

提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
Scrapy爬虫之网站图片爬取
- Scrapy爬取网站实训图片的链接
提示:以下是本篇文章正文内容,下面案例可供参考
1.任务描述
本关任务:使用Scrapy爬取给定网站的图片链接,并保存到本地。
2.相关知识
为了完成本关任务,你需要掌握:
- Scrapy基本操作;
- xpath匹配;
- 文件操作。
生成Scrapy爬虫
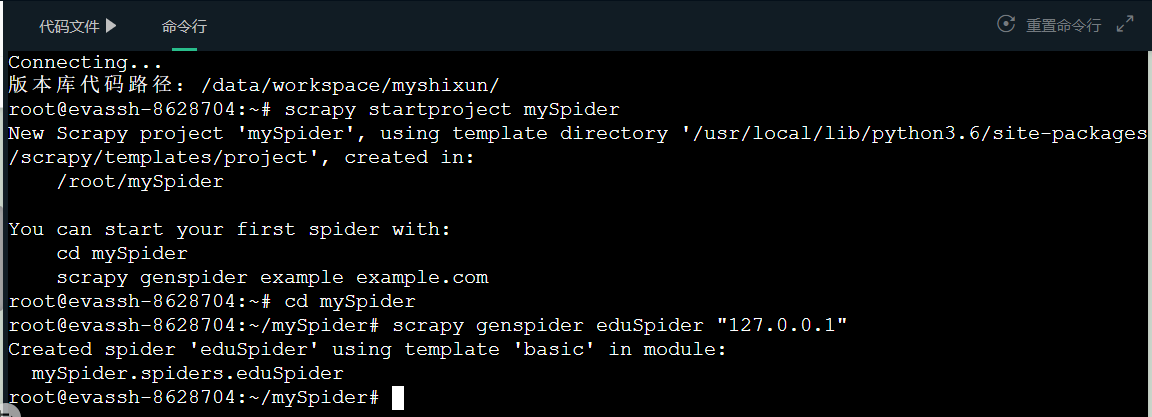
- 新建Scrapy项目——mySpider; 在你想放项目文件的目录下,打开cmd命令窗口,输入命令scrapy startproject mySpider,就可以在该目录下成功生成项目文件夹。
- 生成主爬虫; 进入/mySpider/mySpider/spiders目录下,在此处打开cmd命令窗口,输入命令
scrapy genspider eduSpider "127.0.0.1",eduSpider是爬虫名字,后面接的是爬虫爬取的域的范围。
做完这一步Scrapy爬虫框架就搭建完成,接下来就可以开始代码编写定制你的专属爬虫了。
在目录下,快速打开cmd窗口的小技巧:
- 按Shift+鼠标右键,点击【在此处打开命令窗口】(或【在此处打开PowerShell窗口】)就可快速打开;
- 在文件夹最上面的路径中,选中该路径,直接输入cmd即可。

; 制作Scrapy爬虫
- 文件的读写;
以下代码为Python中最常见的IO操作——读写文件。用w(写)的方式打开文件images.txt(没有就会自动创建),将字符串abc写入了其中。
with open('images.txt','w') as f:
img = abc
f.write("{}\n".format(img))
- xpath匹配;
匹配前要对被爬取的网页进行分析,我使用的是360浏览器,在要爬取的图片上右击选择审查元素(其他浏览器都有类似的功能,具体操作可网上搜索),如下图,定位到图片在网页源码的位置。
images = response.xpath("//div[@class='box']/div/a/img/@src")
index.html
DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>花title>
head>
<body>
<div class="box">
<div>
<a href="/static/app1/imgs/1.png" target="_blank">
<img src="/static/app1/imgs/1.png" alt="未显示">
a>
div>
<div>
<a href="/static/app1/imgs/10.png" target="_blank">
<img src="/static/app1/imgs/10.png" alt="未显示">
a>
div>
<div>
<a href="/static/app1/imgs/11.png" target="_blank">
<img src="/static/app1/imgs/11.png" alt="未显示">
a>
div>
<div>
<a href="/static/app1/imgs/12.png" target="_blank">
<img src="/static/app1/imgs/12.png" alt="未显示">
a>
div>
<div>
<a href="/static/app1/imgs/13.png" target="_blank">
<img src="/static/app1/imgs/13.png" alt="未显示">
a>
div>
<div>
<a href="/static/app1/imgs/14.png" target="_blank">
<img src="/static/app1/imgs/14.png" alt="未显示">
a>
div>
<div>
<a href="/static/app1/imgs/15.png" target="_blank">
<img src="/static/app1/imgs/15.png" alt="未显示">
a>
div>
<div>
<a href="/static/app1/imgs/16.png" target="_blank">
<img src="/static/app1/imgs/16.png" alt="未显示">
a>
div>
<div>
<a href="/static/app1/imgs/17.png" target="_blank">
<img src="/static/app1/imgs/17.png" alt="未显示">
a>
div>
<div>
<a href="/static/app1/imgs/18.png" target="_blank">
<img src="/static/app1/imgs/18.png" alt="未显示">
a>
div>
<div>
<a href="/static/app1/imgs/19.png" target="_blank">
<img src="/static/app1/imgs/19.png" alt="未显示">
a>
div>
<div>
<a href="/static/app1/imgs/2.png" target="_blank">
<img src="/static/app1/imgs/2.png" alt="未显示">
a>
div>
<div>
<a href="/static/app1/imgs/20.png" target="_blank">
<img src="/static/app1/imgs/20.png" alt="未显示">
a>
div>
<div>
<a href="/static/app1/imgs/21.png" target="_blank">
<img src="/static/app1/imgs/21.png" alt="未显示">
a>
div>
<div>
<a href="/static/app1/imgs/22.png" target="_blank">
<img src="/static/app1/imgs/22.png" alt="未显示">
a>
div>
<div>
<a href="/static/app1/imgs/23.png" target="_blank">
<img src="/static/app1/imgs/23.png" alt="未显示">
a>
div>
<div>
<a href="/static/app1/imgs/24.png" target="_blank">
<img src="/static/app1/imgs/24.png" alt="未显示">
a>
div>
<div>
<a href="/static/app1/imgs/25.png" target="_blank">
<img src="/static/app1/imgs/25.png" alt="未显示">
a>
div>
<div>
<a href="/static/app1/imgs/3.png" target="_blank">
<img src="/static/app1/imgs/3.png" alt="未显示">
a>
div>
<div>
<a href="/static/app1/imgs/4.png" target="_blank">
<img src="/static/app1/imgs/4.png" alt="未显示">
a>
div>
<div>
<a href="/static/app1/imgs/5.png" target="_blank">
<img src="/static/app1/imgs/5.png" alt="未显示">
a>
div>
<div>
<a href="/static/app1/imgs/6.png" target="_blank">
<img src="/static/app1/imgs/6.png" alt="未显示">
a>
div>
<div>
<a href="/static/app1/imgs/7.png" target="_blank">
<img src="/static/app1/imgs/7.png" alt="未显示">
a>
div>
<div>
<a href="/static/app1/imgs/8.png" target="_blank">
<img src="/static/app1/imgs/8.png" alt="未显示">
a>
div>
<div>
<a href="/static/app1/imgs/9.png" target="_blank">
<img src="/static/app1/imgs/9.png" alt="未显示">
a>
div>
div>
body>
html>
掌握了以上两点知识,我们就可以开始写我们的主爬虫文件eduSpider.py了,步骤如下:
- 以写的方式打开文件images.txt(如果目录下没有会自动生成该文件);
- xpath匹配图片链接;
- 将匹配到的链接写入images.txt中。
运行Scrapy爬虫
在主爬虫文件eduSpider.py中,定义了爬虫的名字,我们运行的时候就需要这个名字。
运行爬虫时,必须进入项目文件/mySpider中,这里有一个生成爬虫时自动生成的scrapy.cfg配置文件,只有在这个文件所在的位置才可以输入命令,启动爬虫。爬虫运行命令: scrapy crawl eduSpider(爬虫名)。

注:爬虫运行命令我已经写到脚本程序里了,你完成代码后只需要点击测评,平台会自动启动爬虫,以下关卡都相同。在这里介绍是为了你课下在Windows平台练习的需求。
; 3.编程要求
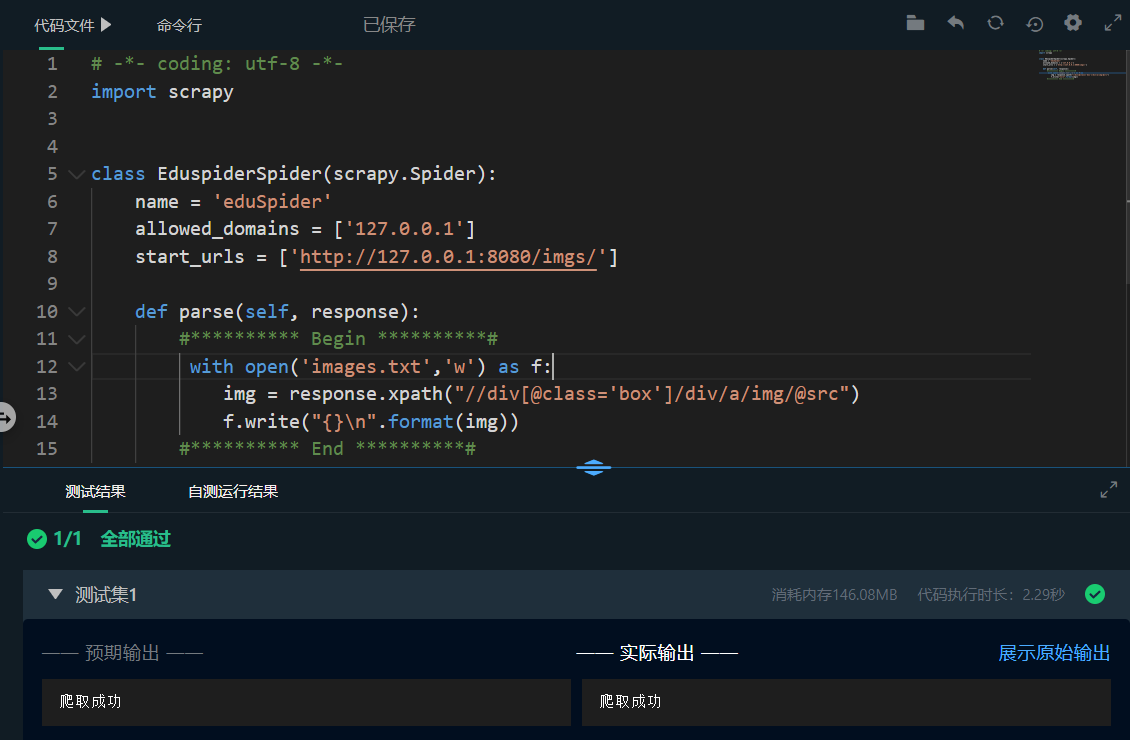
首先,通过审查元素,观察图片链接的代码规律;然后,点击代码文件旁边的三角符号,选择文件eduSpider.py,如下图所示。在 Begin-End 区间补充代码,使函数 parse 能够爬取图片链接,并保存到本地文件images.txt中。
4.测试说明
平台会对你编写的代码进行测试(本次测试无输入):
预期输出:
爬取成功
5.笔者答案
import scrapy
class EduspiderSpider(scrapy.Spider):
name = 'eduSpider'
allowed_domains = ['127.0.0.1']
start_urls = ['http://127.0.0.1:8080/imgs/']
def parse(self, response):
with open('images.txt','w') as f:
img = response.xpath("//div[@class='box']/div/a/img/@src")
f.write("{}\n".format(img))
通过截图
; 总结
- Scrapy爬取网站实训图片的链接
Original: https://blog.csdn.net/qq_42856609/article/details/122746697
Author: Zhang Wenhao
Title: 1. Scrapy爬取网站实训图片的链接
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/698241/
转载文章受原作者版权保护。转载请注明原作者出处!