

目录
举一反三 对一个工作簿中的所有工作表分别求和并将求和结果写入固定单元格
案例01 批量升序排序一个工作簿中的所有工作表
- 代码文件:批量升序排序一个工作簿中的所有工作表.py
- 数据文件:产品销售统计表.xlsx
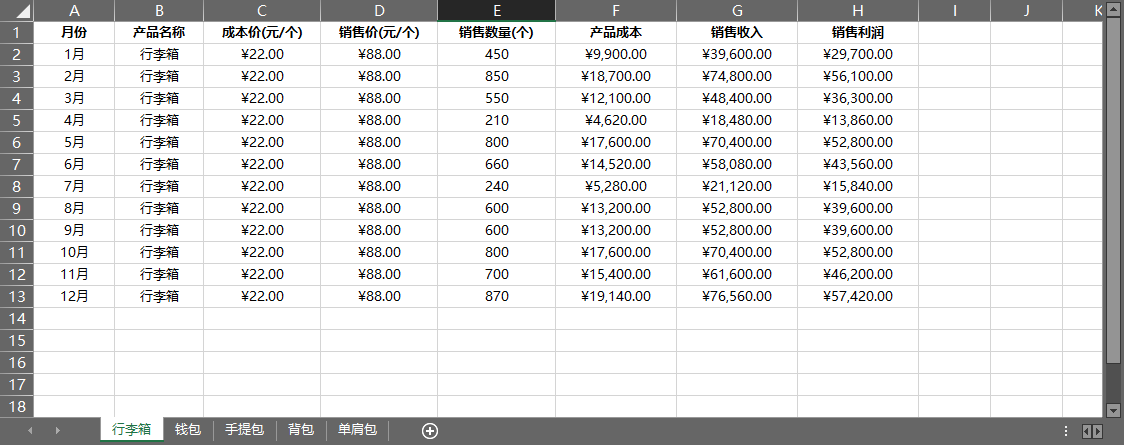

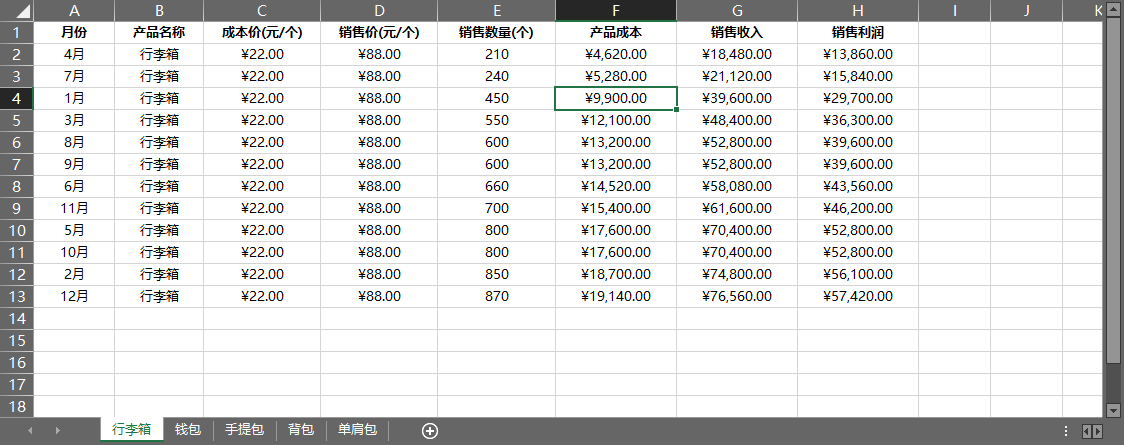
import xlwings as xw
import pandas as pd
app=xw.App(visible=True,add_book=False)
workbook=app.books.open(r'C:\Users\MLoong\Desktop\22\产品销售统计表.xlsx')
for i in workbook.sheets:
values=i.range('A1').expand().options(pd.DataFrame).value #读取当前工作表的数据并装换成DataFrame类型
result=values.sort_values(by='销售利润') #对销售利润进行排序
i.range('A1').value=result
workbook.save()
workbook.close()
app.quit()
知识延伸
第 8 行代码中的 sort_values() 是 pandas 模块中DataFrame对象的函数,用于将数据区域按照某个字段的数据进行排序,这个字段可以是行字段,也可以是列字段。在 3.5.3 节曾简单介绍过s ort_values()函数的用法,这里再详细介绍一下该函数的语法格式和常用参数含义。 sort_values(by=’##’,axis=0,ascending=True,inplace=False,na_position=’last’)
举一反三 批量排序多个工作簿中的数据
- 代码文件:批量排序多个工作簿中的数据.py
- 数据文件:产品销售统计表(文件夹)
除了对一个工作簿的数据进行批量排序,还可以对多个工作簿的数据进行批量排序,具体代码如下
import os
import xlwings as xw
import pandas as pd
app=xw.App(visible=True,add_book=False)
file_path=r'C:\Users\MLoong\Desktop\22\产品销售统计表'
file_list=os.listdir(file_path)
for i in file_list:
if os.path.splitext(i)[1]=='.xlsx':
file_paths=os.path.join(file_path,i)
workbook=app.books.open(file_paths)
for j in workbook.sheets:
values= j.range('A1').expand().options(pd.DataFrame).value
result=values.sort_values(by='销售利润')
j.range('A1').value=result
workbook.save()
workbook.close()
app.quit()
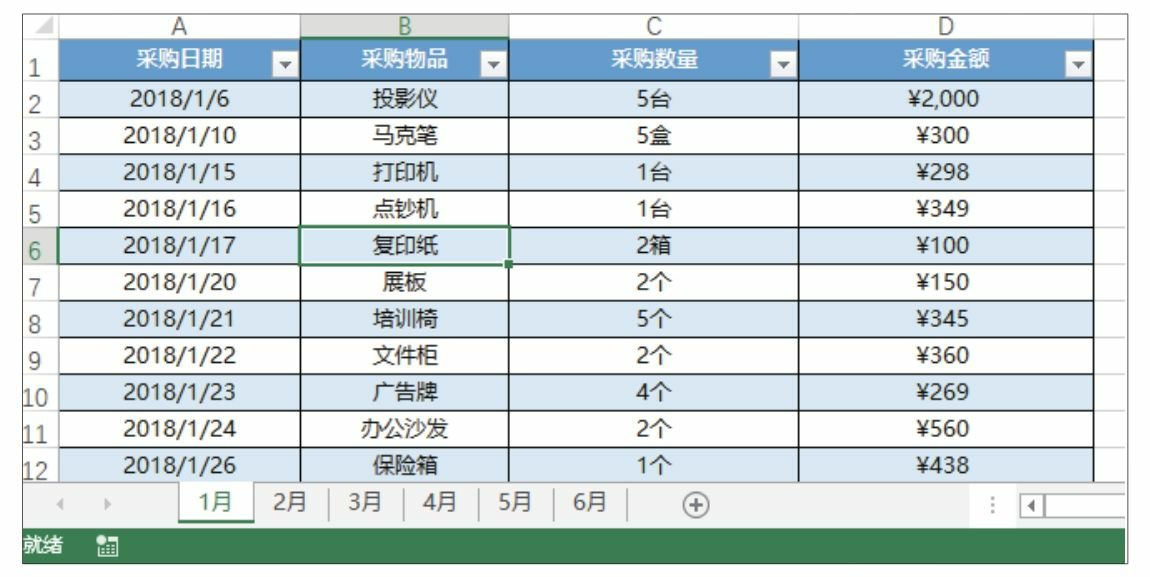
案例02 筛选一个工作簿中的所有工作表数据
- 代码文件:筛选一个工作簿中的所有工作表数据.py
- 数据文件:采购表.xlsx
下图所示是按月份存放在不同工作表中的物品采购明细数据,如果要更改为按物品名称存放在不同工作表中,你会怎么做呢?
import xlwings as xw
import pandas as pd
app=xw.App(visible=True,add_book=False)
workbook=app.books.open(r'C:\Users\MLoong\Desktop\22\采购表.xlsx')
#合并原工作簿中各工作表的数据
table=pd.DataFrame() #创建一个空的DataFrame
for i,j in enumerate(workbook.sheets) :
values=j.range('A1').options(pd.DataFrame,header=1,index=False,expand='table').value
data=values.reindex(columns=['采购物品','采购日期','采购数量','采购金额']) #调整列的顺序
table=table.append(data,ignore_index=True)
#新建表,并写入数据
table=table.groupby('采购物品')
new_workbook=app.books.add()
for idx,group in table: #遍历筛选好的数据,其中idx对应物品名称,group对应物品的明细数据
new_worksheet=new_workbook.sheets.add(idx)
new_worksheet['A1'].options(index=False).value=group
#对分表进行求和,放在右下角最后一个位置
last_cell= new_worksheet['A1'].expand().last_cell #获取当前工作表数据区域右下角单元格
last_row=last_cell.row #获取当前工作表数据区域最后一行
last_column=last_cell.column #获取当前工作表数据区域最后一列
last_column_letter=chr(64+last_column) #根据最后一列,装换成字母列标
sum_cell_name='{}{}'.format(last_column_letter,last_row+1)
sum_last_row_name='{}{}'.format(last_column_letter,last_row)
formula='=sum({}2:{})'.format(last_column_letter,sum_last_row_name)
new_worksheet[sum_cell_name]. formula= formula
new_worksheet.autofit()
new_workbook.save(r'C:\Users\MLoong\Desktop\22\采购分类表.xlsx')
new_workbook.close()
workbook.close()
app.quit()
举一反三 在一个工作簿中筛选单一类别数据
- 代码文件:在一个工作簿中筛选单一类别数据.py
- 数据文件:采购表.xlsx
如果要筛选的只是某一种物品的明细数据,如 ” 保险箱 “,那么代码会更简单,具体如下。
import xlwings as xw
import pandas as pd
app=xw.App(visible=True,add_book=False)
workbook=app.books.open(r'C:\Users\Administrator\Desktop\22\采购表.xlsx')
table=pd.DataFrame() #创建一个新的DataFrame
for i,j in enumerate(workbook.sheets):
values=j.range('A1').options(pd.DataFrame,header=1,index=False,expand='table').value
data=values.reindex(columns=['采购物品','采购日期','采购数量','采购金额'])
table=table.append(data,ignore_index=True) #ignore_index=True是序号进行累加的意思
product=table[table['采购物品']=='保险箱'] #筛选"采购物品"是"保险箱"的数据
new_workbook=xw.books.add()
new_worksheet=new_workbook.sheets.add('保险箱')
new_worksheet['A1'].options(index=False).value=product
new_worksheet.autofit()
new_workbook.save(r'C:\Users\Administrator\Desktop\22\保险箱.xlsx')
new_workbook.close()
workbook.close()
app.quit()
案例03 对多个工作簿中的工作表分别进行分类汇总
- 代码文件:对多个工作簿中的工作表分别进行分类汇总.py
- 数据文件:销售表(文件夹)
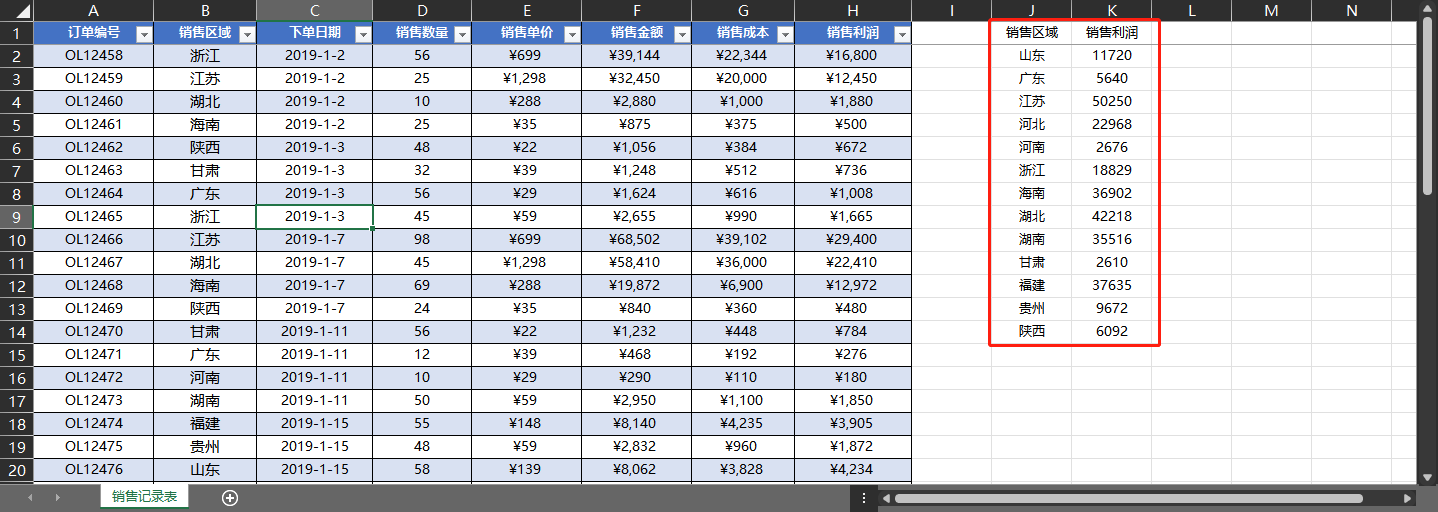
import os
import xlwings as xw
import pandas as pd
app=xw.App(visible=True,add_book=False)
file_path=r'C:\Users\Administrator\Desktop\22\03\销售表'
file_list=os.listdir(file_path)
for i in file_list:
if os.path.splitext(i)[1]=='.xlsx':
workbook=app.books.open(file_path+'//'+i)
for j in workbook.sheets:
values=j.range('A1').expand().options(pd.DataFrame).value
values['销售利润']=values['销售利润'].astype('float') #转换'销售利润'列的数据类型
result=values.groupby('销售区域').sum()
j.range('J1').value=result['销售利润']
workbook.save()
workbook.close()
app.quit()
知识延伸
-
第13 行代码中的astype()是pandas 模块中DataFrame对象的函数,用于转换指定列的数据类型。该函数的语法格式和常用参数含义如下。
-
第14 行代码中groupby()函数后接的sum()函数用于进行求和汇总,还可以使用其他函数完成其他类型的汇总运算。常用的有:用mean()函数求平均值,用count()函数统计个数,用max()函数求最大值,用min()函数求最小值。
举一反三 批量分类汇总多个工作簿中的指定工作表
- 代码文件:批量分类汇总多个工作簿中的指定工作表.py
- 数据文件:销售表1 (文件夹)
如果只想分类汇总多个工作簿中的指定工作表,可以对案例 03的代码进行修改,修改后的代码如下。
import os
import xlwings as xw
import pandas as pd
app=xw.App(visible=True,add_book=False)
file_path=r'C:\Users\Administrator\Desktop\22\03\销售表1'
file_list=os.listdir(file_path)
for i in file_list:
if os.path.splitext(i)[1]=='.xlsx':
workbook=app.books.open(file_path+'//'+i)
worksheet=workbook.sheets['销售记录表']
values=worksheet.range('A1').expand().options(pd.DataFrame).value
values['销售利润']=values['销售利润'].astype('float') #转换'销售利润'列的数据类型
result=values.groupby('销售区域').sum()
worksheet.range('J1').value=result['销售利润']
workbook.save()
workbook.close()
app.quit()
举一反三 将多个工作簿数据分类汇总到一个工作簿
- 代码文件:将多个工作簿数据分类汇总到一个工作簿.py
- 数据文件:销售表(文件夹)
如果想要将多个工作簿中的数据分类汇总到一个工作簿中,可以使用以下代码。
import os
import xlwings as xw
import pandas as pd
app=xw.App(visible=True,add_book=False)
file_path=r'C:\Users\Administrator\Desktop\22\03\销售表'
file_list=os.listdir(file_path)
collection=[]
for i in file_list:
if os.path.splitext(i)[1]=='.xlsx':
workbook=app.books.open(file_path+'//'+i)
worksheet=workbook.sheets['销售记录表']
values=worksheet.range('A1').expand().options(pd.DataFrame).value
filtered=values[['销售区域','销售利润']]
collection.append(filtered)
workbook.close()
new_values=pd.concat(collection,ignore_index=False).set_index('销售区域')
values['销售利润']=values['销售利润'].astype('float') #转换'销售利润'列的数据类型
result=new_values.groupby('销售区域').sum()
new_workbook=app.books.add()
new_worksheet=new_workbook.sheets.add('汇总表')
new_worksheet.range('A1').value=result
new_worksheet.autofit()
new_workbook.save(r'C:\Users\Administrator\Desktop\22\03\销售汇总表.xlsx')
new_workbook.close()
app.quit()
案例04 对一个工作簿中的所有工作表分别求和
- 代码文件:对一个工作簿中的所有工作表分别求和.py
- 数据文件:采购表.xlsx
import os
import xlwings as xw
import pandas as pd
app=xw.App(visible=True,add_book=False)
workbook=app.books.open(r'C:\Users\Administrator\Desktop\22\采购表.xlsx')
for i in workbook.sheets:
values=i.range('A1').expand()
data=values.options(pd.DataFrame).value
sums=data['采购金额'].sum()
column=values.value[0].index('采购金额')+1
row=values.shape[0]
i.range(row+1,column).value=sums
workbook.save()
workbook.close()
app.quit()
知识延伸
-
第10 行代码中的index()是Python中列表对象的函数,常用于在列表中查找某个元素的索引位置。该函数的语法格式和常用参数含义如下。
-
第11 行代码中的shape 是pandas 模块中DataFrame对象的一个属性,它返回的是一个元组,其中有两个元素,分别代表DataFrame的行数和列数。
举一反三 对一个工作簿中的所有工作表分别求和并将求和结果写入固定单元格
- 代码文件:对一个工作簿中的所有工作表分别求和并将求和结果写入固定单元格.py
- 数据文件:采购表.xlsx
如果想要将工作簿中每个工作表的求和结果写入固定的单元格中,可以通过以下代码实现。
import os
import xlwings as xw
import pandas as pd
app=xw.App(visible=True,add_book=False)
workbook=app.books.open(r'C:\Users\Administrator\Desktop\22\采购表.xlsx')
for i in workbook.sheets:
values=i.range('A1').expand().options(pd.DataFrame).value
sums=values['采购金额'].sum()
i.range('F1').value=sums #将求和后的内容写到F1单元格中
workbook.save()
workbook.close()
app.quit()
案例05 批量统计工作簿的最大值和最小值
- 代码文件:批量统计工作簿的最大值和最小值.py
- 数据文件:产品销售统计表(文件夹)

import os
import xlwings as xw
import pandas as pd
app=xw.App(visible=True,add_book=False)
file_path=r'C:\Users\Administrator\Desktop\22\产品销售统计表'
file_list=os.listdir(file_path)
for j in file_list:
if os.path.splitext(j)[1]=='.xlsx':
file_paths=os.path.join(file_path,j)
workbook=app.books.open(file_paths)
for i in workbook.sheets:
values=i.range('A1').expand().options(pd.DataFrame).value
max0=values['销售利润'].max()
min0=values['销售利润'].min()
i.range('I1').value='最大销售利润'
i.range('J1').value=max0
i.range('I2').value='最小销售利润'
i.range('J2').value=min0
i.autofit()
workbook.save()
workbook.close()
app.quit()
知识延伸
除了 sum() 、 mean() 、 count() 、 max() 、 min()等函数,还可以用value_counts() 函数统计重复值的个数,用 product()函数计算乘积,用std() 函数计算标准差,等等。
举一反三 批量统计一个工作簿中所有工作表的最大值和最小值
- 代码文件:批量统计一个工作簿中所有工作表的最大值和最小值.py
- 数据文件:产品销售统计表.xlsx
如果只想统计一个工作簿中所有工作表的最大值和最小值,可以通过以下代码来实现。
import xlwings as xw
import pandas as pd
app=xw.App(visible=True,add_book=False)
workbook=app.books.open(r'C:\Users\Administrator\Desktop\22\产品销售统计表.xlsx')
for i in workbook.sheets:
values=i.range('A1').expand().options(pd.DataFrame).value
max0=values['销售利润'].max()
min0=values['销售利润'].min()
i.range('I3').value='最大销售利润'
i.range('J3').value=max0
i.range('I4').value='最小销售利润'
i.range('J4').value=min0
i.autofit()
workbook.save()
workbook.close()
app.quit()
案例06 批量制作数据透视表
- 代码文件:批量制作数据透视表.py
- 数据文件:商品销售表(文件夹)
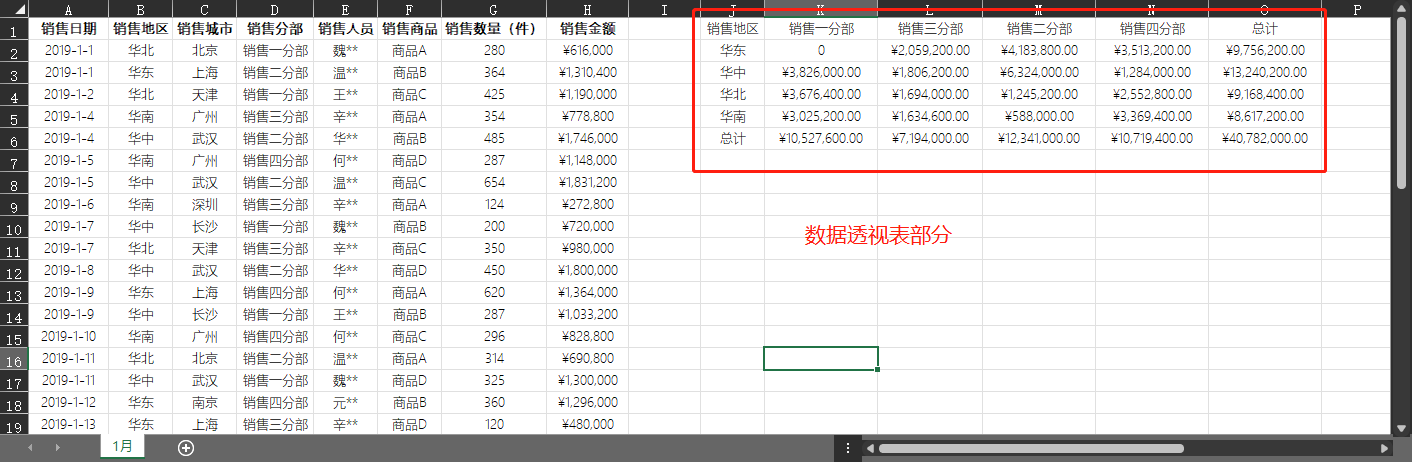
import os
import xlwings as xw
import pandas as pd
app=xw.App(visible=True,add_book=False)
file_path=r'C:\Users\Administrator\Desktop\22\商品销售表'
file_list=os.listdir(file_path)
for i in file_list:
if os.path.splitext(i)[1]=='.xlsx':
workbook=app.books.open(file_path+'\\'+i)
for j in workbook.sheets:
values=j.range('A1').expand().options(pd.DataFrame).value
pivottable=pd.pivot_table(values,values='销售金额' #汇总字段为销售金额
,index='销售地区' #指定行字段为销售地区
,columns='销售分部' #列字段为销售分部
,aggfunc='sum' #汇总计算方式为求和
,fill_value=0 #缺失值填充0
,margins=True #显示汇总行列
,margins_name='总计' #数据行的名称
)
j.range('J1').value=pivottable
j.autofit()
workbook.save()
workbook.close()
app.quit()
知识延伸
第 13 行代码中的 pivot_table() 是 pandas模块中的函数,用于创建一个电子表格样式的数据透视表。该函数的语法格式和常用参数含义如下。
pivot_table(data,values=None,index=None,columns=None,aggfunc=’mean’,fill_value=None,margins=False,dropna=True,margins_name=’All’)

举一反三 为一个工作簿的所有工作表制作数据透视表
- 代码文件:为一个工作簿的所有工作表制作数据透视表.py
- 数据文件:商品销售表.xlsx
如果要一次性为一个工作簿中的所有工作表分别制作数据透视表,可通过以下代码来实现。
import os
import xlwings as xw
import pandas as pd
app=xw.App(visible=True,add_book=False)
workbook=app.books.open(r'C:\Users\Administrator\Desktop\22\商品销售表.xlsx')
for i in workbook.sheets:
values=i.range('A1').expand().options(pd.DataFrame).value
pivottable=pd.pivot_table(values,values='销售金额' #汇总字段为销售金额
,index='销售地区' #指定行字段为销售地区
,columns='销售分部' #列字段为销售分部
,aggfunc='sum' #汇总计算方式为求和
,fill_value=0 #缺失值填充0
,margins=True #显示汇总行列
,margins_name='总计' #数据行的名称
)
i.range('J1').value=pivottable
i.autofit()
workbook.save()
workbook.close()
app.quit()
案例07 使用相关系数判断数据的相关性
- 代码文件:使用相关系数判断数据的相关性.py
- 数据文件:相关性分析.xlsx
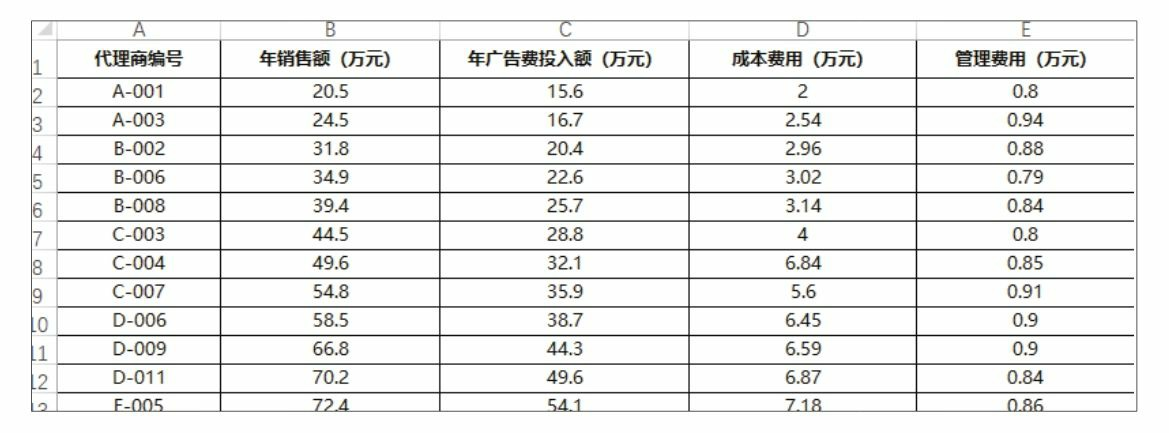
下图为某个计算机软件公司部分代理商的年销售额、年广告费投入额、成本费用、管理费用等数据,根据这些数据你能判断出该公司的产品年销售额与哪些费用的相关性较大吗?
import pandas as pd
df=pd.read_excel(r'C:\Users\Administrator\Desktop\22\相关性分析.xlsx',index_col='代理商编号')
result=df.corr()
print(result)
运行结果
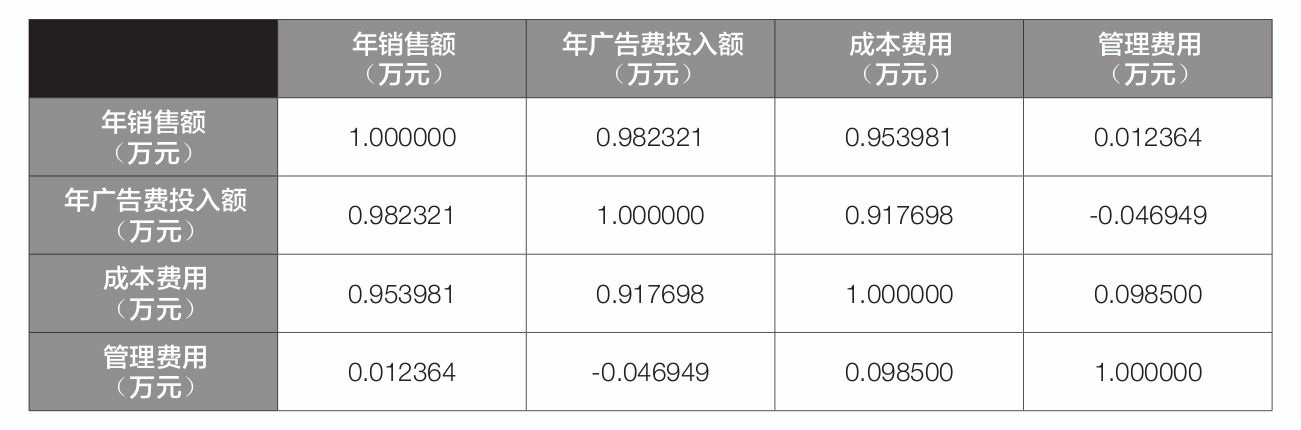
* 上表中第1 行第2 列的数值0.982321,表示的就是年销售额与年广告费投入额的皮尔逊相关系数,其余单元格中数值的含义依此类推。需要说明的是,上表中从左上角至右下角的对角线上的数值都为1 ,这个1其实没有什么实际意义,因为它表示的是变量自身与自身的皮尔逊相关系数,自然是1 。
* 从上表可以看到,年销售额与年广告费投入额、成本费用之间的皮尔逊相关系数均接近1,而与管理费用之间的皮尔逊相关系数接近0,说明年销售额与年广告费投入额、成本费用之间均存在较强的线性正相关性,而与管理费用之间基本不存在线性相关性。前面通过直接观察法得出的结论是比较准确的。
知识延伸
- 第2 行代码中的read_excel()是pandas模块中的函数,用于读取工作簿数据。3.5.2节曾简单介绍过这个函数,这里再详细介绍一下它的语法格式和常用参数的含义。
- read_excel(io,sheet_name=0,header=0,names=None,index_col=None,usecols=None,squeeze=False,dtype=None)

- 第3 行代码中的corr()是pandas 模块中DataFrame对象自带的一个函数,用于计算列与列之间的相关系数。该函数的语法格式和常用参数含义如下。

举一反三 求单个变量和其他变量间的相关性
- 代码文件:求单个变量和其他变量间的相关性.py
- 数据文件:相关性分析.xlsx
如果想要判断某个变量与其他变量之间的相关性,可以在 corr()函数后加上要判断的变量所在的列名,具体代码如下。
import pandas as pd
df=pd.read_excel(r'C:\Users\Administrator\Desktop\22\相关性分析.xlsx',index_col='代理商编号')
result=df.corr()['年销售额(万元)']
print(result)
得出以下结果:
年销售额(万元) 1.000000
年广告费投入额(万元) 0.982321
成本费用(万元) 0.953981
管理费用(万元) 0.012364
Name: 年销售额(万元), dtype: float64
案例08 使用方差分析对比数据的差异
- 代码文件:使用方差分析对比数据的差异.py
- 数据文件:方差分析.xlsx
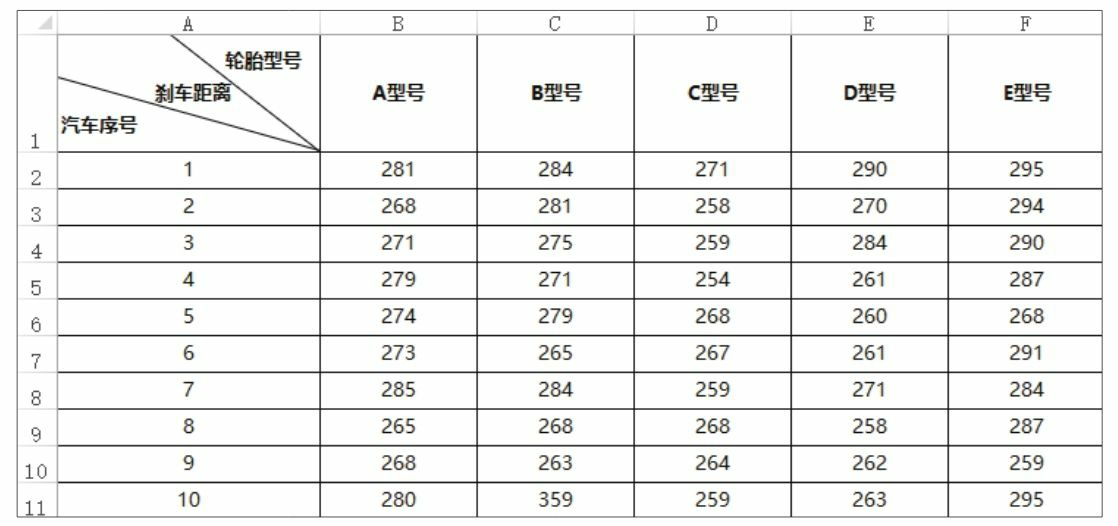
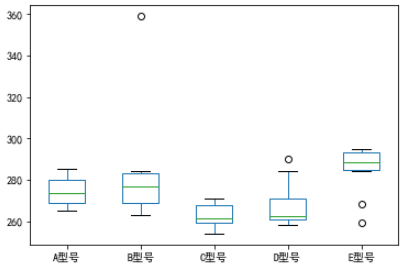
某轮胎生产厂设计生产了5种型号的轮胎,现在要检验这些轮胎在平均刹车距离方面是否有显著差异,作为轮胎定价的参考依据。该厂选择了 50 辆相同的汽车,并为这 5 种型号的轮胎各随机选取了10辆汽车,以相同的速度进行试驾测试,得到如下图所示的刹车距离数据。你能通过分析这些数据判断不同型号轮胎的刹车距离是否存在显著差异吗?
import pandas as pd
from statsmodels.formula.api import ols #导入方差分析的模块
from statsmodels.stats.anova import anova_lm
import xlwings as xw
df=pd.read_excel(r'C:\Users\Administrator\Desktop\22\方差分析.xlsx')
df=df[['A型号','B型号','C型号','D型号','E型号']] #选取ABCDE的型号的列作为分析
df_melt=df.melt() #将列名转换成列数据
df_melt.columns=['Treat','Value'] #重命名列名
df_describe=pd.DataFrame()
df_describe['A型号']=df['A型号'].describe() #计算A型号的平均值、最大值、最小值
df_describe['B型号']=df['B型号'].describe() #计算A型号的平均值、最大值、最小值
df_describe['C型号']=df['C型号'].describe() #计算A型号的平均值、最大值、最小值
df_describe['D型号']=df['D型号'].describe() #计算A型号的平均值、最大值、最小值
df_describe['E型号']=df['E型号'].describe() #计算A型号的平均值、最大值、最小值
print(df_describe)
model=ols('Value~C(Treat)',data=df_melt).fit() #对样本数据进行最小二乘现行拟合计算
anova_table=anova_lm(model,typ=3) #对样本进行方差分析
print(model)
print(anova_table)
app=xw.App(visible=True,add_book=False)
workbook=app.books.open(r'C:\Users\Administrator\Desktop\22\方差分析.xlsx')
worksheet=workbook.sheets['单因素方差分析'] #选中工作表'单因素方差分析'
worksheet.range('H2').value=df_describe.T #将计算出的平均值、最小值、最大值等数据xieru
worksheet.range('H14').value='方差分析'
worksheet.range('H15').value=anova_table #将方差分析的结果写入工作表
workbook.save()
workbook.close()
app.quit()
上述代码的运行结果如下图所示。我们需要关心单元格 L17中的数值,它相当于用 Excel 的单因素方差分析功能计算出的 P-value,代表观测到的显著性水平。通常情况下,该值 ≤0.01表示有极显著的差异,该值在 0.01 ~ 0.05 之间表示有显著差异,该值 ≥0.05表示没有显著差异。这里的 P-value 为 0.00674≤0.01 ,说明5种型号轮胎的平均刹车距离有极显著的差异,该厂可以据此采取这样的定价策略:平均刹车距离越短的型号定价越高。
知识延伸
- 第7 行代码中的melt()是pandas 模块中DataFrame对象的函数,用于将列名转换为列数据,效果如下图所示,以满足后续使用的ols()函数对数据结构的要求。
melt() 函数的语法格式和常用参数含义如下。
melt(id_vars=None,value_vars=None,var_name=None,value_name=’value’,col_level=None)
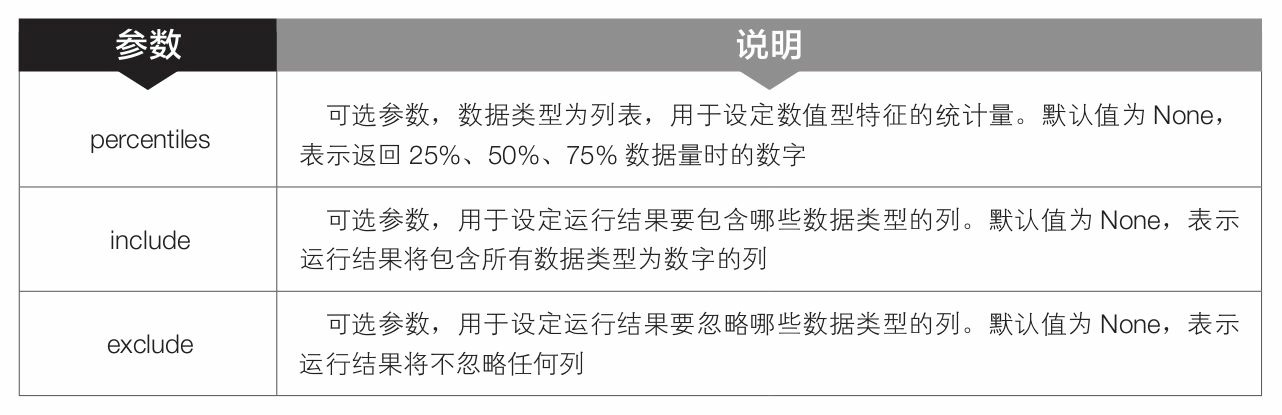
- 第10 ~14 行代码中的describe()是pandas 模块中DataFrame对象的函数,用于总结数据集分布的集中趋势,生成描述性统计数据。该函数的语法格式和常用参数含义如下。
DataFrame.describe(percentiles=None,include=None,exclude=None)
ols(formula,data)

- 第16 行代码中的anova_lm()是statsmodels.stats.anova 模块中的函数,用于对数据进行方差分析并输出结果。该函数的语法格式和常用参数含义如下。
anova_lm(args,scale,test,typ,robust)

举一反三 绘制箱形图识别异常值
- 代码文件:绘制箱形图识别异常值.py
- 数据文件:方差分析.xlsx
如果想要用图表来观察数据的离散分布情况并识别异常值,可以使用 Python 绘制箱形图,具体代码如下。
import pandas as pd
import matplotlib.pyplot as plt
from statsmodels.formula.api import ols #导入方差分析的模块
from statsmodels.stats.anova import anova_lm
import xlwings as xw
df=pd.read_excel(r'C:\Users\Administrator\Desktop\22\方差分析.xlsx')
df=df[['A型号','B型号','C型号','D型号','E型号']] #选取ABCDE的型号的列作为分析
figure=plt.figure()
plt.rcParams['font.sans-serif']=['SimHei']
df.boxplot(grid=False)
app=xw.App(visible=True,add_book=False)
workbook=app.books.open(r'C:\Users\Administrator\Desktop\22\方差分析.xlsx')
worksheet=workbook.sheets['单因素方差分析'] #选中工作表'单因素方差分析'
worksheet.pictures.add(figure,name='图片1',update=True,left=500,top=10)
workbook.save('箱型图.xlsx')
workbook.close()
app.quit()
案例09 使用描述统计和直方图制定目标
- 代码文件:使用描述统计和直方图制定目标.py
- 数据文件:描述统计.xlsx
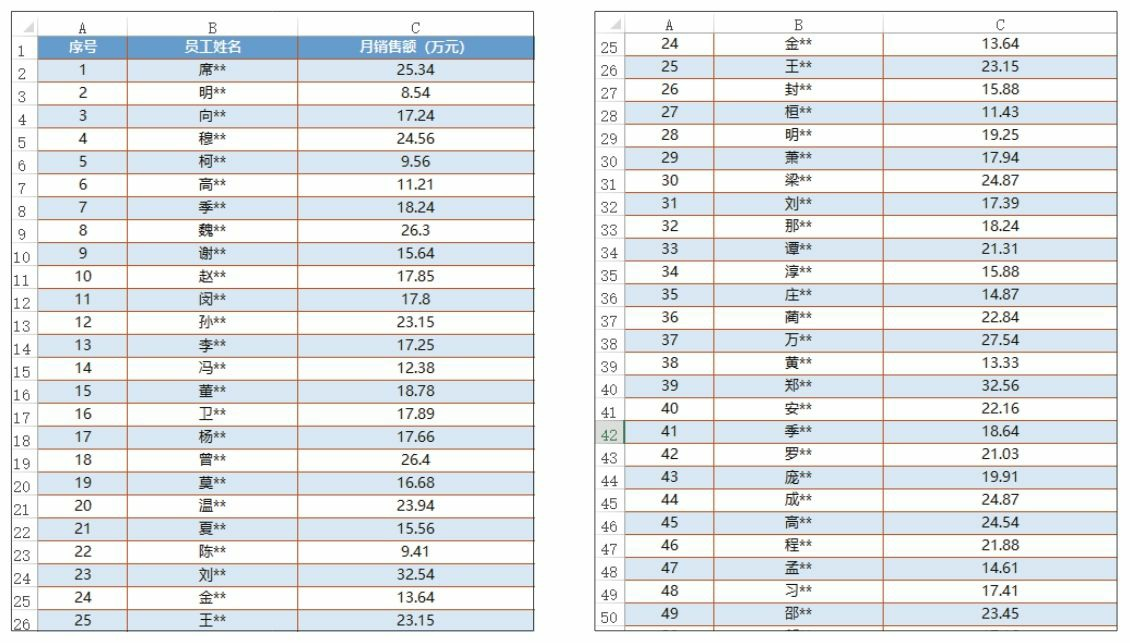
某财产保险公司要对保险业务员实行目标管理,并根据目标完成情况建立相应的奖惩制度。下图所示为从该公司的几百名业务员中随机抽取的 50人的月销售额数据。如果你是该公司的业务主管,你会如何确定业务员的具体销售目标呢?
如果销售目标定得太高,就会有很多人完不成任务,从而失去工作的信心;如果销售目标定得过低,又不利于挖掘业务员的潜力。但是我发现,有很大一部分业务员的月销售额都在一定的区间内徘徊。因此, 可以运用Excel中的描述统计工具获取各业务员月销售额的平均数、中位数、众数、标准差等指标,从而估算出销售目标。此外,还可以对销售数据进行分组,并绘制直方图来直观地展示数据。
import pandas as pd
import matplotlib.pyplot as plt
import xlwings as xw
#构造月销售额数据列
df=pd.read_excel(r'C:\Users\Administrator\Desktop\22\描述统计.xlsx')
df.columns=['序号','员工姓名','月销售额'] #重命名数据列
df=df.drop(columns=['序号','员工姓名']) #删除序号和员工姓名列
df_describe=df.astype('float').describe() #对月销售额数据进行描述性统计
df_cut=pd.cut(df['月销售额'],bins=7,precision=2) #将月销售额分成7个区间
cut_count=df['月销售额'].groupby(df_cut).count() #统计各区间的个数
df_all=pd.DataFrame() #创建一个空的DateFrame用于汇总数据
df_all['计数']=cut_count
df_all_new=df_all.reset_index() #将索引重置
df_all_new['月销售额']=df_all_new['月销售额'].apply(lambda x:str(x)) #将月销售额转换成字符串类型
#绘图
fig=plt.figure() #创建绘图窗口
plt.rcParams['font.sans-serif']=['SimHei'] #解决中文乱码问题
n,bins,patches=plt.hist(df['月销售额'],bins=7,edgecolor='black',linewidth=0.5)
plt.xticks(bins) #将直方图x轴的刻度标签设置为各区间的端点值
plt.title('月度销售额频率分析') #标题
plt.xlabel('月销售额') #x轴标题
plt.ylabel('频数') #y轴标题
#将图放进表里
app=xw.App(visible=True,add_book=False)
workbook=app.books.open(r'C:\Users\Administrator\Desktop\22\描述统计.xlsx')
worksheet=workbook.sheets['业务员销售额统计表'] #选中工作表'单因素方差分析'
worksheet.range('E2').value=df_describe #将描述性统计数据写入表中
worksheet.range('H2').value=df_all_new #将分类后的表写入表中
worksheet.pictures.add(fig,name='图片1',update=True,left=400,top=200)
worksheet.autofit()
workbook.save(r'C:\Users\Administrator\Desktop\22\描述统计-直方图.xlsx')
workbook.close()
app.quit()
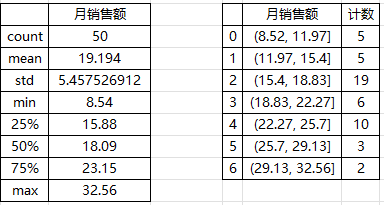
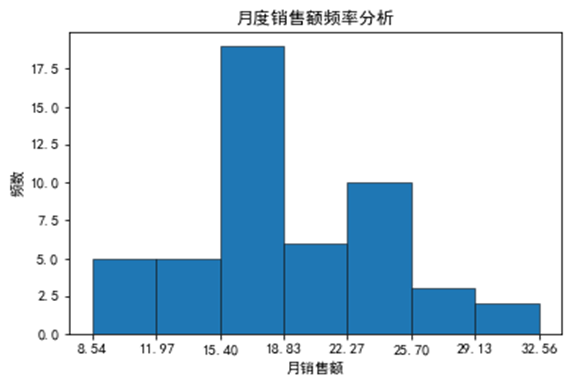
描述统计数据中几个比较重要的值分别为平均值(mean )19.194、标准差(std )5.46、中位数(50%)18.09 、最小值8.54 、最大值32.56。 在工作簿中还可以看到如下图所示的直方图,根据直方图可以看出,月销售额基本上以18 为基数向两边递减,即18 最普遍。
综合考虑上面的描述统计数据及直方图的分布情况,并适当增加目标的挑战性,将月销售额的目标(万元)定在 18 ~ 20之间是比较合理的,大多数人应该能够完成。
知识延伸
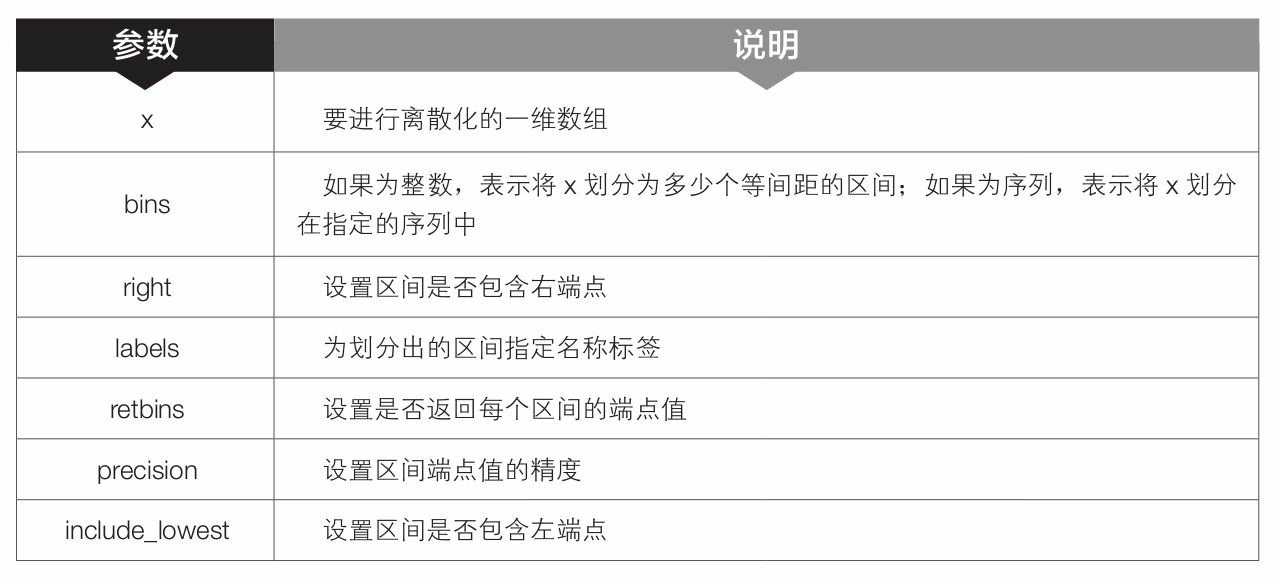
- 第8 行代码中的cut()是pandas模块中的函数,用于对数据进行离散化处理,也就是将数据从最大值到最小值进行等距划分。该函数的语法格式和常用参数含义如下。
cut(x,bins,right=True,labels=None,retbins=False,precision=3,include_lowest=False)
df_cut=pd.cut(df['月销售额'],bins=7,precision=2)
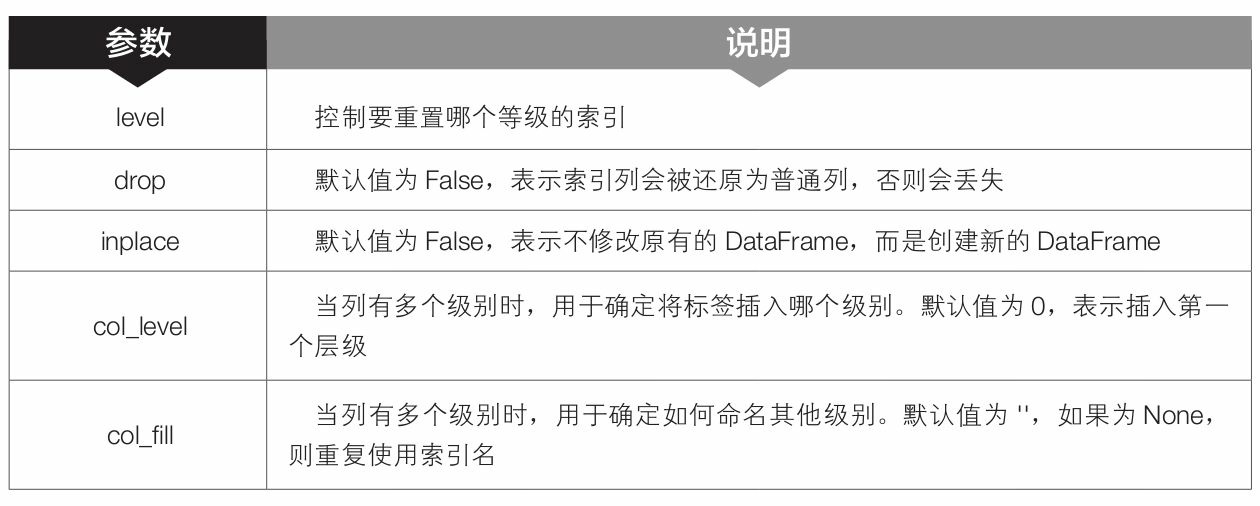
- 第12 行代码中的reset_index()是pandas 模块中DataFrame对象的函数,用于重置DataFrame 对象的索引。在3.5.1节中曾简单介绍过reset_index()函数的用法,这里再详细介绍一下该函数的语法格式和常用参数含义。
DataFrame.reset_index(level=None,drop=False,inplace=False,col_level=0,col_fill=”)
df_all_new=df_all.reset_index() #将索引重置
- 第14 行代码中的figure()是matplotlib.pyplot模块中的函数,用于创建一个绘图窗口。在3.7.2 节中曾使用过figure()函数,这里再详细介绍一下该函数的语法格式和常用参数含义。
figure(num=None,figsize=None,dpi=None,facecolor=None,edgecolor=None,frameon=True,clear=False)
- 第16 行代码中的hist()是Matplotlib模块中的函数,用于绘制直方图。该函数的语法格式和常用参数含义如下。
hist(x,bins=None,range=None,density=False,color=None,edgecolor=None,linewidth=None)
n,bins,patches=plt.hist(df['月销售额'],bins=7,edgecolor='black',linewidth=0.5)

举一反三 使用自定义区间绘制直方图
- 代码文件:使用自定义区间绘制直方图.py
- 数据文件:描述统计.xlsx
案例 09的代码通过指定区间的数量对数据进行均匀分组,区间的端点值是自动计算出来的,如果要指定区间的端点值,可将 cut() 和 hist()函数的参数 bins 设置为序列形式,具体代码如下。
import pandas as pd
import matplotlib.pyplot as plt
import xlwings as xw
#构造月销售额数据列
df=pd.read_excel(r'C:\Users\Administrator\Desktop\22\描述统计.xlsx')
df.columns=['序号','员工姓名','月销售额'] #重命名数据列
df=df.drop(columns=['序号','员工姓名']) #删除序号和员工姓名列
df_describe=df.astype('float').describe() #对月销售额数据进行描述性统计
df_cut=pd.cut(df['月销售额'],bins=range(8,37,4)) #将月销售额分成7个区间
cut_count=df['月销售额'].groupby(df_cut).count() #统计各区间的个数
df_all=pd.DataFrame() #创建一个空的DateFrame用于汇总数据
df_all['计数']=cut_count
df_all_new=df_all.reset_index() #将索引重置
df_all_new['月销售额']=df_all_new['月销售额'].apply(lambda x:str(x)) #将月销售额转换成字符串类型
#绘图
fig=plt.figure() #创建绘图窗口
plt.rcParams['font.sans-serif']=['SimHei'] #解决中文乱码问题
n,bins,patches=plt.hist(df['月销售额'],bins=range(8,37,4),edgecolor='black',linewidth=0.5)
plt.xticks(bins) #将直方图x轴的刻度标签设置为各区间的端点值
plt.title('月度销售额频率分析') #标题
plt.xlabel('月销售额') #x轴标题
plt.ylabel('频数') #y轴标题
#将图放进表里
app=xw.App(visible=True,add_book=False)
workbook=app.books.open(r'C:\Users\Administrator\Desktop\22\描述统计.xlsx')
worksheet=workbook.sheets['业务员销售额统计表'] #选中工作表'单因素方差分析'
worksheet.range('E2').value=df_describe #将描述性统计数据写入表中
worksheet.range('H2').value=df_all_new #将分类后的表写入表中
worksheet.pictures.add(fig,name='图片1',update=True,left=400,top=200)
worksheet.autofit()
workbook.save(r'C:\Users\Administrator\Desktop\22\描述统计-直方图2.xlsx')
workbook.close()
app.quit()
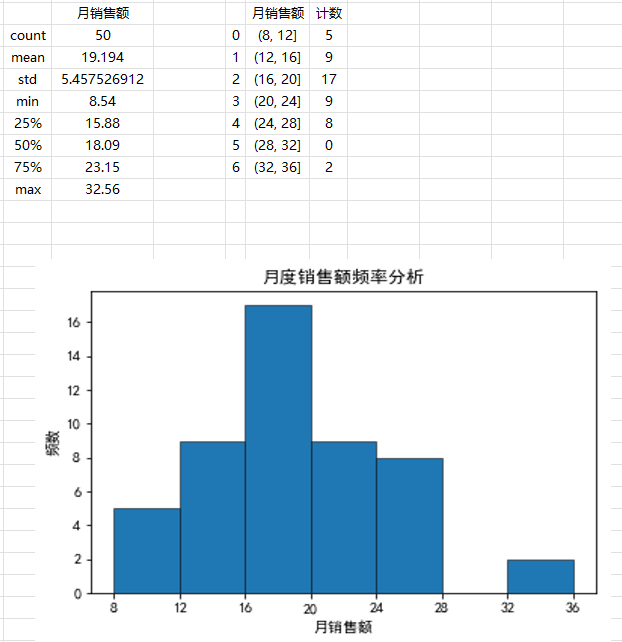
第 8 行和第 16 行代码将 cut() 和 hist() 函数的参数 bins设置为range(8,37,4) ,它代表的是一个等差整数序列 8 、 12 、 16 、 20 、 24 、 28、32 、 36 ,因此,运行上述代码后,打开生成的工作簿 ” 描述统计 2.xlsx”,可以看到如下图所示的分组统计数据和直方图。需要注意的是,因为 range() 函数具有 ” 左闭右开 ” 的特性,所以这里将终止值(第2个参数)设置得比 36 大一些,否则生成的序列只到 32为止,这样会导致无法将最大值 32.56 统计在内。
案例10 使用回归分析预测未来值
- 代码文件:使用回归分析预测未来值.py
- 数据文件:回归分析.xlsx
下图为某公司 2019年每月的汽车销售额和在两种渠道投入的广告费,如果现在需要根据广告费来预测销售额,你会怎么做呢?
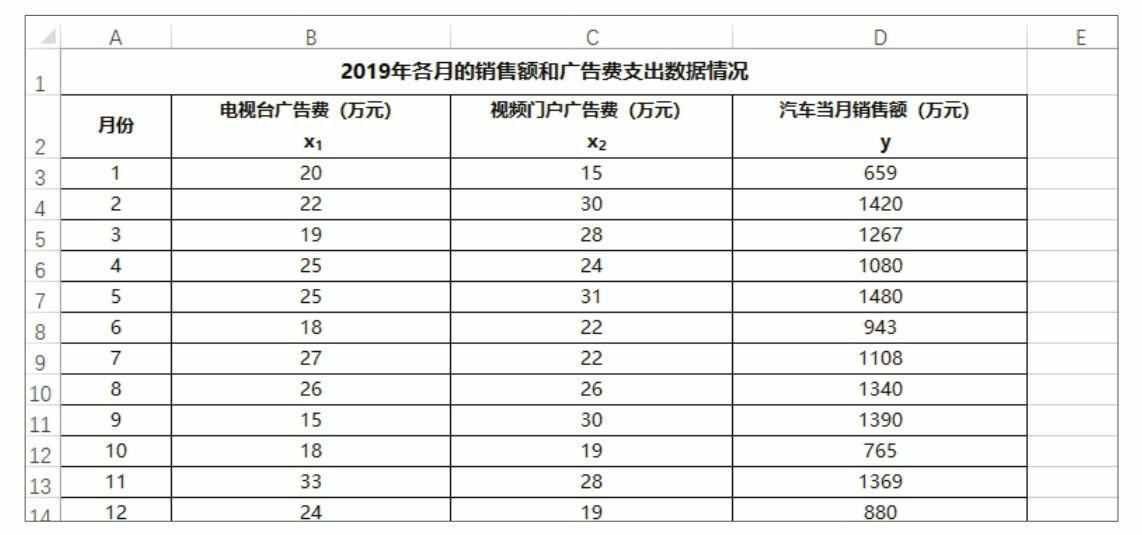
要判断方程是否可靠,需要通过计算 R2值来判断方程的拟合程度。在 Python 中,使用 sklearn 模块的 LinearRegression() 函数可以快速拟合出 线性回归方程,使用 score() 函数可以计算 R2值。下面就来看看如何在拟合出方程后计算 R2 值。
import pandas as pd
from sklearn import linear_model
df=pd.read_excel(r'C:\Users\Administrator\Desktop\22\回归分析.xlsx')
df=df[1:] #删除第一行
df.columns=['月份','电视台广告费','视频门户广告费','汽车当月销售额'] #重命名
#获取'电视台广告费','视频门户广告费'最为自变量
x=df[['电视台广告费','视频门户广告费']]
y=df['汽车当月销售额']
model=linear_model.LinearRegression()
model.fit(x,y)
R2=model.score(x,y)
R2
R2 值的取值范围为 0 ~ 1 ,越接近 1,说明方程的拟合程度越高。这里计算出的 R2 值0.972726比较接近 1,说明方程的拟合程度较高,可以用此方程来进行预测。
知识延伸
第 8 行代码中的 LinearRegression() 是 sklearn模块中的函数,用于创建一个线性回归模型。该函数的语法格式和常用参数含义如下。 LinearRegression(fit_intercept=True,normalize=False,copy_X=True,n_jobs=1)

第 10 行代码中的 score() 是 sklearn模块中的函数,用于计算回归模型的 R2 值。该函数的语法格式为 score(x,y,sample_weight=None)
举一反三 使用回归方程计算预测值
- 代码文件:使用回归方程计算预测值.py
- 数据文件:回归分析.xlsx
前面通过计算 R 2值知道了方程的拟合程度较高,接着就可以利用这个方程来进行预测。假设某月在电视台和视频门户分别投入了 20万元和30 万元广告费,要预测该月的汽车销售额,可以通过以下代码来实现。
import pandas as pd
from sklearn import linear_model
df=pd.read_excel(r'C:\Users\Administrator\Desktop\22\回归分析.xlsx')
df=df[1:] #删除第一行
df.columns=['月份','电视台广告费','视频门户广告费','汽车当月销售额'] #重命名
#获取'电视台广告费','视频门户广告费'最为自变量
x=df[['电视台广告费','视频门户广告费']]
y=df['汽车当月销售额']
model=linear_model.LinearRegression()
model.fit(x,y)
coef=model.coef_ #获取自变量系数
model_intercept=model.intercept_ #获取截距
result='y={}+({})x1+({})x2'.format(coef[0],coef[1],model_intercept)
print('线性回归的方程为:','\n',result)
a=20 #设置电视广告费用
b=30 #设置视频广告费
y=model_intercept+a*coef[0]+b*coef[1]
print('电视广告投放20万,视频门户投放30万,预测汽车的销售额为:','\n',y)
预测结果为:
线性回归的方程为:
y=9.133786669280706+(51.06148377665357)x1+(-316.28885036504175)x2
电视广告投放20万,视频门户投放30万,预测汽车的销售额为:
1398.2313963201796
参考文献 《超简单:用Python让Excel飞起来》
数据下载06:
链接:https://pan.baidu.com/s/1KdI7u72sZIcG_C5Y9AtCJw
提取码:8888
Original: https://blog.csdn.net/Colorfully_lu/article/details/122385033
Author: Colorfully_lu
Title: Python让Excel飞起来—批量进行数据分析
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/695714/
转载文章受原作者版权保护。转载请注明原作者出处!