

SimCLR图像分类 pytorch复现
一、网络模型、损失函数
1.原理
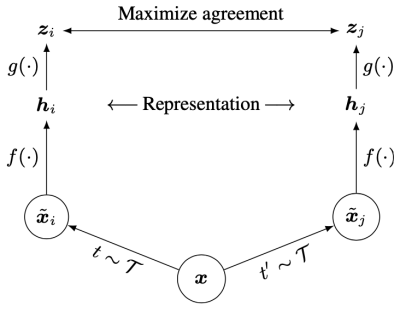
SimCLR(A Simple Framework for Contrastive Learning of Visual Representations)是一种对比学习网络,可以对含有少量标签的数据集进行训练推理,它包含无监督学习和有监督学习两个部分。
无监督学习网络特征提取采用resnet50,将输入层进行更改,并去掉池化层及全连接层。之后将特征图平坦化,并依次进行全连接、批次标准化、relu激活、全连接,得到输出特征。
有监督学习网络使用无监督学习网络的特征提取层及参数,之后由一个全连接层得到分类输出。
在第一阶段先进行无监督学习,对输入图像进行两次随机图像增强,即由一幅图像得到两个随机处理过后的图像,依次放入网络进行训练,计算损失并更新梯度。
这一阶段损失函数为:
其中,x+为与x相似的样本,x-为与x不相似的样本。第二阶段,加载第一阶段的特征提取层训练参数,用少量带标签样本进行有监督学习(只训练全连接层)。这一阶段损失函数为交叉熵损失函数CrossEntropyLoss。
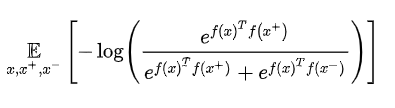
; 2.code
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision.models.resnet import resnet50
class SimCLRStage1(nn.Module):
def __init__(self, feature_dim=128):
super(SimCLRStage1, self).__init__()
self.f = []
for name, module in resnet50().named_children():
if name == 'conv1':
module = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False)
if not isinstance(module, nn.Linear) and not isinstance(module, nn.MaxPool2d):
self.f.append(module)
self.f = nn.Sequential(*self.f)
self.g = nn.Sequential(nn.Linear(2048, 512, bias=False),
nn.BatchNorm1d(512),
nn.ReLU(inplace=True),
nn.Linear(512, feature_dim, bias=True))
def forward(self, x):
x = self.f(x)
feature = torch.flatten(x, start_dim=1)
out = self.g(feature)
return F.normalize(feature, dim=-1), F.normalize(out, dim=-1)
class SimCLRStage2(torch.nn.Module):
def __init__(self, num_class):
super(SimCLRStage2, self).__init__()
self.f = SimCLRStage1().f
self.fc = nn.Linear(2048, num_class, bias=True)
for param in self.f.parameters():
param.requires_grad = False
def forward(self, x):
x = self.f(x)
feature = torch.flatten(x, start_dim=1)
out = self.fc(feature)
return out
class Loss(torch.nn.Module):
def __init__(self):
super(Loss,self).__init__()
def forward(self,out_1,out_2,batch_size,temperature=0.5):
out = torch.cat([out_1, out_2], dim=0)
sim_matrix = torch.exp(torch.mm(out, out.t().contiguous()) / temperature)
mask = (torch.ones_like(sim_matrix) - torch.eye(2 * batch_size, device=sim_matrix.device)).bool()
sim_matrix = sim_matrix.masked_select(mask).view(2 * batch_size, -1)
pos_sim = torch.exp(torch.sum(out_1 * out_2, dim=-1) / temperature)
pos_sim = torch.cat([pos_sim, pos_sim], dim=0)
return (- torch.log(pos_sim / sim_matrix.sum(dim=-1))).mean()
if __name__=="__main__":
for name, module in resnet50().named_children():
print(name,module)
二、配置文件
公共参数写入配置文件
import os
from torchvision import transforms
use_gpu=True
gpu_name=1
pre_model=os.path.join('pth','model.pth')
save_path="pth"
train_transform = transforms.Compose([
transforms.RandomResizedCrop(32),
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomApply([transforms.ColorJitter(0.4, 0.4, 0.4, 0.1)], p=0.8),
transforms.RandomGrayscale(p=0.2),
transforms.ToTensor(),
transforms.Normalize([0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010])])
test_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010])])
三、无监督学习数据加载
使用CIFAR-10数据集,一共包含10个类别的RGB彩色图片:飞机(airplane)、汽车(automobile)、鸟类(bird)、猫(cat)、鹿(deer)、狗(dog)、蛙类(frog)、马(horse)、船(ship)和卡车(truck)。图片的尺寸为32×32,数据集中一共有50000张训练图片片和10000张测试图片。
from torchvision.datasets import CIFAR10
from PIL import Image
class PreDataset(CIFAR10):
def __getitem__(self, item):
img,target=self.data[item],self.targets[item]
img = Image.fromarray(img)
if self.transform is not None:
imgL = self.transform(img)
imgR = self.transform(img)
if self.target_transform is not None:
target = self.target_transform(target)
return imgL, imgR, target
if __name__=="__main__":
import config
train_data = PreDataset(root='dataset', train=True, transform=config.train_transform, download=True)
print(train_data[0])
四、无监督训练
import torch,argparse,os
import net,config,loaddataset
def train(args):
if torch.cuda.is_available() and config.use_gpu:
DEVICE = torch.device("cuda:" + str(config.gpu_name))
torch.backends.cudnn.benchmark = True
else:
DEVICE = torch.device("cpu")
print("current deveice:", DEVICE)
train_dataset=loaddataset.PreDataset(root='dataset', train=True, transform=config.train_transform, download=True)
train_data=torch.utils.data.DataLoader(train_dataset,batch_size=args.batch_size, shuffle=True, num_workers=16 , drop_last=True)
model =net.SimCLRStage1().to(DEVICE)
lossLR=net.Loss().to(DEVICE)
optimizer=torch.optim.Adam(model.parameters(), lr=1e-3, weight_decay=1e-6)
os.makedirs(config.save_path, exist_ok=True)
for epoch in range(1,args.max_epoch+1):
model.train()
total_loss = 0
for batch,(imgL,imgR,labels) in enumerate(train_data):
imgL,imgR,labels=imgL.to(DEVICE),imgR.to(DEVICE),labels.to(DEVICE)
_, pre_L=model(imgL)
_, pre_R=model(imgR)
loss=lossLR(pre_L,pre_R,args.batch_size)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print("epoch", epoch, "batch", batch, "loss:", loss.detach().item())
total_loss += loss.detach().item()
print("epoch loss:",total_loss/len(train_dataset)*args.batch_size)
with open(os.path.join(config.save_path, "stage1_loss.txt"), "a") as f:
f.write(str(total_loss/len(train_dataset)*args.batch_size) + " ")
if epoch % 5==0:
torch.save(model.state_dict(), os.path.join(config.save_path, 'model_stage1_epoch' + str(epoch) + '.pth'))
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='Train SimCLR')
parser.add_argument('--batch_size', default=200, type=int, help='')
parser.add_argument('--max_epoch', default=1000, type=int, help='')
args = parser.parse_args()
train(args)
五、有监督训练
import torch,argparse,os
import net,config
from torchvision.datasets import CIFAR10
from torch.utils.data import DataLoader
def train(args):
if torch.cuda.is_available() and config.use_gpu:
DEVICE = torch.device("cuda:" + str(2))
torch.backends.cudnn.benchmark = True
else:
DEVICE = torch.device("cpu")
print("current deveice:", DEVICE)
train_dataset = CIFAR10(root='dataset', train=True, transform=config.train_transform, download=True)
train_data = DataLoader(train_dataset, batch_size=args.batch_size, shuffle=True, num_workers=16, pin_memory=True)
eval_dataset = CIFAR10(root='dataset', train=False, transform=config.test_transform, download=True)
eval_data = DataLoader(eval_dataset, batch_size=args.batch_size, shuffle=False, num_workers=16, pin_memory=True)
model =net.SimCLRStage2(num_class=len(train_dataset.classes)).to(DEVICE)
model.load_state_dict(torch.load(args.pre_model, map_location='cpu'),strict=False)
loss_criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.fc.parameters(), lr=1e-3, weight_decay=1e-6)
os.makedirs(config.save_path, exist_ok=True)
for epoch in range(1,args.max_epoch+1):
model.train()
total_loss=0
for batch, (data, target) in enumerate(train_data):
data, target = data.to(DEVICE), target.to(DEVICE)
pred = model(data)
loss = loss_criterion(pred, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
print("epoch",epoch,"loss:", total_loss / len(train_dataset)*args.batch_size)
with open(os.path.join(config.save_path, "stage2_loss.txt"), "a") as f:
f.write(str(total_loss / len(train_dataset)*args.batch_size) + " ")
if epoch % 5==0:
torch.save(model.state_dict(), os.path.join(config.save_path, 'model_stage2_epoch' + str(epoch) + '.pth'))
model.eval()
with torch.no_grad():
print("batch", " " * 1, "top1 acc", " " * 1, "top5 acc")
total_loss, total_correct_1, total_correct_5, total_num = 0.0, 0.0, 0.0, 0
for batch, (data, target) in enumerate(train_data):
data, target = data.to(DEVICE), target.to(DEVICE)
pred = model(data)
total_num += data.size(0)
prediction = torch.argsort(pred, dim=-1, descending=True)
top1_acc = torch.sum((prediction[:, 0:1] == target.unsqueeze(dim=-1)).any(dim=-1).float()).item()
top5_acc = torch.sum((prediction[:, 0:5] == target.unsqueeze(dim=-1)).any(dim=-1).float()).item()
total_correct_1 += top1_acc
total_correct_5 += top5_acc
print(" {:02} ".format(batch + 1), " {:02.3f}% ".format(top1_acc / data.size(0) * 100),
"{:02.3f}% ".format(top5_acc / data.size(0) * 100))
print("all eval dataset:", "top1 acc: {:02.3f}%".format(total_correct_1 / total_num * 100),
"top5 acc:{:02.3f}%".format(total_correct_5 / total_num * 100))
with open(os.path.join(config.save_path, "stage2_top1_acc.txt"), "a") as f:
f.write(str(total_correct_1 / total_num * 100) + " ")
with open(os.path.join(config.save_path, "stage2_top5_acc.txt"), "a") as f:
f.write(str(total_correct_5 / total_num * 100) + " ")
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='Train SimCLR')
parser.add_argument('--batch_size', default=200, type=int, help='')
parser.add_argument('--max_epoch', default=200, type=int, help='')
parser.add_argument('--pre_model', default=config.pre_model, type=str, help='')
args = parser.parse_args()
train(args)
六、训练并查看过程
使用visdom,对训练过程保存的loss、acc进行可视化
由于时间关系,只训练了较少的epoch
import numpy as np
import visdom
def show_loss(path, name, step=1):
with open(path, "r") as f:
data = f.read()
data = data.split(" ")[:-1]
x = np.linspace(1, len(data) + 1, len(data)) * step
y = []
for i in range(len(data)):
y.append(float(data[i]))
vis = visdom.Visdom(env='loss')
vis.line(X=x, Y=y, win=name, opts={'title': name, "xlabel": "epoch", "ylabel": name})
def compare2(path_1, path_2, title="xxx", legends=["a", "b"], x="epoch", step=20):
with open(path_1, "r") as f:
data_1 = f.read()
data_1 = data_1.split(" ")[:-1]
with open(path_2, "r") as f:
data_2 = f.read()
data_2 = data_2.split(" ")[:-1]
x = np.linspace(1, len(data_1) + 1, len(data_1)) * step
y = []
for i in range(len(data_1)):
y.append([float(data_1[i]), float(data_2[i])])
vis = visdom.Visdom(env='loss')
vis.line(X=x, Y=y, win="compare",
opts={"title": "compare " + title, "legend": legends, "xlabel": "epoch", "ylabel": title})
if __name__ == "__main__":
show_loss("stage1_loss.txt", "loss1")
show_loss("stage2_loss.txt", "loss2")
show_loss("stage2_top1_acc.txt", "acc1")
show_loss("stage2_top5_acc.txt", "acc1")
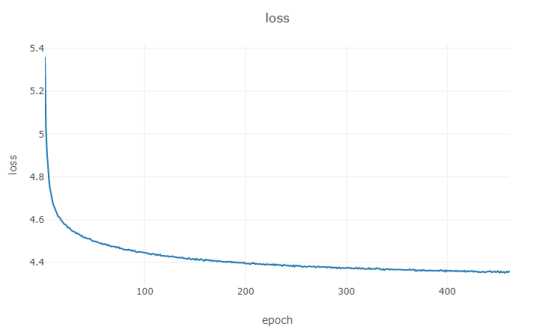
无监督学习损失变化曲线:
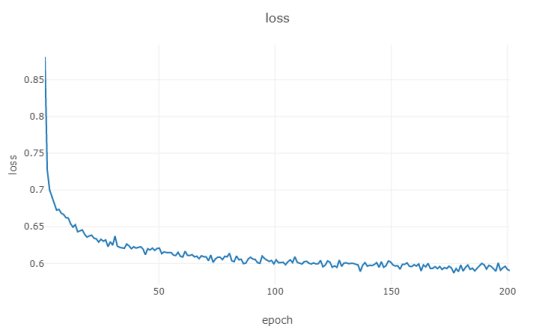
有监督学习损失变化曲线
七、验证集评估
import torch,argparse
from torchvision.datasets import CIFAR10
import net,config
def eval(args):
if torch.cuda.is_available() and config.use_gpu:
DEVICE = torch.device("cuda:" + str(config.gpu_name))
torch.backends.cudnn.benchmark = True
else:
DEVICE = torch.device("cpu")
eval_dataset=CIFAR10(root='dataset', train=False, transform=config.test_transform, download=True)
eval_data=torch.utils.data.DataLoader(eval_dataset,batch_size=args.batch_size, shuffle=False, num_workers=16, )
model=net.SimCLRStage2(num_class=len(eval_dataset.classes)).to(DEVICE)
model.load_state_dict(torch.load(config.pre_model, map_location='cpu'), strict=False)
total_correct_1, total_correct_5, total_num = 0.0, 0.0, 0.0
model.eval()
with torch.no_grad():
print("batch", " "*1, "top1 acc", " "*1,"top5 acc" )
for batch, (data, target) in enumerate(eval_data):
data, target = data.to(DEVICE) ,target.to(DEVICE)
pred=model(data)
total_num += data.size(0)
prediction = torch.argsort(pred, dim=-1, descending=True)
top1_acc = torch.sum((prediction[:, 0:1] == target.unsqueeze(dim=-1)).any(dim=-1).float()).item()
top5_acc = torch.sum((prediction[:, 0:5] == target.unsqueeze(dim=-1)).any(dim=-1).float()).item()
total_correct_1 += top1_acc
total_correct_5 += top5_acc
print(" {:02} ".format(batch+1)," {:02.3f}% ".format(top1_acc / data.size(0) * 100),"{:02.3f}% ".format(top5_acc / data.size(0) * 100))
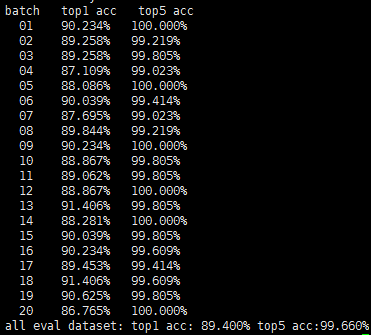
print("all eval dataset:","top1 acc: {:02.3f}%".format(total_correct_1 / total_num * 100), "top5 acc:{:02.3f}%".format(total_correct_5 / total_num * 100))
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='test SimCLR')
parser.add_argument('--batch_size', default=512, type=int, help='')
args = parser.parse_args()
eval(args)
八、自定义图片测试
import torch,argparse
import net,config
from torchvision.datasets import CIFAR10
import cv2
def show_CIFAR10(index):
eval_dataset=CIFAR10(root='dataset', train=False, download=False)
print(eval_dataset.__len__())
print(eval_dataset.class_to_idx,eval_dataset.classes)
img, target=eval_dataset[index][0], eval_dataset[index][1]
import matplotlib.pyplot as plt
plt.figure(str(target))
plt.imshow(img)
plt.show()
def test(args):
classes={'airplane': 0, 'automobile': 1, 'bird': 2, 'cat': 3, 'deer': 4, 'dog': 5, 'frog': 6, 'horse': 7, 'ship': 8, 'truck': 9}
index2class=[x for x in classes.keys()]
print("calss:",index2class)
if torch.cuda.is_available() and config.use_gpu:
DEVICE = torch.device("cuda:" + str(config.gpu_name))
torch.backends.cudnn.benchmark = True
else:
DEVICE = torch.device("cpu")
transform = config.test_transform
ori_img=cv2.imread(args.img_path,1)
img=cv2.resize(ori_img,(32,32))
img=transform(img).unsqueeze(dim=0).to(DEVICE)
model=net.SimCLRStage2(num_class=10).to(DEVICE)
model.load_state_dict(torch.load(args.pre_model, map_location='cpu'), strict=False)
pred = model(img)
prediction = torch.argsort(pred, dim=-1, descending=True)
label=index2class[prediction[:, 0:1].item()]
cv2.putText(ori_img,"this is "+label,(30,30),cv2.FONT_HERSHEY_DUPLEX,1, (0,255,0), 1)
cv2.imshow(label,ori_img)
cv2.waitKey(0)
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='test SimCLR')
parser.add_argument('--pre_model', default=config.pre_model, type=str, help='')
parser.add_argument('--img_path', default="bird.jpg", type=str, help='')
args = parser.parse_args()
test(args)
输入图片:
输出:Original: https://blog.csdn.net/qq_43027065/article/details/118657728
Author: 朽一
Title: SimCLR图像分类——pytorch复现






原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/688066/
转载文章受原作者版权保护。转载请注明原作者出处!