

- 感知机模型:将线性可分的数据,利用一个线性超平面将其分类;(感知机只有输出层神经元进行激活函数处理,即只有一层功能神经元)其模型公式为:
 其中
其中
感知机模型损失定义:

其中M表示误分类结点的集合;
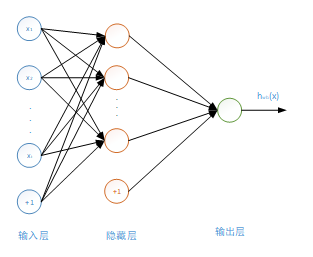
- 隐藏层与输入层是全连接的,假设输入层用向量X表示,则隐藏层的输出就是 f (W1X+b1),W1是权重(也叫连接系数),b1是偏置,函数f可以是常用的sigmoid 函数或者tanh函数;
- 多层感知机是一种多层前馈神经网络 ,常用的快速训练算法有共轭梯度法、拟牛顿法。
由于多层感知机算法的局限性,提出了误差逆传播算法即BP算法;(其不仅被用于多层前馈神经网络,也可用于其他神经网络。)

BP算法实现过程

2. 在BP算法训练的过程:
- 将输入示例提供给输入神经元;
- 对输入数据进行计算,并逐层向前传播,产生输出结果;
- 计算输出结果的误差;
- 将误差逆向传播至隐层神经元;
- 根据误差,调整参数(包括连接权和阈值),从②开始反复迭代,直到满足条件。

★解决BP算法中过拟合问题:
- 早停:将数据划分为训练集和验证集,训练集用来计算梯度、更新连接权和阈值,验证集用来估计误差,若训练集误差降低,但是验证集的误差升高,则停止训练,同时返回具有最小验证集误差的连接权和阈值。
- 正则化:在误差目标函数中增加一个用于描述网络复杂度的部分,例如连接权与阈值的平方和;其误差目标函数

★全局最小与局部极小
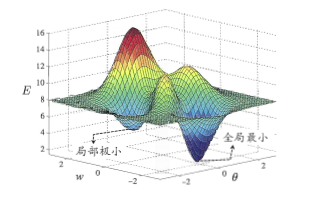

●跳出局部极小方法:(1)以多组不同参数初始化多个神经网络,训练后取其中误差最小的解作为最终参数;即从局部极小选择更可能接近全局最小的结果。(2)使用”模拟退火”技术,在每一步都以一定概率接受比当前结果更差的结果,从而跳出局部极小。(3)随机梯度下降,与标准梯度下降法精确计算梯度不同,随机梯度下降法在计算梯度时加入了随机因素。于是,即便陷入局部极小点,它计算出的梯度仍可能不为零,这样就有机会跳出局部极小继续搜索。


基于Sklearn框架的MLP算法实现:


名称
原理
网络核心
训练过程
其他
RBF(Radial Basis Fuction–径向基函数)网络
一种单隐层前馈神经网络,使用径向基函数作为隐层神经元激活函数,输出层是对隐藏层的线性组合。
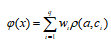
c,w分别为隐层神经元对应的中心和权重
1)确定神经元中心c,常用随机采用、聚类等;
2)利用BP算法确定参数w,b;
RBF神经网络具有”局部映射”特性。BP神经网络是对非线性映射的全局逼近 。
ART(Adaptive Resonance Theory)自适应谐振网络
包含比较层、识别层、识别阈值和重置模块,以竞争学习的方式进行学习;是一种无监督学习过程;
- 比较层接受输入样本,并将其传递给识别层神经元;
- 识别层每个神经元对应一个模式类,神经元数目可在训练过程中动态增长以增加新的模式类;识别层收到输入数据,利用识别层的竞争学习产生获胜神经元;(竞争机制例如:输入神经元识别的类别与标签类别之间的距离,距离小的获胜)
- 获胜神经元发送信号抑制其他神经元的激活,通过输入数据与获胜神经元所对应的得向量间的相似度大于识别阈值,更新网络权重,使输入数据与神经元的模式相似度更大
SOM(Self-Organizing Map)自组织映射网络
一种竞争学习型的无监督神经网络,将高维输入数据映射到低维空间,保持输入数据在高位空间的拓扑(高维空间的相似样本点映射到低维空间中邻近的神经元),将距离小的个体集合划分为同一类别,而将距离大的个体集合划分为不同的类别。
1)接受输入:首先计算本次迭代的学习率和学习半径,并且从训练集中随机选取一个样本。
2)寻找获胜节点:计算数据集中其他样本与此样本的距离,从中找到点积最小的获胜节点。
3)计算优胜领域:根据这两个节点计算出聚类的领域,并找出此领域中的所有节点。
4)调整权值:根据学习率、样本数据调整权重。
5)根据计算结果,为数据集分配类别和标签。
6)评估结果:SOM网络属于无监督聚类,输出的结果就是聚类后的标签。如果训练集已经被分好类,即具有分类标签,那么通过新旧标签的比较就可以反映聚类结果的准确度。
级联相关网络
级联相关神经网络是从一个小网络开始,自动训练和添加隐含单元,最终形成一个多层的结构。
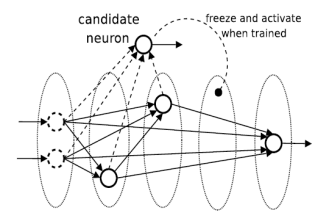
1)候选神经元连结到所有的输入和隐含神经元(图中的虚线),并且候选神经元的输出不连结到网络上;
2)固定住图中的实线部分,只训练候选神经元的权重(也就是图中的虚线);
3)当权重训练好之后,就将候选神经元安装到图中空白的层上,也就是第四个区域,这时候选项的连接权就不能再改变了;
4)将候选神经元连结到网络的输出上,这时候选神经元被激活,开始训练网络的所有输出连接权;
Elman网络
Elman是一种动态递归神经网络,包括输入层、隐藏层、承接层和输出层。

- 输入层输入信号,并将其传入隐藏层;
- 隐藏层采用激活函数,对t时刻的输入信号进行计算,并将其分别传递到输出层和承接层;
- 承接层接收信号并将其与下一时刻的输入信号结合,重新输入到隐藏层;(因此,Elman网络使t时刻的输出状态不仅与t时刻的输入有关,还与t-1时刻的网络状态有关,可以处理与时间有关的动态变化)
Boltzmann(玻尔兹曼机)机
是一种基于能量的模型;包括两层:显层和隐层,显层为数据的输入输出,隐层为数据的内在表达;
通过调整网络权值使训练集中的模式在网络状态中以相同的概率再现。
1)正向学习阶段或输入期:即向网络输入一对输入输出模式,将网络输入输出节点的状态钳制到期望的状态,而让隐节点自由活动以捕捉模式对之间的对应规律;
2)反向学习阶段或自由活动期:对于异联想学习,钳制住输入节点而然隐含节点和输出节点自由活动;对于自联想学习,可以让其可见节点和隐节点都自由活动,已体现网络对输入输出对应规律的模拟情况。输入输出的对应规律表现为网络到达热平衡时,相连节点状态同时为一的平均概率。期望对应规律与模拟对应规律之间的差别就表现为两个学习阶段对应的平均概率的差值,此差值做为权值调整的依据。
不同神经网络对比参考文献:
ART:https://blog.csdn.net/u013468614/article/details/94751690 ;
SOM: https://blog.csdn.net/jyh_AI/article/details/82024431
级联相关网络: https://blog.csdn.net/xc_xc_xc/article/details/53163478
Elman: https://blog.csdn.net/fengzhimohan/article/details/80847979
Boltzmann机:https://www.cnblogs.com/pythonlearing/p/9978246.html
Original: https://blog.csdn.net/zhx111111111/article/details/119239667
Author: ~~~霞
Title: 机器学习算法六:多层感知机(MLP)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/690224/
转载文章受原作者版权保护。转载请注明原作者出处!