

提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
例如:本周阅读了这篇论文,特此记录笔记
一、当年现状
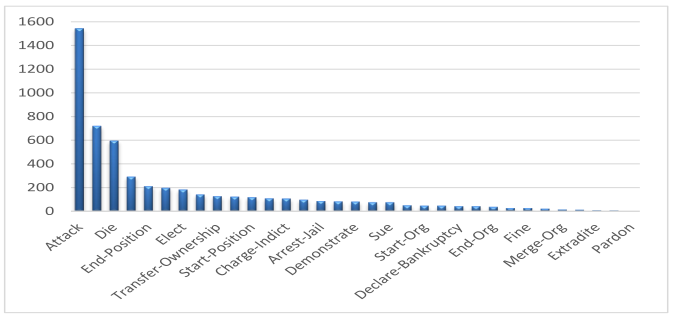
。在 ACE 2005 中,所有 33 种事件类型都是手动预定义的,并且由于注释过程非常昂贵,因此仅在 599 个英文文档中手动注释了相应的事件信息(包括触发器、事件类型、参数及其角色)。 如图 2 所示,ACE 2005 中近 60% 的事件类型的标记样本少于 100 个,甚至有三种事件类型的标记样本少于 10 个。 此外,那些预定义的 33 种事件类型在大规模数据上的自然语言处理 (NLP) 应用程序中的覆盖率很低。因此,对于大规模事件的提取,尤其是在开放域场景中,如何自动高效地生成足够的训练数据是一个重要的问题。

; 二、数据集
数据集
Freebase是语义知识库,本文选择了21种事件类型,其中约有380万个实例进行实验
FrameNet是一种语言资源,用于存储有关词汇和谓词参数语义的信息
Wikipedia维基百科数据
三、方法
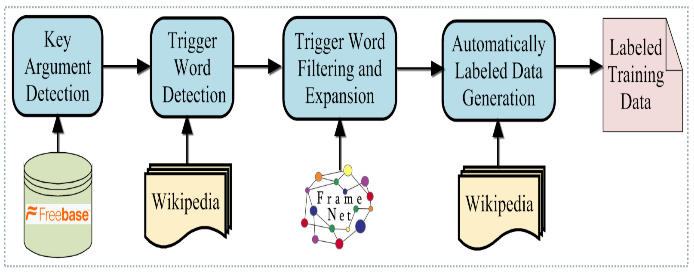
Key Argument Detection:
(直观地说,一类事件的自变量扮演着不同的角色。一些论点在事件中起着不可或缺的作用,并且在区分不同事件时充当重要的线索。例如,与时间,地点等论点相比,配偶是婚姻事件中的关键论点。我们称这些论点为关键论点。)
对每种事件类型的参数进行优先级排序,并为每种类型的事件选择关键参数
角色显著性(RS):计算元素相关性;使用一个参数来区分一个事件实例和给定事件类型的其他实例,那么这个参数将在给定事件类型中发挥重要作用

其中 RSij 是第 j 个事件类型的第 i 个参数的角色显着性,Count(Ai , ETj) 是 Freebase 中所有 event Type j 实例中出现的 Arguemnti 的数量,Count(ETj) 是 event Type j 的实例数在Freebase的数量
事件相关性 (ER): 反映了参数可用于区分不同事件类型的能力。如果在每个事件类型中发生参数,则该参数将具有较低的事件相关性。我们建议计算ER如下:

其中 ERi 是第 i 个参数的事件相关性,Sum (ET) 是知识库中所有事件类型的数量,Count(ETCi) 是包含第 i 个参数的事件类型的数量 . 最后,KR 计算如下:

Trigger word detection:
在检测到每种事件类型的关键参数之后,我们使用这些关键参数来标记可能在Wikipedia中表达事件的句子.最后,作者选择包含Freebase中事件实例的所有关键参数的句子作为表达相应事件的句子.然后使用这些标记的句子来检测触发器.如果一个动词在一个事件类型的标记句子中出现的次数多于其他动词,则该动词倾向于触发该类型的事件;如果一个动词出现在每个事件类型的句子中,比如i,这个动词触发事件的概率很低.我们提出触发候选频率(TCF)和触发事件类型频率(TETF)来评估上述两个方面


其中 TRij 是第 i 个动词对第 j 个事件类型的触发率,Count(Vi, ETSj) 是表达第 j 个事件类型并包含第 i 个动词的句子的数量,Count(ETSj) 是个数 在表达第 j 个事件类型的句子中,Count(ETIi) 是事件类型的数量,这些事件类型的标记句子包含第 i 个动词。 最后,我们选择具有高 TR 值的动词作为每种事件类型的触发词。
Trigger word filtering and expansion:
通过以上触发词检测,我们可以得到一个初始的语言触发词库,由于存在较大噪声,且缺乏名词触发因素,我们使用词嵌入将Freebase中的事件映射到FrameNet中的帧,通过计算语义相似度选择映射框架,从而过滤在初始动词触发词词典中而不在映射框架中的动词.并且我们使用对映射框架具有高置信度的名词来扩展触发词典.
具体来说,我们使用所有词的平均单词嵌入i Freebase事件类型名称ei和字嵌入j k词法单元的框架ej, k计算语义相似度。最后,我们选择帧包含最大相似性的ei和ej, k映射框架,可以制定如下:

Automatically labeled data generation
本文提出了一个软远程监督并使用它来自动生成训练数据,它假设任何包含Freebase中所有关键参数和相应触发词的句子都可能以某种方式表达该事件,并且参数发生在那个句子中很可能在那个事件中扮演相应的角色.
; 小结
第一阶段称为事件分类,旨在预测关键参数候选人是否参与 Freebase 事件。 如果关键参数参与 Freebase 事件,则进行第二阶段,该阶段旨在为事件分配参数并确定其相应角色。
我们将要在 DMCNN 中训练的参数分类阶段的所有参数定义为 θ。 假设有 T 个包 {M1,M2, …,MT} 并且第 i 个包包含 qi 个实例(句子) Mi = {m1 i ,m2 i , …,mqi i } ,目标 多实例学习是预测看不见的袋子的标签。 在参数分类阶段,我们将包含相同候选参数的句子和具有相同事件类型的触发器作为包,并且独立考虑包中的所有实例。 给定一个输入实例 mj i ,具有参数 θ 的网络输出一个向量 O,其中第 r 个分量 Or 对应于与参数角色 r 关联的分数。 为了获得条件概率 p(r|mj i , θ),我们对所有参数角色类型应用 softmax 操作:

其中,n 是角色的数量。多实例学习的目标是区分包而不是实例。因此,我们定义了袋子的目标函数。给定所有 (T) 个训练包 (Mi, yi),我们可以使用包级别的交叉熵定义目标函数,如下所示:
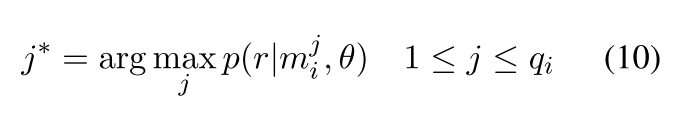

为了计算网络参数θ,我们使用Adadelta(Zeiler,2012)更新规则,通过小批量随机梯度下降来最大化对数似然J(θ)
总结
结论:本文首先手动评估自动生成的标记数据的精度.从自动标记的数据中随机选择500个样本.每个选定的样本都包含突出显示的触发器,标记的参数以及相应的事件类型和参数角色.同时给出了一些要求示例,注释者为每个样本分配两个标签之一.在自动生成的数据在触发标记和参数标记上可以达到88.9和85.4的精度.

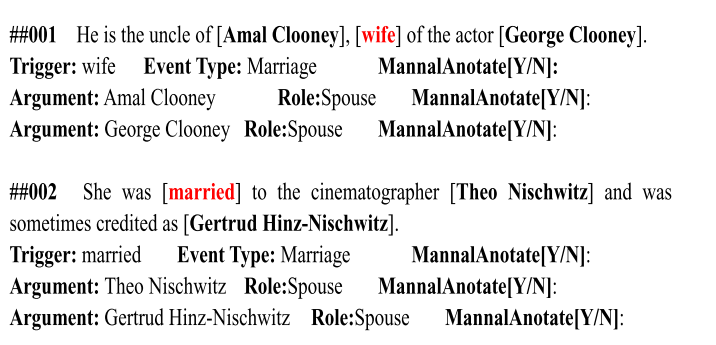
上图是人工验证方法及结果,结果显示,本文方法与人工标注方法相比正确率达85多。可以取得不错的效果。
Original: https://blog.csdn.net/weixin_45742602/article/details/124398136
Author: 云桬
Title: Automatically Labeled Data Generation for Large Scale Event Extraction论文笔记
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/554939/
转载文章受原作者版权保护。转载请注明原作者出处!