

主要贡献:
1.规避R-CNN中冗余的特征提取操作,只对整张图像全区域进行一次特征提取(首次在SPP-Net中提出);
2.用RoI pooling层取代最后一层max pooling层,同时引入建议框信息,提取相应建议框特征;
3.Fast R-CNN网络末尾采用并行的不同的全连接层,可同时输出分类结果和窗口回归结果,实现了end-to-end的多任务训练【建议框提取除外】,也不需要额外的特征存储空间【R-CNN中这部分特征是供SVM和Bounding-box regression进行训练的】;
4.采用SVD对Fast R-CNN网络末尾并行的全连接层进行分解,减少计算复杂度,加快检测速度。
背景:
1.R-CNN网络训练、测试速度都很慢:R-CNN网络中,一张图经由selective search算法提取约2k个建议框【这2k个建议框大量重叠】,而所有建议框变形后都要输入AlexNet CNN网络提取特征【即约2k次特征提取】,会出现上述重叠区域多次重复提取特征,提取特征操作冗余。
2.R-CNN网络训练、测试繁琐:R-CNN网络训练过程分为ILSVRC 2012样本下有监督预训练、PASCAL VOC 2007该特定样本下的微调、20类即20个SVM分类器训练、20类即20个Bounding-box 回归器训练,该训练流程繁琐复杂;同理测试过程也包括提取建议框、提取CNN特征、SVM分类和Bounding-box 回归等步骤,过于繁琐。
3.R-CNN网络训练需要大量存储空间:20类即20个SVM分类器和20类即20个Bounding-box 回归器在训练过程中需要大量特征作为训练样本,这部分从CNN提取的特征会占用大量存储空间;
4.R-CNN网络需要对建议框进行形变操作后【形变为227×227 size】再输入CNN网络提取特征:因为在提取完特征进行全连接操作的时候才需要固定特征尺寸【R-CNN中将输入图像形变为227×227可正好满足AlexNet CNN网络最后的特征尺寸要求】,然后才使用SVM分类器分类。
改进方法:
对于问题1:只对图片进行一次CNN特征提取操作,然后利用SS在原图上获取候选框,然后在特征图上找出相应的候选框区域,这样就可以避免冗余的特征提取操作。(此方法最早在SPP-Net中被提出来)
对于问题2、3:在网络末尾采用并行的不同的全连接层,可同时输出softmax分类结果和BBox回归结果(每类产生一个回归器,k类对应于4*k个回归值),实现了end-to-end的多任务训练【建议框提取除外】,也不需要额外的特征存储空间。
对于问题3:设计了ROI Pooling模块,它可以将不同尺寸的特征图上的候选框Pooling成固定尺寸,然后输入到并行的全连接层进行分类和回归。(RCNN中也有类似的操作,与之不同的是:1.RCNN中是对图像进行resize,而ROI Pooling是对feature map进行resize。2.RCNN中是在网络的一开始就进行resize,而ROI Pooling是在过程中进行resize)
模块设计:ROI Pooling模块
ROI Pooling层的输入:
1.经过基础网络卷积和池化后的固定大小的特征图;
2.表示ROI信息的N*5维的矩阵,其中N表示ROI数目,纵坐标的第一列表示图片在输入特征图batch中的索引,之后四位是ROI的左上角和右下角坐标的信息。
ROI Pooling层的操作:
将特征图中的ROI缩放到预定义的大小,如7*7的尺寸,缩放的处理流程包括:将ROI均分为等大的子区域,其数量与网络层的输出大小相同;计算每个子区域中的最大值或平均值;将每个子区域中的计算结果作为该层输出中的一个元素。
ROI Pooling层的输出:
经过该层后获得N*3维的矩阵,其中N表示ROI数目,纵坐标的第一列表示输出特征图batch中的索引,最后两位表示pooling后的输出大小。
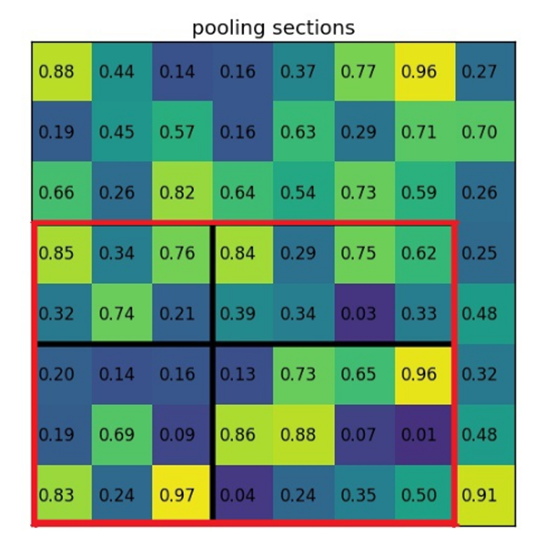
由该层的实际处理过程可知,ROI Pooling的输出维度实际上不依赖于特征图和其上产生ROI的大小,仅由ROI等分后的子区域的数目决定。整个处理过程可以通过一个例子近似展示。下图表示一个8 _8的feature map,红色框表示其中的一个ROI,ROI Pooling后的大小为2_2,也就是红色框中被黑色框分割后的区域数目。

; 训练阶段:
1.有监督预训练
ILSVRC 20XX样本只有类别标签,有1000种物体;文中采用AlexNet【S for small】、VGG_CNN_M_1024【M for medium】、VGG-16【L for large】这三种网络分别进行训练测试,下面仅以VGG-16举例。

2.特定样本下的微调

PASCAL VOC数据集中既有物体类别标签,也有物体位置标签,有20种物体;
正样本仅表示前景,负样本仅表示背景;
回归操作仅针对正样本进行;
该阶段训练集扩充方式:50%概率水平翻转;
微调前,需要对有监督预训练后的模型进行3步转化:
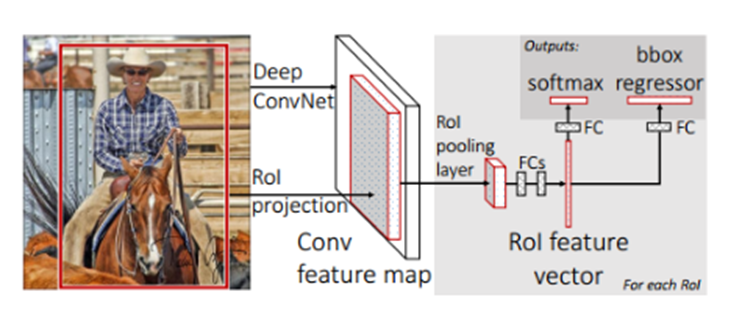
①RoI池化层取代有监督预训练后的VGG-16网络最后一层池化层;
②两个并行层取代上述VGG-16网络的最后一层全连接层和softmax层,并行层之一是新全连接层1+原softmax层1000个分类输出修改为21个分类输出【20种类+背景】,并行层之二是新全连接层2+候选区域窗口回归层,如下图所示;
③上述网络由原来单输入:一系列图像修改为双输入:一系列图像和这些图像中的一系列候选区域;
SGD超参数选择:
1.除了修改增加的层,原有的层参数已经通过预训练方式初始化;
2.用于分类的全连接层以均值为0、标准差为0.01的高斯分布初始化,用于回归的全连接层以均值为0、标准差为0.001的高斯分布初始化,偏置都初始化为0;
3.针对PASCAL VOC 2007和2012训练集,前30k次迭代全局学习率为0.001,每层权重学习率为1倍,偏置学习率为2倍,后10k次迭代全局学习率更新为0.0001;
4.动量设置为0.9,权重衰减设置为0.0005。
测试阶段:
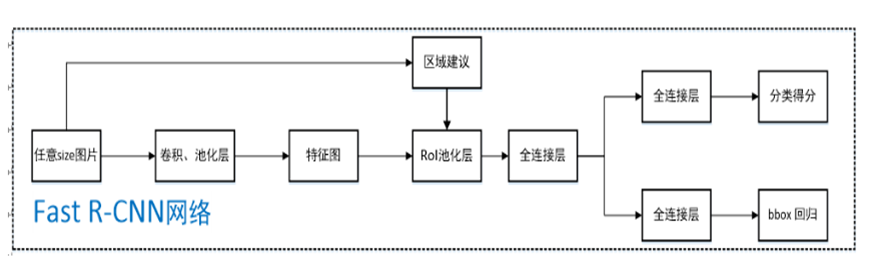
- 任意size图片输入CNN网络,经过若干卷积层与池化层,得到特征图;
- 在任意size图片上采用selective search算法提取约2k个建议框;
- 根据原图中建议框到特征图映射关系,在特征图中找到每个建议框对应的特征框【深度和特征图一致】,并在RoI池化层中将每个特征框池化到H×W 【VGG-16网络是7×7】的size;
- 固定H×W【VGG-16网络是7×7】大小的特征框经过全连接层得到固定大小的特征向量;
- 第4步所得特征向量经由两个并行的全连接层【由SVD分解实现】,分别得到两个输出向量:一个是softmax的分类得分,一个是Bounding-box窗口回归;
- 利用窗口得分分别对每一类物体进行非极大值抑制剔除重叠建议框,最终得到每个类别中回归修正后的得分最高的窗口。
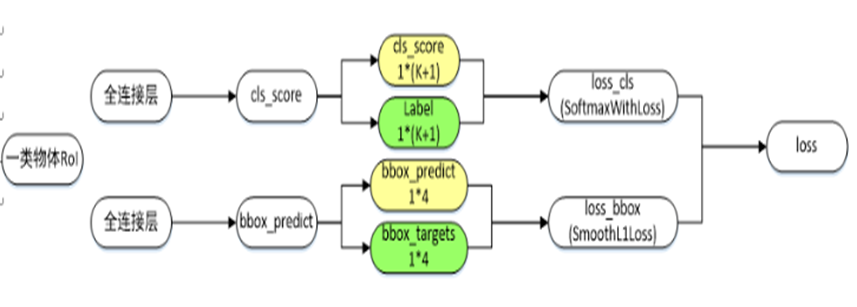
; 损失函数:
Fast rcnn中实现的是多任务学习,即proposals的分类任务和BBox回归任务,如下图所示【仅针对一个RoI即一类物体说明】,黄色框表示训练数据,绿色框表示输入目标:
优点:
1.不需要人为地对图片进行操作(RCNN中的这部分操作一定程度上破坏了图片的结构信息),在过程中自动地将特征图resize成固定的尺寸,以满足全连接层的输入要求。
2.只对图片进行一次CNN特征提取,然后共享特征图进行多任务操作,也就是共享了卷积操作,大大减少了计算量,减少了运行时间。
3.用softmax取代SVM分类器,将原来分步处理合并成一个连续的过程,避免了特征存储、浪费磁盘空间等问题,降低了过程的复杂度。
4.处理图片速度大大提高。
缺点:
Fast R-CNN中采用selective search算法提取候选区域,而目标检测大多数时间都消耗在这里【selective search算法候选区域提取需要2~3s,而提特征分类只需要0.32s】,这无法满足实时应用需求,而且Fast R-CNN并没有实现真正意义上的端到端训练模式【候选区域是使用selective search算法先提取出来的】。
准确率:
同样使用较大规模的网络,Fast RCNN和RCNN相比,训练时间从84小时减少为9.5小时,测试时间从47秒减少为0.32秒。在PASCAL VOC 2007上的准确率相差无几,约在66%-67%之间。
Original: https://blog.csdn.net/qq_41981894/article/details/123493091
Author: ZDA爱吃火锅
Title: Fast RCNN总结
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/682285/
转载文章受原作者版权保护。转载请注明原作者出处!