

前言
如果说在CNN领域一定要学习一个卷积神经网络,那一定非Resnet莫属了。
接下来我将按照:Resnet论文解读、Pytorch实现ResNet50模型两部分,进行讲解,博主也是初学者,不足之处欢迎大家批评指正。
预备知识:卷积网络的深度越深,提取的特征越高级,性能越好,但传统的卷积神经网络随着层数深度的增加,会面临网络退化、梯度消失、梯度爆炸等问题,使得高层网络的性能反而不如浅层网络。
卷积细节: 将一个(W,H,C)的3维矩阵,输入卷积层,卷积 步长stride,边界 填充数量padding, KxK卷积核Cout个:
输出一个(W-K+2 _padding)/stride +1,(H-K+2_padding)/stride +1,Cout)的3维矩阵。
网络退化: 深层网络训练模型可收敛,但在测试集和训练集的误差均大于浅层网络。
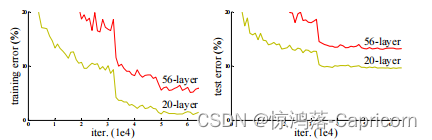

梯度消失: 假设每层梯度是一个小于1的数,由链式法则,反向传播时,梯度时不断相乘的,每向前传播一层,梯度就乘以一个小于1的数,传到最后一层,梯度已经接近0了,这就是梯度消失,换句话说就是,小于1的数连成很快会趋近于0。
梯度爆炸: 反之,如果每层梯度是一个大于1的数,大于1的数连成很快会趋近于无穷。
为解决上述问题
Resnet创新亮点:
1.解决梯度消失\爆炸问题:引入BN层(Batch Normalization),弃用Dropout
2.解决网络退化问题:引入残差(Residual)
`提示:以下是本篇文章正文
一、Resnet论文精读
引入残差
残差的基本思想:真实测量值=预测值+残差
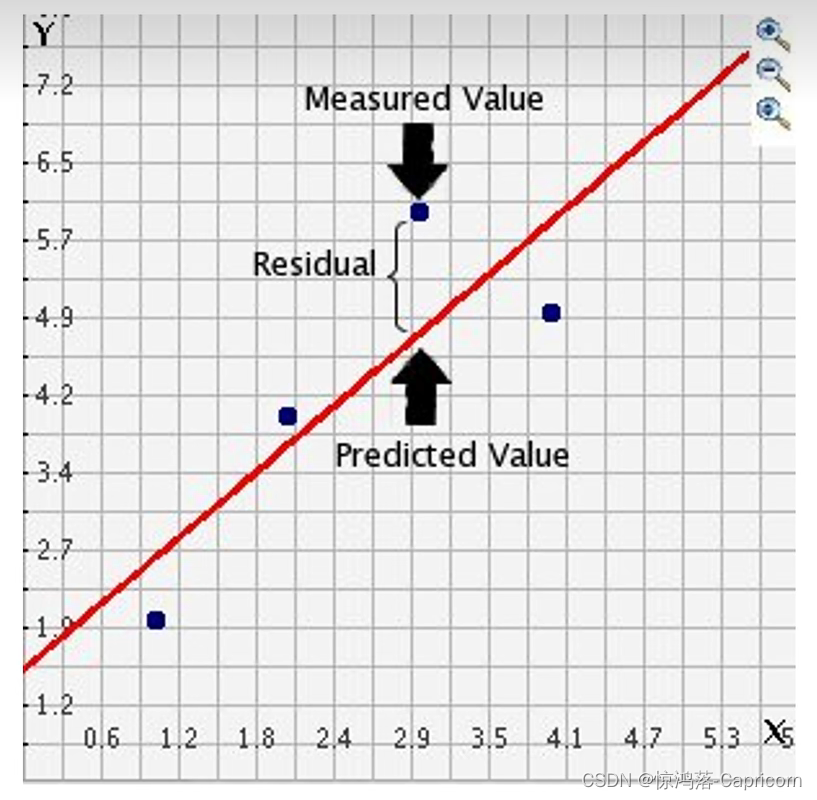
**
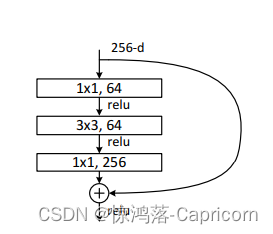
; 残差块
**:
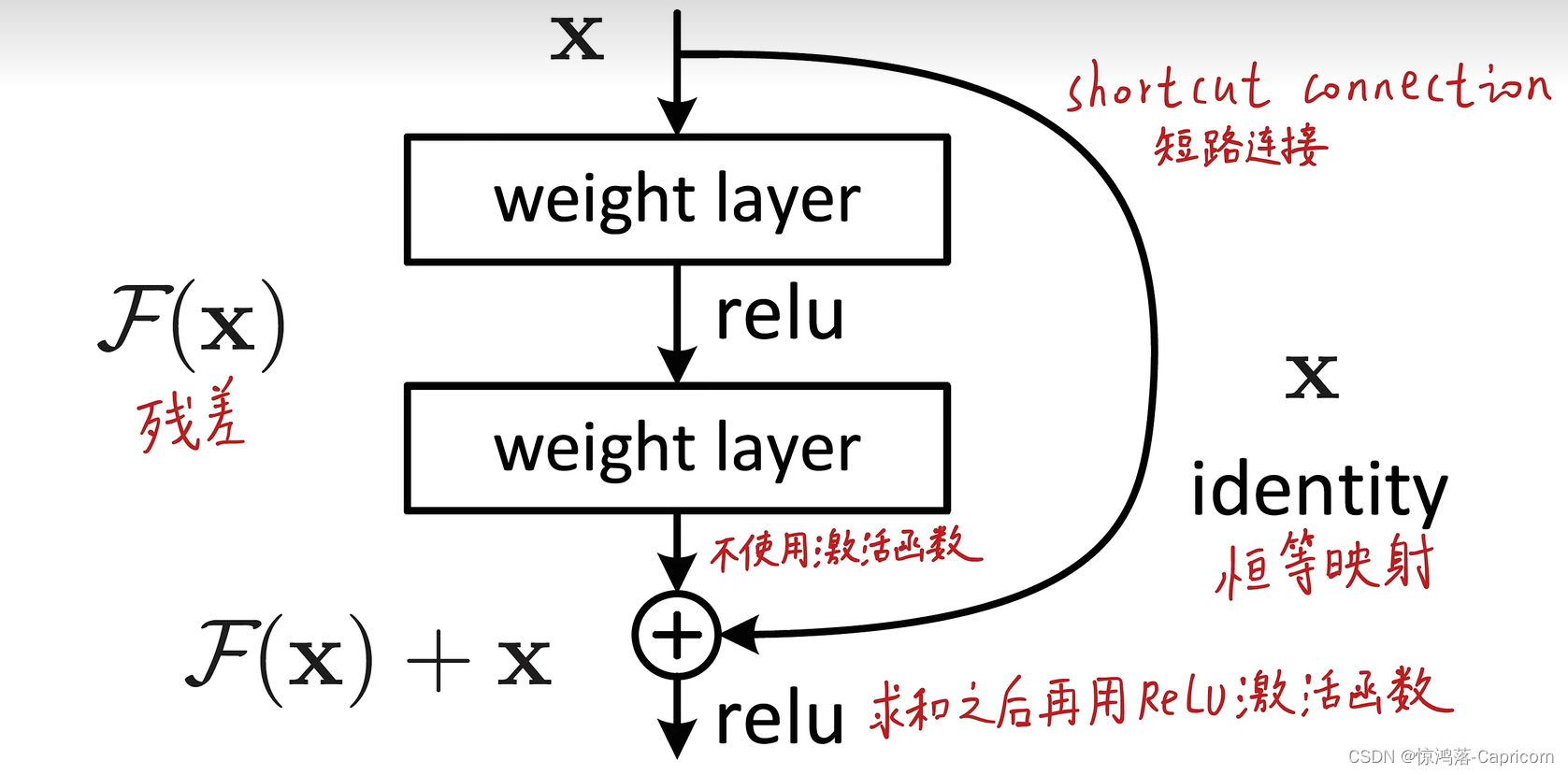
其中,输入X,分为两路,X为恒等映射,F(X)为残差映射,两者求和进入激活函数,再输出Relu(F(X)+X)。
残差F(X)的作用:是修正恒等映射X的误差,使网络拟合的更好。
如果X足够好,则残差的参数均为0,使输出的F(X)=0;
如果X不够好,F(X)在X的基础上优化。
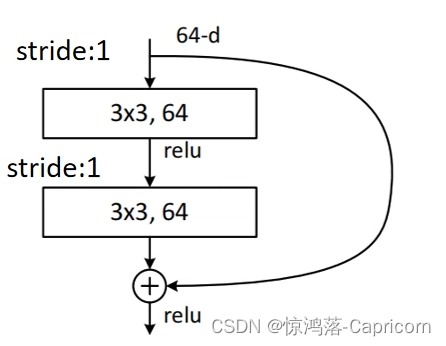
其中,F(X)与X相加时,shape必须相同,若F(X)的数据维数变化(如stride>1降维),则X也需要进行相应的变化(如对X做1×1的卷积)。
求F(X)残差的卷积均使用3x3conv,下采样大小降维一半。
由于恒等映射X的存在,反向传播时,梯度可以从深层直接给到浅层,避免了梯度消失与爆炸。
**
ResNet50模型基本构成
**
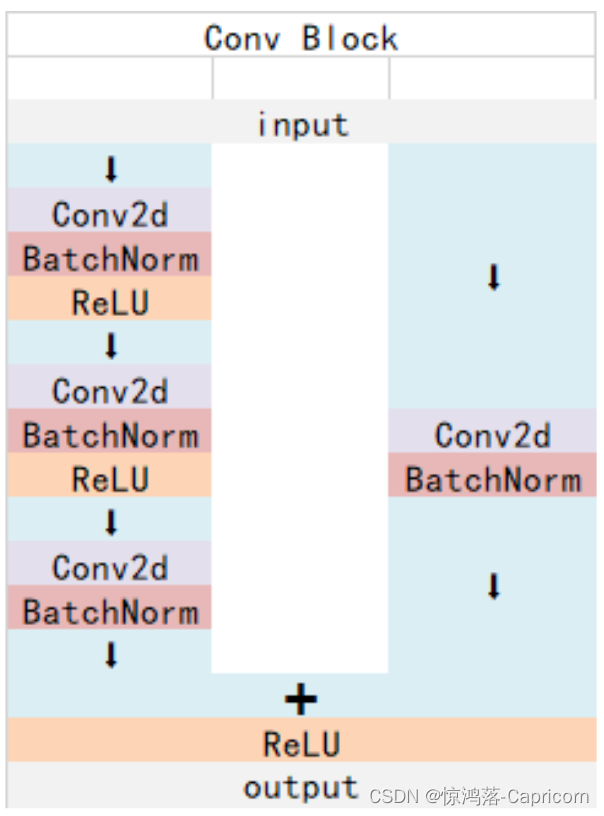
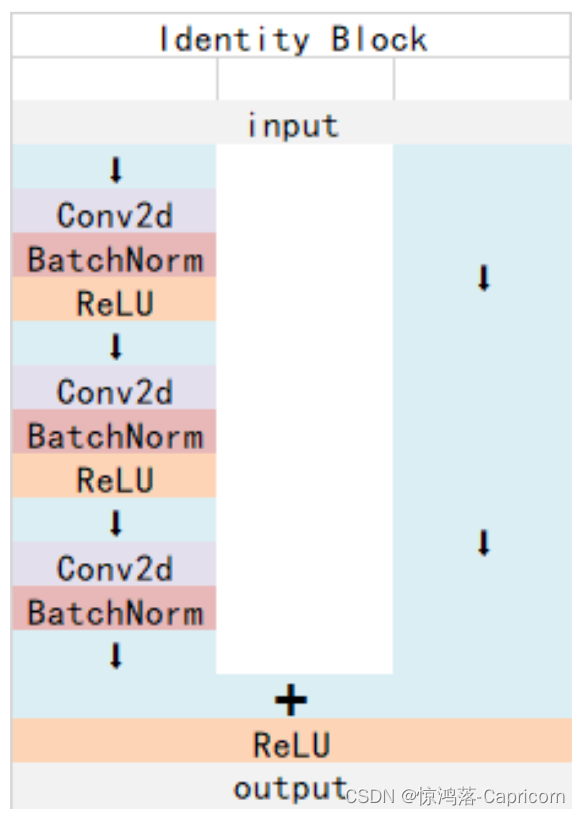
ResNet50有两个基本的块,分别名为 Conv Block_和 _Identity Block。
Conv Block:针对X和F(X)的维度(通道数和size)是不一样的,所以不能连续串联,它的作用是改变网络的维度;
Identity Block:针对X和F(X)的维度(通道数和size)相同,可以串联,用于加深网络的。
**
; BN层
:**
Batch normalization:目的是预处理使我们的一批(Batch)的feature map满足均值为0,方差为1的分布规律,这样能够加速网络的收敛。(在网络中间调整每层输入的feature map)。
一个batch size为2(两张图片,每张图片有3个通道,其中颜色红,绿,蓝分别代表r,g,b通道。)的Batch Normalization的原理,首先会统计每个通道数目所有点的像素值,求得均值和方差,然后在每个通道上分别用该点的像素值 _减均值除方差_得到该点的像素值,此过程就是BN。最后将其接入到激活函数中。
(其中, Xi是指一批数据的同一个通道的所有特征图的数据,如下图X1就是指两张彩图的R通道的所有数据)
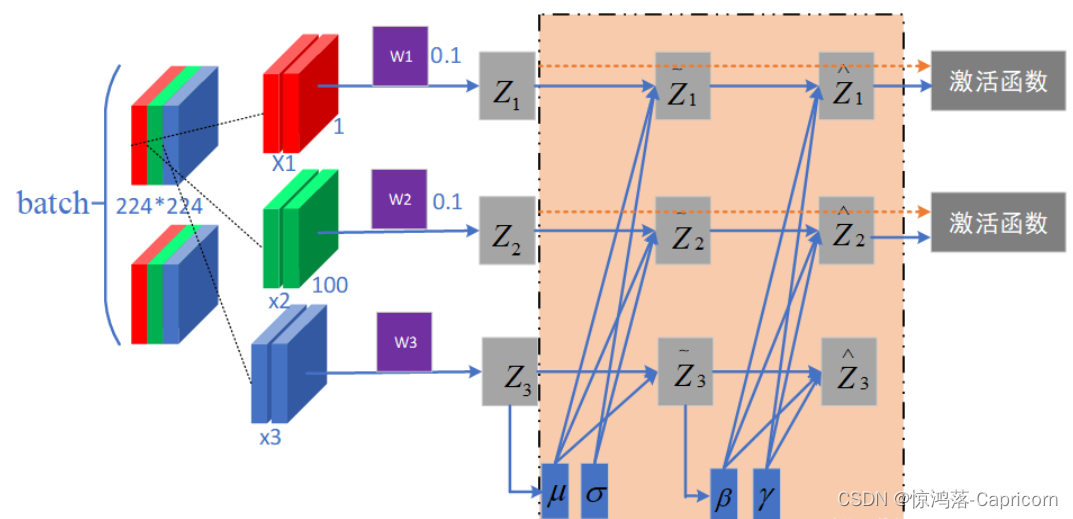

上述公式中,xi经过减均值,除方差之后,得到的数据的均值为0,方差为1,而后面的γ和β参数的作用又是什么呢?有时均值为0,方差为1并不是最好的效果,所以可以用通过γ调整数据的方差,通过β调整数据的均值。

介绍完BN层的原理,下面我们来看看具体的实例吧:
feature map1、feature map2分别是由image1、image2经过一系列卷积池化后得到的特征矩阵。其中每个网格的值代表该点的像素值,分别统计feature map1 和feature map2每个通道的像素值,得到一个矩阵,在使用BN的计算公式计算经过BN以后,得到每个通道每个像素点的像素值。计算公式也如下。
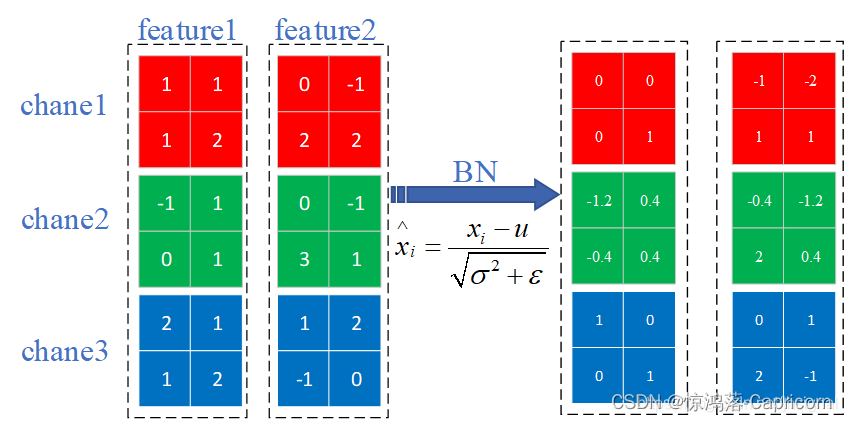
[注]:
(1)训练时要将traning参数设置为True,在验证时将trainning参数设置为False。在pytorch中可通过创建 模型的model.train()和model.eval()方法控制。
(2)batch size尽可能设置大点,设置小后表现可能很糟糕,设置的越大求的均值和方差越接近整个训练集的均值和方差。
(3)一般将bn层放在卷积层(Conv)和激活层(例如Relu)之间,且卷积层不要使用偏置bias,因为使用偏置和不使用偏置的yi是相等的,所以使用偏置只会徒增网络的参数,导致训练起来更加的费劲。

标准化(standardization):将数据通过去均值实现中心化的处理,根据凸优化理论与数据概率分布相关知识,数据中心化符合数据分布规律,更容易取得训练之后的泛化效果, 数据标准化是数据预处理的常见方法之一,缩放和每个点都有关系,通过方差(variance)体现出来。与归一化对比,标准化中所有数据点都有贡献(通过均值和标准差造成影响)。 加速模型收敛:标准化后,最优解的寻优过程明显会变得平缓,更容易正确的收敛到最优解。
归一化(Normalization):归一化的目标是找到某种映射关系,将原数据映射到(a,b)区间上,如0~1之间,缩放仅仅跟最大、最小值的差别有关。 提升模型精度:归一化后,不同维度之间的特征在数值上有一定比较性,可以大大提高分类器的准确性。
**
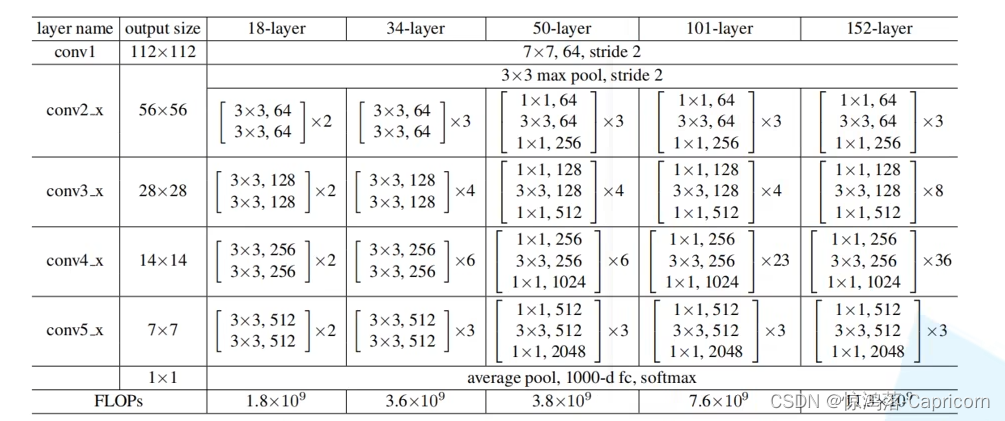
Resnet50总体结构
:**

Resnet网络就是残差块的堆叠,解决了网络退化问题,实现网络层数的加深,使之拥有足够好的特征提取能力。
补充:
Resnet解决网络退化的原理:
1. 深度梯度回传顺畅:恒等映射这一路的梯度是1,可以把浅层的信号传到深层,也可以把深层的梯度注回浅层,防止梯度消失。
2. 传统线性结构网络难以拟合”恒等映射”:什么都不做时很重要;skip connection可以让模型自行选择要不要更新;弥补了高度线性造成的不可逆的信息损失。
3. 图像相邻像素梯度的局部相关性:解决了传统多层卷积造成的,回传的相邻像素梯度的局部相关性越来越低的问题。
; 二、Resnet50代码复现
完整代码
代码如下(示例):
import torch.nn as nn
import torch
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_channel, out_channel, stride=1, downsample=None, **kwargs):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel,kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channel)
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel,kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channel)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += identity
out = self.relu(out)
return out
class Bottleneck(nn.Module):
"""
注意:原论文中,在虚线残差结构的主分支上,第一个1x1卷积层的步距是2,第二个3x3卷积层步距是1。
但在pytorch官方实现过程中是第一个1x1卷积层的步距是1,第二个3x3卷积层步距是2,
这么做的好处是能够在top1上提升大概0.5%的准确率。
"""
expansion = 4
def __init__(self, in_channel, out_channel, stride=1, downsample=None, groups=1, width_per_group=64):
super(Bottleneck, self).__init__()
width = int(out_channel * (width_per_group / 64.)) * groups
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=width,kernel_size=1, stride=1, bias=False)
self.bn1 = nn.BatchNorm2d(width)
self.conv2 = nn.Conv2d(in_channels=width, out_channels=width, groups=groups,kernel_size=3, stride=stride, bias=False, padding=1)
self.bn2 = nn.BatchNorm2d(width)
self.conv3 = nn.Conv2d(in_channels=width, out_channels=out_channel * self.expansion,kernel_size=1, stride=1, bias=False)
self.bn3 = nn.BatchNorm2d(out_channel * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out += identity
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self,
block,
blocks_num,
num_classes=1000,
include_top=True,
groups=1,
width_per_group=64):
super(ResNet, self).__init__()
self.include_top = include_top
self.in_channel = 64
self.groups = groups
self.width_per_group = width_per_group
self.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2,padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(self.in_channel)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, blocks_num[0])
self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2)
self.layer3 = self._make_layer(block, 256, blocks_num[2], stride=2)
self.layer4 = self._make_layer(block, 512, blocks_num[3], stride=2)
if self.include_top:
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
def _make_layer(self, block, channel, block_num, stride=1):
downsample = None
if stride != 1 or self.in_channel != channel * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channel, channel * block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(channel * block.expansion))
layers = []
layers.append(block(self.in_channel,
channel,
downsample=downsample,
stride=stride,
groups=self.groups,
width_per_group=self.width_per_group))
self.in_channel = channel * block.expansion
for _ in range(1, block_num):
layers.append(block(self.in_channel,
channel,
groups=self.groups,
width_per_group=self.width_per_group))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
if self.include_top:
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def resnet50(num_classes=1000, include_top=True):
return ResNet(Bottleneck, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top)
def resnet34(num_classes=1000, include_top=True):
return ResNet(BasicBlock, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top)
def resnet101(num_classes=1000, include_top=True):
return ResNet(Bottleneck, [3, 4, 23, 3], num_classes=num_classes, include_top=include_top)
def resnext50_32x4d(num_classes=1000, include_top=True):
groups = 32
width_per_group = 4
return ResNet(Bottleneck, [3, 4, 6, 3],
num_classes=num_classes,
include_top=include_top,
groups=groups,
width_per_group=width_per_group)
def resnext101_32x8d(num_classes=1000, include_top=True):
groups = 32
width_per_group = 8
return ResNet(Bottleneck, [3, 4, 23, 3],
num_classes=num_classes,
include_top=include_top,
groups=groups,
width_per_group=width_per_group)
Original: https://blog.csdn.net/weixin_54338498/article/details/125590669
Author: 惊鸿落-Capricorn
Title: 卷积神经网络学习—Resnet50(论文精读+pytorch代码复现)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/688048/
转载文章受原作者版权保护。转载请注明原作者出处!