

核心思想
本文提出一种基于图匹配的领域自适应目标检测算法。简单的介绍一下领域自适应目标检测(DAOD)任务,通常做目标检测是假设训练样本和测试样本是来自同一个分布的(可以简单理解为同一个数据集),而实际上测试样本的来源可能非常多样(来自不同数据集)。我们将训练样本所处的分布称为源域(source domain),将测试样本所处的分布称为目标域(target domain),为了提高对于来自不同分布样本的检测能力,提出了领域自适应(Domain Adaptive)的想法。现有的方法通常是在特征空间中为每个类别的目标定义一个prototype,比如特征向量的均值,作为类别中心。然后通过训练让源域和目标域中同类别的prototype尽量对齐,为每个类别的目标都找到一个公共的分布,以实现领域的自适应。作者认为这样做有两个弊端:1. 这种类别相关的”紧凑的”分布会使得网络丧失一定的分布感知能力,进而影响泛化能力;2. 训练过程中,由于每个batch的图像都是随机选取的,会存在某些类别的目标只在源域或目标域中出现,导致语义上的错误匹配(比如由于当前源域图像中没有猫这个目标只有狮子,而目标域的图像中有猫,就有可能把猫匹配到狮子上去),这有可能影响类别中心的更新。
为了解决上述的问题,作者提出一种基于图的建模方法,不再使用prototype来建模类别条件分布,而是用更加具体的图的形式来构建。如果说prototype是用”猫”这个字来描述猫这个类别,那图则是用”猫头”、”猫腿”、”猫身”和”猫尾巴”这种稠密的方式来描述猫。不仅可以通过各个节点之间边来进行图内的信息传递,还可以利用跨图连接实现不同的图之间的信息交互(cross graph interaction,CGI)。对于缺失的类别,作者提出一种虚拟节点的概念,从一个存储着所有类别目标特征信息的图记忆银行(graph-guided memory bank,GMB)中采样得到缺失类别的节点来补全图,称之为图嵌入的语义补全模块(Graph-embedded
Semantic Completion module,GSC)。最后采用双边图匹配方法(Bipartite Graph Matching,BGM)实现源域图和目标域图之间的对齐。


; 实现过程
首先,来自源域和目标域的图片分别经过一个共享权重的特征提取网络得到对应的特征图,为构建图模型需要将视觉特征转化成图(V2G)。对于源域图片,由于已知每个目标的标签和位置,因此可以根据目标的外接框所在位置,从特征图上进行均匀采样得到特征点。并且对于外接框外部的背景图像也按一定比例采样特征点,再利用一个非线性映射层得到对应节点特征v s i v_s^i v s i 。对于目标域图片,作者根据分类器输出的得分图(score map),将得分超过一定阈值(0.5)的像素点认为是目标的特征点,而将得分低于阈值(0.05)的像素点认为是背景点,分别进行采样和非线性映射得到节点特征v t i v_t^i v t i 。
然后对源域或目标域中缺失的类别进行节点补全,作者定义了为目标域和源域分别定义了一个图记忆银行S s / t S_{s/t}S s /t 。如果类别w w w不在源域图像中,则计算目标域中类别w w w对应节点{ v t ( w ) } {v_t^{(w)}}{v t (w )}的标准差σ t ( w ) \sigma_t^{(w)}σt (w )来近似描述缺失类别w w w分布的尺度。然后从源域图记忆银行中加载类别w w w对应的记忆种子S s ( w ) S_s^{(w)}S s (w )作为类别期望μ s ( w ) \mu_s^{(w)}μs (w ),构建一个正态分布N ( μ s ( w ) , σ t ( w ) ) N(\mu_s^{(w)}, \sigma_t^{(w)})N (μs (w ),σt (w ))。从中采样虚拟特征点x s h x^h_s x s h ,并经过一个线性映射得到虚拟节点特征v s h v^h_s v s h 。同理对于目标域中缺失的类别也可以采用类似的方式采样得到虚拟节点。
下面介绍如何构建和更新图记忆银行。由于节点v s / t v_{s/t}v s /t 是来自于同一个batch的不同图像,因此通过引入节点之间的边连接ε s / t \varepsilon_{s/t}εs /t ,可以构建一种跨图像的图。对于边的建立,作者采用了一种Edge Drop方法避免了冗余连接导致的潜在关系偏好问题,A s / t = E d g e d r o p { s o f t m a x [ V s / t W e ( V s / t W e ) T ] } A_{s/t}=Edgedrop{softmax[V_{s/t}W_e(V_{s/t}W_e)^T]}A s /t =E d g e d ro p {so f t ma x [V s /t W e (V s /t W e )T ]},A s / t A_{s/t}A s /t 是用于描述连接结构的邻接矩阵,W e W_e W e 是可学习的参数。构建了图结构之后,就可以利用基于图的信息传播来聚合跨图像的语义信息,得到增强的节点v ~ s / t i \tilde{v}{s/t}^i v ~s /t i ,如下v ~ s / t i = L N ( ∑ v s / t i ∈ N R i ∣ N R i ∣ A s / t i , j v s / t j W g c n + v s / t i ) \tilde{v}{s/t}^i=LN(\sum^{|NR^i|}{v{s/t}^i \in NR^i}A_{s/t}^{i,j}v_{s/t}^jW_{gcn} + v_{s/t}^i)v ~s /t i =L N (v s /t i ∈N R i ∑∣N R i ∣A s /t i ,j v s /t j W g c n +v s /t i )其中N R i NR^i N R i表示节点v s / t i v_{s/t}^i v s /t i 的相邻节点,W g c n W_{gcn}W g c n 表示可学习的参数,L N LN L N表示层规范化。图记忆银行是随机初始化得到的,经过强化的节点用来更新图记忆银行中每个类别的种子。对于类别w w w,从图记忆银行中加载得到种子S s / t ( w ) S_{s/t}^{(w)}S s /t (w ),并与类别w w w对应的节点v ~ s / t ( w ) \tilde{v}{s/t}^{(w)}v ~s /t (w )放在一起构成一个集合{ S s / t ( w ) , v ~ s / t ( w ) } {S{s/t}^{(w)}, \tilde{v}{s/t}^{(w)}}{S s /t (w ),v ~s /t (w )},采用普聚类的方式将集合分成两类,一类是包含种子节点的π s / t s e e d \pi{s/t}^{seed}πs /t see d ,另一类是不包含种子节点的其他类π s / t e l s e \pi_{s/t}^{else}πs /t e l se 。只是用包含种类节点的一组节点π s / t s e e d \pi_{s/t}^{seed}πs /t see d 用于更新。更新的方式采用一种基于动量momentum的方法S s / t ( w ) ← s i m ( b s / t , S s / t ( w ) ) S s / t ( w ) + [ 1 − s i m ( b s / t , S s / t ( w ) ) ] b s / t S_{s/t}^{(w)}\leftarrow sim(b_{s/t},S_{s/t}^{(w)})S_{s/t}^{(w)} + [1 -sim(b_{s/t},S_{s/t}^{(w)}) ]b_{s/t}S s /t (w )←s im (b s /t ,S s /t (w ))S s /t (w )+[1 −s im (b s /t ,S s /t (w ))]b s /t 其中s i m ( b s / t , S s / t ( w ) ) = b s / t ⋅ S s / t ( w ) ∥ b s / t ∥ 2 ⋅ ∥ S s / t ( w ) ∥ 2 sim(b_{s/t},S_{s/t}^{(w)}) =\frac{b_{s/t} \cdot S_{s/t}^{(w)}}{\|b_{s/t}\|{2}\cdot \|S{s/t}^{(w)}\|{2}}s im (b s /t ,S s /t (w ))=∥b s /t ∥2 ⋅∥S s /t (w )∥2 b s /t ⋅S s /t (w )b s / t = 1 ∣ π s / t s e e d ∣ − 1 ∑ v ~ s / t ( w ) ∈ π s / t s e e d v ~ s / t ( w ) b{s/t}=\frac{1}{|\pi_{s/t}^{seed}|-1}\sum_{\tilde{v}{s/t}^{(w)}\in \pi{s/t}^{seed}}\tilde{v}{s/t}^{(w)}b s /t =∣πs /t see d ∣−1 1 v ~s /t (w )∈πs /t see d ∑v ~s /t (w )
最后,看看如何通过双边图匹配实现跨领域的对齐任务。上文提到构建图的时候聚合了不同图像之间的信息,而这里的不同图像是指同一个域内的不同图像,只是在一个图G s G_s G s 或G t G_t G t 内的不同节点之间进行信息传递。而为了实现跨领域的对齐,跨图的信息交互是必须的,即图G s G_s G s 和G t G_t G t 之间的信息交互。作者采用多头注意力机制来实现跨图的信息传递V ^ s = L M { s o f t m a x [ ( V ~ s W q ) ( V ~ t W k ) T ] ( V ~ t W v ) W p + V ~ s } \hat{V}_s=LM{softmax(\tilde{V}_sW_q)(\tilde{V}_tW_k)^TW_p +\tilde{V}_s }V ^s =L M {so f t ma x (V ~s W q )(V ~t W k )T W p +V ~s }V ^ t = L M { s o f t m a x [ ( V ~ t W q ) ( V ~ s W k ) T ] ( V ~ s W v ) W p + V ~ t } \hat{V}_t=LM{softmax(\tilde{V}_tW_q)(\tilde{V}_sW_k)^TW_p +\tilde{V}_t }V ^t =L M {so f t ma x (V ~t W q )(V ~s W k )T W p +V ~t }其中W ( ⋅ ) W{(\cdot)}W (⋅)均表示可学习的参数。得到节点V ^ s / t \hat{V}{s/t}V ^s /t 后,就可以计算节点的关联矩阵M a f f M{aff}M a ff 如下M a f f i , j = f m l p { f p ( v ^ s i ) ∥ f p ( v ^ t i ) } M_{aff}^{i,j}=f_{mlp}{f_p(\hat{v}s^i)\|f_p(\hat{v}_t^i)}M a ff i ,j =f m lp {f p (v ^s i )∥f p (v ^t i )}其中∥ \|∥表示级联操作,f p f_p f p 表示一个线性映射,f m l p f{mlp}f m lp 表示一个多层感知机。接下来M a f f M_{aff}M a ff 经过一个实例规范化层和可微分的Sinkhorn层得到双随机关联矩阵M ~ a f f \tilde{M}_{aff}M ~a ff ,该矩阵表征了两个图的节点之间的最佳匹配关系。
损失函数

损失函数包含节点分类损失、图匹配损失、节点对抗损失、全局对抗损失和检测损失。
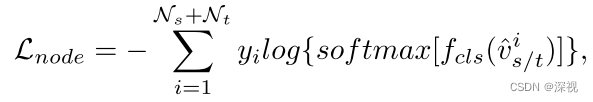
L n o d e L_{node}L n o d e 表示节点分类损失,y i y_i y i 表示正确标签或伪标签,f c l s f_{cls}f c l s 表示分类器。利用一个分类器根据增强后的节点特征进行类别预测,并使用交叉熵损失函数计算损失

L m a t L_{mat}L ma t 表示图匹配损失,Y Π Y_{\Pi}Y Π表示源域中的节点和目标域中的节点之间的类别匹配关系,如果v s i v_s^i v s i 和v t j v_t^j v t j 属于同一类别,则Y Π i , j = 1 Y_{\Pi}^{i,j}=1 Y Πi ,j =1,否则Y Π i , j = 0 Y_{\Pi}^{i,j}=0 Y Πi ,j =0。第一项是鼓励正确匹配的点,第二项是抑制错误匹配的点,第三项则是引入了结构约束,来最小化匹配的节点局部邻域内的结构差异。
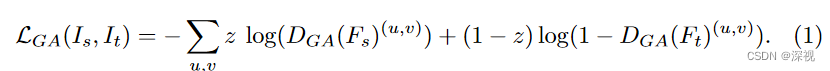
L G A L_{GA}L G A 表示基于图像的全局对抗损失,这是参考了EPM(Every pixel matters: Center-aware feature alignment for domain adaptive object detector.)算法。设计了一个辨别器D G A D_{GA}D G A 来判断每个像素点是来自于源域还是目标域,通过对抗训练的方式
实现任意类别的全局对齐。
L N A = − ∑ i N s D l o g { f d c [ f b ( v s i ) ] } − ∑ i N t ( 1 − D ) l o g { f d c [ f b ( v t i ) ] } L_{NA}=-\sum_{i}^{N_s}Dlog{f_{dc}[f_b(v_s^i)]}-\sum_{i}^{N_t}(1-D)log{f_{dc}[f_b(v_t^i)]}L N A =−i ∑N s D l o g {f d c [f b (v s i )]}−i ∑N t (1 −D )l o g {f d c [f b (v t i )]}
L N A L_{NA}L N A 表示节点对抗损失,f d c f_{dc}f d c 表示域分类器,f b f_b f b 表示堆叠的辨别模块(FC-LN-ReLU),D D D表示所属的域标签。考虑到图节点之间非网格的对应关系且属于非欧空间内的表征,作者参考L G A L_{GA}L G A 设计了节点辨别器用于对齐正确匹配的节点。
L d e t L_{det}L d e t 是一个常用的目标检测损失函数,参考FCOS,设计了包含分类、回归和中心对齐的损失。
; 创新点
- 提出一种新的领域自适应目标检测范式,将跨领域对齐定义为图匹配问题
- 提出一种图嵌入的语义补齐模块,解决了由于某种目标类别缺失导致的语义缺失问题
算法评价
本文使用图来建模不同类别的条件分布,并利用图匹配的方式来对齐源域和目标域,以实现领域自适应的目标检测。图结构相对于图像的像素点具备稀疏性和非网格属性,而相对于常用的prototype形式又具备一定的稠密性,这使得他能够更灵活准确地描述某个类别的特征分布。通过图匹配方法,将不同源的同类目标分布对齐。论文作者也发布了一篇文章(《CVPR2022 ORAL | 重新思考对齐Prototype的域自适应:基于Graph Matching的新范式》)介绍该文的算法思想,感兴趣的朋友可以去阅读学习。
如果大家对于深度学习与计算机视觉领域感兴趣,希望获得更多的知识分享与最新的论文解读,欢迎关注我的个人公众号” 深视“。
Original: https://blog.csdn.net/qq_36104364/article/details/126972934
Author: 深视
Title: 论文阅读笔记《SIGMA: Semantic-complete Graph Matching for Domain Adaptive Object Detection》
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/686462/
转载文章受原作者版权保护。转载请注明原作者出处!