

10.Pandas实现DataFrame的Merge(合并)
文章目录
前言
笔者最近正在学习Pandas数据分析,将自己的学习笔记做成一套系列文章。本节主要记录Pandas中DataFrame的Merge
Pandas的Merge,相当于Sql的Join,将不同的表按key关联到一个表
Merge的语法:
DataFrame.merge(right, how=’inner’, on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=(‘_x’, ‘_y’), copy=True, indicator=False, validate=None)
- left,right:要merge的dataframe或者有name的Series
- how:join类型,’left’,’right’,’outer’,’inner’
- on: join的key,left和right都需要有这个key
- left_on: left的df或者series的key
- right_on: right的df或者series的key
- left_index,right_index:使用index而不是普通的column做join
- suffixes:两个元素的后缀,如果列有重名,自动添加后缀,默认是(’_x’,’_y’)
一、电影数据集的join实例
电影评分数据集
是推荐系统研究的很好的数据集,包含三个文件:
- 用户对电影的评分数据ratings.dat
- 用户本身的信息数据 users.dat
- 电影本身的数据 movie.dat
可以关联三个表,得到一个完整的大表
https://grouplens.org/datasets/movielens/
二、程序演示
提前读取数据
import pandas as pd
df_ratings=pd.read_csv(
"./datas/ml-1m/ratings.dat",
sep="::",
engine='python',
names="UserID::MovieID::Rating::Timestamp".split("::")
)
df_ratings.head()


df_users=pd.read_csv(
"./datas/ml-1m/users.dat",
sep="::",
engine='python',
names="UserID::Gender::Age::Occupation::Zip-code".split("::")
)
df_users.head()

df_movies=pd.read_csv(
"./datas/ml-1m/movies.dat",
sep="::",
engine='python',
names="MovieID::Title::Genres".split("::")
)
df_movies.head()
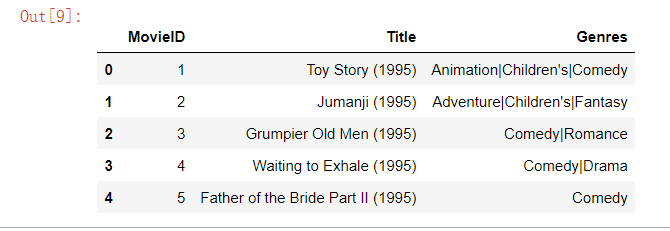
1.合并不同表的信息
df_ratings_users=pd.merge(
df_ratings,df_users,left_on='UserID',right_on="UserID",how="inner"
)
df_ratings_users.head()
df_ratings_users_movies=pd.merge( df_ratings_users,df_movies,left_on='MovieID',right_on='MovieID',how='inner'
)
df_ratings_users_movies.head(10)


2.理解merge时数量的对齐关系
以下关系要正确的理解:
- one-to-one:一对一关系,关联的key都是唯一的
- 比如(学号,姓名)merge(学号,姓名)
- 结果条数为1*1
- one-to-many: 一对多关系,左边唯一key,右边不唯一key
- 比如(学号,姓名)merge (学号,[语文分数、数学分数、英语分数])
- 结果条数:1*N
- many-to-many:多对多关系,左边和右边都不是唯一的
- 比如(学号,[语文分数、数学分数、英语分数]) merge (学号,[篮球、足球、乒乓球])
- 结果条数为:M*N
left=pd.DataFrame({
'sno':[11,12,13,14],
'name':['a','b','c','d']
})
left
right=pd.DataFrame({'sno':[11,12,13,14],
'age':['21','22','23','24']})
right
pd.merge(left,right,on='sno')


left=pd.DataFrame({
'sno':[11,12,13,14],
'name':['a','b','c','d']
})
left
right=pd.DataFrame({'sno':[11,11,11,12,12,13],
'grade':['语文88','数学90','英语75','语文66','数学55','英语29']})
right
pd.merge(left,right,on='sno')


left=pd.DataFrame({
'sno':[11,11,12,12,12],
'爱好':['篮球','羽毛球','乒乓球','篮球','足球']
})
left
right=pd.DataFrame({'sno':[11,11,11,12,12,13],
'grade':['语文88','数学90','英语75','语文66','数学55','英语29']})
right
pd.merge(left,right,on='sno')


3.理解left join、right join、inner join、outer join的区别
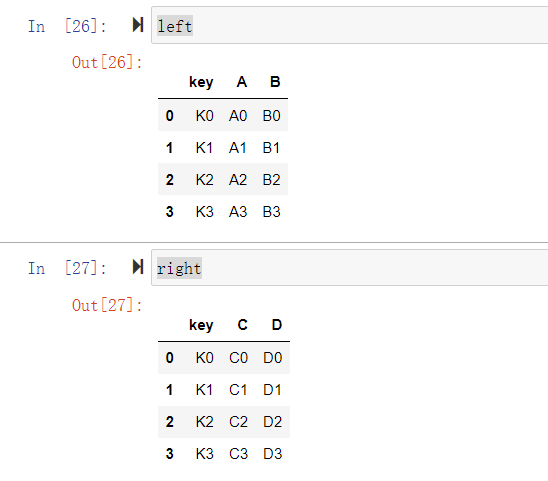
left=pd.DataFrame({
'key':['K0','K1','K2','K3'],
'A':['A0','A1','A2','A3'],
'B':['B0','B1','B2','B3']
})
right=pd.DataFrame({
'key':['K0','K1','K2','K3'],
'C':['C0','C1','C2','C3'],
'D':['D0','D1','D2','D3']
})
left
right
pd.merge(left,right,how='inner')

pd.merge(left,right,how='left')

pd.merge(left,right,how='right')

pd.merge(left,right,how='outer')

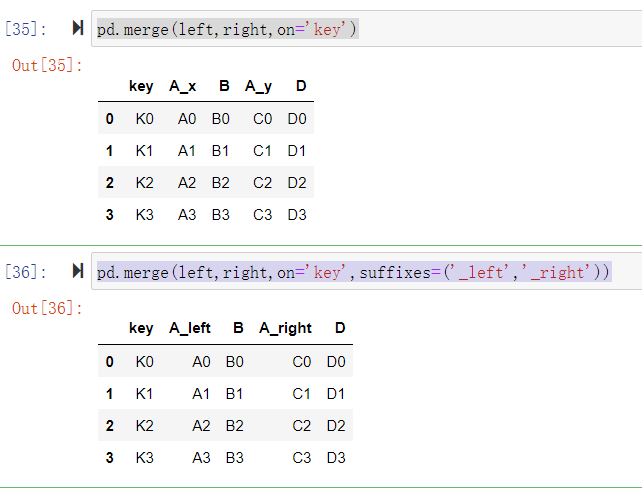
4. 如果出现非Key的字段重名怎么办
left=pd.DataFrame({
'key':['K0','K1','K2','K3'],
'A':['A0','A1','A2','A3'],
'B':['B0','B1','B2','B3']
})
right=pd.DataFrame({
'key':['K0','K1','K2','K3'],
'A':['C0','C1','C2','C3'],
'D':['D0','D1','D2','D3']
})
left
right
pd.merge(left,right,on='key')
pd.merge(left,right,on='key',suffixes=('_left','_right'))

总结
这就是pandas的DataFrame的Merge的基本用法了,希望可以帮助到你。
Original: https://blog.csdn.net/qq_48081868/article/details/119996707
Author: Wumbuk
Title: Pandas数据分析—实现DataFrame的Merge(合并)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/693626/
转载文章受原作者版权保护。转载请注明原作者出处!