

简介
前阵子和小伙伴做了 2021年华为杯研赛的B题”空气质量预报二次建模”,发现数据预处理一块挺有意思的,涵盖了常规的缺失值(随机缺失、指标缺失/列缺失、条目缺失/行缺失)、异常值(偏离正态分布、非负数据为负),以及不常规的协同处理等,一直想着有机会整理一下。
【注】只想看协同处理部分,即”4. 监测点A、A1、A2、A3数据预处理”的可直接转到:[Python] 反距离权重插值案例及代码_禾木页的博客-CSDN博客
目录
1. 赛题及数据
赛题及数据大家可自行前往”中国研究生创新实践系列大赛管理平台“下载,或者直接在网上搜索。
1.1 竞赛试题
2021年B题题目为”空气质量预报二次建模”,简而言之,核心任务是让你用已有的基于WRF-CMAQ模型得到的 一次预报数据(包含6个污染物浓度指标和15个气象指标),加上提供的 实测数据(6个污染物浓度指标和5个气象指标),在一次预报模型之上,建立一套比它更优的模型,因此叫二次建模。
更优的标准是,使用二次建模预测结果中 “空气质量指数AQI”预报值的最大相对误差应尽量小,且 “首要污染物”他预测准确度尽量高。


1.2 数据集预览
官方提供数据集如下。
附件1 监测点A空气质量预报基础数据
附件2 监测点B、C空气质量预报基础数据
附件3 监测点A1、A2、A3空气质量预报基础数据
从附件名字可以推测数据集的 内部结构应该基本一致,只是监测点不同而已。事实也是如此,因此下面主要概述监测点A的数据,其他同理。
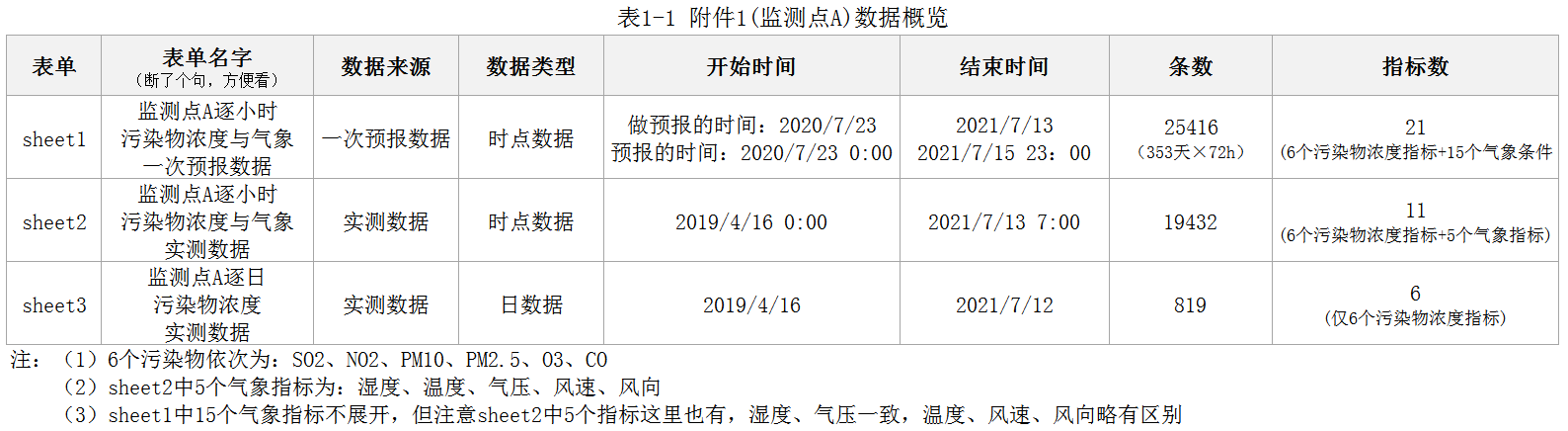
时间那里有点乱,其实不难理解,重点关注”结束时间”就好,大家的结束日期都是2021年7月13日。
怎么理解呢?
首先,题目对时间表达有一个设定,即7:00代表的时点段为7:00-8:00,23:00代表的时间段是23:00-24:00。在此基础上:
(1)sheet1是预报的数据,题目设定是可以往后预报三天(当天+后两天),因此它站在7月13号预测,可以预测到7月15号。
(2)sheet2是实测时数据,题目设定每天预报的时间是早上七点,也就是说在7月13号做预报时, 七点及之前所有真实的数据是可以获取的,因此”实测时数据”截止到7月13号7:00。
◆按道理,”7:00″代表7-8点,那么早上七点预测,”7:00″的数据应该是不可以用的,只能用到6:00(代表6-7点),但是题目自己设定可用,就不给自己增加难度啦~
(3)sheet3是实测日数据,经初步的验证,除O3外(后面会讲),发现”实测日数据≈实测时数据的24h平均”,7月13日时间数据只到早上七点,那它当然没有当天的日数据啦,所以只到7月12号。
- 监测点A数据预处理
数据预处理一般包括缺失值处理和异常值处理。
缺失值处理十分灵活,通常还要考虑数据实际含义;而且缺失值填补结果的优劣对后续的分析也有较大影响,本文大篇幅也是在进行缺失值的处理。
异常值处理相对而言较为简单,一般分两类异常。一是数据形态的异常,可用3西格玛原则处理;二是逻辑异常,比如数据集出现”非负数值为负”的情况;其他情况需根据具体案例判断是否存在异常。
以下数据处理均在Spyder3.7中进行。
import os
import pandas as pd
import numpy as np
#设置工作目录
os.chdir('C:\\Users\...)
os.getcwd()
#导入数据:监测点A的三个数据集
df1A=pd.read_excel("附件1 监测点A空气质量预报基础数据.xlsx","监测点A逐小时污染物浓度与气象一次预报数据")
df2A=pd.read_excel("附件1 监测点A空气质量预报基础数据.xlsx","监测点A逐小时污染物浓度与气象实测数据")
df3A=pd.read_excel("附件1 监测点A空气质量预报基础数据.xlsx","监测点A逐日污染物浓度实测数据")
2.1 监测点A一次预报数据处理
2.1.1 缺失值处理
如果不做实际案例,网上的数据预处理教程往往是通过某命令找到缺失的位置,然后通过一些方法(如均值、众数、随机森林等)填充缺失值。但在这里你会发现,如果直接找缺失值,结果会显示不存在缺失。
由于isnull,any()只识别nan类型的缺失,为防止缺失的类型是null,我们将null转化为nan再查找一次,结果还是显示不存在缺失。
##df1A数据预处理
#查找变量是否存在缺失值
df1A.isnull().any()
#避免缺失的类型是null,将null转化为nan
df1A = df1A.replace('null',np.NaN)
df1A.isnull().any()
Out[1]:
模型运行日期 False
预测时间 False
地点 False
近地2米温度(℃) False
地表温度(K) False
比湿(kg/kg) False
湿度(%) False
近地10米风速(m/s) False
近地10米风向(°) False
雨量(mm) False
云量 False
边界层高度(m) False
大气压(Kpa) False
感热通量(W/m²) False
潜热通量(W/m²) False
长波辐射(W/m²) False
短波辐射(W/m²) False
地面太阳能辐射(W/m²) False
SO2小时平均浓度(μg/m³) False
NO2小时平均浓度(μg/m³) False
PM10小时平均浓度(μg/m³) False
PM2.5小时平均浓度(μg/m³) False
O3小时平均浓度(μg/m³) False
CO小时平均浓度(mg/m³) False
dtype: bool
这就代表数据没有缺失值吗?
答案显然是否定的。数据缺失,不一定是”挖空式”的缺失,比如这份数据,如果是”模拟运行日期”或者”预测时间”的整一条数据缺失,通过上述方法是查找不到的。解决方式:
1、查看每一个”模型运行日期”下,是否有某个小时的缺失。
题目设定:每次模拟可以预测当天+未来两天共3天(72小时)的数据。
对每一个”模型运行日期”进行计数,发现每个”模型运行日期”下均有72条数据,即预测的三天。说明只要进行了预测,就一定会一次性预测三天的,不存在中间某个小时的预测缺失,代码见下文。
2、查看”模型运行时间”是否存在缺失。
方法1:上一步的输出结果的Index就是每一个模型运行日期,可以通过[F.index]逐一查看每个日期。但在这道题中,时间跨度将近一年,这样子看太麻烦了。
方法2:统计每个月份出现的天数,少于正常天数的月份说明那个月有”模型运行日期”的缺失,直接去找那个月份的数据。这里通过绘制”年”和”月”的交叉表,得到月份的情况(详见Out[2]),再根据月份情况查看是哪一天存在缺失(详见Out[3]-Out[5])。
分析
2020年7月份仅9天是因为从2020年7月23号开始的,到7月31日刚好9天,不存在缺失。
2020年11月份存在缺失,经查,为:2020-11-11
2021年1月份存在缺失,经查,为:2021-1-25
2021年5月份存在缺失,经查,为:2021-5-21
2021年7月份截止到7月13日,刚好13天,不存在缺失。
验证 :不放心的话,可以验证一下是否仅有3天缺失。
2020年7月23日-2021年7月13日,共365-9=356天
F中共353条日期数据(或交叉表cross_ym2总和正好为353天[cross_ym2.sum().sum()]),正好缺失3天,分析结果应该无误。
缺失值处理:
一般情况下,都需要对缺失值进行填充,除实际意义外,若数据集中含有缺失值,后面很多命令是会报错的。但在这里我们并不补充缺失值,原因如下:
一是缺失的是整条数据,对后面数据处理不存在影响,只是后续需要合并不同监测点的数据时,不能简单的横向拼接;
二是考虑实际意义,一个”模型运行日期”的缺失代表预测的连续72条时数据的缺失,3个日期就代表3*72=216条数据缺失,不好补,可能也补不好,所以还是不补了。
既然不补,了解缺失值有什么作用呢?
个人看来,了解数据概况是预处理的重要一步,不管作不作处理,都要做到”心中有数”。
##df1A数据预处理
#查看每一个"模型运行日期"下,是否有某个小时的缺失
F=df1A['模型运行日期'].value_counts()
#输出结果:每个日期下均有72条数据(略)
#分析:72条时数据即预测的三天。说明只要进行了模拟,就会一次性模型三天的,不存在中间某个小时的预测缺失
#通过交叉表查看是否有"模型运行日期"的缺失
df1A['年份'] = df1A['模型运行日期'].dt.year #提取"模型运行日期"的年份
df1A['月份'] = df1A['模型运行日期'].dt.month #提取"模拟运行日期"的月份
cross_ym = pd.crosstab(index=df1A['年份'],columns=df1A['月份'],values=df1A['月份'],aggfunc='count')
#由于每个"模型运行日期"对应72条数据,所以还需要除以72
cross_ym2 = cross_ym/72
Out[2]:
月份 1 2 3 4 5 6 7 8 9 10 11 12
年份
2020 NaN NaN NaN NaN NaN NaN 9.0 31.0 30.0 31.0 29.0 31.0
2021 30.0 28.0 31.0 30.0 30.0 30.0 13.0 NaN NaN NaN NaN NaN
#查看是2020-11、2021-1、2021-5中是哪一天缺失
lack1 = df1A[(df1A['年份']==2020) & (df1A['月份']==11)] #提取2020年11月数据
lack1d = lack1['模型运行日期'].value_counts() #统计"模拟运行日期",主要是想要它的index
lack1d.index.sort_values() #.sort_values() 主要为了为日期排个序,方便看
Out[3]:
DatetimeIndex(['2020-11-01', '2020-11-02', '2020-11-03', '2020-11-04',
'2020-11-05', '2020-11-06', '2020-11-07', '2020-11-08',
'2020-11-09', '2020-11-10', '2020-11-12', '2020-11-13',
'2020-11-14', '2020-11-15', '2020-11-16', '2020-11-17',
'2020-11-18', '2020-11-19', '2020-11-20', '2020-11-21',
'2020-11-22', '2020-11-23', '2020-11-24', '2020-11-25',
'2020-11-26', '2020-11-27', '2020-11-28', '2020-11-29',
'2020-11-30'],
dtype='datetime64[ns]', freq=None)
lack2 = df1A[(df1A['年份']==2021) & (df1A['月份']==1)] #提取2021年1月数据
lack2d = lack2['模型运行日期'].value_counts()
lack2d.index.sort_values()
Out[4]:
DatetimeIndex(['2021-01-01', '2021-01-02', '2021-01-03', '2021-01-04',
'2021-01-05', '2021-01-06', '2021-01-07', '2021-01-08',
'2021-01-09', '2021-01-10', '2021-01-11', '2021-01-12',
'2021-01-13', '2021-01-14', '2021-01-15', '2021-01-16',
'2021-01-17', '2021-01-18', '2021-01-19', '2021-01-20',
'2021-01-21', '2021-01-22', '2021-01-23', '2021-01-24',
'2021-01-26', '2021-01-27', '2021-01-28', '2021-01-29',
'2021-01-30', '2021-01-31'],
dtype='datetime64[ns]', freq=None)
lack3 = df1A[(df1A['年份']==2021) & (df1A['月份']==5)] #提取2021年5月数据
lack3d = lack3['模型运行日期'].value_counts()
lack3d.index.sort_values()
Out[5]:
DatetimeIndex(['2021-05-01', '2021-05-02', '2021-05-03', '2021-05-04',
'2021-05-05', '2021-05-06', '2021-05-07', '2021-05-08',
'2021-05-09', '2021-05-10', '2021-05-11', '2021-05-12',
'2021-05-13', '2021-05-14', '2021-05-15', '2021-05-16',
'2021-05-17', '2021-05-18', '2021-05-19', '2021-05-20',
'2021-05-22', '2021-05-23', '2021-05-24', '2021-05-25',
'2021-05-26', '2021-05-27', '2021-05-28', '2021-05-29',
'2021-05-30', '2021-05-31'],
dtype='datetime64[ns]', freq=None)
2.1.2 异常值处理
由于sheet1数据为基于WRF-CMAQ模型得到的 一次预报数据,所谓异常值也可能就是这个模型本来的输出结果,而不是因为整理或记录错误产生的异常。
题目要求改进一次预报模型,若是模型本来输出的结果就是偏大或偏小的,没有道理将其作为异常值处理。因此对于附件1″监测点A逐小时污染物浓度与气象一次预报数据”,不做异常值处理。
到此为止,sheet1的预处理工作已经完毕。实际上仅是了解了sheet1的数据缺失情况,发现在2020-11-11、2021-01-25、2021-5-21三天没有做预测,并没有进行清洗数据的工作。
2.2 监测点A实测时数据处理
通过浏览附件1sheet2″监测点A逐小时污染物浓度与气象实测数据”,大致可将数据缺失类型整理如下。

2.2.1 整行数据缺失:删失处理
方法一:删失处理。对于这种整行数据都缺失,而且是连续几行都缺失的,个人比较建议直接删去,因为补的话也很难补好,万一补得有问题反而影响后面作答。而且在常规的数据预处理中,也是允许当个案的指标缺失超过某一阙值(如75%、80%)时,删去此个案的做法。
方法二:时间序列填补。观察到这份数据属于时间序列数据,理论上可以用时间序列方法填补。但时间序列方法有繁有简,是否有必要根据缺失值做时间序列,以及具体用哪一种时间序列方法,大家可自行斟酌。
下面给出的是方法一”删失处理”的代码。
这里用的是【.dropna(thresh=X)】函数,它将删除 非缺失值小于X的行/列。这里整行缺失时”检测时间”和”地点”还在,所取thresh=3。
##df2A数据预处理
#将缺失符号换为缺失值
df2A = df2A.replace('—',np.nan)
#删去整一行都是缺失值的行
df2A_drop1=df2A.dropna(axis=0,thresh=3) #删去一行中非缺失值个数小于3的行
2.2.2 缺失值填补法1:前后均值填充
sheet2数据集填补缺失值的逻辑其实有两个:
一是横向上,指标间存在相关性:去做指标间的相关性分析就会发现,这套题的指标之间基本都是相关的(实际意义也说得通,污染物浓度和气象指标之间肯定存在相关性),而且是统计学上显著相关的,这就代表可以用其他指标预测得到缺失指标,常见的方法如随机森林插补等。
二是纵向上,时间上存在连续性:这是一份按时间排列的数据,纵向上两个时间仅差1小时,而指标代表的是污染物浓度和气象,这种指标肯定是”渐变”而不是”突变”的,因此对于随机挖空式缺失值,可以用前后时间的平均值填充。
◆正常来说,用”前后均值插补”补完的数据集可能还会不完整,因为按我们平时的理解,如果前后还是空值应该就补不了了。但此处调用.interpolate()函数,当变量连续空值时,能够自动实现每一个插入值都是前后的均值。对单个变量插值的代码为【df[‘a’] = df[‘a’].interpolate() 】,此处代码如下。
##df2A数据预处理,续经过删失处理的df2A_drop1数据集
#对于每一个变量,用前后均值填补缺失值
df2A_drop2 = pd.DataFrame()
for i in range(df2A_drop1.shape[1]): #【df2A_drop1.shape[1]】表示列数
df2A_drop2[df2A_drop1.columns[i]] = df2A_drop1[df2A_drop1.columns[i]].interpolate()
2.2.3 缺失值填补法2:随机森林插值
随机森林差值的详细介绍可查看下面文章,代码逐行讲解,十分详尽。(机器学习)随机森林填补缺失值的思路和代码逐行详解_m0_46177963的博客-CSDN博客
此处引用了上面博客中的代码,部分地方根据本例数据集的特征做了微调,完整代码如下。最终得到的【df2A_dealmissing】即为经”删失处理”和”随机森林插值”的不含缺失值的数据集。
##df2A数据预处理,续df2A_drop1
#1、一些数据准备工作
#复制一份df2A_drop1,插值完的数据填在df2A_dealmissing
df2A_dealmissing = df2A_drop1.copy()
#考虑后续索引问题,这里df2A_drop2重置了index
df2A_dealmissing.reset_index(inplace=True)
#检验缺失值情况
df2A_dealmissing.isnull().sum(axis=0)
#2、用随机森林进行缺失值插补
import matplotlib.pyplot as plt
from sklearn.datasets import load_boston
from sklearn.ensemble import RandomForestRegressor
from sklearn.impute import SimpleImputer
#数据集中缺失值从少到多进行排序
sortindex = np.argsort(df2A_dealmissing.isnull().sum(axis=0)).values
print(sortindex)
[ 0 1 2 9 10 11 12 13 6 8 3 4 7 5]
#从有缺失值的列开始循环就好(结合上述分析,从sortindex[8]列开始有缺失值)
for i in sortindex[8:len(sortindex)] :
#构建新特征矩阵和新标签
df = df2A_dealmissing.copy()
fillc = df.iloc[: , i]
df.drop(df.columns[[i]],axis=1,inplace=True) #更新df,只储存用来拟合的变量
#在新特征矩阵中,对含有缺失值的列,进行0的填补,注意只能对数值部分进行填补
df_0 = SimpleImputer(missing_values=np.nan , strategy="constant" , fill_value=0).fit_transform(df.iloc[:,3:12])
#构建新的训练集和测试集
y_train = fillc[fillc.notnull()]
y_test = fillc[fillc.isnull()]
x_train = df_0[y_train.index , :]
x_test = df_0[y_test.index , : ]
#用随机森林得到缺失值
rfc = RandomForestRegressor()
rfc.fit(x_train , y_train)
y_predict = rfc.predict(x_test) #用predict接口将x_test导入,得到我们的预测结果,此结果就是要用来填补空值的
#将缺失值填补到原数据表格
df2A_dealmissing.loc[df2A_dealmissing.iloc[:,i].isnull() , df2A_dealmissing.columns[i]] = y_predict
#检验缺失值情况
df2A_dealmissing.isnull().sum(axis=0)
#前面重置了df2A_drop2的index,将index重置回来
df2A_dealmissing=df2A_dealmissing.rename(index=df2A_dealmissing['index'])
#删去中间产生的'index'列
df2A_dealmissing.drop(['index'],axis=1,inplace=True)
#最终得到的df2A_dealmissing即为经删失处理和随机森林差值的不含缺失值的数据集
2.2.4 异常值处理step1:3西格玛原则
实测数据在某个小时的数值可能存在偏离数据正常分布:使用 3
原则识别落在均值三倍标准差之外的异常数据。则将超过 的数据替换为,将小于的值替换为 。代码如下。
#续上,经缺失值处理的数据为df2A_dealmissing,将经过异常值处理的数据储存在df2A_dealoutliers中
df2A_dealoutliers=df2A_dealmissing.copy()
#计算3西格玛原则的上下界
high = df2A_dealoutliers.mean()+3*df2A_dealoutliers.std();high
low = df2A_dealoutliers.mean()-3*df2A_dealoutliers.std();low
#替换超过上下界的数值
for i in range(2,13):
i2=i-2
false_high=np.where(df2A_dealoutliers.iloc[:,i]>high[i2])[0] #找出每一列超过上界的数的位置
df2A_dealoutliers.iloc[false_high,i]=high[i2]
false_low=np.where(df2A_dealoutliers.iloc[:,i]
2.2.5 异常值处理step2:非负数据变成0
考虑数据实际含义,浓度数据不可能为负数,因此将浓度为负的数据替换成0。代码如下
#将浓度小于零的数据替换成0,续上一步处理的df2A_dealoutliers
for i in range(2,8):
index_low_zero=df2A_dealoutliers[df2A_dealoutliers.iloc[:,i]
到此为止,附件1sheet2″监测点A逐小时污染物浓度与气象实测数据”预处理工作已全部完毕,为方便后续阅读,将最终预处理完的df2A数据储存为【dfA_real_hour】,意为监测点A实测时数据。
2.3 监测点A实测日数据处理
2.3.1 缺失值填补:用时数据均值填补
分析附件1sheet3″监测点A逐日污染物浓度实测数据”的缺失值类型,其实跟sheet2差不多,而且也都是时间序列数据,只是一个是时数据,一个是日数据。
那还使用跟sheet2一样的处理方式(删失处理——上下均值插补/随机森林插补)吗?
◆考虑数据实际含义,不建议这么简单粗暴进行。考虑数据含义,日数据和时数据肯定存在逻辑联系。通过一些简单的探索分析,也发现除O3外,sheet3中的数据几乎都是sheet2中对应日期的24h平均;O3的计算方式特别些,是取”8小时滑动平均的最大值”,这也意味着,填补sheet3日数据的首选方式,是按照数据的它们原本的逻辑(24h平均or8小时滑动平均的最大值)进行计算。
为方便后续处理,首先定义change_htod(df)函数,将”时数据”转化为”日数据”。
#定义一个函数,可以将df2A的"时数据"转换成对应日期的"日数据"
def change_htod(df):
"""
适用于df2A数据
将小时实测数据转化为日数据
df为完整数据列表[监测时间,SO2,NO2,PM10,PM2.5,O3,CO,温度,湿度,气压,风速,风向]
"""
#第一步:识别出日期
df['日期'] =df['监测时间'].dt.date
df['时间'] =df['监测时间'].dt.time
#第二步:按日期计算平均值
df_mean_day = pd.DataFrame({'SO2平均浓度(μg/m³)':df.groupby('日期')['SO2监测浓度(μg/m³)'].mean(),
'NO2平均浓度(μg/m³)':df.groupby('日期')['NO2监测浓度(μg/m³)'].mean(),
'PM10平均浓度(μg/m³)':df.groupby('日期')['PM10监测浓度(μg/m³)'].mean(),
'PM2.5平均浓度(μg/m³)':df.groupby('日期')['PM2.5监测浓度(μg/m³)'].mean(),
'O3平均浓度(μg/m³)':df.groupby('日期')['O3监测浓度(μg/m³)'].mean(),
'CO平均浓度(mg/m³)':df.groupby('日期')['CO监测浓度(mg/m³)'].mean(),
'平均温度(℃)':df.groupby('日期')['温度(℃)'].mean(),
'平均湿度(%)':df.groupby('日期')['湿度(%)'].mean(),
'平均气压(MBar)':df.groupby('日期')['气压(MBar)'].mean(),
'平均风速(m/s)':df.groupby('日期')['风速(m/s)'].mean(),
'风向(°)':df.groupby('日期')['风向(°)'].mean()})
#第三步:臭氧问题重处理
#o3数据重排:使用O3的"日期-时间"交叉表
cross_o3=pd.crosstab(index=df['时间'],columns=df['日期'],values=df['O3监测浓度(μg/m³)'],aggfunc='sum')
#根据cross_o3,计算8小时滑动平均值最大值,得到序列o3
adj = []
o3 = []
for j in range(cross_o3.shape[1]): #[cross_o3.shape[1]]为cross_o3的列数,即日期数
for i in range(7,24): #与o3"8小时滑动平均"定义有关,早上八点才产生第一个滑动平均值
adj.append(cross_o3.iloc[i-7:i+1,j].mean()) #八小时滑动平均
o3.append(max(adj)) #将每天滑动平均的最大值存储到序列o3中
adj = []
#将日期与o3对应
dfo3 = pd.DataFrame(o3,index=cross_o3.columns,columns=["O3最大八小时滑动平均监测浓度(μg/m³)"])
#第四步:替换掉步骤二中由简单平均产生的臭氧数据
df_mean_day.iloc[:,4]=dfo3.iloc[:,0]
#第五步:返回根据"时数据"转化的"日数据"
return df_mean_day
调用上述函数的计算结果,对sheet3的”日数据”进行插补,代码如下。
#复制一份df3A,经过缺失值处理的数据放在df3A_dealmissing中
df3A_dealmissing = df3A.copy()
#检查df3A数据缺失情况
df3A_dealmissing.isnull().sum(axis=0)
#注意2021-7-14和2021-7-13本来就要我们预测,不算缺失值,可删去
df3A_dealmissing.drop(df3A_dealmissing.index[[820,821]],axis=0,inplace=True) #删除行,用行索引
#找到缺失值所在的行列
loca_nan0=np.where(pd.isna(df3A_dealmissing))[0] #每个缺失值对应的行
loca_nan1=np.where(pd.isna(df3A_dealmissing))[1] #每个缺失值对应的列
#调用上述函数,将时数据转换成日数据。续上述预处理完的sheet2时数据:dfA_real_hour
dfA_real_htod=change_htod(dfA_real_hour)
#填补缺失值
df3A_dealmissing['日期'] =df3A_dealmissing['监测日期'].dt.date
for i in range(len(loca_nan0)):
day = df3A_dealmissing.iloc[loca_nan0[i],8] #提取日期
column = loca_nan1[i]-2 #提取列:df3A变量与df_mean_day差了两位
df3A_dealmissing.iloc[loca_nan0[i],loca_nan1[i]] = dfA_real_htod.loc[day][column] #替换缺失值
检查填补完的数据是否还存在缺失值,若存在,可以用随机森林进一步填补。
此处检查发现,填补完的”日数据”已经不存在缺失值,缺失值处理完毕,保存为【df3A_dealmissing】,并转至异常值处理。
#再次检查df3A_dealmissing数据缺失情况
df3A_dealmissing.isnull().sum(axis=0)
Out[6]:
监测日期 0
地点 0
SO2监测浓度(μg/m³) 0
NO2监测浓度(μg/m³) 0
PM10监测浓度(μg/m³) 0
PM2.5监测浓度(μg/m³) 0
O3最大八小时滑动平均监测浓度(μg/m³) 0
CO监测浓度(mg/m³) 0
日期 0
#删去中间产生的"日期"变量,最终df3A_dealmissing即为经缺失值处理的数据集
del df3A_dealmissing['日期']
2.3.2 异常值处理step1:用时数据均值替换
对于实测日数据,同样使用 3原则识别落在均值三倍标准差之外的异常数据。但对于异常数据,我们首先考虑用日数据的平均值替换,如果替换后还存在异常的,再用 3 原则的上下界进行替换。
2.3.3 异常值处理step2:3西格玛原则
若用日数据替换异常值后,仍存在异常,则用 3原则的上下界进行替换。
2.3.4 异常值处理step3:非负数据变成0
考虑数据实际含义,浓度数据不可能为负数,因此将浓度为负的数据替换成0。
#续章节2.3.1,复制一份df3A_dealmissing
df = df3A_dealmissing.copy()
#步骤1:计算3西格玛原则的上下界
high = df.mean()+3*df.std();high
low = df.mean()-3*df.std();low
#步骤2:替换超过上下界的24h平均值
df['日期'] =df['监测日期'].dt.date
for i in range(2,8):
i2=i-2;lie=i-2
false_high=np.where(df.iloc[:,i]>high[i2])[0] #异常值所在行
for j in range(len(false_high)):
date=df.iloc[false_high[j],8] #提取日期
df.iloc[false_high[j],i] = dfA_real_htod.loc[date][lie] #替换缺失值
false_low=np.where(df.iloc[:,i]high[i2])[0]
df.iloc[false_high,i]=high[i2]
false_low=np.where(df.iloc[:,i]
到此为止,附件1sheet3″监测点A逐日污染物浓度实测数据”预处理工作已全部完毕,为方便后续阅读,将最终预处理完的df3A数据储存为【dfA_real_day】,意为监测点A实测日数据。
- 监测点B、C数据预处理
监测点B、C的数据结构与监测点A一致,包含sheet1、sheet2、sheet3三个表格,处理方式与监测点A一致,此处不再赘述。
4. 监测点A1、A2、A3数据预处理
【注】只想看这部分的,可转到博客:[Python] 反距离权重插值案例及代码_禾木页-CSDN博客
因为除协同处理部分,很多方法1-3节讲了,在这里到就不再继续重复,为避免跳转来跳转去比较麻烦,只想看第4节监测点A、A1、A2、A3预处理过程的可直接转到上面博客。
4.1 监测点A1、A2、A3一次预报数据
由于数据结构与监测点A一致,分析过程同章节 2.1 监测点A一次预报数据处理,此处不再赘述。
分析发现,A、A1、A2、A3四个监测点的一次预报数据的缺失日期都是一样的,均为2020-11-11、2021-01-25、2021-05-21。
题外话:经再三确认过,这里确实没有导错数据。看来出题人还是没有太为难我们呀,这为后面数据合并和匹配降低了许多难度。
#监测点A1:在2020-11、2021-01、2021-05月份存在缺失
月份 1 2 3 4 5 6 7 8 9 10 11 12
年份
2020 NaN NaN NaN NaN NaN NaN 9.0 31.0 30.0 31.0 29.0 31.0
2021 30.0 28.0 31.0 30.0 30.0 30.0 13.0 NaN NaN NaN NaN NaN
#监测点A2:在2020-11、2021-01、2021-05月份存在缺失
月份 1 2 3 4 5 6 7 8 9 10 11 12
年份
2020 NaN NaN NaN NaN NaN NaN 9.0 31.0 30.0 31.0 29.0 31.0
2021 30.0 28.0 31.0 30.0 30.0 30.0 13.0 NaN NaN NaN NaN NaN
#监测点A3:在2020-11、2021-01、2021-05月份存在缺失
月份 1 2 3 4 5 6 7 8 9 10 11 12
年份
2020 NaN NaN NaN NaN NaN NaN 9.0 31.0 30.0 31.0 29.0 31.0
2021 30.0 28.0 31.0 30.0 30.0 30.0 13.0 NaN NaN NaN NaN NaN
#经查,监测点A1、A2、A3的缺失日期均为,与监测点A一致。
2020-11-11
2021-01-25
2021-05-21
4.2 监测点A1、A2、A3实测时数据处理
4.2.1 缺失值处理step1:反距离权重插值(IDW)
由于题目说到:监测点A、A1、A2、A3存在协同作用,即它们之间的变量可能存在一定的相关性。又考虑到污染物浓度和气象条件在地表上应当是连续变化的,所以在缺失值处理时,先引入反向距离权重,对于缺失的数据,用其他2-3个监测点的反向距离权重进行加权。

数学表达式:
令dij表示监测点i和监测点j之间的欧式距离,权重表达式为:
此处取:
根据坐标生成距离权重的代码如下所示:
#定义计算欧氏距离函数
def distEclud(vecA, vecB):
return np.sqrt(np.sum(np.power((vecA - vecB), 2)))
#导入四个监测点坐标
vecA=np.array([0,0])
vecA1=np.array([-14.4846,-1.9699])
vecA2=np.array([-6.6716,7.5953])
vecA3=np.array([-3.3543, -5.0138])
#监测点A、A1、A2、A3之间的反向距离权重
w01=1/distEclud(vecA,vecA1)
w02=1/distEclud(vecA,vecA2)
w03=1/distEclud(vecA,vecA3)
w12=1/distEclud(vecA1,vecA2)
w13=1/distEclud(vecA1,vecA3)
w23=1/distEclud(vecA2,vecA13)
#创建权重矩阵
W=np.array([[0,w01,w02,w03],[0,0,w12,w13],[0,0,0,w23],[0,0,0,0]]);W
Out[8]:
array([[0. , 0.0684091 , 0.09891839, 0.16577225],
[0. , 0. , 0.08096807, 0.0866625 ],
[0. , 0. , 0. , 0.07669788],
[0. , 0. , 0. , 0. ]])
#形成对称矩阵(此处对角线元素为零,后面不减也是可以的)
W += W.T - np.diag(W.diagonal());W
Out[9]:
array([[0. , 0.0684091 , 0.09891839, 0.16577225],
[0.0684091 , 0. , 0.08096807, 0.0866625 ],
[0.09891839, 0.08096807, 0. , 0.07669788],
[0.16577225, 0.0866625 , 0.07669788, 0. ]])
定义反距离权重插值的代码如下。大致逻辑是把监测点A、A1、A2、A3实测时数据按变量拆分成11个数据集,在每个数据集中分别找出每一列缺失值的位置,对确实类型进行判断后实现插值,最后将数据恢复成原来A、A1、A2、A3的样子。
由于篇幅原因,这里写得比较简单,详细可以转到:[Python] 反距离权重插值案例及代码_禾木页-CSDN博客
这篇文章提供了两种实现反距离权重插值(IDW)的方法,对实现的逻辑也有更清晰的解释
#定义一个函数,实现反距离权重插值
def cov_nan(df,W):
"""
功能:当除缺失点位外,还存在2个及以上其他点位时,实现反距离权重差值
df格式:第一列为"key"变量,后面依次为A0、A1、A2、A3等数据
W格式:与df非"key"变量对应的权重
"""
for col in range(1,df.shape[1]): #对于除"key"变量的每一列
loca_nan=np.where(pd.isna(df.iloc[:,col]))[0] #查看每一列缺失值所在的行
for i in loca_nan:
#切出含有缺失值的行
h=df.iloc[i,1:df.shape[1]]
#定义一个缺失值示性向量
I=np.array(np.repeat(1,df.shape[1]-1))
I[h.isnull()]=0
#除了要插值的变量,至少还有有2个其他点位变量才适合用反距离权重插值
if I.sum()>=2:
W_sum=(W[col-1]*I).sum()
df.iloc[i,col]=(h*W[col-1]*I/W_sum).sum()
else:
continue
return df
利用反距离权重插值(IDW)同时处理监测点A、A1、A2、A3的代码:
#监测点A1、A2、A实测时数据导入
df2A1=pd.read_excel("附件3 监测点A1、A2、A3空气质量预报基础数据.xlsx","监测点A1逐小时污染物浓度与气象实测数据")
df2A2=pd.read_excel("附件3 监测点A1、A2、A3空气质量预报基础数据.xlsx","监测点A2逐小时污染物浓度与气象实测数据")
df2A3=pd.read_excel("附件3 监测点A1、A2、A3空气质量预报基础数据.xlsx","监测点A3逐小时污染物浓度与气象实测数据")
#步骤1:一些预处理工作
#通过数据预览,发现A1少了"气压变量",为使数据结构一致,给他补回去
s=np.repeat(np.nan, df2A1.shape[0])
df2A1.insert(10, '气压(MBar)', s)
#通过数据预览,发现监测点A1部分数据为异常的零,实际应判断缺失值
df2A1.iloc[0:5360,8:13]=np.nan
#通过数据预览,发现A2、A3存在'—'缺失
df2A2=df2A2.replace('—',np.nan)
df2A3=df2A3.replace('—',np.nan)
#都删去"地点"
df2A.drop(['地点'],axis=1,inplace=True)
df2A1.drop(['地点'],axis=1,inplace=True)
df2A2.drop(['地点'],axis=1,inplace=True)
df2A3.drop(['地点'],axis=1,inplace=True)
#发现A、A1、A2、A3变量顺序一样,名字也一样
#步骤2:将A、A1、A2、A3实测时数据合并【df_mergeA】
df_mergeA=pd.merge(df2A,df2A1,on='监测时间',how='outer')
df_mergeA=pd.merge(df_mergeA,df2A2,on='监测时间',how='outer')
df_mergeA=pd.merge(df_mergeA,df2A3,on='监测时间',how='outer')
#缺失值替换
df_mergeA=df_mergeA.replace('na',np.nan)
#转化为数值型
df_mergeA.iloc[:,1:45]=df_mergeA.iloc[:,1:45].astype('float64')
#这里发现,merge完的数据虽然数据量没有太大变化,但spyder预览窗口莫名变得很卡,包括从merge中切片出来的数据
#但是将生成的df_mergeA导出再导入后,则不存在这个问题
df_mergeA.to_excel('df_mergeA.xlsx',encoding='utf_8_sig',index=False)
del df_mergeA
df_mergeA=pd.read_excel("df_mergeA.xlsx","Sheet1")
#步骤3:理论上,运行此代码即可得到填补完的合并数据集【df_mergeA_dealmissing】
df_mergeA_dealmissing=df_mergeA.copy()
for i in range(1,12):
df_val=df_mergeA.iloc[:,[0,i,i+11,i+22,i+33]]
df_val_dealmissing=cov_nan(df_val,W)
df_mergeA_dealmissing.iloc[:,[i,i+11,i+22,i+33]]=df_val_dealmissing.iloc[:,[1,2,3,4]]
"""
理论上,运行上述代码即可得到填补完的合并数据集df_mergeA_dealmissing
但实践中发现,上述代码加上函数cov_nan()内部代码,共三个嵌套的for循环,运行速度非常很慢(超过30min)
由于仅有11个变量,所以实际运行中拿掉了最后一个for循环,改"人工手动循环" ╮(╯_╰)╭
如果有更好的编码方式,欢迎交流 (*^▽^*)~~~
"""
最后,就是将处理完的【df_mergeA_dealmissing】合并数据集恢复原来的监测点A、A1、A2、A3实测时数据的样子。
#步骤4:还原数据集,得到【df2A_new】,【df2A1_new】,【df2A2_new】,【df2A3_new】
#从处理好的【df_mergeA_dealmissing】中拆分出来
df2A_new = df_mergeA_dealmissing.iloc[:,0:12]
df2A1_new = df_mergeA_dealmissing.iloc[:,[0,12,13,14,15,16,17,18,19,20,21,22]]
df2A2_new = df_mergeA_dealmissing.iloc[:,[0,23,24,25,26,27,28,29,30,31,32,33]]
df2A3_new = df_mergeA_dealmissing.iloc[:,[0,34,35,36,37,38,39,40,41,42,43,44]]
#恢复变量名字
df2A_new.columns = list(df2A.columns)
df2A1_new.columns = list(df2A.columns)
df2A2_new.columns = list(df2A.columns)
df2A3_new.columns = list(df2A.columns)
#恢复"地点"列
s=np.repeat('监测点A', df2A_new.shape[0])
df2A_new.insert(1, '地点', s)
s=np.repeat('监测点A1', df2A1_new.shape[0])
df2A1_new.insert(1, '地点', s)
s=np.repeat('监测点A2', df2A2_new.shape[0])
df2A2_new.insert(1, '地点', s)
s=np.repeat('监测点A3', df2A3_new.shape[0])
df2A3_new.insert(1, '地点', s)
4.2.2 缺失值处理step2:随机森林插补
利用反向距离权重插值完后,对于四个监测点都是缺失值或者四个监测点中有三个缺失的,暂时还未处理。此时可利用” 2.2.3 缺失值填补法2:随机森林插值“进行处理。
由于这里监测点A、A1、A2、A3有协同作用,理论上可以用两种方式插值,可根据意向自由选择。
方法一:用拆分数据集插值。监测点A、A1、A2、A3的实测时数据分别插值。需进行4次插值,每次处理11个变量。
方法二:用合并数据集插值。用监测点A、A1、A2、A3实测时数据的合并数据插值。只需进行1次插值,一次处理44个变量。
4.2.3 异常值处理:3西格玛+非负数据处理
过程与监测点A一样,可查看章节 2.2.4 异常值处理step1:3西格玛原则、 2.2.5 异常值处理step2:非负数据变成0。
4.3 监测点A1、A2、A3实测日数据处理
过程与监测点A一样,可查看章节 2.3 监测点A实测日数据处理
以上即作者个人能看到的 2021年华为杯研赛B题”空气质量预报二次建模”需要进行数据预处理的地方。由于知识积累和能力水平的限制,可能还有些地方考虑得不够到位,或者方法上还有所欠缺,欢迎有兴趣的读者一起交流~~
Original: https://blog.csdn.net/qq_42281663/article/details/120880145
Author: 禾木页
Title: 2021华为杯数学建模B题“空气质量预报二次建模” 预处理思路+Python代码
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/694854/
转载文章受原作者版权保护。转载请注明原作者出处!