜色
(4)最大最小值突出显示
操作步骤:选择区域–开始–条件格式–最前/最后规则–前10项/最后10项–为值最大的那些单元格设置格式,设置填充颜色2.数据图形化、可视化
(1)数据条长度展现数据大小
(2)用两种颜色数据条正负:选择区域–条件格式–数据条–其他规则–设置正值填充颜色–单击负值和坐标轴设置–颜色和坐标轴的设置
(3)变化颜色展现数据分布:选择区域–色阶
(4)用 图标集 表示数据3.用自定义条件实现复杂条件的设置
(1)实现整行记录标识
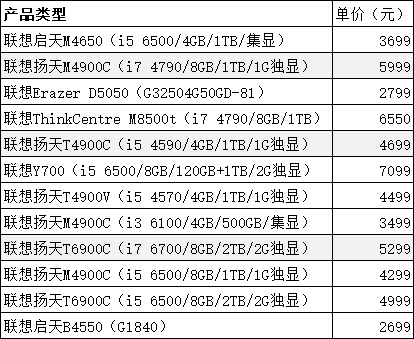
目的:找到产品类型中”联想扬天T4900C(i5 4590/4GB/1TB/1G独显)”的记录,并且标识。
选择区域–开始–条件格式–新建规则–使用公式确定要设置格式的单元格–为符合此公式的值设置格式–在文本框中输入=$A1="联想扬天T4900C(i5 4590/4GB/1TB/1G独显)"
(2)实现隔行记录标识
选择区域–开始–条件格式–新建规则–使用公式确定要设置格式的单元格–为符合此公式的值设置格式–在文本框中输入=(mod(row(),2)=1)*(A1<>""),mod(row(),2)=1代表奇数行,A1<>””代表单元格不能空值(3)满足多个条件的记录整行标识
目的:找出单价大于5000,销量大于300的整行标识
选择除标题行外的所有数据区域,–开始–条件格式–新建规则–使用公式确定要设置格式的单元格–为符合此公式的值设置格式–在文本框中输入=($B2>=5000)*($C2>=300),号代表两个条件同时满足。
(4)关键词匹配
目的:找出产品类型中包含联想的整条记录
选择除标题行外的所有数据区域,–开始–条件格式–新建规则–使用公式确定要设置格式的单元格–为符合此公式的值设置格式–在文本框中输入=find("联想",$A1),号代表两个条件同时满足。
数据透视表
注意:对数值排序的时候,选中任意一个可排序的单元格,单击鼠标右键–排序–降序,不要选择透视表
【设计】-【报表布局】-【以表格形式显示】
值显示方式:
单击鼠标右键-【值显示方式】-【列汇总的百分比】:各列的每行数据占所有行数据的百分比
单击鼠标右键-【值显示方式】-【行汇总的百分比】:和行相反
【数据透视表工具】-【分析】-【插入切片器】-选择筛选字段
三组9个常用统计函数
求和:sum、sumif、sumifs
计数:count、countif、COUNTIFS
平均:AVERAGE、AVERAGEIF、AVERAGEIFS
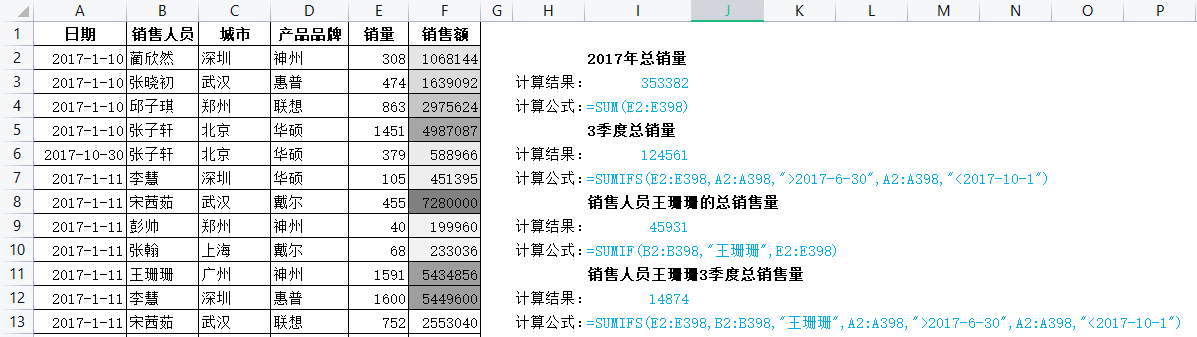
2.countif函数:两列数据核对
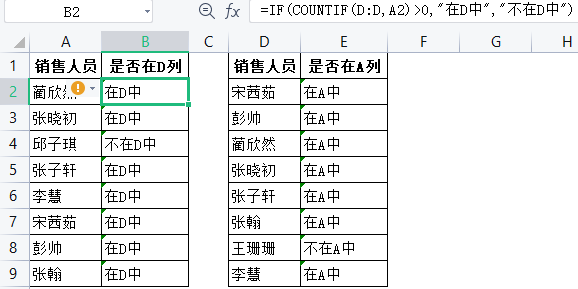
2)帮助vlookup函数实现一对多查找:
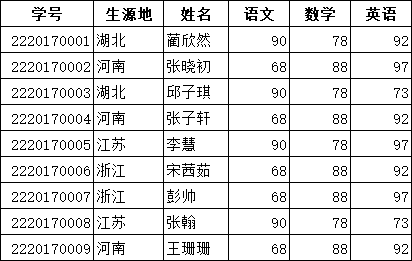
现有一份学生成绩单,现需要在I4:N9区域根据I2生源地查找所有记录,构造辅助列A列,在A2单元格中输入公式
=countif(c$2:c2,c2)&c2,用countif函数将生源地出现次数和生源地联系起来,形成序号+生源地的形式,在i5单元格中输入公式 =iferror(vlookup(row(a1)&$i$2,$a:$g,column(b1),0),""),横向纵向单元格填充,完成。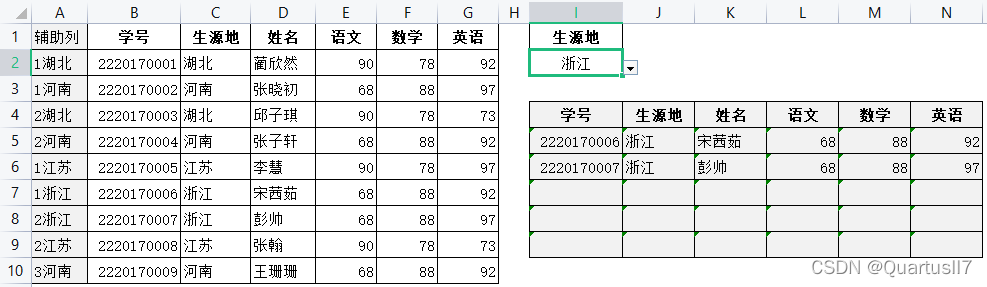
3)中国式排名
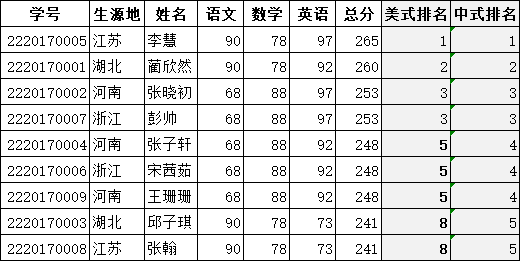
在h2单元格输入:
=rank(g2,$g$2:$g$10),美式排名在i2单元格输入公式
=sumproduct(($g$2:$g$10>g2)*(1/(countif($g$2:$g$10,$g$2:$g$10))))+1,中国排名,利用countif统计不重复值得计数原理,实现踢出重复之后的排名;i2单元格输入公式方法二: =SUM(--IF($G$2:$G$10>=G2,MATCH($G$2:$G$10,$G$2:$G$10,)=ROW($2:$10)-1)),按下组合键。
; 筛选与隐藏状态下的数据统计
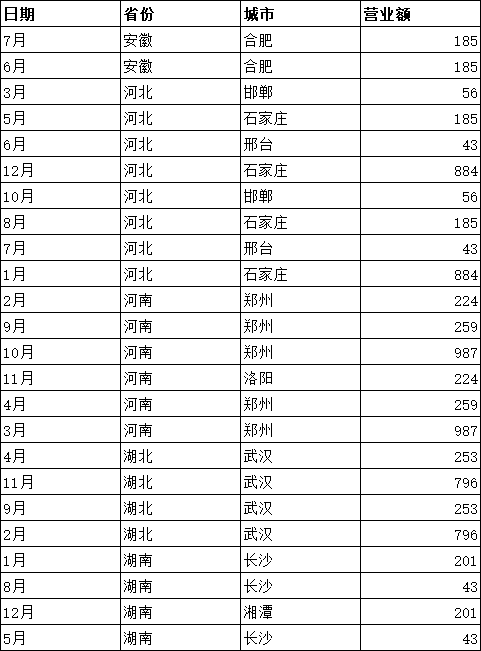
1)subtotal函数可以忽略被筛选的和隐藏的行,函数结果会随着筛选结果的变化而变化。
subtotal函数用法:subtotal(function_num,ref1,···),function_num代表不同的函数,对于筛选模式下,不再统计这部分行数据。对于手动隐藏的行,1-11表示统计隐藏的行,101-111表示不统计隐藏的行。
subtotal是一组函数,用来对列表或数据库进行分类汇总。
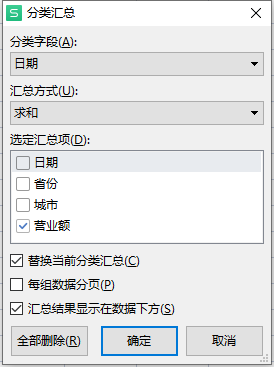
2)subtotal函数实现分类汇总
【数据】-【分类汇总】
计算最值与排序
MAX、MIN、LARGE、SMALL
1.在浮动分值有上下限的条件下计算得分
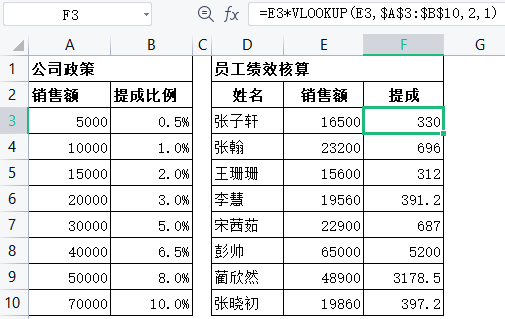
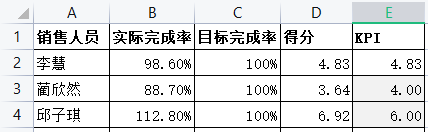
现有一组销售人员业务完成率的数据,需要根据公司政策来计算各销售人员销售KPl。公司政策:基准分5分,完成率每超过目标1%加0.15分,每相差1%减0.12分。销售KPI最高得6分,最低得4分。
计算方式:①利用IF函数根据目标完成率和实际完成率的差值计算销售得分,在D2单元格中输入公式”=IF(B2>=C2,5+(B2-C2/1% 0.15,5+(B2-C21/19% 0.12)” ;②利用MAX 和MIN函数的特点,在E2单元格中输入公式”=MAX(MIN(D2,6).4)”, 即可完成销售KPI 的测算,如图所示。

2.计算前三名总销售额
现有一组销售数据,需要计算前三名销售人员的总销售额。
计算方法:在D3单元格中输入公式”
=SUMIL ARGE(B2:B10,{1,2,3})",按Ctrl+Shift+Enter组合键结束运算,如图所示。其中,LARGE(B2:B10,{1,2,3})表示在数据区域B2:B10中找出排名第一、第二、 第三的3个数字。
3.按条件排序
现有一组销售数据,需要将大于100的销售额降序排序,其余数据不显示。
计算方法:①在C2单元格中输入公式”=
L ARGE(IF($B$2:$B$10> 100,$B$2:$B$10),ROWIA1)“,按Ctrl+Shift+Enter组合键结束运算;②在D2单元格中输入公式”=IFERROR (C2,””),屏蔽C列中的错误值,如图所示。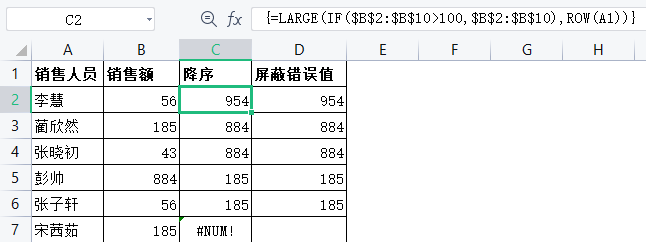
4.一对多查找
在4.4节中我们掌握了COUNTIF函数帮助VL OOKUP函数实现一对多查找的方法, 这里我们学习如何使用INDEX和SMALL函数嵌套来完成一对多查找。
现有一组生源地和学生姓名数据,需要根据提供的生源地提取学生名单。
计算方式:在D5单元格中输入公式”
=INDEX($B:$B, SMALL(IF($A$2:$A$10=$D$2,RO W($A$2:$A$10),4"8),COLUM1I))&*"",按Ctrl+Shift+Enter组合键结束运算。向右拖动公式即可完成同一生源地学生名单的查找,如图4.85所示。其中,利用SMALL函数来定位所有D2在第一列的位置,COLUMN(A1) 用来显示第几个D2,这样在拖动D5单元格的填充柄往右填充公式时,在D5时为COLUMN(A1)即1,第一个D2;在E5时为COL UMN(B1)即2,第二个D2;以此类推。在这个公式末尾添加&”,是为了实现公式在向右拖动的过程中,如果没有匹配值,就用空格代替。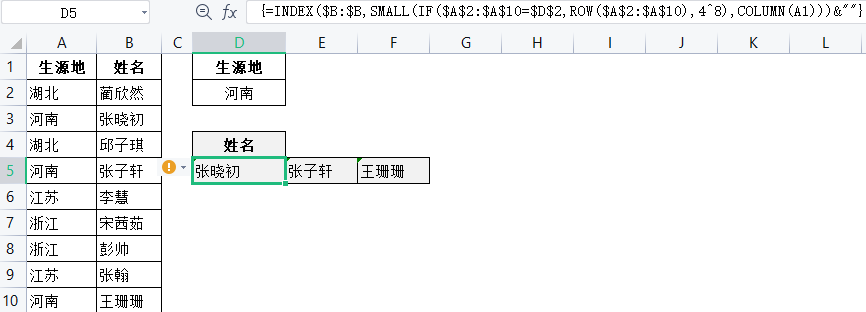
; 身份证
一个18位数的身份证号码,
隐藏着我们每个人的很多秘密。
1.出生日期
每个人的出生日期都是身份证号码中从第7位开始的8位数字。提取出生日期需要
利用DATE 函数。计算方法:在C2单元格中输入公式”=DATEIMID(B2,7.4),MIDIB2,11,2),MIDIB2.13.2)”,
其中,MID(B2,7.4)为年份, MID(B211,2)为月份,MID[B2,132)为日。结果如图所示。
工龄月份 =DATEDIF(D3,”2021/12/31″,”M”)

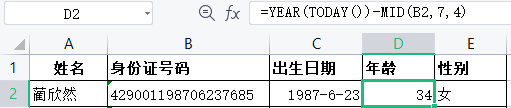
2.年龄
当前年份减去出生年份就是我们每个人的年龄。
计算方法:在D2单元格中输入公式”=YEAR(TODAY()-MIDA2,7,4)”。或者=YEAR(NOW())-MID(I3,7,4)结果如图
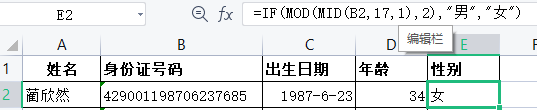
3.性别
我们每个人的18位身份证号码中第17位是判断性别的数字,奇数代表男性,偶数代表女性。
首先利用MID函数将第17位数字提取出来,然后利用MOD函数判断奇偶(能否被2整除),最后用IF函数判断男女。
计算方法:在E2单元格中输入公式”=IF(MOD(MID(B2,17,1),2),” 男”,”女””。结果如图
4.籍贯
在18位身份证号码中,前6位代表地址信息,其中第1、2位代表省,第3、4位代表地(市),第5、6位代表县(市)。如果能找到原始籍贯信息表,则通过VLOOKUP函数进行匹配是最简单易懂的方法,但是信息收集、存储及使用相对烦琐。
这里提供一种直接可以匹配到省的方法:先将代表身份的前两位数字提取出来,然后使用LOOKUP函数进行匹配,代表省份的数字与省份用数组公式表示。
计算方法:在C2单元格中输入公式”
=LOOKUP(VALUE(LEFT(B2,2)),{11,"北京市”;12,"天津市";13,"河北省";14," 山西省";15,"内蒙古自治区";21,"辽宁省:22,吉林省";23,"黑龙江省";31,“上海市";32,"江苏省";33,"浙江省";34,"安徽省";35,"福建省";36,"江西省;37,"山东省";41,‘河南省";42,"湖北省";43,"湖南省";44,"广东省";45,"广西壮族自治区";46,"海南省";50,"重庆市";51,"四川省";52,"贵州省";53,"云南省‘;54,"西藏自治区“;61,"陕西省“;62,"甘肃省“;63,‘青海省”;64,"宁夏回族自治区"; 65,"新疆维吾尔自治区";71,"台湾省";81,"香港特别行政区;82,"澳门特别行政区“;"","0"})“。结果如图。LOOKUP函数有两种应用形式:
一是向量形式,函数语法为LOOKUP(lookup_ value,lookup_ vector,result vector)。
二是数组形式,函数语法为LOOKUP(lookup _value,array)。
这里使用LOOKUP函数数组形式的语法,由省份代码和省份名称组成第二个参数array,且数组升序排列。

5.星座
星座与我们每个人的出生月和日相关,所以提取星座需要先提取出生的月份和具体日期。同样,我们也可以先编制一张出生日期与星座对照表,然后使用VLOOKUP函数进行匹配。
这里提供一种直接计算的方法, 与提取籍贯相似,也使用LOOKUP函数。
计算方法:在D2单元格中输入公式” =LOOKUP(–MID(B2,11,4),{100;120;219;321;421;521;622;723;823;923;1023;1122;1222},”摩羯座”,水瓶座”;双鱼座”,”白羊座”,”金牛座”;”双子座9,巨蟹座”,狮子座”,处女座”,”天秤座”;”天蝎座”;”射手座”,”摩羯座”})”。结果如图所示。
此处将日期变成数值进行计算,如6月23日,变成数值为623,在622和723之间,所以为巨蟹座。

6.属相
属相与我们每个人的出生年份相关,所以提取属相需要先提取出生年份。
这里同样提供两种计算方法。
计算方法1:在E2单元格中输入公式”=CHOOSE(MOD(MID(B2,7.4)- 2008.12+1.*鼠”,”牛”,”虎”,”兔”,”龙”,”蛇”,”马”,”羊,”猴”,”鸡”,”狗”,”猪”)”。
CHOOSE函数的语法1 CHOOSE(index _num, value1, (vlue2.,…当index _num为1时,计算结果为value1 ;当index. _num为2时,计算结果为value2 ;以此类推。
2008年为鼠年,每12年为一轮,与12相除的余数加1,得到的结果即为后面对应的属相。
计算方法2在E2单元格中输入公式”-MDOr 鼠牛虎免龙轮马羊聚鸡狗猪MOOMD (2.7,4)- 20+.121″结果如图。

数据分析
1.对比分析
1.时间对比:同环比
2.同级主体间对比:横向对比,比如:同一行业不同企业之间的对比
3.活动前后对比:纵向对比:营销活动效果,如客户满意度、广告业务、品牌知名度
4.实际完成和计划完成对比:横向对比,比如销售目标、实际完成、超额完成、完成率
注意:对比分析无处不在,但是并不代表任何两个数据均可以拿来做”对比”。在做”对比分析”的过程中,有两点需要注意。
①数据属性上的一致性。数据属性包括指标含义、计算方法、口径范围、计量单位等,只有属性致的数据才 有可比性。例如,北京联通 的客户满意度与江苏常州移动的客户满意度没有可比性,北京联通的满意度和忠诚度没有可比性,北京地区男性与上海地区女性的购买习惯没有可比性,采用不同满意度衡量体系得到的满意度数据没有可比性,300 元人民币与300美元也不能直接进行对比。
②数据形式上的一致性。数据的对比分析包括绝对数对比和相对数对比,绝对数只能和绝对数进行对比,相对数只能和相对数进行对比。例如,实际销售额(绝对数)只能跟其他绝对数进行对比,不能跟销售增长率这类相对数进行对比。
2.交叉分析
交叉分析就是将横向与纵向结合,实际上就是一张二维表,能够通过横向和纵向两个维度精准定位
3.综合评价分析法
案例:现需了解三大运营商在某高校的学生满意度情况
(1)确定评价指标体系
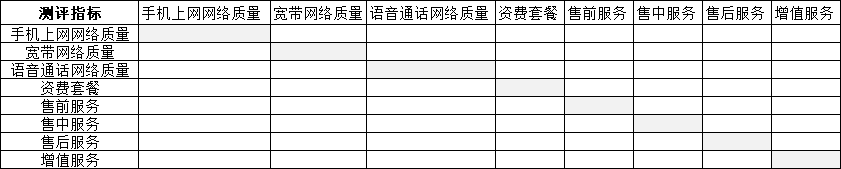
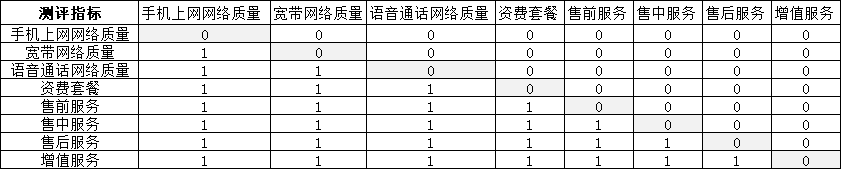
首先通过预调研了解学生在选择运营商时考虑的因素有哪些,然后对这些因素进行分类整理,最后得出运营商满意度指标,共有8个:手机上网网络质量、宽带网络质量、语音通话质量、资费套餐、售前服务、售中服务、售后服务、增值服务。
(2)确定指标权重
确定指标权重有多种方法,如分层分析法、德菲尔法、因子分析法等。其中,分层分析法和因子分析法需要借助统计学相关知识进行较为复杂的权重计算及验证;德菲尔法又称专家意见法。
在实际调研中,采用分层分析法和专家意见法结合,利用0-1二分法则,完成权重测算。
(3)建立矩阵表
(4)输入数值公式,初始化
在矩阵区主对角线单元格中全部输入数值0,代表每一个指标相对于自身的重要性不做判断,以此对角线为主分界。
在B3单元格输入公式=if(c2=1,0,1),在b4单元格输入=if(d2=1,0,1),以此类推,左下角单元格与右上角单元格实现以对角线为中心的对称,当右上角单元格全部为0时,左下角单元格全部为1,完成矩阵表的初始化。
(5)专家意见法:向专业人员征询:A列8个指标为i,第一行8个指标为j,当i较j重要时,在i和j的交叉节点处输入数值1,当i没有j重要时,输入数值0。最后计算每张专家矩阵表中各指标的平均值。
(6)计算各指标综合得分=sum(m2:t2),计算各指标权重(指标综合得分/各指标综合得分总和)=u2/sum($u$2:$u$9)。数据仅供参考。
(7)数据采集
通过线上线下调研,采集学生群体对运营商各指标的满意度情况数据:对8个指标从1-10分打分,计算各项指标满意度=(该项指标平均得分-1)/9 _100;计算总体满意度=sum(各项指标满意度_各项指标权重)。
得出满意度情况,明确短板,提供改进方向。

4.矩阵分析法
矩阵分析法解决问题和分配资源,集中力量解决主要问题。又叫波士顿矩阵分析法。波士顿矩阵:市场增长率-相对市场份额矩阵。原理:产品市场占有率越高,创造利润越强,销售增长率越高,为了维持其增长及扩大市场占有率所需的资金也越多,优化产品结构,资源良性循环的目的。
案例:客户满意度研究中应用矩阵分析法
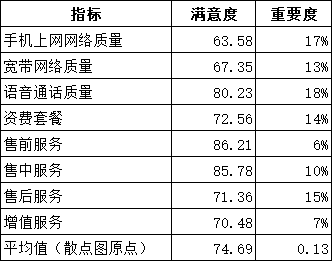
(1)确定各服务项目的重要度和满意度,重要度为指标权重
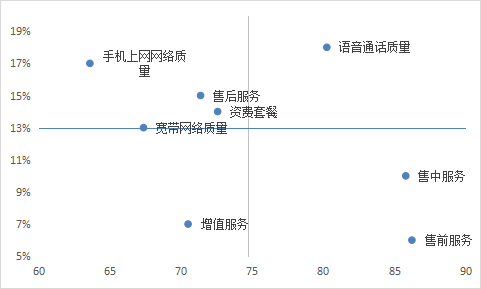
(2)以重要度数据为Y轴,以满意度数据为X轴,组成坐标轴,插入”散点图”,在x轴和y轴上按照重要程度和满意度平均值进行刻度划分,构成四个象限。
注意:纵向平均值线-点击纵向坐标轴-【设置坐标轴格式】-【坐标轴选项】-在【纵坐标轴交叉】-中输入74.69,-【标签】-【标签位置】-【低】-完成设置。横向同理。
散点图数据标签可以通过【标签选项】-【单元格中的值】来完成设置。
(3)确定4个象限的类型,分别为高度关注区、优先改进区、无关紧要区、优势维持区、并对各个区域进行详细解读
高度关注区:高满意度-高重要度区域,客户对该区域的指标” 语音通话质量”非常关注,且对该指标的表现也比较满意。因此,企业应对该服务项目继续保持关注和投入力度。
优先改进区:低满意度-高重要度区域,客户认为”手机上网网络质量”、”售后服务”、”资费套餐”、”宽带网络质量”相对来说还是比较重要的,但是企业提供的产品和服务让他们并不是很满意。因此,落在该区域的指标是企业目前迫切需要改进的。
无关紧要区:低满意度-低重要度区域,客户认为企业提供的”增值服务”相对来说不是很重要,且企业目前提供的”增值服务”也没有让他们很满意。因此,企业可以适当调整产品和服务策略,进一步关注客户对”增值服务”期望值的变化。如果客户期望值持续下降,且不符合公司定位或者未来市场需求,则可以将该项目上的资源转移至”优先改进区”的项目上。
优势维持区:高满意度-低重要度区域,客户认为”售中服务”和”售前服务”不是很重要,但是企业目前提供的”售中服务”和” 售前服务”还是让他们比较满意的。这就需要企业衡量在这两类服务项目上是否投入了过多的资源,如果是,则可以适当调整资源配置,将该区域过剩的资源转移至”优先改进区” ;如果不是因为资源投入过多,而仅仅是因为客户本来对该区域的期望值就比较低,可以维持现有的投入,继续保持在这两类服务项目上的优势。
5.对应分析
在企业营销中,经常需要明确产品 定位,即需要搞清楚以下3个问题:
①什么样的消费者在使用我们的产品?
②不同的消费者在购买习惯和使用习惯上存在什么差异?
③在消费者心目中,不同的品牌,形象有哪些不同?
如何通过数据分析回答这3个问题?这就需要借助矩阵分析法的另一种具体应用一对应分析,将品牌与消费者的”描述”yiyi对应来分析不同品牌在消费者心目中的形象是否存在差异。而这就需要利用 SPSS数据统计分析软件来实现。
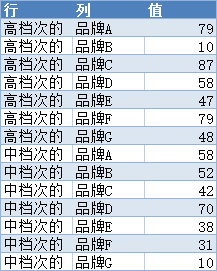
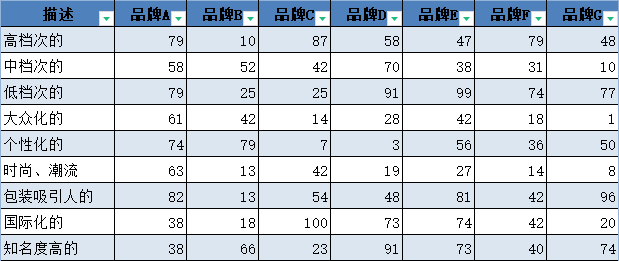
我们引用了””XX品牌消费者U8A调研”这样一个案例来学习二维表如何结换为一维表,今天我们再次引用这个案例并利用对应分析法对该品牌进行市场定位分析。
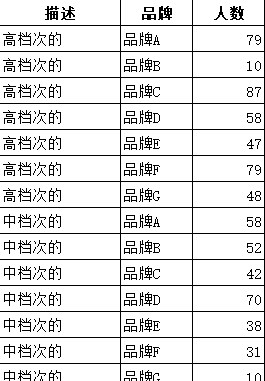
案例:XX 品牌消费者U&A调研。问卷中有这样一道题目:请告诉我下面这些词语,哪些最适合用来描述您刚才提及的具体品牌。(限选5个选项)
高档次的;中档次的;低档次的;大众化的;个性化的;时尚、潮流;包装吸引人的;国际化的;知名度高的;产品多样的;到处容易买到的;销量大的;有激情、活力的;稳重的
注意:消费者”描述”可选项数量最好超过品牌数量的3倍,这里为了简化计算操作步骤,适当地对可选项进行了精简。有效样本量为200个,将二维表转换为一维表的结果如图
(1)对变量进行编码
对应分析是要用各散点间的距离体现”品牌”和消费者” 描述”的关联关系。计算距离要求变量是数值型的,而从原始数据中可以看出” 品牌”和消费者” 描述”这两个变量都是文本型的。为了使这两个变量能够参与运算,需要将其编码,使之转变为数值型。编码规则如图所示。
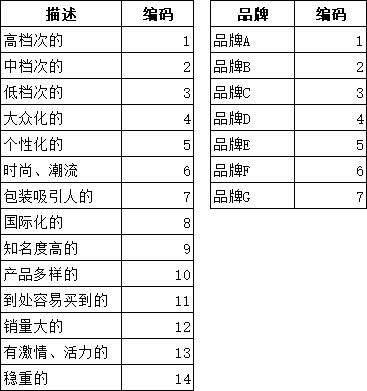
按照编码规则,利用vlookup将图中”品牌”和 消费者”描述” 的记录更换为编码值:
=VLOOKUP(A3,$I$2:$J$16,2,0)
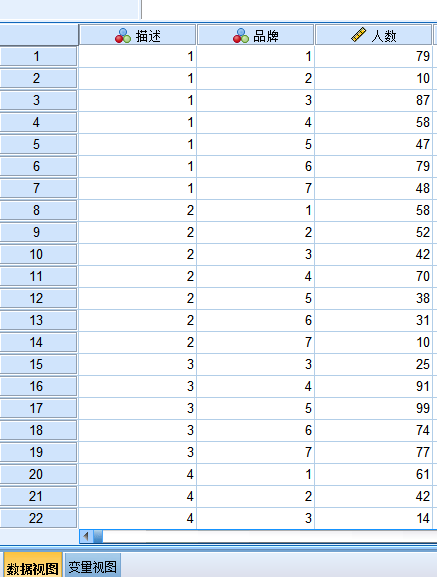
(2)将excel数据导入SPSS
打开spss,将数据导入:
设置”描述”变量值标签:在SPSS界面的左下角打开[变量视图]-单击”描述”的[值]单元格,打开[值标签]对话框,在[值]数值框中输入”1″,在[标签]文本框中输入”高档次的”,单击[添加]按钮。以此类推,将14个消费者”描述”的编码值和文本内容全部导入,单击[确定)按钮。
设置”品牌”变量值标签:同上
完成值标签设置后,切换到【数据视图]中对”人数” 进行”加权个案”。通常在分组计数的情况下,做多元对应分析和类别主成分分析需要对数据进行加权个案。单击[数据]-【加权个案], 将”人数”变量导入【加权个案]- [频率变量],单击[确定]按钮,
(3)进行对应分析
在【数据视图】中单击【分析】-【降维】-【对应分析】工具,打开【对应分析】对话框。将”描述”导入【行】
单击【定义范围】按钮,打开【对应分析定义行范围】对话框,共有14个消费者”描述”编码。在【最小值】数值框中输入1,在【最大值】数值框中输入14,单击【更新】按钮,将1~ 14导入【类别约束】列表框,单击[继续]按钮,同理,将”品牌”导入[列],单击[定义范围]按钮,打开[对应分析:定义列范围]对话框,共有7个”品牌”编码。在[最小值]数值框中输入1,在[最大值]数值框中输入7,单击[更新]按钮,将1~ 7导入[类别约束]列表框, 单击[继续]按钮。完成行和列设置,单击[确定]按钮,如图
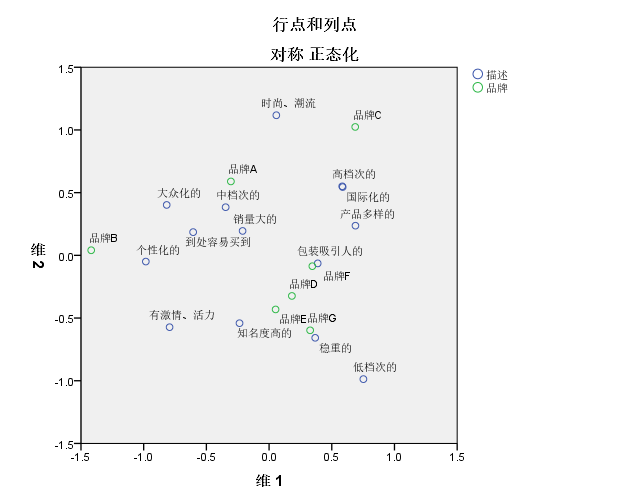
SPSS输出文档中生成了对应分析表、摘要、概宰行点、概率列点和对称的标准化5张图表。前4张图表主要是过程文件,具体内容在此不一-详述。重点是最后一张图表, 它是对应分析的最终结果。通过散点图中各散点的空间位置反映消费者”描述”与各”品牌” 的关联性,如图
(4)对图表添加参考线并进行美化。
双击图表进入[图表编辑器],单击工具栏上的[向X轴添加参考线]和[向Y轴添加参考线]图标,完成参考线设置。通过【属性】选项卡完成图表美化
(5)图表解读
根据图表中各散点的距离,解读品牌与品牌形象之间的关联性,一般分为两步。
1.考察同一变量的区分度。分别考察行变量、列变量各类别间是否被清晰地分隔开。可以分别考察在各个维度上的区分情况,如果同一变量不同类别在某个方向靠得较近,则说明这些类别在该维度上的区别不大。从”品牌”来看:品牌A、品牌B、品牌C这3个品牌之间的距离较远,且与其余4个品牌的距离也较远,说明A的品牌形象、B的品牌形象、C的品牌形象之间差别较大,且与其他4个品牌的品牌形象差别较大;品牌D、品牌E、品牌F、品牌G这4个品牌之间的距离较近,说明这4个品牌的品牌形象差异不大。从消费者”描述” 来看:”高档次的”与”国际化的”基本重叠,说明在消费者心目中富档次的”与”国际化的”这两个概念代表的含义基本-致;而 “时尚、潮流”与”低档次的”距离较远,说明在消费者心目中这是两个相反的概念。
2.考察两个变量之间的联系。两个变量之间的联系是对应分析考察的重点,也是我们应该真正关心的问题。一般而言,落在同一象限上的不同变量的分类点彼此有联系,散点间的距离越近,关联倾向越强。
从图可以看出,在消费者心目中,A的品牌形象主要是”中档次的”,F的品牌形象主要是”包装吸引人的”, E的品牌形象主要是”知名度高的” ,G的品牌形象主要是”稳重的”。
- 漏斗分析法
漏斗分析法使用场景–品牌阶梯分析:只通过对各相关层面,各个步骤进行描述后,判断哪一阶段的情况。
案例:XOX 品牌消费者U&A 调研。
问题1:以下这些品牌中,您听说过的品牌有哪些呢?
问题2:在过去的3个月里,您使用过的品牌有哪些?
问题3:在过去的3个月里,您经常使用的品牌有哪些?
可题4:在过去的3个月里,您最常使用哪一个品牌?
问题5:在以后的使用中,您会不会转换到其他品牌?
经过数据采集、数据录入、数据整理、数据计算等过程后,得到各个品牌在各个转换阶
段的消费者流失情况,如图
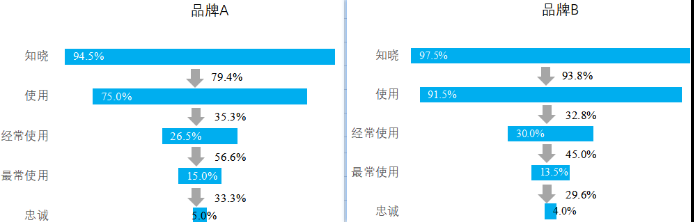
通过对比分析,我们可以得知品牌A在知晓率和使用转换率环节相对较为薄弱,应该加大宣传力度,让更多的消费者知道并且激发他们购买及使用的意愿;品牌B在经常使用转换率、最常使用转换率和忠诚转换率环节相对薄弱,应该加大产品研发力度,提高产品质量,加快产品的迭代升级,培养更多的忠诚用户。
2.漏斗分析法使用场景一电商销售管理
在电商销售管理方面,漏斗分析图可以帮助我们进行消费者购买流程中关键环节的转换率分析。
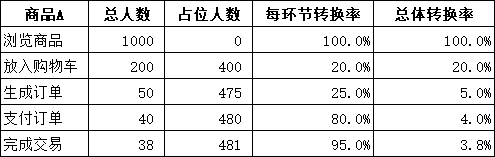
案例:网站后台数据显示浏览该商品的人数是1000 人,放入购物车的人数是 200 人,其中,50人生成了订单,40人支付了订单,38人完成了交易,在实际的数据分析过程中,单一的漏斗分析图无法准确评价某个关键流程中各环节转换率的好坏,可以对类似产品的转换率进行对比,也可以对该环节优化前后的效果进行对比,或者对同一环节不同细分客户群的转换率进行对比。总之,只有对比才能较为准确地得出该环节转换率的好坏,并有针对性地进行优化和改善。
操作步骤:
1.整理原始数据,设置辅助数据,如图示。在C2单元格中输入0,在 C3单元格中输入公式”=(1000-B3)/2″,向下填充公式;在D2单元格中输入 100%,在D3单元格中输入公式=B3/B2,向下填充公式;在E2单元格中输入公式”=B2/1000″,向下填充式。
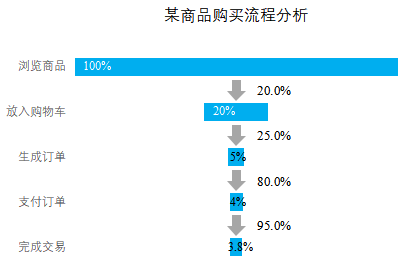
2.插入堆积条形图。
选择A、B、C 3列插入堆积条形图,在[设置坐标轴格式]- [坐标轴选项]选项卡中勾选[逆序类别]复选框,在[设计]-[选择数据]- [选择数据源]对话框中单击”下移”小三角,实现”占位人数”与”总人数”的位置互换。
3.美化图表,单击”占位人数”条形图,设置【无填充】,删除”网格线”,删除图例,删除横坐标轴,将纵坐标轴”刻度线”设置为”无线条”。
4.补充数据, 完成漏斗图制作。修改条形图标签,将总体转换率数据放置在条形图内侧,将每环节转换率数据放置在两个条形的中间,并用向下的箭头标识走向,即可完成所示的图表。
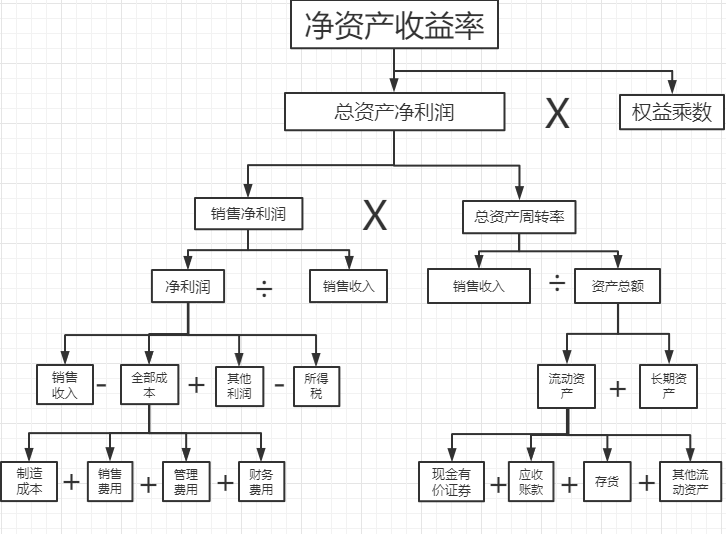
7.杜邦分析法
此方法是利用集中主要的财务比率之间的关系来综合分析企业财务状况的一种方法,以净资产收益率为核心,以总资产净利润和权益乘数为两大测评维度,重点揭示企业盈利能力及权益乘数对净资产收益率的影响,以及各指标间的相关关系,从财务角度为各级管理者优化经营状况、提高经营业绩提供思路
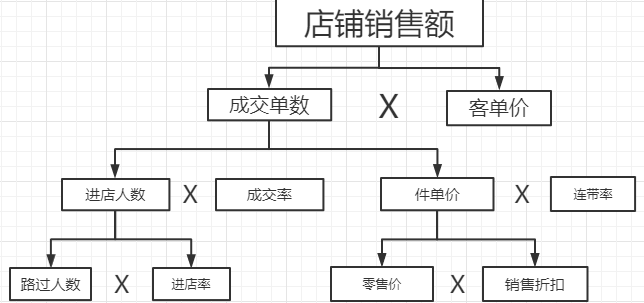
从上图可以看出,提高净资产收益率的根本在于扩大销售、节约成本、优化投资配置、加速资金周转、优化资金结构,除了用于财务分析,还有店铺销售额分析、市场占有率分析。
案例一:零售店销售额杜邦分析
从上图可知,影响店铺销售额指标有6个,”路过人数、进店率、零售价、销售折扣、成交率、连带率”。一般来说,”率”的影响大于绝对值,路过人数很难控制,进店率相对来说比较好控制,零售价出厂统一定价,没有办法提高,但可以控制销售折扣。
因此,连带率是最容易改善的,其次是成交率,再次是销售折扣,而路口人数难控制,其次是零售价,再次是进店率。零售店铺可以根据难以程度及本身存在的薄弱环节来改善细项指标,最终实现店铺销售额的提高。
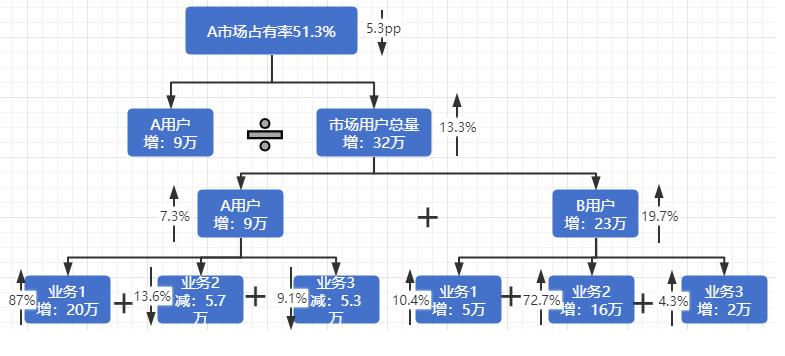
案例二:某公司市场占有率杜邦分析,如图:
从图看出,A市场占有率任然处于行业领先地位,且2016年A的用户规模任在增长;但是A市场占有率较2015年下降5.3pp,主要原因是市场用户总量的增长率高于A的用户增长率;而市场用户总量的快速增长是因为B用户的大规模增长,其中B的三大业务均出现不同幅度的增长,而业务2增长幅度最大;A的业务1增长幅度大,但是业务2和业务3的用户规模下降,也导致A整体的用户规模增幅低于市场用户总量。
; 数据呈现
1.数据图表使用原则:简洁明确
2.数据图表的四大构成元素
1.标题:分主标题和副标题,主标题是船体主要信息,副标题对主标题补充
2.绘图区
3.图例
4.脚注:对图表中数据进行解释,同时添加数据来源
3.图表:
柱形图与条形图
柱形图与折线图
折线图与面积图
饼图
树状图:展示有结构关系的数据之间的比列分布情况
旭日图:展示层级和归属关系,便于进行细分溯源分析
直方图:分析数据分布比重和分布频率
箱形图:常用于品质管理,提供有关数据位置和分散情况的关键信息
瀑布图:表现数据的增减变化情况及数据之间的差异对比,适合财务分析
盈亏柱形图
堆积柱形图:多个数据系列并且希望强调总数值
双层环形图
背离式条形图(旋风图):进行数据对比
热力型数据地图
数据分析报告
1.数据分析报告的种类
行业级分析报告:针对某一行业的发展历史、发展现状、发展趋势进行分析,采用的分析方法主要有PEST\波特五力模型
企业级分析报告:针对企业的客户、产品、服务等方面进行分析,采用的分析方法有SWOT、4P、5W2H
综合型分析报告:多维度拆解分析方法
专题型分析报告:
日常型分析报告:定期数据为基础,用来反映计划执行情况、业务发展情况、投诉量变动等,特征是时效性
三方机构分析报告:
其他常用的分析方法:逻辑树分析方法、对比分析方法、假设检验分析、相关分析方法、群组分析方法、RFM分析方法、AARRR模型分析、漏斗分析。
2.数据分析报告结构
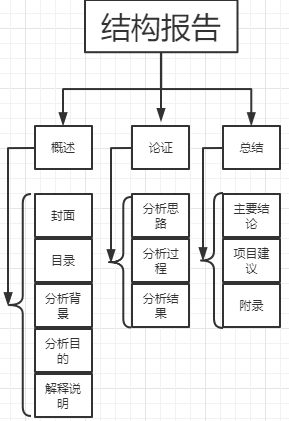
其中,
解释说明:是对影响数据分析质量的关键因素进行详细描述,一般包括
{
项目执行方式:比如线上调研
总样本量:2000
样本构成:20-40岁 男性和女性
指标解释:
特殊情况说明等
}
分析背景:
{
内部环境:企业市场目标调整、新产品上市、新技术研发
外部环境:市场需求变化、政策导向变化、竞争对手战略调整
}
分析目的:围绕背景的变化,解决企业现阶段的各种问题。
核心结论:行为现象的结论–这种结论涉及到的社会学、经济学、心理学现象–现象背后的原因。
Original: https://blog.csdn.net/QuartusII7/article/details/121658130
Author: QuartusII7
Title: 数据分析入门到精通
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/699192/
转载文章受原作者版权保护。转载请注明原作者出处!