

paper:https://arxiv.org/pdf/2112.05561v1.pdf
目录
3. Global Attention Mechanism (GAM)
4.1 Classification on CIFAR-100 and ImageNet datasets
Abstract
为了提高各种计算机视觉任务的性能,人们研究了各种注意机制。然而,以往的方法忽略了保留通道和空间两个方面的信息对增强跨维交互作用的重要性。因此,我们提出了一种全局吸引机制,通过减少信息约简和放大全局交互表示来提高深度神经网络的性能。在卷积空间关注子模块的基础上,提出了一种基于多层感知器的三维排列通道关注子模块。在CIFAR-100和ImageNet-1K上对所提出的图像分类机制的评估表明,我们的方法稳定地优于最近几种使用ResNet和轻量级MobileNet的注意机制。
1. Introduction
卷积神经网络(CNNs)在计算机视觉领域的许多任务和应用中得到了广泛的应用(Girshick et al.)。研究人员发现,CNN在提取深层视觉表征方面表现良好。随着CNNs相关技术的改进,ImageNet数据集上的图像分类(Den et al.)在过去九年中,准确率从63%提高到90%(Krizhevsky et al)。这一成就还归功于ImageNet数据集的复杂性,这为相关研究提供了难得的机会。鉴于其涵盖的真实场景的多样性和广泛性,它给传统的表象分类基准、表征学习、迁移学习等研究带来了很大的益处,特别是对注意机制的研究也带来了挑战。
近年来,注意机制在多种应用中的性能不断提高,并引起了人们的研究兴趣(Niu et al.)。Wang et al.使用编解码器残差注意模块对特征映射进行细化,以获得更好的性能。Hu et al.,Woo et al.、Park et al.分别使用空间注意机制和通道注意机制,获得了较高的准确率。然而,由于信息减少和维度分离,这些机制利用了来自有限感受域的视觉表示。在这一过程中,它们失去了全球空间-通道交互作用。我们的研究目标是让注意力机制跨越空间通道维度。我们提出了一种保留信息的”全局”注意机制,以放大”全局”的跨维互动。因此,我们将所提出的方法命名为全局注意机制Global Attention Mechanism(GAM)。
已经有几个研究集中在图像分类任务中注意机制的性能改善上。挤压激励网络(SENet)(Hu et al.)首先利用通道注意和通道特征融合来抑制不重要的通道,但对不重要的像素的抑制效率较低。后一种注意机制同时考虑了空间维度和通道维度。卷积挡路注意模块(CBAM)(Woo et al.)顺序放置通道和空间注意操作,而瓶颈注意模块(BAM)(Park et al.)同时进行。然而,这两种方法都忽略了通道-空间的相互作用,从而丢失了跨维信息。考虑到跨维交互的重要性,三元组注意模块(TAM)(Misra et al.)通过利用通道、空间宽度和空间高度这三个维度中每一对之间的注意权重来提高效率。但是,每次注意操作仍然应用于其中两个维度,而不是全部三个维度。为了放大跨维度的交互作用,我们提出了一种能够捕捉所有三个维度的显著特征的注意机制。
- Global Attention Mechanism (GAM)
我们的目标是设计一种减少信息缩减并放大全局维度交互特征的机制。我们采用了CBAM中的顺序通道-空间注意机制,并对子模块进行了重新设计。整个过程如图1所示,并在公式1和公式2中表示(Woo et al.)。给定输入特征映射
 ,中间状态和输出定义为:
,中间状态和输出定义为:

其中
和分别是通道和空间注意图;表示基于元素的乘法。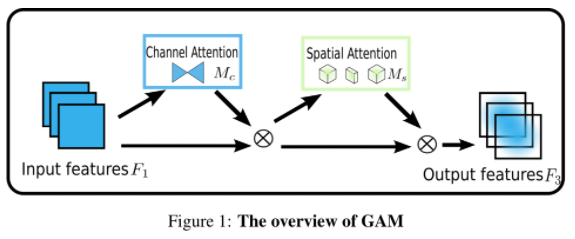
图1:GAM概述
通道注意力子模块使用3D置换来保留三维信息,然后利用两层MLP(多层感知器)放大跨维通道-空间依赖关系。(MLP是具有缩减比r的编码器-解码器结构,与BAM相同。)通道关注子模块如图2所示。
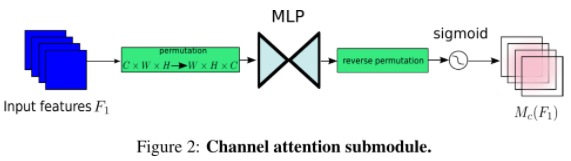
图2:通道注意力子模块
在空间注意力子模块中,为了聚焦空间信息,我们使用了两个卷积层次进行空间信息融合。我们也使用与BAM相同的信道关注子模块的缩减率r。同时,最大汇集减少了信息,对信息的贡献为负。我们去掉了池,以进一步保留功能地图。因此,空间注意模块有时会显著增加参数的数量。为了防止参数的显著增加,我们采用了信道混洗的分组卷积(Zhang et al.)在ResNet50中,不带群卷积的空间注意子模块如图3所示。
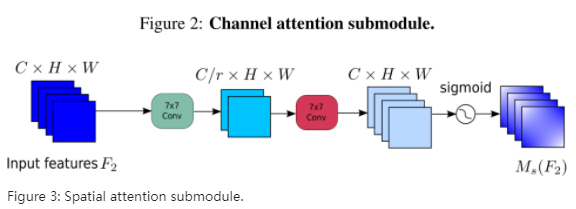
图3:空间注意力子模块
代码实现
import torch.nn as nn
import torch
class GAM_Attention(nn.Module):
def __init__(self, in_channels, out_channels, rate=4):
super(GAM_Attention, self).__init__()
self.channel_attention = nn.Sequential(
nn.Linear(in_channels, int(in_channels / rate)),
nn.ReLU(inplace=True),
nn.Linear(int(in_channels / rate), in_channels)
)
self.spatial_attention = nn.Sequential(
nn.Conv2d(in_channels, int(in_channels / rate), kernel_size=7, padding=3),
nn.BatchNorm2d(int(in_channels / rate)),
nn.ReLU(inplace=True),
nn.Conv2d(int(in_channels / rate), out_channels, kernel_size=7, padding=3),
nn.BatchNorm2d(out_channels)
)
def forward(self, x):
b, c, h, w = x.shape
x_permute = x.permute(0, 2, 3, 1).view(b, -1, c)
x_att_permute = self.channel_attention(x_permute).view(b, h, w, c)
x_channel_att = x_att_permute.permute(0, 3, 1, 2)
x = x * x_channel_att
x_spatial_att = self.spatial_attention(x).sigmoid()
out = x * x_spatial_att
return out
if __name__ == '__main__':
x = torch.randn(1, 64, 32, 48)
b, c, h, w = x.shape
net = GAM_Attention(in_channels=c, out_channels=c)
y = net(x)
- Experiment
在本节中,我们评估CIFAR-100上的GAM(Krizhevsky et al.)和ImageNet-1K数据集(Deng et al.)分类基准和两项消融研究。我们使用两个数据集来验证方法的泛化。请注意,这两个数据集都是分类标准。ImageNet-1K对实际应用程序的影响更大。
4.1 Classification on CIFAR-100 and ImageNet datasets
我们用两种ResNet来评估GAM(He et al.)和MobileNet V2(Sandler et al.)因为(A)它们是用于图像分类的标准体系结构(B)它们分别代表规则网络和轻量级网络。我们将GAM与SE、BAM、CBAM、TAM和AttentionBranch Network(ABN)(Fukui et al.)进行了比较。我们重新实现了网络和机制,并在相同的条件下对它们进行了价值评估。所有型号均采用四个NVIDIA Tesla V100 GPU进行培训。
对于CIFAR-100,我们评估了使用和不使用群卷积(GC)的GAM。我们对所有网络进行了200个轮次的训练,起始学习率为0.1。然后,我们在60、120和160这三个时期降低学习率。结果如表1所示。结果表明,GAM的性能优于SE、BAM和CBAM。
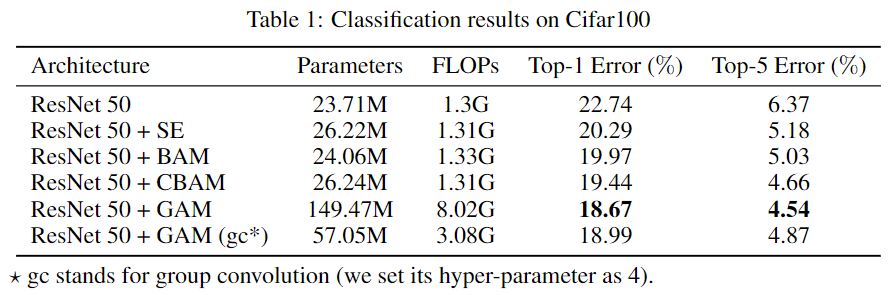
表1:Cifar100上的分类结果
对于ImageNet-1K,我们将图像预处理为224×224(He et al.)。我们包括ResNet18和ResNet50(He et al.)。验证方法在不同网络深度上的泛化。对于ResNet50,我们包括与群卷积的比较,以防止参数的显著增加。我们将起始学习率设置为0.1,每30个迭代就放弃它。我们总共使用了90个训练轮次。在空间注意力子模块中,为了匹配特征的大小,我们将第一个块的第一个步长从1切换到2。CBAM保留其他设置以进行公平比较,包括在空间关注子模块中使用最大池化。
MobileNetV2是用于图像分类的最有效的轻量级模型之一。除了使用0.045的初始学习率和4×
的权重衰减外,我们对MobileNetV2使用相同的ResNet设置。
对ImageNet-1K的评估如表2所示,它表明GAM可以稳定地提高不同神经体系结构的性能。特别是,对于ResNet18,GAM的性能优于ABN,参数更少,效率更高。
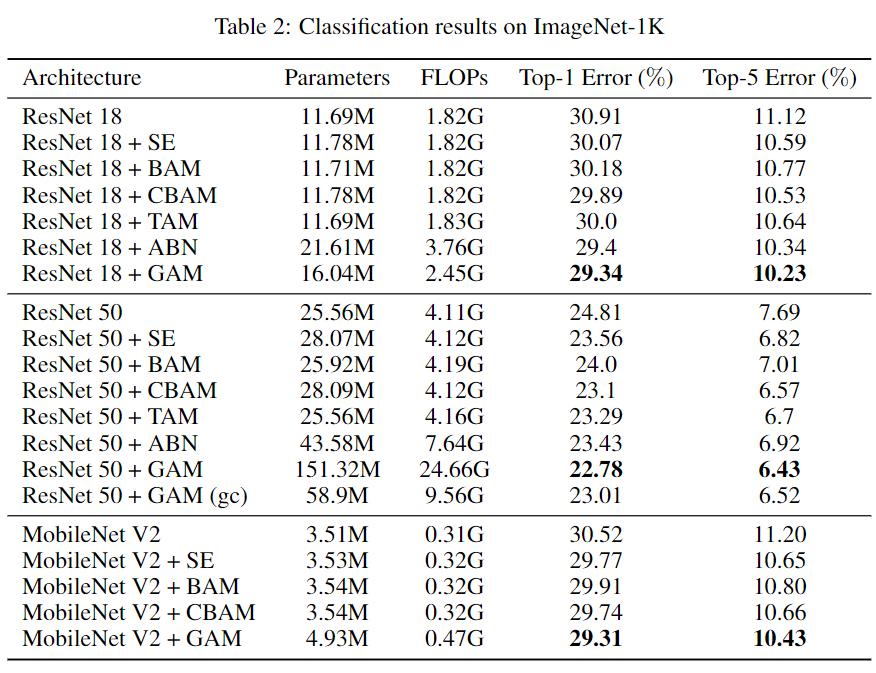
表2:ImageNet-1K上的分类结果
4.2 Ablation studies
我们用ResNet18对ImageNet-1K进行了两项消融研究。我们首先分别评估了空间注意和渠道注意的贡献。然后,我们将GAM与CBAM在有无最大汇集的情况下进行了比较。
为了更好地理解空间注意和通道注意分别对消融的贡献,我们通过开启和关闭一种方式进行了消融研究。例如,ch表示空间注意力被关闭,而频道注意力被打开。SP表示通道关注已关闭,空间关注已打开。结果如表3所示。我们可以在两个开关实验中观察到性能的提高。结果表明,空间关注度和通道关注度对性能增益均有贡献。请注意,它们的组合进一步提高了性能。
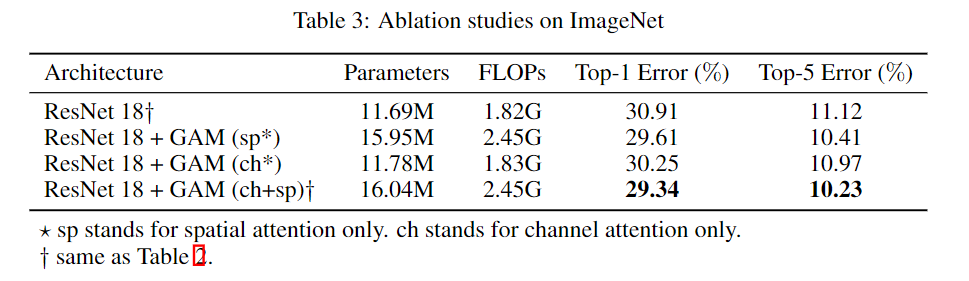
表3:在ImageNet上的消融实验
*sp仅代表空间注意。ch仅代表通道注意。†如表2所示。
最大池化可能对空间注意负贡献,这取决于神经结构(例如,ResNet)。因此,我们进行了另一项消融研究,将GAM与CBAM在使用和不使用ResNet18最大池化的情况下进行比较。表4显示了结果。可以观察到,在这两种情况下,我们的方法都优于CBAM。
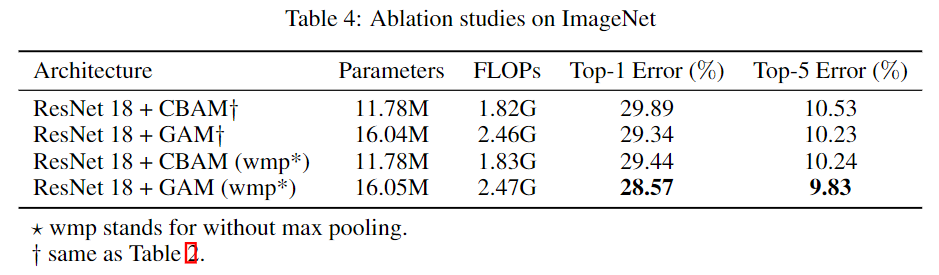
表4:在ImageNet上的消融实验
*wmp仅代表无最大池化。†如表2所示。
- Conclusion
在这项工作中,我们提出了GAM来放大显著的跨维度感受域。实验结果表明,GAM能够稳定地提高不同架构和深度的CNN的性能。
CIFAR-100和ImageNet-1K在我们的评估中作为概念证明进行了基准测试。它们表示随着类和图像数量的增加而不断扩大。因此,我们的实验表明,GAM具有良好的数据拓展能力和鲁棒性。我们认为完整的ImageNet数据集更好地服务于生产中的应用程序。大型模型训练成本很高,尤其是最新的顶级解决方案。我们用ResNet和MobileNet进行的评估也证明了它在模型缩放上的可行性。我们的目标是下一步研究GAM的详细拓展能力。
随着网络参数的增加,GAM获得性能提升。在未来,我们计划研究减少大型网络参数数量的技术,例如ResNet50、ResNet101等。同时,我们还计划探索其他利用参数减少技术的跨维度注意机制。
References
Ross Girshick, Jeff Donahue, Trevor Darrell, and Jitendra Malik. Rich feature hierarchies for accurateobject detection and semantic segmentation. In Proceedings of the IEEE conference on computervision and pattern recognition, pages 580–587, 2014.
Jonathan Long, Evan Shelhamer, and Trevor Darrell. Fully convolutional networks for semanticsegmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition,pages 3431–3440, 2015.
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for imagerecognition. In Proceedings of the IEEE conference on computer vision and pattern recognition,pages 770–778, 2016.
Christoph H Lampert, Hannes Nickisch, and Stefan Harmeling. Learning to detect unseen objectclasses by between-class attribute transfer. In 2009 IEEE Conference on Computer Vision andPattern Recognition, pages 951–958. IEEE, 2009.
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scalehierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition,pages 248–255. Ieee, 2009.
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep con-volutional neural networks. Advances in neural information processing systems, 25:1097–1105,2012.
Xiaohua Zhai, Alexander Kolesnikov, Neil Houlsby, and Lucas Beyer. Scaling vision transformers.arXiv preprint arXiv:2106.04560, 2021.
Zhaoyang Niu, Guoqiang Zhong, and Hui Yu. A review on the attention mechanism of deep learning.Neurocomputing, 452:48–62, 2021.
Fei Wang, Mengqing Jiang, Chen Qian, Shuo Yang, Cheng Li, Honggang Zhang, Xiaogang Wang,and Xiaoou Tang. Residual attention network for image classification. In Proceedings of the IEEEconference on computer vision and pattern recognition, pages 3156–3164, 2017.
Jie Hu, Li Shen, and Gang Sun. Squeeze-and-excitation networks. In Proceedings of the IEEEconference on computer vision and pattern recognition, pages 7132–7141, 2018.
Sanghyun Woo, Jongchan Park, Joon-Young Lee, and In So Kweon. Cbam: Convolutional blockattention module. In Proceedings of the European conference on computer vision (ECCV), pages3–19, 2018.
Jongchan Park, Sanghyun Woo, Joon-Young Lee, and In So Kweon. Bam: Bottleneck attentionmodule. arXiv preprint arXiv:1807.06514, 2018.
Diganta Misra, Trikay Nalamada, Ajay Uppili Arasanipalai, and Qibin Hou. Rotate to attend:Convolutional triplet attention module. In Proceedings of the IEEE/CVF Winter Conference onApplications of Computer Vision, pages 3139–3148, 2021.
Xiangyu Zhang, Xinyu Zhou, Mengxiao Lin, and Jian Sun. Shufflenet: An extremely efficientconvolutional neural network for mobile devices. In Proceedings of the IEEE conference oncomputer vision and pattern recognition, pages 6848–6856, 2018.
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009.
Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, and Liang-Chieh Chen. Mo-bilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE conference oncomputer vision and pattern recognition, pages 4510–4520, 2018.
Hiroshi Fukui, Tsubasa Hirakawa, Takayoshi Yamashita, and Hironobu Fujiyoshi. Attention branchnetwork: Learning of attention mechanism for visual explanation. In Proceedings of the IEEE/CVFConference on Computer Vision and Pattern Recognition, pages 10705–10714, 2019.
Original: https://blog.csdn.net/m0_53232749/article/details/123208991
Author: 刘可乐呀
Title: 【GAM全文翻译及代码实现】Global Attention Mechanism: Retain Information to Enhance Channel-Spatial Interactions
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/688393/
转载文章受原作者版权保护。转载请注明原作者出处!