

目录
“物以类聚,人以群分”,所谓的聚类,就是将样本划分为由类似的对象组成的多个类的过程。聚类后,我们可以更加准确的在每个类中单独使用统计模型进行估计、分析或预测;也可以探究不同类之间的相关性和主要差异。
聚类和分类的区别:分类是已知类别的,聚类未知。
一、K-means聚类算法
1、K-means聚类算法流程
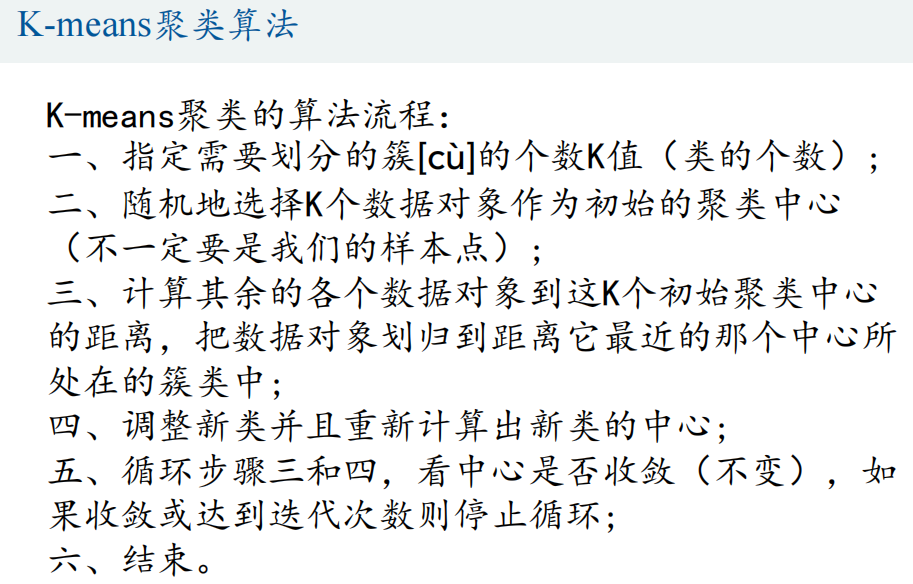

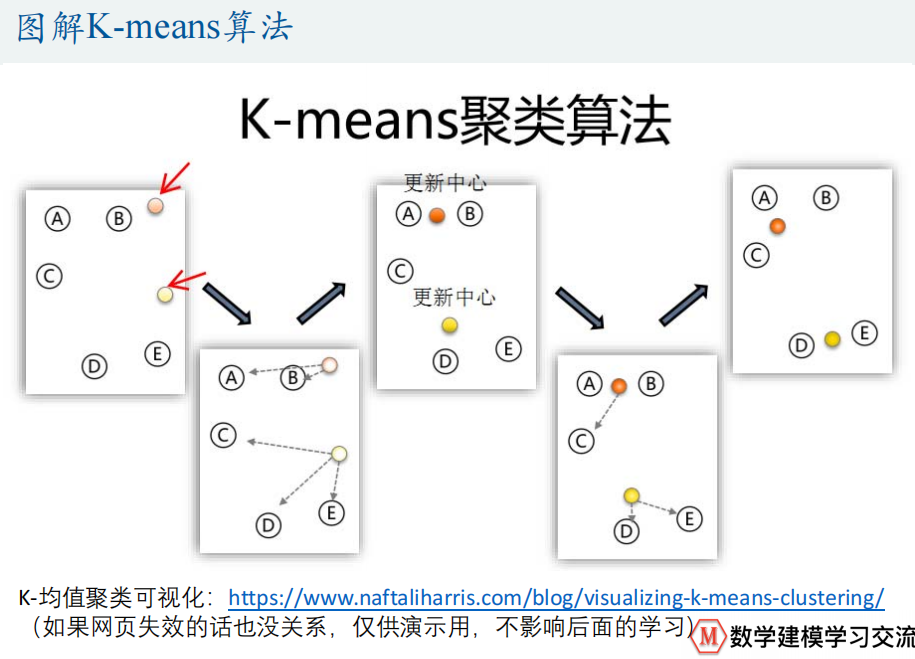
2、 算法流程图
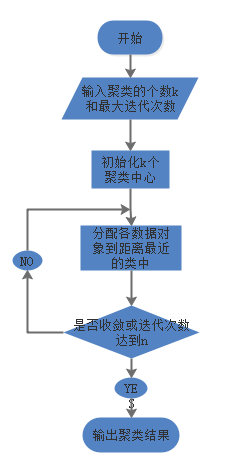
3、 K-means 算法的评价
优点:
(1)算法简单、快速
(2)对处理大数据集,该算法是相对高效率的。
缺点:
(1)要求用户必须事先给出要生成的簇的数目K。
(2)对初值敏感。
(3)对于孤立点数据敏感。
K‐means++ 算法可解决( 2) 和( 3) 这两个缺点。
二、K-means++算法
1、算法描述

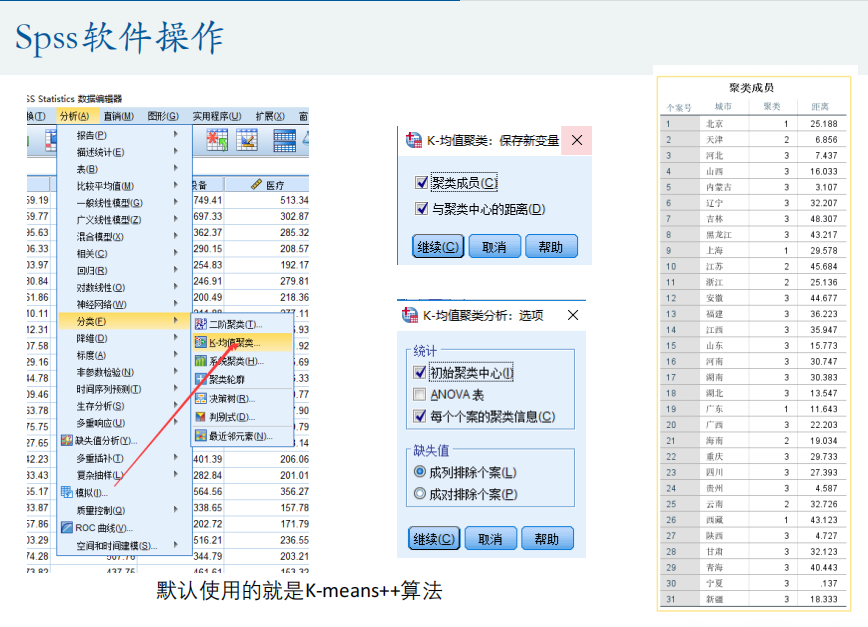
2、Spss软件操作
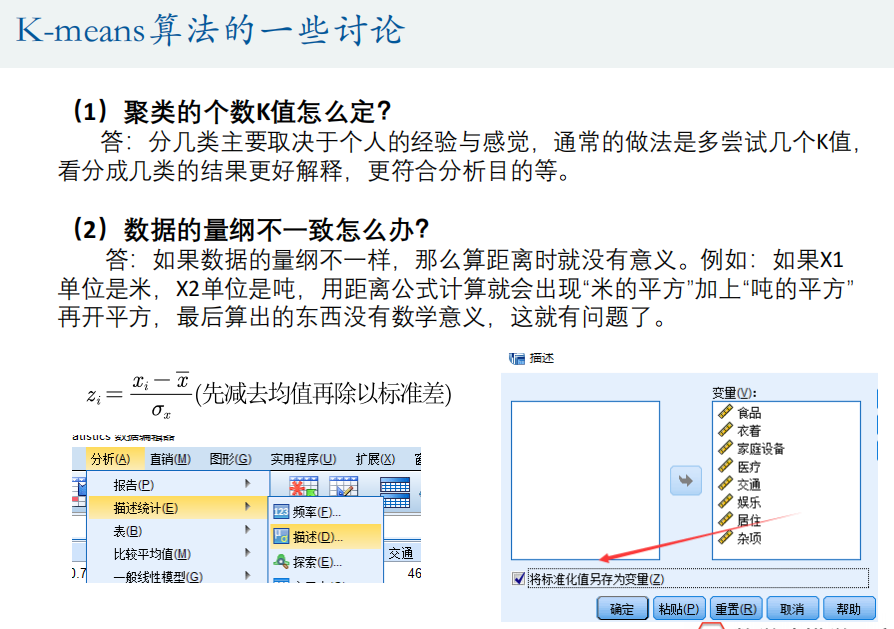
三、 系统(层次)聚类
1、简介
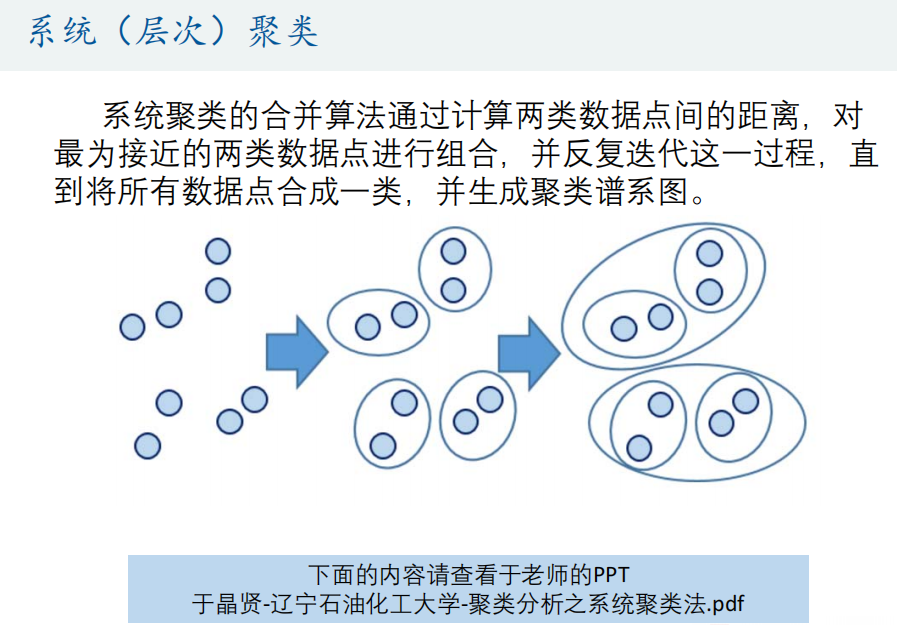

2、Spss软件操作

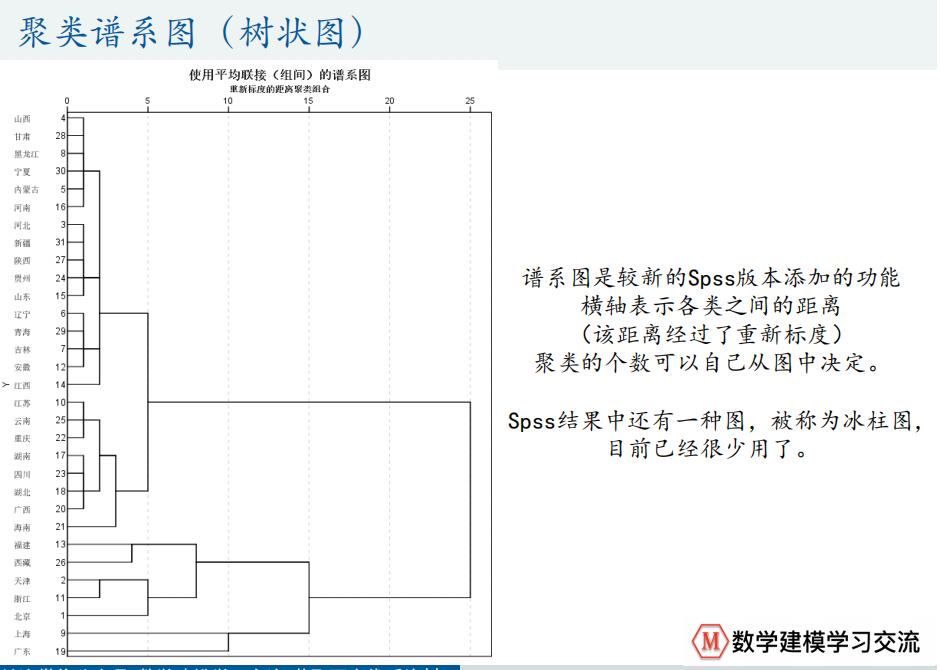
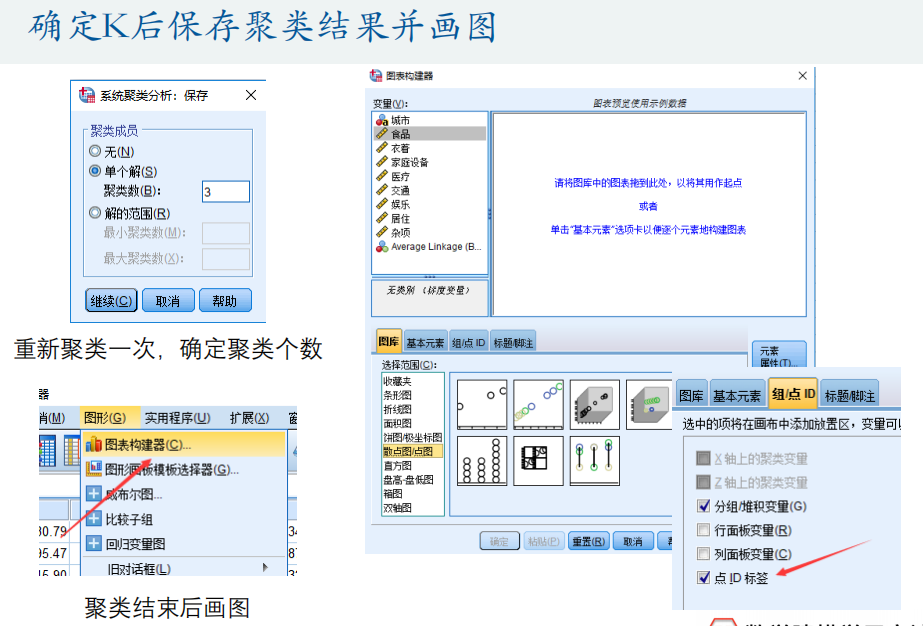
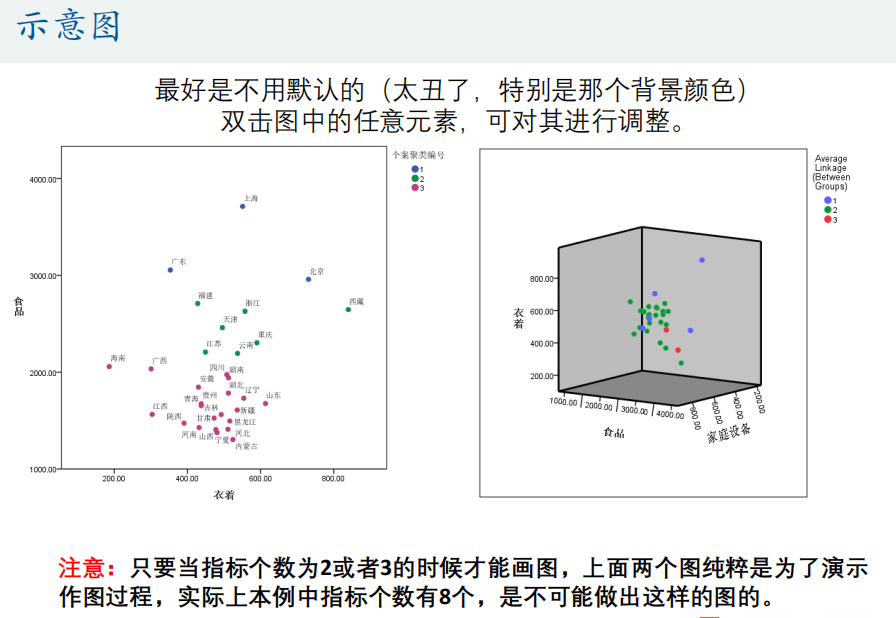
3、聚类谱系图(树状图)
4、 用图形估计聚类的数量

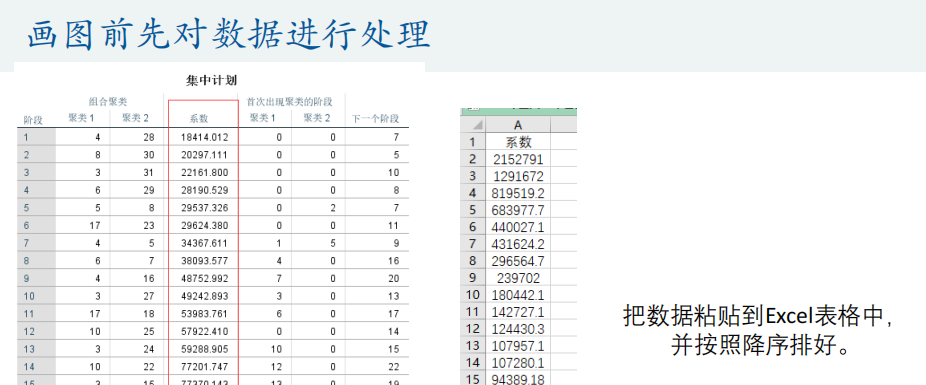
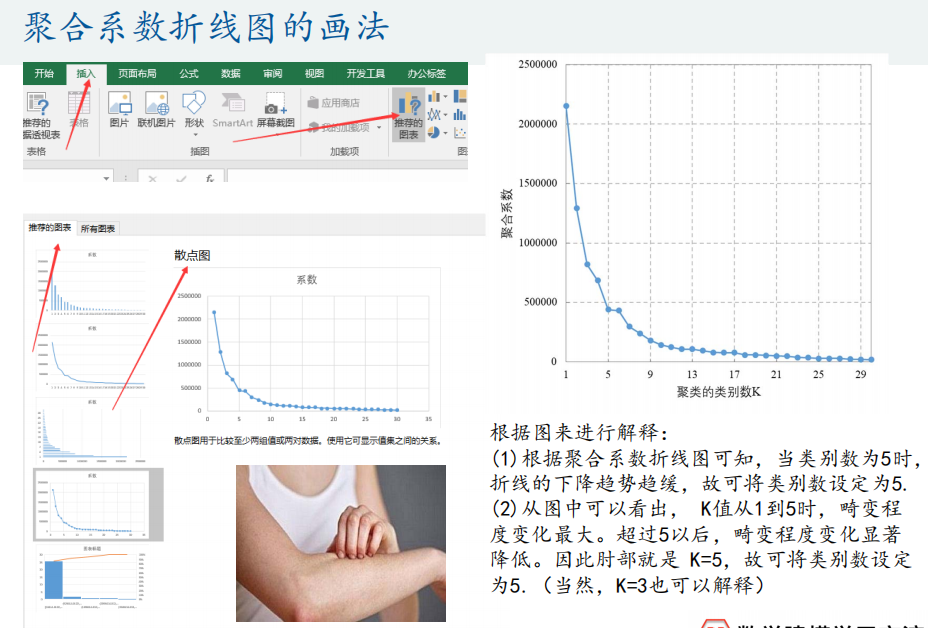
5、聚类系数折线图的画法
四、 DBSCAN算法

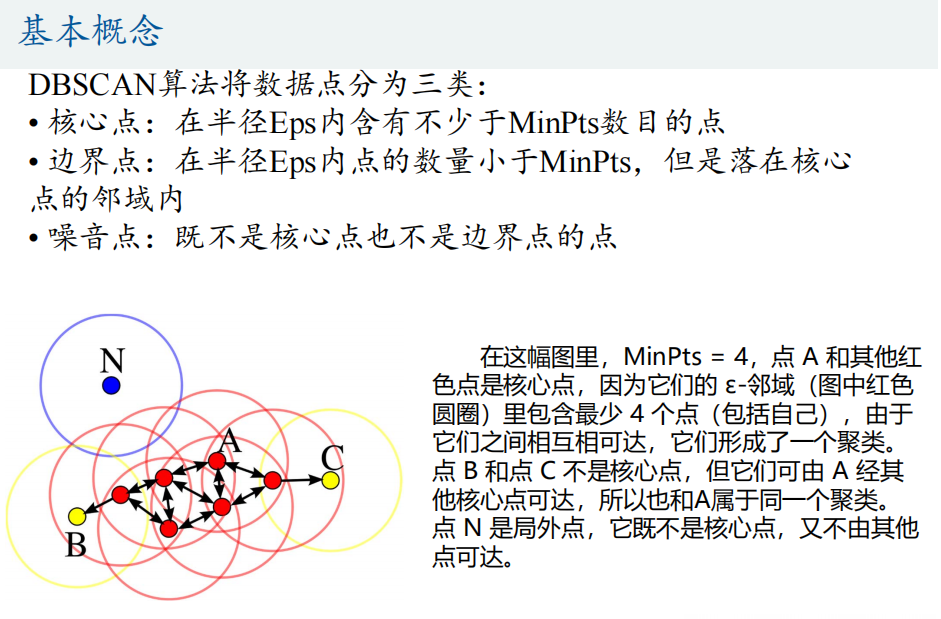
1、基本概念
2、伪代码

3、Matlab代码

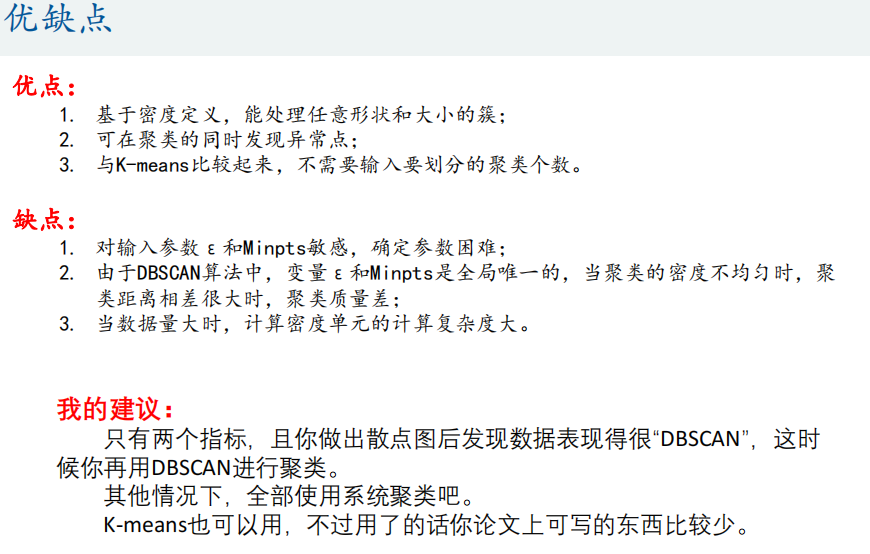
4、优缺点
参考:清风数学建模课程笔记,仅作为个人笔记。
Original: https://blog.csdn.net/catzhaojia/article/details/122666779
Author: 要如我愿
Title: 【数学建模】聚类模型
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/698235/
转载文章受原作者版权保护。转载请注明原作者出处!