

SSD
SSD用的是一种one-stage模型 SSD采用的主干网络是VGG网络。 SSD直接采用卷积对不同的特征图来进行提取检测结果。对于形状为m x n x p 的特征图,只需要采用3X3XP这样比较小的卷积核得到检测值。
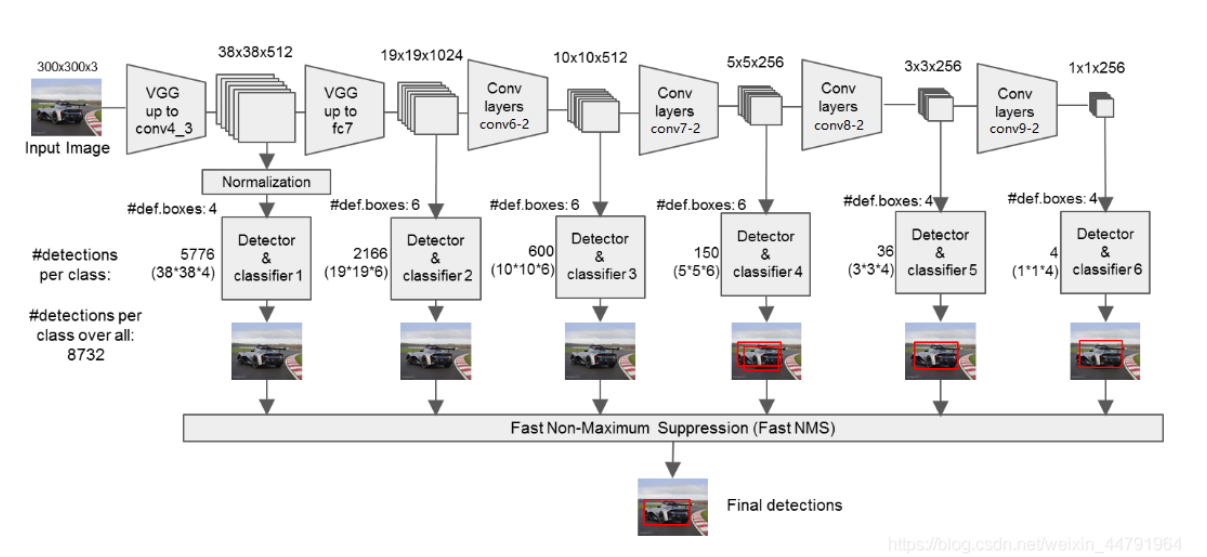
SD采用VGG16作为基础模型,然后在VGG16的基础上新增了卷积层来获得更多的特征图以用于检测。SSD的网络结构如下图所示。上面是SSD模型,下面是Yolo模型,可以明显看到SSD利用了多尺度的特征图做检测。模型的输入图片大小是300X300。
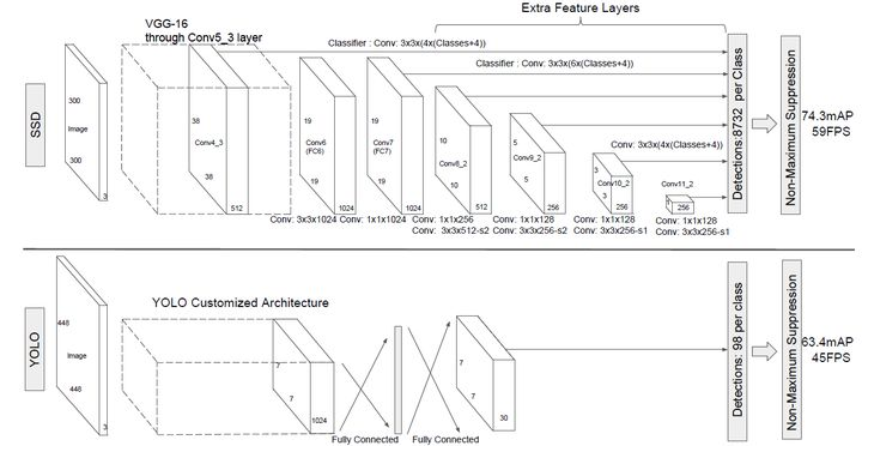

conv 表示卷积层。
VGG
MaxPool2d() 函数是用于最大池化
kernel_size是卷积核大小
stride是步长 2,长和高都会分别压缩一半
所以高和宽 会 被压缩。
padding 是对边缘部分的数据进行压缩
300 300 64 到 150 150 64
卷积不会改变图片的长和高
ReLU() 是激活函数
pool5 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
nn.ReLU(inplace=True), conv7, nn.ReLU(inplace=True)
nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True)]
其中ceil_mode 取值是true 和false。

卷积—-卷积—–最大池化
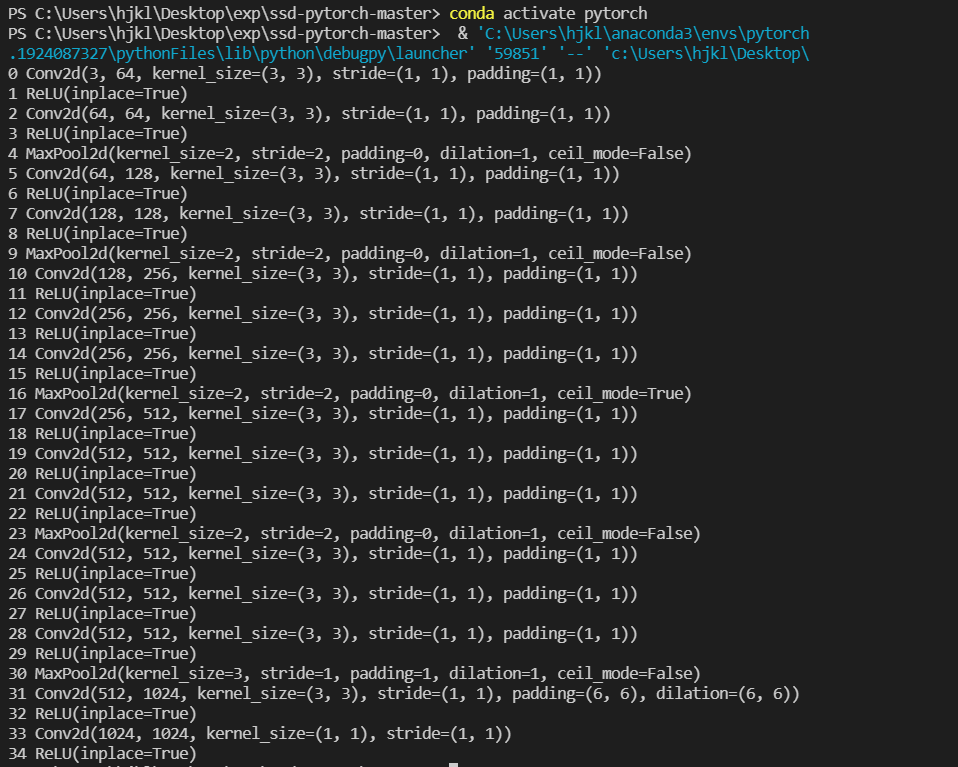
代码运行结果如下:
17 Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
18 ReLU(inplace=True)
19 Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
20 ReLU(inplace=True)
21 Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
22 ReLU(inplace=True)
23 MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
以下是VGG代码
import torch.nn as nn
from torchvision.models.utils import load_state_dict_from_url
'''
该代码用于获得VGG主干特征提取网络的输出。
输入变量i代表的是输入图片的通道数,通常为3。
300, 300, 3 -> 300, 300, 64 -> 300, 300, 64 -> 150, 150, 64 -> 150, 150, 128 -> 150, 150, 128 -> 75, 75, 128 ->
75, 75, 256 -> 75, 75, 256 -> 75, 75, 256 -> 38, 38, 256 -> 38, 38, 512 -> 38, 38, 512 -> 38, 38, 512 -> 19, 19, 512 ->
19, 19, 512 -> 19, 19, 512 -> 19, 19, 512 -> 19, 19, 512 -> 19, 19, 1024 -> 19, 19, 1024
38, 38, 512的序号是22
19, 19, 1024的序号是34
'''
base = [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'C', 512, 512, 512, 'M',
512, 512, 512]
def vgg(pretrained = False):
layers = []
in_channels = 3
for v in base:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
elif v == 'C':
layers += [nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
pool5 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
conv6 = nn.Conv2d(512, 1024, kernel_size=3, padding=6, dilation=6)
conv7 = nn.Conv2d(1024, 1024, kernel_size=1)
layers += [pool5, conv6,
nn.ReLU(inplace=True), conv7, nn.ReLU(inplace=True)]
model = nn.ModuleList(layers)
if pretrained:
state_dict = load_state_dict_from_url("https://download.pytorch.org/models/vgg16-397923af.pth", model_dir="./model_data")
state_dict = {k.replace('features.', '') : v for k, v in state_dict.items()}
model.load_state_dict(state_dict, strict = False)
return model
if __name__ == "__main__":
net = vgg()
for i, layer in enumerate(net):
print(i, layer)
Original: https://blog.csdn.net/m0_51265528/article/details/123686220
Author: 一个努力学习的萌新加油哦
Title: SSD学习笔记—2022年3月23日
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/682491/
转载文章受原作者版权保护。转载请注明原作者出处!