

这部分主要讲解一下如何使用,需要看原理的小伙伴,可以到我之前的博客:
https://blog.csdn.net/wzk4869/article/details/126379073?spm=1001.2014.3001.5501
这里只介绍用基尼指数来评价的方法:
sklearn已经帮我们封装好了一切,我们 只需要调用其中的函数即可。
一、导入数据集
import pandas as pd
url = 'http://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data'
wine_data = pd.read_csv(url, header = None)
wine_data


我们加入列名:
wine_data.columns = ['Class label', 'Alcohol', 'Malic acid', 'Ash',
'Alcalinity of ash', 'Magnesium', 'Total phenols',
'Flavanoids', 'Nonflavanoid phenols', 'Proanthocyanins',
'Color intensity', 'Hue', 'OD280/OD315 of diluted wines', 'Proline']
wine_data

我们来大致看下这时一个怎么样的数据集:
import numpy as np
np.unique(wine_data['Class label'])
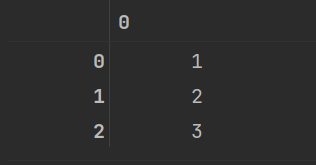
可见我们的数据集只有三个类别。
检查一下数据是否有空数组:
wine_data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 178 entries, 0 to 177
Data columns (total 14 columns):
--- ------ -------------- -----
0 Class label 178 non-null int64
1 Alcohol 178 non-null float64
2 Malic acid 178 non-null float64
3 Ash 178 non-null float64
4 Alcalinity of ash 178 non-null float64
5 Magnesium 178 non-null int64
6 Total phenols 178 non-null float64
7 Flavanoids 178 non-null float64
8 Nonflavanoid phenols 178 non-null float64
9 Proanthocyanins 178 non-null float64
10 Color intensity 178 non-null float64
11 Hue 178 non-null float64
12 OD280/OD315 of diluted wines 178 non-null float64
13 Proline 178 non-null int64
dtypes: float64(11), int64(3)
除去class label之外共有13个特征,数据集的大小为178。常规做法,将数据集分为训练集和测试集。
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
x, y = wine_data.iloc[:, 1:].values, wine_data.iloc[:, 0].values
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.3, random_state = 0)
feat_labels = df.columns[1:]
forest = RandomForestClassifier(n_estimators=10000, random_state=0, n_jobs=-1)
forest.fit(x_train, y_train)
这样一来随机森林就训练好了,其中已经把特征的重要性评估也做好了,我们拿出来看下。
importances = forest.feature_importances_
indices = np.argsort(importances)[::-1]
for f in range(x_train.shape[1]):
print("%2d) %-*s %f" % (f + 1, 30, feat_labels[indices[f]], importances[indices[f]]))
输出的结果为:
1) 10 0.182483
2) 13 0.158610
3) 7 0.150948
4) 12 0.131987
5) 1 0.106589
6) 11 0.078243
7) 6 0.060718
8) 4 0.032033
9) 2 0.025400
10) 9 0.022351
11) 5 0.022078
12) 8 0.014645
13) 3 0.013916
要筛选出重要性比较高的变量的话,这么做就可以:
threshold = 0.15
x_selected = x_train[:, importances > threshold]
x_selected

帮我们选好了三列数据!
Original: https://blog.csdn.net/wzk4869/article/details/126425961
Author: 旅途中的宽~
Title: 利用随机森林对特征重要性进行评估(含实例+代码讲解)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/617803/
转载文章受原作者版权保护。转载请注明原作者出处!