

pd.DataFrame()
DataFrame 是一种二维的数据模型,相当于EXcel表格中的数据,有横竖两种坐标,横轴用columns,竖轴用index 来确定,在建立DataFrame 对象的时候,需要确定三个元素:数据,竖轴,横轴。
DataFrame既有行索引也有列索引,
import pandas as pd
import numpy as np
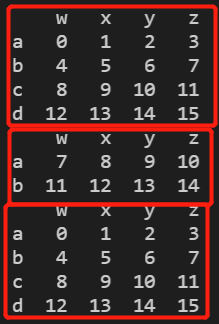
a = pd.DataFrame(np.arange(16).reshape(4,4),index=list('abcd'),columns=list('wxyz'))
print(a)
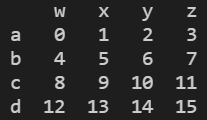

- 设置索引index
a.index = a['x']
print(a)
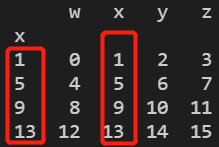
//可新建一个DataFrame,index设置为别的表格index
labels = pd.DataFrame(columns=['s','x'],index=a.index)
print(labels)
- a.iloc[行位置,列位置]
通过默认生成的数字索引查询指定的数据
下面表格说明:
- i值里的数字可以为正数也可以为负数,正数0代表第一行,1代表第2行;负数 -1代表倒数第一行,-2代表倒数第2行
方法说明:行(列)数索引值从0开始a.iloc[i]i值可以是数字也可以是一个数组,获取第i行数据或者行子集a.iloc[:,j]j值可以是数字也可以是一个数组, 获取第j列数据或者列子集a.iloc[i,j]获取第i行第j列的值
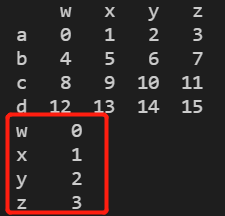
1. a.iloc[i] 获取第i行数据或者行子集
print(a)
print(a.iloc[0]) #获取第一行数据
print(a.iloc[:2]) #获取第一行和第二行

print(a.iloc[1:]) #获取第二行到最后一行的数据
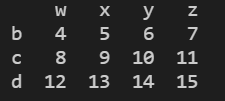
print(a.iloc[[0,-1]]) #获取第一行和倒数第一行数据
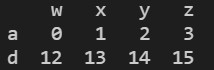
2. a.iloc[:,j] 获取第j列数据或者列子集
print(a.iloc(:,0) #获取第0列数据

print(a.iloc[:,[0,1]]) #获取第一列和第二列数据

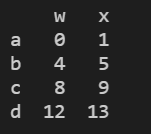
print(a.iloc[:,:2]) #获取第一列和第2列
3. a.iloc[i,j] 获取第i行第j列的值
print.iloc(-1,0) #获取倒数第一行第一列数据,即 12
print(a.iloc[1,[0,1]]) #获取第2行,第一二列数据
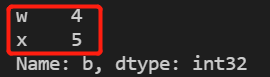
print(a.iloc[[0,1],2]) #获取第一二行第3列数据
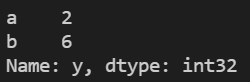
print(a.iloc[[0,1],[1,2]]) #获取第一二行的第二三列数据

- 将Pandas中的DataFrame类型转换成Numpy中array类
在用pandas包和numpy包对数据进行分析和计算时,经常用到DataFrame和array类型的数据。在对DataFrame类型的数据进行处理时,需要将其转换成array类型
1.a.values
import numpy as np
import pandas as pd
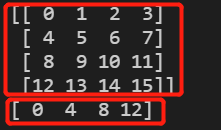
print(a.values)
print(a['w'].values)
2.使用numpy中的array方法
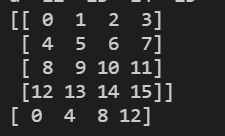
print(np.array(a))
print(np.array(a['w']))
- pandas使用sort_index排序
DataFrame.sort_index(axis=0, level=None, ascending=True, inplace=False, kind=’quicksort’, na_position=’last’, sort_remaining=True, ignore_index=False, key=None)[source]
sort_index文档
axis:0按照行名排序;1按照列名排序
level:默认None,否则按照给定的level顺序排列—貌似并不是,文档
ascending:默认True升序排列;False降序排列
inplace:默认False,否则排序之后的数据直接替换原来的数据框
kind:排序方法,{‘quicksort’, ‘mergesort’, ‘heapsort’}, default ‘quicksort’。似乎不用太关心。
na_position:缺失值默认排在最后{“first”,”last”}
by:按照某一列或几列数据进行排序,但是by参数貌似不建议使用
- x.sort_index() 默认参数ascending=True 对行index升序排列
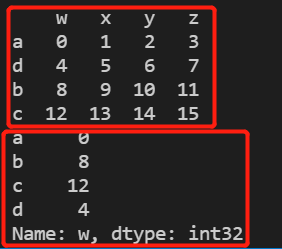
c = pd.DataFrame(np.arange(16).reshape(4,4),index=list('adbc'),columns=list('wxyz'))
print(c['w'].sort_index()) #原本index为adbc,对index排序后变成abcd
c = pd.DataFrame(np.arange(16).reshape(4,4),index=list('adbc'),columns=list('wxyz'))
print(c)
c.sort_index(ascending=True,inplace=True)
print(c) #inplace=True,这时候c被修改了
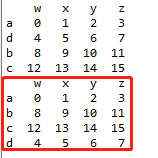
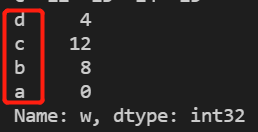
- x.sort_index(ascending=False)对行index降序排列
print(c['w'].sort_index(ascending=False))
3. 对列columns排序
默认axis=0,对行index排序,axis=1对列index排行
d = pd.DataFrame(np.arange(16).reshape(4,4),index=list('adbc'),columns=list('zwyx'))
print(d)
print(d.sort_index(axis=1)) # 原本列columns为zwyx, 对列columns排序后变成wxyz
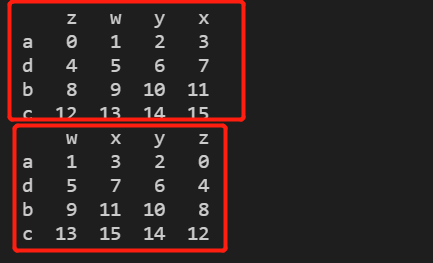
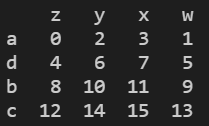
- 对列columns降序排列
print(d.sort_index(axis=1,ascending=False)) # 原本列columns为zwyx, 对列columns排序后变成zyxw
- pandas中的rolling函数用于移动计算
DataFrame.rolling(window, min_periods=None, center=False, win_type=None, on=None, axis=0, closed=None, method=’single’)
rolling文档
window: 也可以省略不写。表示时间窗的大小,注意有两种形式(int or offset)。如果使用int,则数值表示计算统计量的观测值的数量即向前几个数据。如果是offset类型,表示时间窗的大小。、min_periods:每个窗口最少包含的观测值数量,小于这个值的窗口结果为NA。值可以是int,默认None。offset情况下,默认为1。
center参数,默认为False,表示当前元素往上选,加上本身总共筛选3个。
center参数,默认为True,表示以当前元素为中心,从个方向进行筛选。
win_type: 窗口的类型。截取窗的各种函数。字符串类型,默认为None。各种类型
on: 可选参数。对于dataframe而言,指定要计算滚动窗口的列。值为列名。
axis: int、字符串,默认为0,即对列进行计算
closed:定义区间的开闭,支持int类型的window。对于offset类型默认是左开右闭的即默认为right。可以根据情况指定为left both等。
print(d)
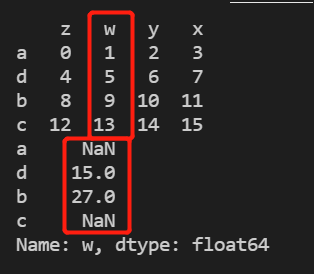
print(d['w'].rolling(3).sum()) #相当于创建了一个长度为3的窗口,窗口从上到下依次滑动,当前行加上前2行数据的总和
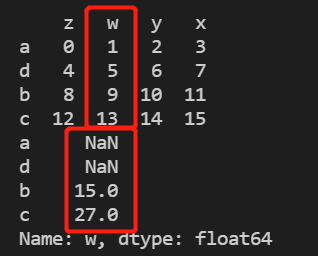
print(d['w'].rolling(3,center=True).sum())
6.pandas的填充缺失值fillna()
在数据集里面的缺失值需要填充起来,避免各种出错,在做分析的时候,我们经常要将缺失值填充为前一个值,或者是后一个值。
DataFrame.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None)[source]
参数说明method取值 : {‘backfill’, ‘bfill’, ‘pad’, ‘ffill’, None}, default None
pad/ffill:用前一个非缺失值去填充该缺失值
backfill/bfill:用下一个非缺失值填充该缺失值
None:指定一个值去替换缺失值(缺省默认这种方式)inplaceFalse 创建一个副本,修改副本,原对象不变(缺省默认)
True 直接修改原对象axis默认是纵向填充的;1是左右横向填充的
import pandas as pd
import numpy as np
from numpy import nan as NaN
df1=pd.DataFrame([[1,2,3],[NaN,NaN,2],[NaN,NaN,NaN],[8,8,NaN]])
print(df1)

1.用常数填充
print(df1.fillna(100)) # 将所有NaN替换成100

2.用字典填充
print(df1.fillna({0:10,1:20,2:30})) # 将columns为0的所有NaN填充10,为1列的所有NaN填充20,为2列的所有NaN填充30

3.用前一个非缺失值去填充
print(df1.fillna(method='ffill')) #用前一个非缺失值去填充该缺失值

4.用后一个非缺失值去填充
print(df1.fillna(method='bfill')) #用后一个非缺失值去填充该缺失值

7.pandas中的where()
where文档
DataFrame.where(cond, other=nan, inplace=False, axis=None, level=None, errors=’raise’, try_cast=NoDefault.no_default)
cond :条件判断
other: 条件cond为False时,将值替换为other
import pandas as pd
import numpy as np
df1=pd.DataFrame([[1,2,3],[4,5,6],[7,8,9]])
print(df1)

print(df1.where(df1!=1,100)) #条件判断为False的值替换为100,即值为1的替换成100

- pandas.DataFrame.copy
DateFrame.copy(deep=True) :复制object的索引和数据
-
当deep=True时(默认), 会创建一个新的对象进行拷贝. 修改这份拷贝不会对原有对象产生影响.
-
当deep=False时, 新的对象只是原有对象的references. 任何对新对象的改变都会影响到原有对象
a = pd.DataFrame(np.arange(16).reshape(4,4),index=list('abcd'),columns=list('wxyz'))# b = pd.DataFrame(np.array([33,11,22,44]),index=list('adbc'),columns=['m'])
print(a)
p = a.iloc[2:]
p.index = a.iloc[:2].index
print(p)
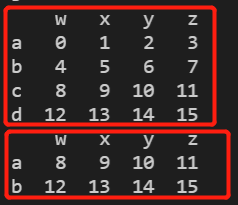
p.iloc[:2] = p - 1
print(p)
print(a) #可以看到a的后2行也被修改了
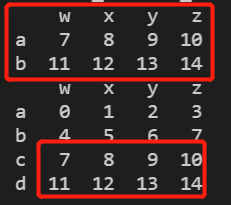
上面操作可以看到修改p后a也被修改了,因此我们可以用DateFrame.copy(deep=True) 复制索引和数据。
a = pd.DataFrame(np.arange(16).reshape(4,4),index=list('abcd'),columns=list('wxyz'))# b = pd.DataFrame(np.array([33,11,22,44]),index=list('adbc'),columns=['m'])
print(a)
p = a.iloc[2:].copy(deep=True)
p.index = a.iloc[:2].index
p.iloc[:2] = p - 1
print(p)
print(a) #此时a没有变化
Original: https://blog.csdn.net/qq_34035425/article/details/121078711
Author: Jqlender
Title: pandas中的DataFrame数据结构
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/675397/
转载文章受原作者版权保护。转载请注明原作者出处!