

–neozng1@hnu.edu.cn
2. Neck
前一个版本的NanoDet为了追求极致的推理速度使用了无卷积融合的PAN架构,即top-down和down-top路径都是直接通过双线性插值的上下采样+element-wise add实现的,随之而来的显然是性能的下降。在NanoDet-Plus中,作者将Ghost module用于特征融合中,打造了Ghost-PAN,在保证不增加过多参数和运算量的前提下增强了多尺度目标检测的性能。
Ghost PAN中用到了一些GhostNet中的模块,直接查看第一部分关于即可。
作者在Ghost bottleneck的基础上,增加一个reduce_layer以减小通道数,构成Ghost Blocks。这就是用于top-down和bottom-up融合的操作。同时还可以选择是否使用残差连接。且Ghost Block中的ghost bottle neck选用了5×5的卷积核,可以 扩大感受野,更好地融合不同尺度的特征。
class GhostBlocks(nn.Module):
"""Stack of GhostBottleneck used in GhostPAN.
Args:
in_channels (int): Number of input channels.
out_channels (int): Number of output channels.
expand (int): Expand ratio of GhostBottleneck. Default: 1.
kernel_size (int): Kernel size of depthwise convolution. Default: 5.
num_blocks (int): Number of GhostBottlecneck blocks. Default: 1.
use_res (bool): Whether to use residual connection. Default: False.
activation (str): Name of activation function. Default: LeakyReLU.
"""
def __init__(
self,
in_channels,
out_channels,
expand=1,
kernel_size=5,
num_blocks=1,
use_res=False,
activation="LeakyReLU",
):
super(GhostBlocks, self).__init__()
self.use_res = use_res
if use_res:
# 若选择添加残差连接,用一个point wise conv对齐通道数
self.reduce_conv = ConvModule(
in_channels,
out_channels,
kernel_size=1,
stride=1,
padding=0,
activation=activation,
)
blocks = []
for _ in range(num_blocks):
blocks.append(
GhostBottleneck(
in_channels,
int(out_channels * expand), # 第一个ghost module选择不扩充通道数,保持和输入相同
out_channels,
dw_kernel_size=kernel_size,
activation=activation,
)
)
self.blocks = nn.Sequential(*blocks)
def forward(self, x):
out = self.blocks(x)
if self.use_res:
out = out + self.reduce_conv(x)
return out
把Ghost Block对PAN中用于特征融合的卷积进行替换就得到了Ghost PAN。
- 初始化和参数部分
class GhostPAN(nn.Module):
"""Path Aggregation Network with Ghost block.用ghost block替代了简单的卷积用于特征融合
Args:
in_channels (List[int]): Number of input channels per scale.
out_channels (int): Number of output channels (used at each scale)
拥有相同的输出通道数,方便检测头有统一的输出
use_depthwise (bool): Whether to depthwise separable convolution in
blocks. Default: False
kernel_size (int): Kernel size of depthwise convolution. Default: 5.
expand (int): Expand ratio of GhostBottleneck. Default: 1.
num_blocks (int): Number of GhostBottlecneck blocks. Default: 1.
use_res (bool): Whether to use residual connection. Default: False.
num_extra_level (int): Number of extra conv layers for more feature levels.
Default: 0.
upsample_cfg (dict): Config dict for interpolate layer.
Default: dict(scale_factor=2, mode='nearest')
norm_cfg (dict): Config dict for normalization layer.
Default: dict(type='BN')
activation (str): Activation layer name.
Default: LeakyReLU.
"""
def __init__(
self,
in_channels,
out_channels,
use_depthwise=False,
kernel_size=5,
expand=1,
num_blocks=1,
use_res=False,
num_extra_level=0,
upsample_cfg=dict(scale_factor=2, mode="bilinear"),
norm_cfg=dict(type="BN"),
activation="LeakyReLU",
):
super(GhostPAN, self).__init__()
assert num_extra_level >= 0
assert num_blocks >= 1
self.in_channels = in_channels
self.out_channels = out_channels
# DepthwiseConvModule和ConvModule都是MMdetection中的基础模块,分别对应深度可分离卷积和基本的conv+norm+act模块
conv = DepthwiseConvModule if use_depthwise else ConvModule
- top-down连接
build top-down blocks
self.upsample = nn.Upsample(**upsample_cfg)
在不同stage的特征输入FPN前先进行通道数衰减,降低计算量
self.reduce_layers = nn.ModuleList()
for idx in range(len(in_channels)):
self.reduce_layers.append(
ConvModule(
in_channels[idx],
out_channels,
1,
norm_cfg=norm_cfg,
activation=activation,
)
)
self.top_down_blocks = nn.ModuleList()
# 注意索引方式,从最后一个元素向前开始索引到0个
for idx in range(len(in_channels) - 1, 0, -1):
self.top_down_blocks.append(
GhostBlocks(
# input channel为out_channels*2是因为特征融合采用的cat而非add
out_channels * 2,
out_channels,
expand,
kernel_size=kernel_size,
num_blocks=num_blocks,
use_res=use_res,
activation=activation,
)
)
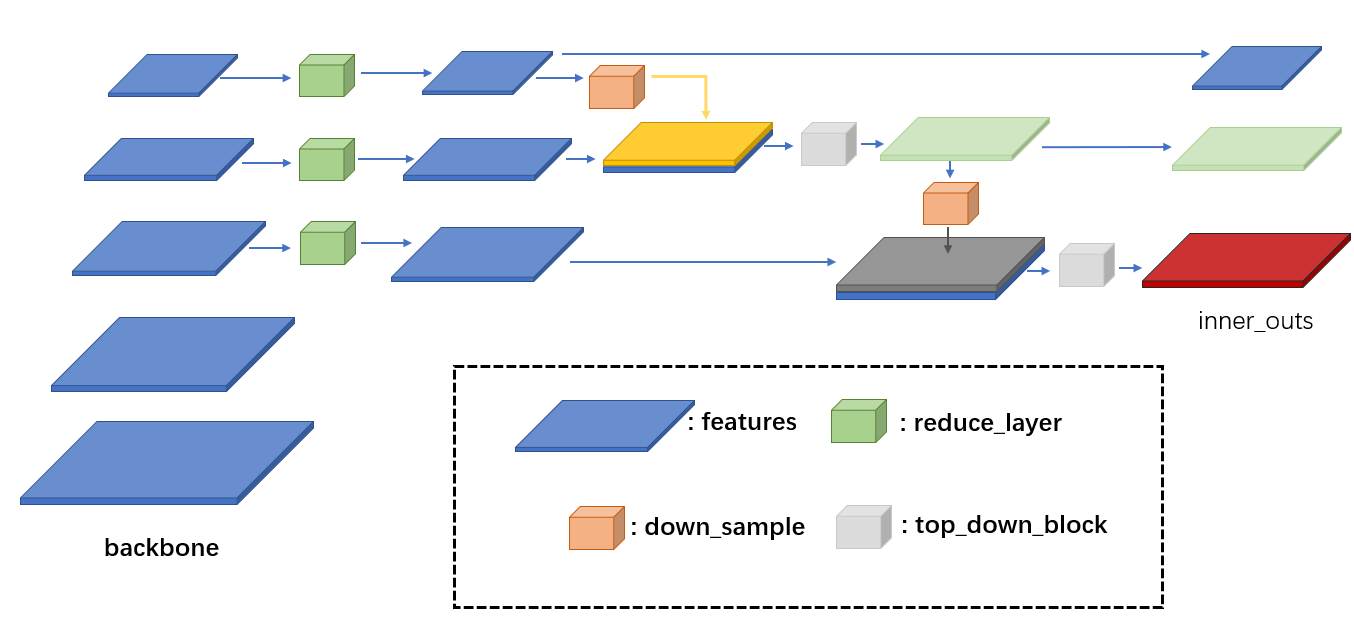

* bottom-up连接
build bottom-up blocks
self.downsamples = nn.ModuleList()
self.bottom_up_blocks = nn.ModuleList()
for idx in range(len(in_channels) - 1):
self.downsamples.append(
conv(
out_channels,
out_channels,
kernel_size,
stride=2,
padding=kernel_size // 2,
norm_cfg=norm_cfg,
activation=activation,
)
)
self.bottom_up_blocks.append(
GhostBlocks(
out_channels * 2, # 同样是因为融合时使用cat
out_channels,
expand,
kernel_size=kernel_size,
num_blocks=num_blocks,
use_res=use_res,
activation=activation,
)
)
bottom-up连接和top-down一样,只不过方向相反,稍后在 foward() 方法中可以很清楚的看到,这里不再作图(PPT画图真的太慢了累死我了)
* extra layer
extra layers,即PAN上额外的一层,由PAN的最顶层经过卷积得到.
self.extra_lvl_in_conv = nn.ModuleList()
self.extra_lvl_out_conv = nn.ModuleList()
for i in range(num_extra_level):
self.extra_lvl_in_conv.append(
conv(
out_channels,
out_channels,
kernel_size,
stride=2,
padding=kernel_size // 2,
norm_cfg=norm_cfg,
activation=activation,
)
)
self.extra_lvl_out_conv.append(
conv(
out_channels,
out_channels,
kernel_size,
stride=2,
padding=kernel_size // 2,
norm_cfg=norm_cfg,
activation=activation,
)
)
extra layer就是取reduce_layer后的最上层feature map经过extra_lvl_in_conv后的输出 和bottom-up输出的最上层feature map经过extra_lvl_out_conv的输出进行element-wise相加得到的层,稍后将用于拥有过最大尺度 (最高的下采样率) 的检测头。
- 前向传播
def forward(self, inputs):
"""
Args:
inputs (tuple[Tensor]): input features.
Returns:
tuple[Tensor]: multi level features.
"""
assert len(inputs) == len(self.in_channels)
# 对于每一个stage的feature,分别送入对应的reduce_layers
inputs = [
reduce(input_x) for input_x, reduce in zip(inputs, self.reduce_layers)
]
# top-down path
inner_outs = [inputs[-1]] # top-down连接中的最上层不用操作
for idx in range(len(self.in_channels) - 1, 0, -1):
# 相邻两层的特征要进行融合
feat_heigh = inner_outs[0]
feat_low = inputs[idx - 1]
inner_outs[0] = feat_heigh
# 对feat_high进行上采样扩充
upsample_feat = self.upsample(feat_heigh)
# 拼接后投入对应的top_down_block层,得到稍后用于进一步融合的特征
inner_out = self.top_down_blocks[len(self.in_channels) - 1 - idx](
torch.cat([upsample_feat, feat_low], 1)
)
# 把刚刚得到的特征插入inner_outs的第一个位置,进行下一轮融合
inner_outs.insert(0, inner_out)
# bottom-up path,和top-down path类似的操作
outs = [inner_outs[0]] # inner_outs[0]是最底层的特征
for idx in range(len(self.in_channels) - 1):
feat_low = outs[-1] # 从后往前索引,每轮迭代都会将新生成的特征append到list后方
feat_height = inner_outs[idx + 1]
downsample_feat = self.downsamples[idx](feat_low) # 下采样
# 拼接后投入连接层得到输出
out = self.bottom_up_blocks[idx](
torch.cat([downsample_feat, feat_height], 1)
)
outs.append(out)
# extra layers
# 把经过reduce_layer后的特征直接投入extra_in_layer
# 再把经过GhostPAN后的特征输入extra_out_layer
# 两者element-wise add后追加到PAN的输出后
for extra_in_layer, extra_out_layer in zip(
self.extra_lvl_in_conv, self.extra_lvl_out_conv
):
outs.append(extra_in_layer(inputs[-1]) + extra_out_layer(outs[-1]))
return tuple(outs)
Original: https://blog.csdn.net/NeoZng/article/details/123300977
Author: HNU跃鹿战队
Title: NanoDet代码逐行精读与修改(二)FPN/PAN
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/686729/
转载文章受原作者版权保护。转载请注明原作者出处!