

1. 什么是 DStream ?
1. A Discretized Stream(一个离散化流)
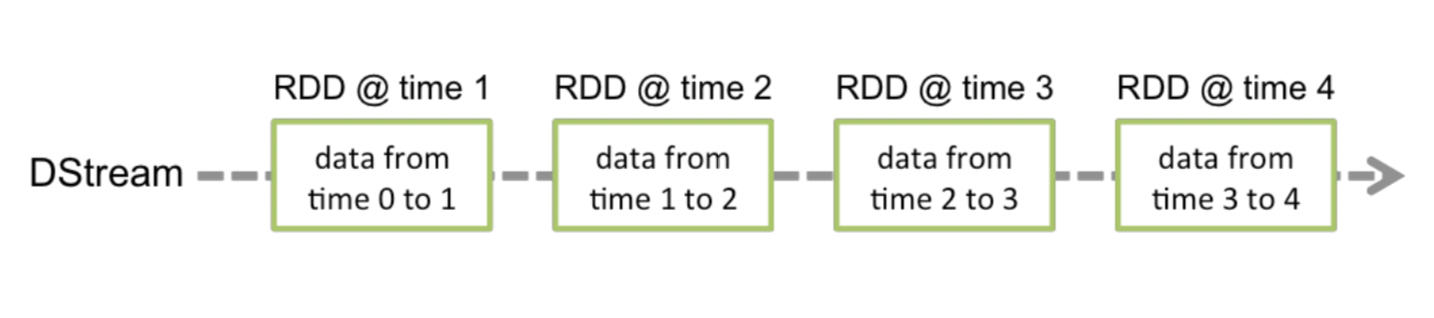
2. Spark Streaming 中基本抽象
表示: 一系列 连续的 RDD
每个RDD包含 一段时间间隔(采集周期) 内的数据
3. 是一个抽象类,定义了 几个重要的属性
def slideDuration: Duration => 生成RDD的时间间隔
def dependencies: List[DStream[_]] => 依赖的父DStream列表
def compute(validTime: Time): Option[RDD[T]] => 每个时间间隔后生成RDD的函数

2. 创建 DStream
1. 通过 读取 数据流 创建 DStream的实例
TCP => ReceiverInputDStream
HDFS => MappedDStream
Kafka => DirectKafkaInputDStream
Queue => QueueInputDStream
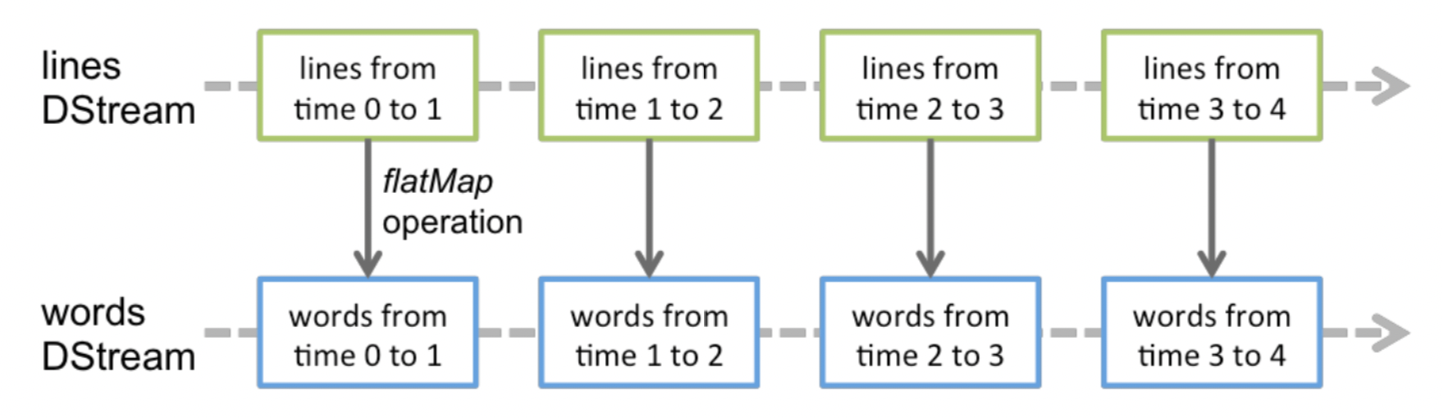
2. 通过 算子 转换 成DStream
3. 怎样理解 DStream算子 的有状态 和 无状态
/*
* TODO 怎样理解 DStream算子 的有状态 和 无状态
* 无状态的 转换算子
* 在每个采集周期内,都会将采集的数据生成一个RDD
* 无状态是指 只操作 采集当前周期内的RDD
* 示例:
* map、flatmap、filter、repartition、groupByKey
*
* 有状态的 转换算子
* 有状态是指 会将之前采集周期内采集的数据 与当前采集周期的数据做聚合操作
*
* */
4. 无状态 转换算子
/*
* TODO transform 算子
* 功能:
* 返回新的DStream,会将采集周期内的RDD 作为参数进行转换
* 使用场景:
* 1. DStream功能不完善
* 2. 需要代码周期性的执行(将采集周期内的RDD 写出到数据库,可以创建一次连接,多次写入)*
*
* */
// TODO 无状态 转换算子
object NoHaveStateOperator extends App {
//1.初始化 Spark 配置信息
private val sparkConf: SparkConf = new SparkConf().setMaster("local[5]").setAppName("NoHaveStateOperator")
//2.初始化 StreamingContext(并指定采集周期)
private val ssc: StreamingContext = new StreamingContext(sparkConf, Seconds(4))
//3.通过监控socket端口创建DStream
private var dstream: ReceiverInputDStream[String] = ssc.socketTextStream("gaocun", 9999)
//MapOper
//groupByKeyOper
//JoinOper // 两条流 做join操作
transformOper
def MapOper(): Unit = {
var map_ds: DStream[(String, Int)] = dstream.map(e => {
// 打印 Executor 端 PID 和 线程名称
println(s"Executor-ThreadName:${Thread.currentThread.getName}")
println(s"Executor-PID:${ManagementFactory.getRuntimeMXBean.getName}")
(e, 1)
}
)
map_ds.print()
}
def groupByKeyOper = {
val kv_ds: DStream[(Int, String)] = dstream.map((1, _))
val group_kv: DStream[(Int, Iterable[String])] = kv_ds.groupByKey()
group_kv.print()
}
def JoinOper = {
val dstream1: ReceiverInputDStream[String] = ssc.socketTextStream("gaocun", 9998)
val ds1: DStream[(String, Int)] = dstream.map((_, 1))
val ds2: DStream[(String, Int)] = dstream1.map((_, 2))
val join_ds: DStream[(String, (Int, Int))] = ds1.join(ds2)
join_ds.print()
}
def transformOper = {
val ds: DStream[String] = dstream.transform(
rdd => {
// code : Driver端执行(每个采集周期执行一次)
// 打印 Driver 的 PID 和 线程名称
println(s"transform-ThreadName:${Thread.currentThread.getName}")
println(s"transform-pid:${ManagementFactory.getRuntimeMXBean.getName}")
rdd.map(
e => {
// code : Executor端执行
// println(s"map:${Thread.currentThread.getName}")
// println(s"map-pid:${ManagementFactory.getRuntimeMXBean.getName}")
e
}
)
}
)
ds.print()
}
// 打印 Driver 的 PID 和 线程名称
println(s"Driver-ThreadName:${Thread.currentThread.getName}")
println(s"Driver-PID:${ManagementFactory.getRuntimeMXBean.getName}")
//Start the execution of the streams
ssc.start()
//等待执行结束(在执行过程中 任何的异常都会触发程序结束)
ssc.awaitTermination()
}
5. 有状态 转换算子
package com.dxm.sparkstreaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
/*
*
* TODO updateStateByKey 算子
* 功能:
* 对 key-value型的 DStream,做聚合操作(更新相同key 的value值) 返回新的 StateDStream
* 参数:
* updateFunc: (Seq[V], Option[S]) => Option[S]
* Seq[V]: 当前采集周期内 相同key value的集合
* Option[S]: 上一周期内 相同key 的value值
* partitioner: Partitioner => 指定分区器(默认使用HashPartitioner)
* rememberPartitioner: Boolean
* 执行流程:
* 当前采集周期 DStream => (a,1),(a,1),(a,1),(a,1),(a,1)
* 上一采集周期 StateDStream => (a,1)
* 聚合函数:
* def (当前采集周期value值集合,上一周期内value值) => 集合后的value值
*
* 注意:
* 使用 updateStateByKey 算子时,必须指定 checkpoint(会存储上一采集周期内 聚合的结果)
*
*
* */
// TODO 有状态 转换算子
object HaveStateOperator extends App {
//1.初始化 Spark 配置信息
private val sparkConf: SparkConf = new SparkConf().setMaster("local[3]").setAppName("HaveStateOperator")
//2.初始化 StreamingContext(并指定采集周期)
private val ssc: StreamingContext = new StreamingContext(sparkConf, Seconds(5))
//3.通过监控socket端口创建DStream
private var dstream: ReceiverInputDStream[String] = ssc.socketTextStream("gaocun", 9999)
updateStateByKeyOper
def updateStateByKeyOper = {
ssc.checkpoint("/Users/dxm/Desktop/home/d_book/java_home/SparkAPI/src/main/data/sparkstreaming/checkpoint")
val kv_ds: DStream[(String, Int)] = dstream.map((_, 1))
// 更新相同key 的value值
val state_ds = kv_ds.updateStateByKey(
(current_values: Seq[Int], buff_value: Option[Int]) => {
// 对Value 做累加
Option(current_values.sum + buff_value.getOrElse(0))
// 将Value 放入到集合中
//Option(current_values.toList.union(buff_value.getOrElse(List())))
}
)
state_ds.print()
}
//Start the execution of the streams
ssc.start()
//等待执行结束(在执行过程中 任何的异常都会触发程序结束)
ssc.awaitTermination()
}
6. Window 算子
package com.dxm.sparkstreaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
/*
*
* TODO window 算子
* 1.怎样理解 window 算子
* 采集器 在固定采集周期内采集数据 -----rdd1----rdd2----rdd3----rdd4--...--->
* window 算子每次获取x个采集周期内的数据 -----win(rdd1----rdd2)----win(rdd3----rdd4)--...--->
* window 可以按照一定的 时间间隔 水平滑动
* 2.语法
* window(windowDuration: Duration, slideDuration: Duration): DStream[T]
* 参数:
* windowDuration: window 的宽度(时间长度),必须是采集周期的整数倍
* slideDuration: window 滑动间隔(时间长度),必须是采集周期的整数倍
* 3.功能
* 返回新的DStream,元素为 窗口内的所有元素
*
* TODO countByWindow 算子
* 功能:
* 返回新的DStream,元素为 对窗口内所有元素个数 计数
*
* TODO reduceByWindow 算子
* 功能:
* 返回新的DStream,元素为 窗口内的所有元素 都会根据指定的reduce函数做聚合
* 语法:
* def reduceByWindow(
* reduceFunc: (T, T) => T, 指定聚合函数
* windowDuration: Duration, 窗口大小
* slideDuration: Duration 滑动时长
* ): DStream[T]
*
* TODO reduceByKeyAndWindow 算子
* 功能:
* 返回新的DStream, 元素为 窗口内所有的元素做 reduceByKey 操作
* 语法:
* def reduceByKeyAndWindow(
* reduceFunc: (V, V) => V, 指定value的聚合规则
* windowDuration: Duration, 窗口大小
* slideDuration: Duration 滑动时长
* ): DStream[(K, V)]
* 注意:
* 元素数据类型必须为 (k,v)
*
* TODO reduceByKeyAndWindow(有状态) 算子
* 功能:
* 返回新的DStream, 元素为 新进入窗口的所有元素 reduceByKey后, 再与要离开窗口的元素 聚合
* 语法:
* def reduceByKeyAndWindow(
* reduceFunc: (V, V) => V, 当前窗口元素聚合规则
* invReduceFunc: (V, V) => V, 与要离开窗口元素聚合规则
* windowDuration: Duration,
* slideDuration: Duration = self.slideDuration,
* numPartitions: Int = ssc.sc.defaultParallelism,
* filterFunc: ((K, V)) => Boolean = null
* ): DStream[(K, V)]
*
* TODO countByValueAndWindow 算子
* 功能:
* 返回新的DStream, 元素为 窗口内所有元素 分组计数 (x,cnt)
*
*
* */
// TODO Window 算子
object WindowOperator extends App {
//1.初始化 Spark 配置信息
private val sparkConf: SparkConf = new SparkConf().setMaster("local[3]").setAppName("HaveStateOperator")
//2.初始化 StreamingContext(并指定采集周期)
private val ssc: StreamingContext = new StreamingContext(sparkConf, Seconds(5))
//3.通过监控socket端口创建DStream
private var dstream: ReceiverInputDStream[String] = ssc.socketTextStream("gaocun", 9999)
//windowOper
//countByWindowOper
//reduceByWindowOper
//reduceByKeyAndWindowOper
//reduceByKeyAndWindowStatusOper
countByValueAndWindowOper
def windowOper = {
val win_ds: DStream[String] = dstream.window(Seconds(10), Seconds(5))
win_ds.print()
}
def countByWindowOper = {
ssc.checkpoint("/Users/dxm/Desktop/home/d_book/java_home/SparkAPI/src/main/data/sparkstreaming/checkpoint")
val count_ds: DStream[Long] = dstream.countByWindow(Seconds(10), Seconds(10))
count_ds.print()
}
def reduceByWindowOper = {
val kv_ds: DStream[(String, Int)] = dstream.map((_, 1))
val reduce_ds: DStream[(String, Int)] = kv_ds.reduceByWindow(
(e1: (String, Int), e2: (String, Int)) => {
println(e1.getClass.getName)
(e1._1 + e2._1, e1._2 + e2._2)
}
, Seconds(10)
, Seconds(10)
)
reduce_ds.print()
}
def reduceByKeyAndWindowOper = {
val kv_ds: DStream[(String, Int)] = dstream.map((_, 1))
val reduceByKey_ds: DStream[(String, Int)] = kv_ds.reduceByKeyAndWindow(
(e1: Int, e2: Int) => {
e1 + e2
},
Seconds(10), Seconds(10)
)
reduceByKey_ds.print()
}
def reduceByKeyAndWindowStatusOper = {
ssc.checkpoint("/Users/dxm/Desktop/home/d_book/java_home/SparkAPI/src/main/data/sparkstreaming/checkpoint")
val kv_ds: DStream[(String, Int)] = dstream.map((_, 1))
val reduceByKey_ds: DStream[(String, Int)] = kv_ds.reduceByKeyAndWindow(
(e1: Int, e2: Int) => {
// println(111)
// println(s"111:${e1}:${e2}")
e1 + e2
},
(e1: Int, e2: Int) => {
// println(s"222:${e1}:${e2}")
e1 + e2
},
Seconds(10), Seconds(10)
)
reduceByKey_ds.print()
}
def countByValueAndWindowOper = {
ssc.checkpoint("/Users/dxm/Desktop/home/d_book/java_home/SparkAPI/src/main/data/sparkstreaming/checkpoint")
val count_ds: DStream[(String, Long)] = dstream.countByValueAndWindow(Seconds(10), Seconds(10))
count_ds.print()
}
//Start the execution of the streams
ssc.start()
//等待执行结束(在执行过程中 任何的异常都会触发程序结束)
ssc.awaitTermination()
}
7. 输出 算子
package com.dxm.sparkstreaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
/*
* TODO 关于 DStream 的输出
* DStream 和 RDD 一样,也是惰性求值 如果 StreamingContext 中没有输出操作,整个Context将无法执行
*
* TODO print 算子
* 功能:
* 打印DStream 每个采集周期内RDD 的前x个元素
*
* TODO foreachRDD 算子
* 功能:
* 对DStream 每个采集周期内的RDD 应用指定的函数
* 语法:
* foreachRDD(foreachFunc: (RDD[T], Time) => Unit): Unit
* 参数:
* RDD[T] : RDD
* Time : 采集时间
* 使用场景:
* 这是DStream最通用的输出算子,可以再指定的函数中 将每个RDD输出到 外部系统(文件、网络、数据库)
*
* TODO saveAsTextFiles|saveAsObjectFiles|saveAsHadoopFiles 算子
* 功能:
* 将每个RDD 保存为 text格式的文件
* 将每个RDD 保存为 Java对象序列化格式的文件
* 将每个RDD 保存为 Hadoop files格式的文件
* 参数:
* def saveAsTextFiles(prefix: String, suffix: String = ""): Unit
* prefix: 文件名称_前缀
* suffix: 文件名称_后缀
* 最终格式: prefix-time.suffix
*
* TODO 保存到 HDFS
* 使用 foreachRDD 将每个RDD保存到HDFS
*
*
*
*
* */
// TODO 输出 算子
object OutputOperator extends App {
// 设置 提交任务用户名 hadoop用户名
System.setProperty("HADOOP_USER_NAME", "root")
//1.初始化 Spark 配置信息
private val sparkConf: SparkConf = new SparkConf().setMaster("local[5]").setAppName("OutputOperator")
//2.初始化 StreamingContext(并指定采集周期)
private val ssc: StreamingContext = new StreamingContext(sparkConf, Seconds(10))
//3.通过监控socket端口创建DStream
private var dstream: ReceiverInputDStream[String] = ssc.socketTextStream("gaocun", 9999)
//打印当前采集周期RDD 的前x个元素(默认为10个)
//dstream.print()
//foreachRddDef
def foreachRddDef = {
dstream.foreachRDD(
(rdd, time) => {
println(time.toString())
println(rdd.getClass.getName)
}
)
}
//saveAsTextFilesDef
def saveAsTextFilesDef = {
// 输出到文本文件
var outputPath = "/Users/dxm/Desktop/home/d_book/java_home/SparkAPI/src/main/data/sparkstreaming/"
dstream.saveAsTextFiles(s"${outputPath}gc", "txt")
// gc-1658492596000.txt
// ._SUCCESS.crc
// .part-00000.crc
// _SUCCESS
// part-00000
}
//saveAsHdfsDef
def saveAsHdfsDef = {
dstream.foreachRDD(
(rdd, time) => {
println(time.toString())
println(rdd.collect().mkString(","))
rdd.repartition(1).saveAsTextFile("hdfs://gaocun:8020//sparkstreaming")
}
)
}
//Start the execution of the streams
ssc.start()
//等待执行结束(在执行过程中 任何的异常都会触发程序结束)
ssc.awaitTermination()
}
Original: https://www.cnblogs.com/bajiaotai/p/16565552.html
Author: 学而不思则罔!
Title: 3_Spark Streaming DStream 及 算子
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/683564/
转载文章受原作者版权保护。转载请注明原作者出处!