

学习实体和关系嵌入在完成知识图谱中的应用
*
– 1 题目
– 2 摘要
– 3 问题定义
– 4 方法及原理
–
+ 4.1 TransE模型[2]
+ 4.2 TransH模型[3]
+ 4.3 TransR模型
– 5 研究成果
–
+ 5.1 链接预测
+ 5.2 关系抽取
+ 5.3 三元组分类
– 6 创新点
– 7 个人体会
1 题目
英文原标题:
Learning Entity and Relation Embeddings for Knowledge Graph Completion
中文译题:
学习实体和关系嵌入在完成知识图谱中的应用
2 摘要
论文摘要的中文翻译内容
知识图谱补全意在实现目标实体之间的链接预测。在本论文中,作者研究了知识图谱的表征方法。最近的TransE和TransH模型都是通过将关系视为一种从头实体(Head)到尾实体(Tail)的一种翻译机制来获得实体和关系之间的表征关系。在现实生活中,一个实体可能有不同的特征,关系可能是关注于实体不同方面的特征,这种情况下,公共的实体特征空间不足以进行表征。在本论文中,我们提出TransR模型来在分离的实体空间和关系空间中,构建实体和关系表征。训练表征向量分两步走:
- 首先将实体映射到关系空间中
- 再在两个投影空间中构建翻译关系
论文中的模型在 链接预测、三元组分类和关系抽取三个任务中都得到验证,相较于TransE和TransH都有了一定提升。
3 问题定义
本文中涉及到的三个问题是关系抽取、链接预测和三元组分类。
知识图编码实体的结构化信息,其中含有各种各样的关系信息。一个知识图谱的体量可能会很大,可能含有数百万实体和数十亿的关系,但是它通常并不是完整的,多实体之下必然会存在庞大的关系网络,知识图谱补全所做的工作就是根据现有知识图的实体和关系的监督学习之下,补全找到新的关系事实,这也是研究所面临的关系抽取问题的来源。
在实际应用中知识图谱具有挑战性,在两个方面体现出来,一是节点是具有不同类型和属性的实体,即单纯将这样不同的实体草率的映射到相同的语义空间是不对;二是边也是不同类型的关系,我们对于关系,不仅需要确定实体之间是否存在关系,还要预测出来关系的特定类型。
将知识图嵌入到连续向量空间,是近年来研究的主要方向,这种方法代替了传统的链接预测方法。
一个实体是多方面的,不同的关系涉及的可能是实体的不同方面,在这样的情况下,我们简单的将关系和实体映射到相同的语义空间中是不正确的。TransR模型解决的主要问题就是如何将实体空间和关系空间分离开,如何将同一实体的不同关系表示出来。
4 方法及原理
本论文中提出TransR[1]模型,是对TransE和TransH模型的一个提升,论文中介绍了以往的一些模型,着重介绍的是TransE和TransH。
4.1 TransE模型[2]
TransE模型,是在word2vec的启发下,头实体与关系加和之后接近尾实体,对于三元组(h,r,t),其中h、r、t分别表示头实体、关系和尾实体。Trans系列的核心思想是把h、r、t三者的关系抽象成一种翻译机制。
TransE模型利用 h + r ≈ t来实现向量训练,评分函数如下:
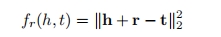

; 4.2 TransH模型[3]
TransH模型优化的也是复杂关系的建模,但是它聚焦了关系两端连接的实体数量,即四种复杂关系1-1、1-N、N-1、N-N。
TransH模型是通过给每一个关系r,都通过一个超平面Wr和一个关系向量dr表示,将关系分离出实体的嵌入空间。
将h和t都映射到新建的超平面中得到h⊥和t⊥,通过h⊥+dr ≈ t⊥来实现训练,这样做的目的是使得同一个实体在不同关系中意义不同,即通过不同关系建立超平面(即法平面)不同来实现。
TransH的评分函数也较TransE做了相对应的调整。
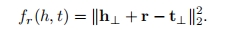
4.3 TransR模型
TransR模型的提出是在TransE和TransH的基础上来实现的,将实体和关系分别映射到不同的两个语义空间中,即论文中提到的entity space和relation space,两个语义空间的关系是:对于三元组(h,r,t),首先根据关系r将实体空间中的h和t分别映射到关系空间中,记作hr和tr。
hr = hMr, tr = tMr
在关系空间中建立如下模型:
hr + r ≈ tr
评分标准为定义为如下函数:

并且存在某些特定关系,实体可能会表现出不同的模式,不能单纯将关系和实体直接对应,需要借助聚类,将不同的头尾实体聚类成不同的组,对每个组不同的关系向量扩展TransR,该种方法基于聚类,也被称为CTransR。
对于聚类的每一簇, 我们分别为每个簇学习一个单独的关系向量rc和关系矩阵Mr,将实体中 的hr,c = hMr ,tr,c=tMr ,分数函数也进行相应调整:
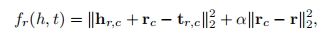
||rc-r||2 2确保了rc向量不会偏离r向量太远。然后它的系数α约束了该式对于分数的影响,其他方面CTransR同TransR大体相同。
训练过程之中,作者定义了基于边际的分数函数作为训练的标准,其中错误三元组的构建是通过替换头尾实体来进行构建。
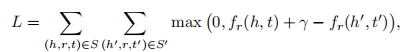
; 5 研究成果
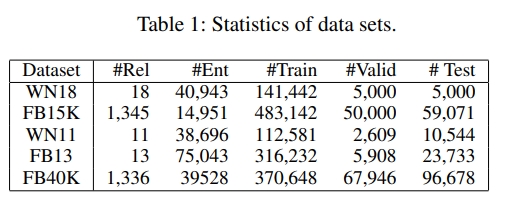
实验中使用的经典数据集的分配比例见表一。
TransR模型的评估主要在链接链接预测、三元组分类和关系抽取。
实验中使用的评价指标有两种,Mean Rank 和 Hits@10(%),下面对这两种评价指标进行简单解释。
Mean Rank
对于每个测试三元组,以预测尾实体,将三元组的tail entity用知识图谱中每个实体替换,函数建模,计算分数,按照升序对分数进行排列。
然后根据真实的t在序列中排名,求得平均,这样得到的评估分数就是Mean
Hits@10(%)
在评估过程中,我们并不是直接看正确答案是否被准确预测,而是看每一个预测三元组的正确答案是否能排进序列前十。Hit@10(%)的分数
Hit_score = (排在前十个数)/总个数
论文中进行了一步过滤,将人为构建的负例三元组过滤掉之后进行评测,负例三元组指得是构建之后已经存在知识图谱中的三元组。
Raw项指的是过滤之前的评估分数,Filter指的是过滤负例三元组之后的评估分数。
5.1 链接预测
表中提到的unif和bern是两种负采样方式。
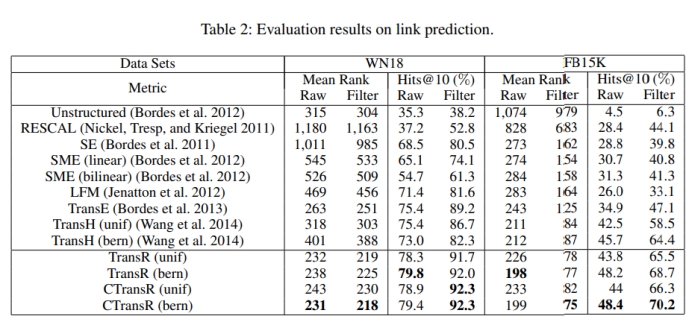
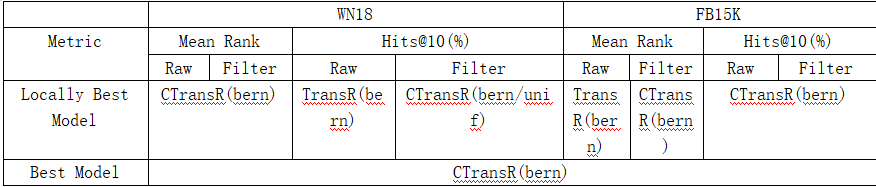
根据图中评估结果,我绘制了如下总结表格:
在WN18数据集上,以Hits@10(%)为评价指标,CTransR在unif和bern两种采样策略上都表现突出,优于论文发表之前的所有模型,且比TransR效果突出,Filter项目下,模型得到了92.3%的高分。
以bern为采样方式,Mean Rank评估指标下,CTransR在Raw和Filter两种情况下,都取得了该评估项目的最高分。
对于FB15K数据集,TransR(bern)模型在Mean Rank(Raw)评估指标下表现最优异,而过滤之后,CTransR(bern)表现最为突出。
在该数据集情况下,CTransR(bern)取得了Hits@10(%)评分下Raw和Filter的双高分。
根据Table2,我们可以对链接预测这方面问题,TransR的效果得到初步结论,以bern为采样策略的CTransR模型脱颖而出,效果拔群。
; 5.2 关系抽取
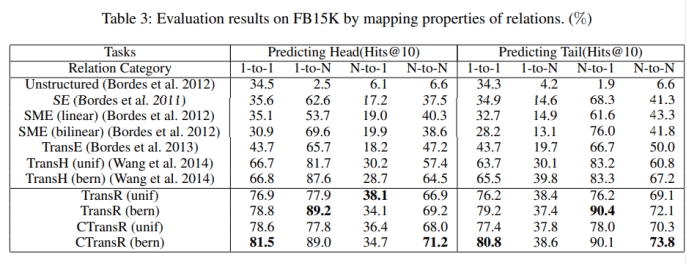
Table3展示了TransR系列模型和相关模型在FB15K数据集上,以Hits@10为评估指标,对关系抽取中头实体预测和尾实体预测两个经典任务进行模型测评与对比。
在头实体预测任务中,四种情况下效果最好的模型均是TransR系列模型,TransR和CTransR在关系抽取任务上表现突出,优于以往的若干模型。
在尾实体预测任务中,CTransR(bern)取得了1-to-1任务、N-to-N任务的最好成绩;N-to-1任务中,TransR(bern)表现突出。
但是遗憾的是,在尾实体1-to-N关系抽取任务中,TransR系列模型的效果并没有超过TransH(bern)模型,但差距不大。
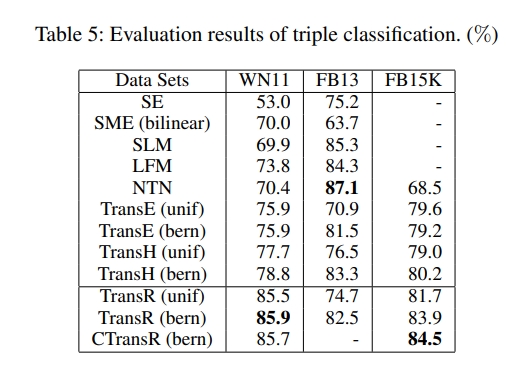
5.3 三元组分类
Table5展示了三元组分类的效果。在WN11数据集上TransR表现突出,优于包括TransE和TransH在内的其他模型。在FB15K数据集上,CTransR表现优异。
但是我们也发现,TransR模型在FB13数据集上表现远没有NTN模型表现优秀,但是论文中提到,在FB15K大数据量情况中,TransR、TransE、TransH都比NTN表现优秀,这在一定程度上说明结果很可能是与训练集中关系类型数量有关,FB13中只有13种关系类型,而FB15K中1345种关系,且在两个数据集种,实体和关系的数量是接近的。
之前的研究中,FB13的知识图谱复杂程度是高于FB15K和WN11的,NTN模型在复杂知识图谱数据集上表现突然,在一定程度上说明,NTN可以利用FB13进行张量变换学习其中复杂的相关性。
对于稀疏图谱的学习,更简单的模型能够更好胜任工作,并且具有更好的泛化性,在本任务的结果中,”bern”采样方法在三个数据集上都提升了模型的效果。
TransE和TransH的训练时间分别是5分钟和30分钟,TransR模型的计算复杂度相对较高,训练时间需要大约3个小时,TransR计算消耗资源较多,这方面仍需要提升。

准确度-召回率曲线图表如上,该曲线是作者根据之前论文的研究成果,参数设定嵌入维度k,d为50,学习率0.001,边距γ=1.0,B=960,不相似度的度量设置为L1
曲线分析
在召回率[0,0.5]范围内,TransR优于TransE模型效果,在召回率[0.5,1.0]范围内,TransR优于包括TransE和TransH在内的所有评价模型。
; 6 创新点
探讨TransR的创新点,要建立在跟以往论文的比较之中,在TransR的提出之前,TransE和TransH都取得了一定的成果,但是它们都是将实体和关系混杂于同一语义空间,因此基于以上事实,我们讨论关于这篇论文的创新点所在。
将实体和关系嵌入在不同的语义空间。这篇论文中提到的技术是将实体和关系嵌入到不同的实体空间和关系空间之中,并且通过实体之间的平移来学习嵌入,模型对于实体关系的学习模式更加贴合实际。
CTransR初探索。本文将聚类算法引入,同基础版的TransR模型结合提出了CTransR模型,这个模型是基于分段线性回归的概念来对每个关系类型内的内部复杂相关性进行建模。
多任务评价体系。TransR的评估是在链接预测、三元组分类和文本抽取三个领域开展的,通过对结果的分析,同TransE和TransH相比,TransR都取得了一定程度的效果改善
7 个人体会
TransR可能不是一个很优秀的模型,在以上三个任务的准确度上提升相对来说并不多,我在挑选要阅读的论文时,看到了Trans系列的论文,我选择TransR是希望知道一个技术是如何承上启下的。
在TransR被提出之前,有TransE和TransH;在TransR被提出之后,也有TransD等更加优秀的模型。最新的模型一定不会是最好的模型,还会有更多研究人员前赴后继,为推动领域革新而努力。
知识表示经历了蓬勃的发展,从1948年至今,主要经历了一阶谓词逻辑表示、产生式规则、框架表示法、脚本表示法、语义网表示法、知识图谱表示法,知识图谱还是现在的主流知识表示法,它很好的将知识表示和机器学习、神经网络等技术打通,比如这篇论文中引入的聚类方法,是非监督学习的一种。
知识表示的主要研究很多已经聚焦在知识图谱上,对于知识图谱的潜力大家很期待,但我们仍需要聚焦于多个问题:
如何在前人累累的研究成果上做出自己的创新?
如何将知识工程等演绎方法同机器学习等归纳推理方法有机统一?
这可能是我们新一代人工智能求道者需要思考的主要方向,也是人工智能被给予希望的关键点。道阻且长,我愿以自己微薄之力投身其中!
参考文献
[1] SHAOZHI DAI, YANCHUN LIANG, SHUYAN LIU, et al. Learning Entity and Relation Embeddings with Entity Description for Knowledge Graph Completion[C]. //Proceedings of the 2018 2nd International Conference on Artificial Intelligence: Technologies and Applications (ICAITA 2018).Paris, France:Atlantis Press, 2018. DOI:10.2991/icaita-18.2018.49.
[2] ANTOINE BORDES, NICOLAS USUNIER, ALBERTO GARCIA-DURAN, et al. Translating Embeddings for Modeling Multi-relational Data[C]. //Advances in Neural Information Processing Systems 26, vol. 4: 27th annual conference on Neural Information Processing Systems 2013, December 5-10, 2013, Lake Tahoe, Nevada, USA.:Neural Information Processing Systems, 2013:2799-2807.
[3] ZHEN WANG, JIANWEN ZHANG, JIANLIN FENG, et al. Knowledge Graph Embedding by Translating on Hyperplanes[C]. //Proceedings of the twenty-eighth AAAI conference on artificial intelligence and the twenty-sixth innovative applications of artificial intelligence conference: 27-31 July 2014, Quebec Ciry, Quebec, Canada, v.2.:AAAI Press, 2014:1112-1119.
[4] Meenakshi Malhotra and T. R. Gopalakrishnan Nair. Evolution of Knowledge Representation and Retrieval Techniques[J]. International Journal of Intelligent Systems and Applications(IJISA), 2015, 7(7) : 18-28.
[5] Knowledge Graph Embedding via Dynamic Mapping Matrix[C]// Meeting of the Association for Computational Linguistics & the International Joint Conference on Natural Language Processing. 2015.
Original: https://blog.csdn.net/weixin_45841983/article/details/120825809
Author: HL Lee
Title: 【论文笔记】《Learning Entity and Relation Embeddings for Knowledge Graph Completion》
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/557438/
转载文章受原作者版权保护。转载请注明原作者出处!