

目标检测算法最难理解的,设计最复杂的就是 正负样本分配和 损失函数这块了,这两者将很大程度决定网络的训练效果,因此开帖对yolo系列做一总结,重点也在这两者,吸收他人优秀博客内容,进行整理,由于主要是为了方便自己今后查阅,所以碎碎念可能比较多。


; YOLO v1:
2016 CVPR有两个明星,一个是resnet,另一个就是YOLO。

上图是网络输出,注意里面每个格子预测两个Box,即论文中的B设置为2,但只有一组class probabilities,即每个格子只能预测一个物体,两个Box是为了让每一个格子可以学到多种类型的边界框。
正负样本分配:
某个grid cell的预测结果与gt中所有目标计算IoU,IoU最高的那个物体视为这个grid cell应该去预测的目标,即yolo的每个grid cell只负责预测一个物体,由于只有7*7个grid cell,所以yolo对密集排布的目标预测效果差。
论文中损失:

同济子豪兄的注释:

- 损失平衡系数:λ c o o r d \lambda_{coord}λcoor d 是正样本BBox损失的权重系数,论文中设置为5。而负样本不计算BBox损失,只计算是否存在目标的obj损失,其系数λ n o o b j \lambda_{noobj}λn oo bj 设置为0.5,正样本的该损失权重设置为1,正样本的obj损失中标签C ^ i \hat{C}_i C ^i 不是1,是目前预测结果与分配到的正样本的IoU,负样本该项为0。
- x,y,w,h:w,h都相对输入图像的尺寸归一化到0,1之间了,x,y是相对该grid cell左上角位置的偏移量,也在0~1范围内。
- 对w,h开根号的原因:我们对BBox预测的评价指标是IoU,但IoU相同时,大框的w、h所求得的损失肯定是比小框要高的开根号可以认为是为了增加sum-squared error (L2 loss)的尺度不变性。
- 对分类也是用L2损失:根据我调研的几个第三方的代码实现,这个p i ( c ) p_i (c)p i (c )和前式中的C i C_i C i 也没做过softmax(我没有看到)或sigmoid,网络最后一层是线性层,而p ^ i ( c ) \hat{p}_i (c)p ^i (c )的正样本和负样本标签分别为1和0,这样如果初始化不好,刚开始训练就有可能梯度爆炸吧,这个是我理解得有问题?
; YOLO v2:
相比v1,在backbone上有更新,加入了BN层,且检测头多了一个passthrough layer的短接以进行多尺度信息融合,最后的检测头还是只有一个,并且使用了anchor box机制,因为预测偏移量比直接预测更好学习,锚框的shape和大小是根据k-means聚类得到了5种锚框。论文标题的9000意思是可以使用文中所提的训练方法使yolov2实现9000种目标的检测。
结构图
backbone为darknet19,因为原始darknet19分类网络包含19个卷积层。

相比v1有以下改进:

接下来展开讲解。
; BN层

升级分辨率
这个分辨率指的是在imagenet上预训练的分辨率,相比v1中的224 _224,换成了448_448输入分辨率,最终目标检测都是用的448*448分辨率。作者意思224预训练到448做目标检测有跨度,不统一。
使用anchor的定位方式
每个grid cell(网格)可以最多预测5个物体,5代表五种不同的anchor:
所以检测头是用(5+20)×5共125通道的1×1卷积核对最后的特征图进行卷积,得到了125×(13×13)的输出tensor。

; Dimension Cluster
在Faster RCNN和SSD中锚框的设置主要基于经验,而在该作中对训练集的gt框使用K-means聚类的方法得到锚框。

在faster rcnn中,中心点的预测是没有限制的,因为上式中的tx和ty的取值是没有限制的,这使得网络可能由左上角的锚框预测了一个位于左下角的图像,这是不稳定的,作者提出了新的预测方式:
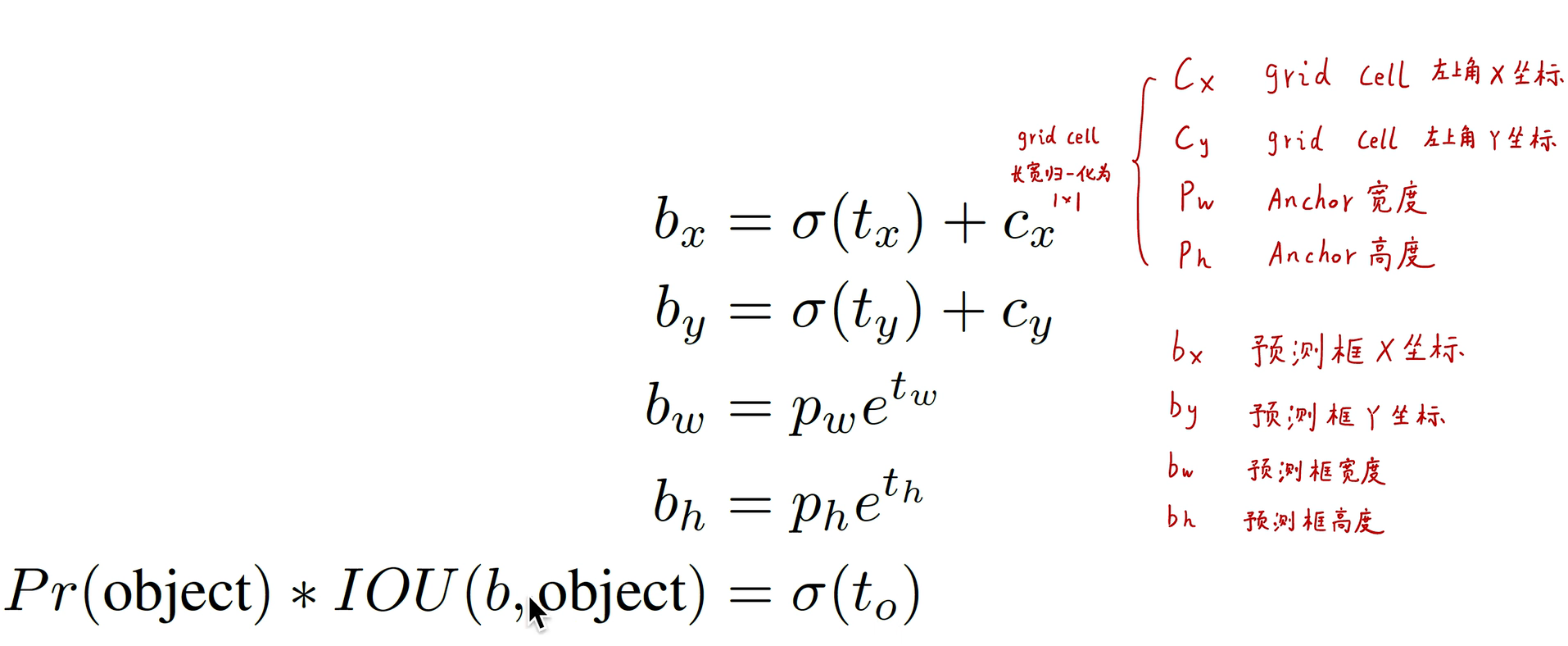
其中的sigmoid函数使得每个cell的预测结果的中心位置都是落在该cell中。
; Fine-Grained Features
为了利用细粒度特征帮助检测小目标,使用了一个paththrough layer(与yolov5中的focus操作类似)将13 13与26 26的特征图进行了信息融合:

可以看到这是个宽高减半,通道数乘4的操作。
多尺度训练
为了提升网络的鲁棒性,每训练十个epoch,在320到608中随机挑选一个尺度(32的倍数)作为输入分辨率。
下面两点论文中几乎没有提及,需要在代码中学习
正负样本匹配
该部分在损失函数中同时记录
损失函数:

上图是网友根据yolov2的代码整理的损失函数,式子中b i j k o b_{ijk}^{o}b ijk o 是obj置信度,b i j k r b_{ijk}^{r}b ijk r 是预测的BBox位置信息,其中r ∈ ( x , y , w , h ) , b i j k c r\in (x,y,w,h),b_{ijk}^{c}r ∈(x ,y ,w ,h ),b ijk c 是预测的框所属类别。p r i o r k r prior_{k}^{r}p r i o r k r 是anchor的位置,因为每个cell中的五个anchor都是一样的,所以下角标只需要知道anchor属于这五个anchor的哪一个信息。t r u t h r truth^{r}t r u t h r是标注框的位置信息。t r u t h c truth^{c}t r u t h c是标注框的类别信息。I O U t r u t h k IOU_{truth}^{k}I O U t r u t h k 是anchor与标注框的IOU。
loss由三部分组成,其中标黄的部分非0即1。
第一部分标黄部分,为负样本惩罚,表示预测框与标注框的IOU如果小于阈值0.6,那视作这个预测框是与负样本匹配了,取值1,反之为0,后面的部分表示标签0与置信度b i j k o b_{ijk}^{o}b ijk o 的L2损失。这个IoU的计算是只根据大小和形状来计算的,与位置无关,即先将某个grid cell所属的anchor和gt(ground truth)中心位置重合,再计算IoU。
第二部分标黄部分,表示是在12800次迭代前,将anchor与预测框位置误差加入损失,可以使模型能够在前期学会预测anchor位置,使得输出的t x , t y , t w , t h t^{x},t^{y},t^{w},t^{h}t x ,t y ,t w ,t h更稳定;(这一项自己的理解不是很清晰)
第三部分标黄部分,表示预测框是否负责预测物体,该anchor与标注框的IoU最大对应的预测框负责预测物体(IOU>0.6但非最大的预测框忽略不计),其中第一项表示预测框与标注框的定位误差,第二项表示预测框的置信度与标注框和anchor的IoU的误差,表示预测框的所属分类结果与标注框的类别信息的误差,这个预测类别结果我看到的代码都是做了softmax的。
图中还有五个λ \lambda λ, 表示每一个损失的平衡系数。
; YOLO v3:

在coco mAP指标上,yolo v3相比retinanet没有优势,但在AP50上是又快又准。
backbone是darknet53,有残差结构,相比resnet,下采样采用步距为2的卷积而非maxpooling,
在多尺度融合网络部分,标准FPN使用add操作,而yolo v3使用concatenate操作。
在每个检测头上,有三种尺度的锚框,输出与v2类似。即一共有9种锚框(先验框),对应九层检测器。
正负样本匹配:
将与gt重合最大的先验框作为正样本obj,定位,类别损失都要计算;
将与gt重合度地低于某阈值的先验框作为负样本,只计算obj损失;
其他情况的先验框丢弃。
这种匹配方式其实是有缺点的,匹配到的正样本会很少,不利于网络的训练。在yolo v3
ultralytics中,会先将gt与9种先验框左上角对齐,然后计算IoU,将gt映射回超过阈值的先验框所对应的检测层的grid网格上,该gt中心点所在网格的先验框即分配为正样本,
这样因为有可能有多个先验框与gt重合度大于阈值,所以会有更多的先验框被作为正样本。
损失:
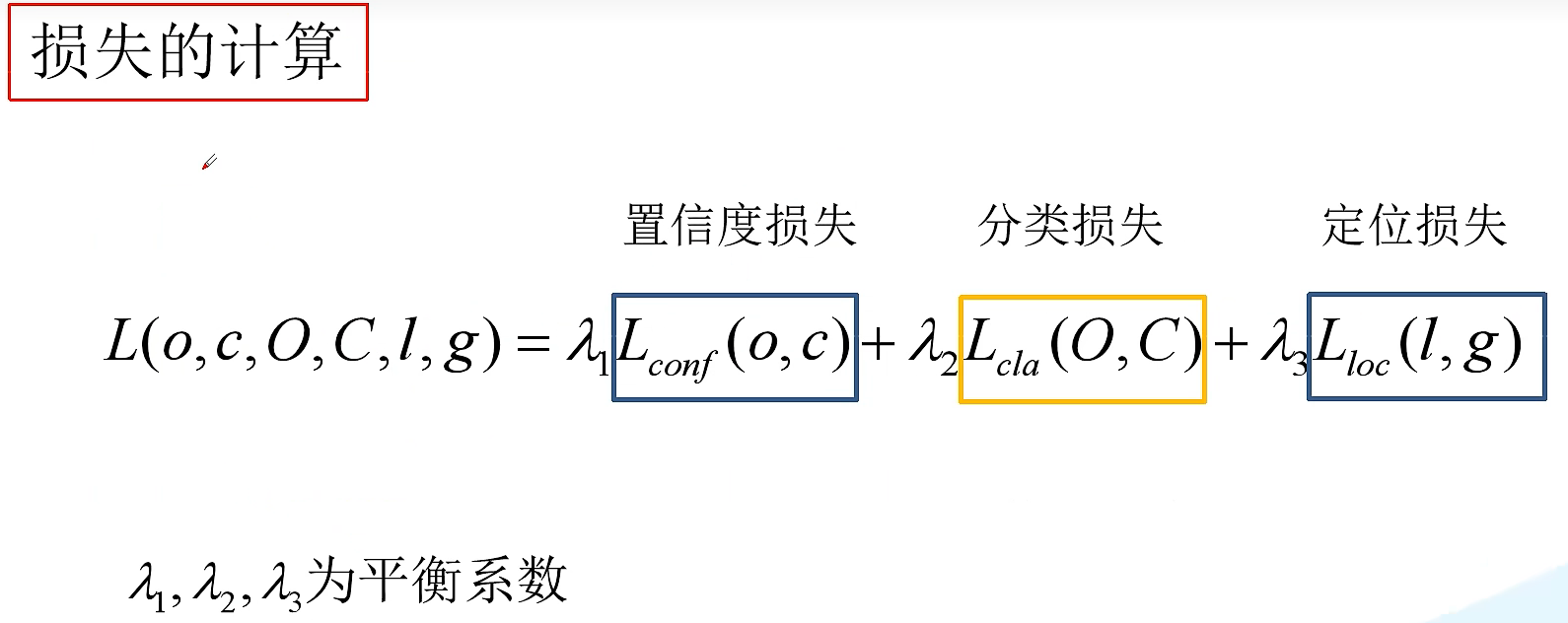
- 定位损失:SSE(sum of squared error loss), 下图中p代表锚框的参数,b代表预测框的参数,g代表gt的参数

v3中的分类损失是用BCE计算的:

其obj损失(conf损失)也是用BCE损失:原文中O i O_{i}O i 取0或1,是bool型

; YOLO v3-SPP和ultralytics
YOLO v3作为经典的目标检测算法,还有两个著名的改进版:YOLO v3 SPP和YOLO v3-SPP-ultralytics,相比原始版本精度有一定提升,但速度更慢了,总结其中的trick如下。

Mosaic 图像增强
该操作就是将随机的4副训练图像拼成一张图进行训练,优点如下:
- 增加数据多样性
- 增加目标个数
- BN能一次性统计多张图片的参数
SPP模块
下图是YOLO v3 SPP模块的网络结构,相比v3原版,修改了最大感受野特征图后面的Convolutional Set模块,加入了spp模块,spp模块key实现局部特征和全局特征(所以spp结构的最大的池化核要尽可能的接近等于需要池化的featherMap的大小)的featherMap级别的融合,丰富最终特征图的表达能力。

; CIoU loss
相比之前yolo系列使用L2损失来进行BBox回归,CIoU损失是更好的选择,我在另一篇笔记中有详细记录目标检测的各种BBox回归损失函数。
Original: https://blog.csdn.net/kill2013110/article/details/125545685
Author: cartes1us
Title: 目标检测中的损失函数与正负样本分配:YOLO v1, v2, v3,v3-spp-ultralytics
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/682867/
转载文章受原作者版权保护。转载请注明原作者出处!