



Abstract:本文所研究的任务是object detection。思想是图像的非均匀切割(如上图)。从而有的块(物体密集、目标小、检测难度大)可以采用大模型(输入为高分辨率图像)进行inference,有的块(物体稀疏、目标大、检测难度小)可以采用小模型(输入为低分辨率图像)进行推断,有的块(不包含物体)可以不推断。
因此,要解决的问题有:1、如何分割;2、如何给分割后的块分配模型;优化的目标为:在时延budget的约束下,使得推断准确率mAP最大。作者采用的方法为枚举法。
另外,还需要选取不推断的块。大概思想是检测到该块前面帧都不包含物体时,则可以进行skip。
如上图所示,红色部分为skip,绿色部分为小模型,蓝色部分为大模型。
; 测量

作者首先进行了测量,上表为作者采用的model。本文讨论的model主要为EfficientDet,可以看到,不同大小的EfficientDet model能够处理不同resolution的图像。模型越大,对应的处理时延越长,准确率越高。
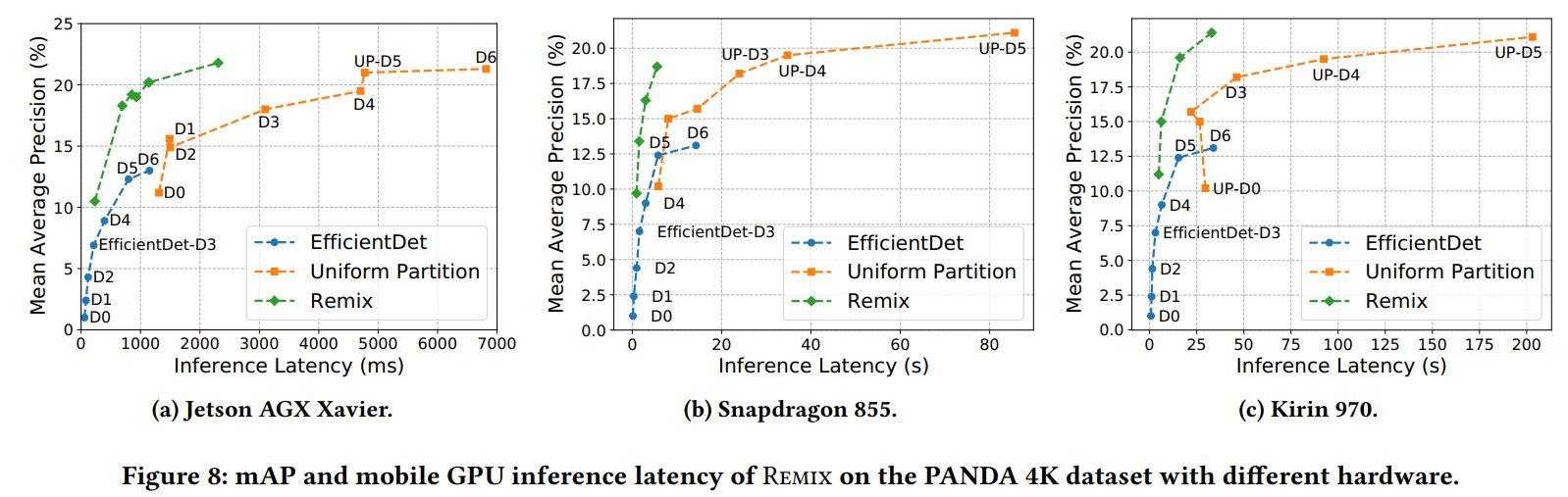
作者测量的平台为Nvidia Jetson AGX Xavier,采用的框架为TensorFlow。数据集为PANDA 4K,指标为mean averaged
precision (mAP)。
Down-sampling inputs reduces the latency but has a low accuracy.
Up-scaling networks increases the accuracy but has a high latency.
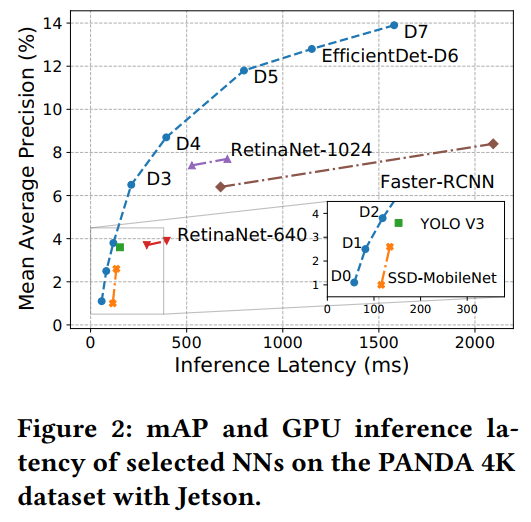
如上图所示,输入的分辨率(对应模型的大小),影响着推断时延和准确率。
Uniform partitioning may further increase the accuracy buthas an even higher latency.
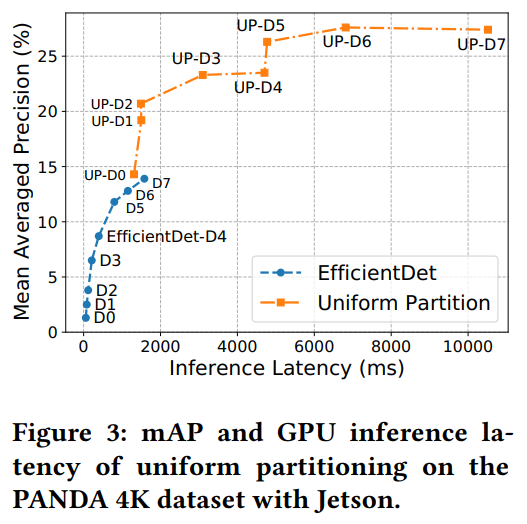
The accuracy of NNs varies among objects of different sizes.
作者首先对物体的大小进行分类,从S0到L3依次增大,并测量不同模型检测不同大小物体的准确率。
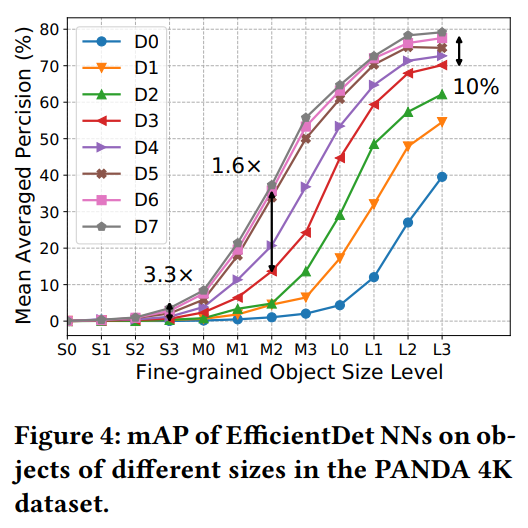
可以看到,物体越小,大模型的增益越大(这里的增益是采用准确率的倍数表示的)。因此作者提出,对于小物体,用大模型比较好;对于大物体,用小模型比较好。
因此,接下来围绕两个主要工作展开。Adaptive Partition:分割图像使得检测又快又准;Selective Execution:skip没有物体的块。
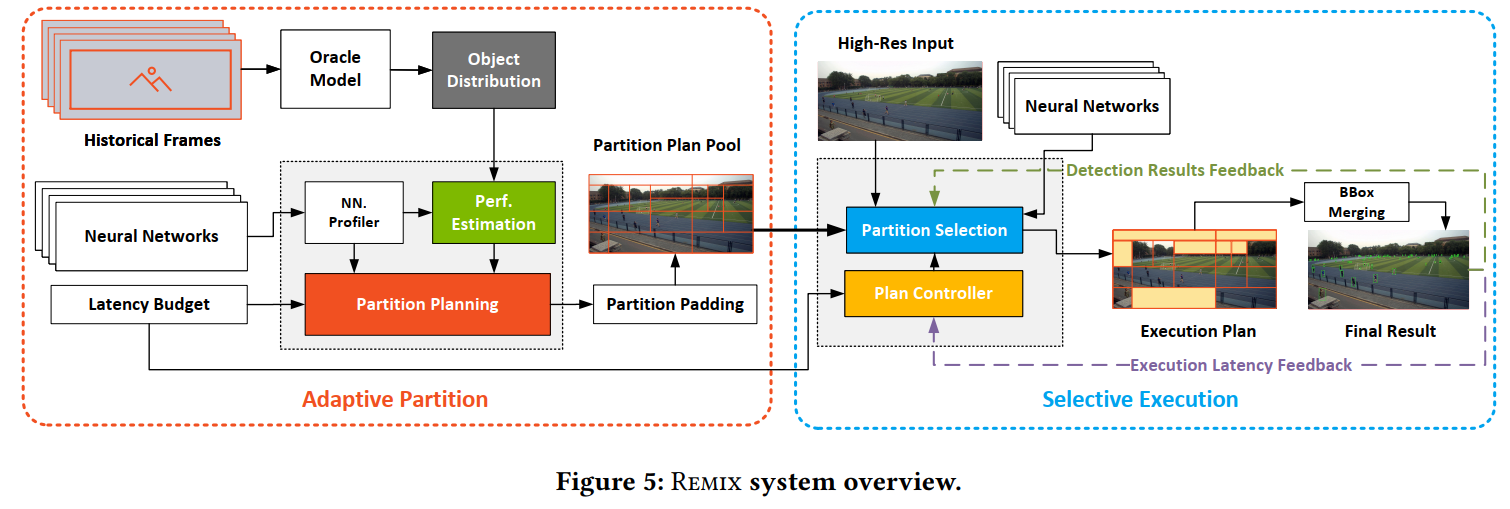
Partition Planning就是分割块。输入有:Latency Budget,就是时延上限;NN Profiler,我们需要先提前获取到不同神经网络的推断时延和在不同大小物体的准确率mAP;Object Distribution,通过历史帧和一个训练好的高级模型提取出不同大小物体的分布。因此,可以通过Perf. Estimation评估不同分割方案用不同模型的延时和准确率。Partition Planning采用枚举和剪枝的方法去找到若干候选方案,即在budget的约束下最大化accuracy。
然后候选方案输入Partition Selection可以选出不包含object的块。这时候又可以腾出部分时间,可以通过Plan Controller进一步调整budget。
Adaptive Partition
目标:找出若干分割方案κ \kappa κ,在T T T的约束下最大化准确率。
Neural network profiling.
提前测量不同网络n ∈ N n \in N n ∈N,采用不同batch size b b b的平均时延L n b L_n^{b}L n b 。
对于每个网络n ∈ N n \in N n ∈N,测量一个准确率向量,表示不同大小物体分布的准确率。
A P n = ⟨ τ S 0 , τ S 1 , ⋯ τ M 0 , τ M 1 , ⋯ τ L 2 , τ L 3 ⟩ A P_{n}=\left\langle\tau_{S 0}, \tau_{S 1}, \cdots \tau_{M 0}, \tau_{M 1}, \cdots \tau_{L 2}, \tau_{L 3}\right\rangle A P n =⟨τS 0 ,τS 1 ,⋯τM 0 ,τM 1 ,⋯τL 2 ,τL 3 ⟩
Object distribution extraction.
通过历史帧的物体分布来计算出当前帧的分布。历史帧V V V的物体采用一个高级网络UP-D7来标注。
F V = ⟨ ϕ S 0 , ϕ S 1 , ⋯ ϕ M 0 , ϕ M 1 , ⋯ ϕ L 2 , ϕ L 3 ⟩ F_{V}=\left\langle\phi_{S 0}, \phi_{S 1}, \cdots \phi_{M 0}, \phi_{M 1}, \cdots \phi_{L 2}, \phi_{L 3}\right\rangle F V =⟨ϕS 0 ,ϕS 1 ,⋯ϕM 0 ,ϕM 1 ,⋯ϕL 2 ,ϕL 3 ⟩
ϕ \phi ϕ为distribution probability。(这里有点不是很理解它的单位是啥,个数?概率?)
Performance estimation.
对于分割后的每个块p p p,通过以上向量的点乘,可以估算出准确率。
e A P p n = A P n ⋅ F p eAP_{p}^{n}=A P_{n} \cdot F_{p}e A P p n =A P n ⋅F p
因此,对于每个分割方案,将所有块加和,即可得总的准确率。
e A P V κ = ∑ e A P p n ⋅ λ p , p ∈ V eAP_{V}^{\kappa}=\sum eAP_{p}^{n} \cdot \lambda_{p}, \quad p \in V e A P V κ=∑e A P p n ⋅λp ,p ∈V
输入同一网络的不同块可以作为一个batch,时延的计算为:
e L a t κ = ∑ L n b , n ∈ N κ eLat_{\kappa}=\sum L_{n}^{b}, \quad n \in N_{\kappa}e L a t κ=∑L n b ,n ∈N κ
通过以上计算,我们可以计算不同分割方案的性能。接着作者设计一个暴力枚举+剪枝的算法求解候选方案。

思想有点像回溯法。
可以先看11行。对于每种网络,依据它的输入来均匀分割当前帧。然后对于每个的每个块,获取出比网络n n n更小的网络集合,以及当前块p p p的物体H p H_p H p ,然后依次迭代进入下一轮。返回值S K p SK_p S K p 为当前块p p p的最佳分割方案。将S K p SK_p S K p 加入当前已有的分割方案t m p tmp t m p,然后剪枝。最后返回当前块的分割方案K K K。
可以理解为:当前一棵树,树的父节点为当前帧,然后依次均匀分割出每个块作为叶子节点,叶子节点可以依次递归(分割)出子节点并计算出当前的最佳方案,最后依次回溯向父节点返回自己的方案。父节点接收后依次合并剪枝。这样从父节点向下递归、又向上回溯,就可以得出最后的方案。结束的条件为当前子节点不能再分割了,即到了最小网络了。
前面的2-10行为选择网络模型。对于当前节点(块),可以依次分配不同的网络模型。分配完后,用前面的公式计算出时延和准确率,得出模型的选择方案并进入候选集K K K中。
剪枝方式为:

同时,考虑到之后去除部分块可以腾出一部分算力,作者还选取了一些T ∼ 1.5 T T \sim 1.5T T ∼1 .5 T的方案。
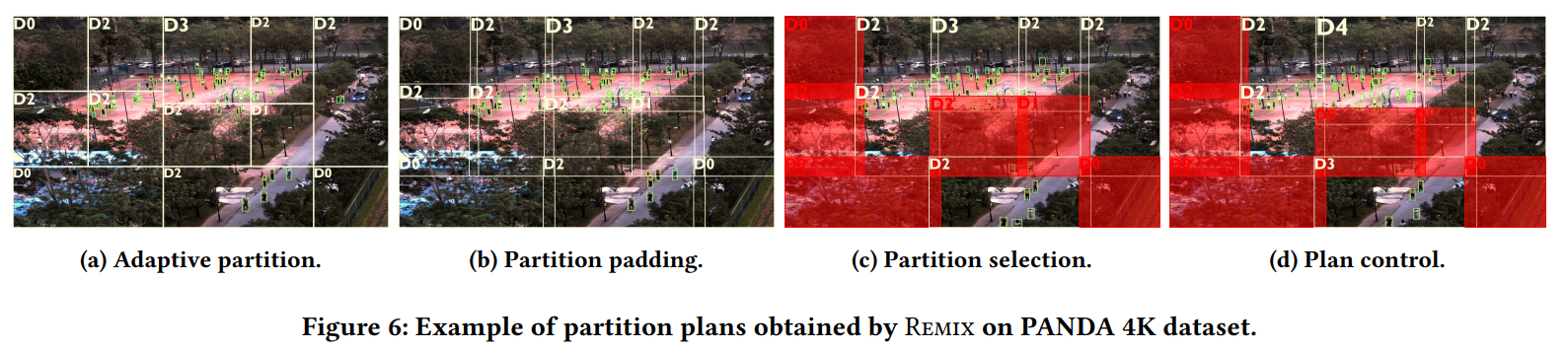
; Partition padding.
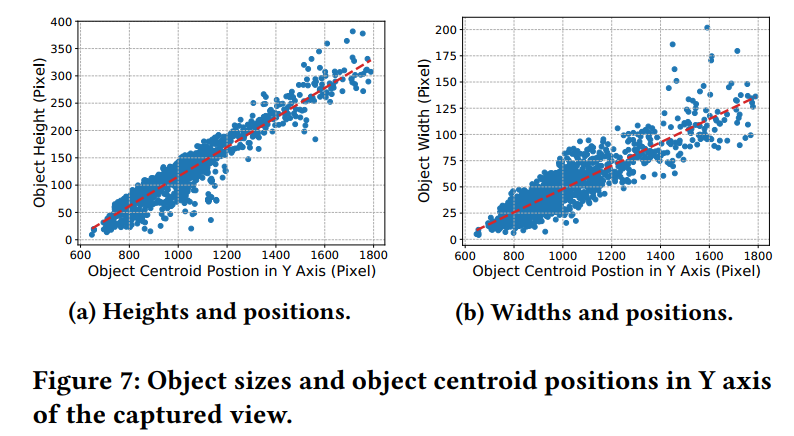
考虑到分割后有些物体被一分为二了,作者又扩大了一下块的边界。作者测量发现物体的宽和高跟物体的垂直坐标呈线性关系,因此作者通过回归建立y坐标和宽高的关系,并扩展。如图6(b)所示。
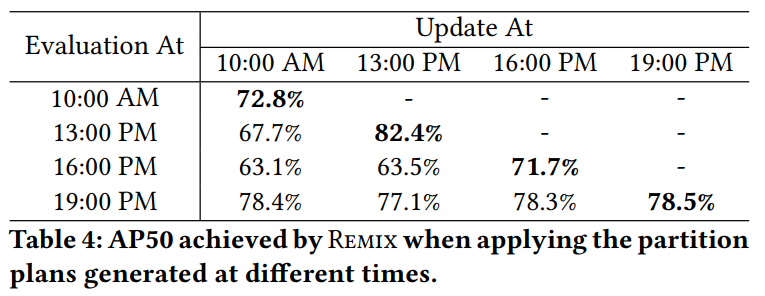
作者测量得到在边缘端分割需要花费6 min。
Selective Execution
考虑到有些块不包含物体,可以skip。作者的测量类似于TCP的拥塞控制。作者设置一个跳跃窗口w p w_p w p 。当连续检测到ι p \iota_p ιp 帧没有物体时,作者设置w p = ι p − 1 w_p=\iota_p-1 w p =ιp −1。如果检测到物体,则w p = 0 w_p=0 w p =0。如果当前帧跳过了,则w p = w p − 1 w_p=w_p-1 w p =w p −1。
接着,考虑到有些块被舍弃了,作者适当放大budget,使得inference真实的latency L L L更加真实人为设定的budget T T T。这里作者采用的是PID控制器方法,将budget T T T设为desired setpoint,将Latency设为measured process variable,学习更真实的算法的约束u u u。
e.g., 原始设定的L L L为5s,直接的方式是budget为5s,但是这样latency L L L会偏小,但是准确率下降。该方法适当增大算法的budget。
然后用u u u在刚刚选出的K K K中选出小于延时约束且准确率最大的方案。
最后作者采用non-maximum suppression (NMS) algorithm的方法将不同块融合。
实验
Jetson AGX Xavier, TensorFlow Lite; Snapdragon 855 and Kirin970, TensorFlow Lite.
Original: https://blog.csdn.net/qq_40766325/article/details/121288371
Author: Jim1Vic
Title: Mobicom21: Flexible High-resolution Object Detection on Edge Devices with Tunable Latency解读
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/687144/
转载文章受原作者版权保护。转载请注明原作者出处!