

···abstract
本文提出来voxel-based transformer 主骨干,叫做Voxel Transformer (VoTr)。3D卷积在voxel-based(体素系列)不能够有效捕捉大范围信息,由于感受野的限制。所以提出来将自注意力机制应用与voxel中,即transformer-based的结构能够解决这个问题。直接应用标准的transformer不可行,所以提出改进the sparse voxel module和the submanifold voxel model,这两个模块中的多头注意力中提出两个注意力机制:Local Attention 和 Dilated Attention。
1、Introduction
以前的方法分为两个分支:一个是point-based系列,另一个是voxel-based。point-based系列由于点云稀疏,直接操作点会造成时间资源消耗负担,voxel-based能够很好的利用稀疏卷积来操作。
3D卷稀疏卷积由于感受野的限制,有效性不是很好,但是改进感受野也不是很好处理。
最近transformer在2D方面效果很好,主要是因为像素能够通过自注意力机制构造大范围的关系。如果直接用transformer会有两个问题:1)非空体素太稀疏,所以应该设计特殊操作只关注非空的体素;2)非空体素数量大;所以非常需要新的方法来扩大关注范围,同时将每个查询的参与体素的数量保持在较小的值内。
为了解决第一个问题,作者提出the sparse voxel module和the submanifold voxel module,the submanifold voxel module严格用来操作非空体素的,用来保持原有3D几何形状;the sparse voxel module可以在空位置输出特征,更加灵活,可以进一步放大非空体素空间。为了解决第二个问题,在两个模块的多头注意力机制中应用两个注意力机制:Local Attention 和 Dilated Attention,Local Attention用来关注局部信息,Dilated Attention逐步增加搜索步长,扩展搜索范围。为了这两个注意力机制的查询速度,提出Fast Voxel Query:一个基于GPU的哈希表,用于高效地存储和查找非空体素。
3个贡献:
1)VoTr
2)the sparse voxel module和the submanifold voxel module 以及其中的Local Attention 和 Dilated Attention,包括Fast Voxel Query
3)实验效果很好。。。。。。
2、相关工作
point-based系列的实现model:F-PointNet利用frustum(锥体)、PointRCNN、3DSSD介绍一个新的采样策略
voxel-based系列的实现model:SECOND提出3D稀疏卷积、HVNet、PV-RCNN使用关键点提取特征
transformer-based系列的实现model:2D方面:Vision Transformer划分图片为一个个patch放入transformer、SETR逐级向上采样;MaX-DeepLab使用掩码的transformer;3D:Point Transformer、Pointformer
3、Voxel Transformer
3.1 整体结构
整体结构如图所示。
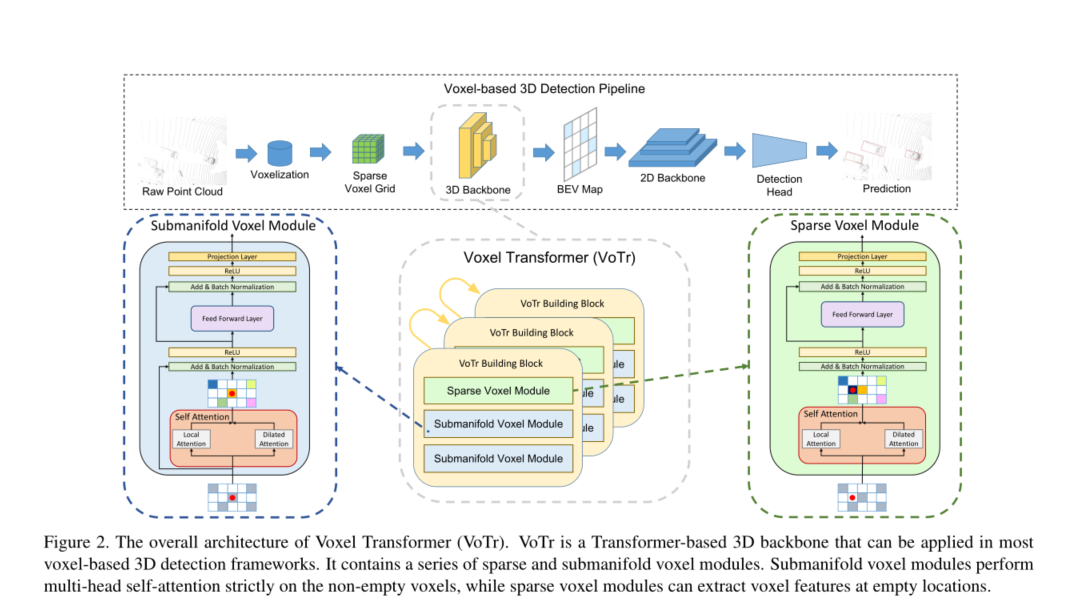

3.2 Voxel Transformer Module
VoTr由3个VoTr Building Block组成,每个VoTr Building Block由1个Sparse Voxel Module和2个Submanifold Voxel Module组成。子流形体素模块严格地对非空体素进行操作并且仅在非空位置提取特征;稀疏体素模块可以在空位置提取体素特征,表现出更大的灵活性,可以根据需要扩展原始的非空体素空间。
3.2.1 稀疏体素中的自注意力
1)首先将vi, vj 转换成真正的体素中心pi,pj,利用p = r ·(v + 0.5),其中r为体素大小,i表示要查询的体素,j为参与计算的体素。
2)计算位置编码Epos
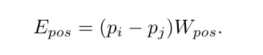
3) 计算Q,K,V
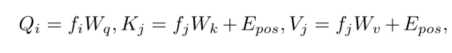
其中 Wq、Wk、Wv分别是查询、键和值的线性投影
4)计算注意力
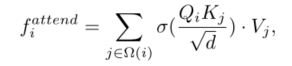
最后也是使用softmax函数,体素上的自我注意是标准2D自我注意的自然3D扩展,具有稀疏输入和相对坐标作为位置嵌入。
3.2.2 Submanifold Voxel Module
由两部分组成,self-attention layer 和 feed-forward layer。
标准的Transformer模块与我们提出的模块的主要区别在于三个方面:1)我们在前馈层之后增加了一个额外的线性投影层,用于体素特征的通道调整。2)用批归一化代替了层归一化。3)我们去除了模块中的所有丢弃层,因为参与的体素的数量已经很少,随机拒绝其中的一些体素阻碍了学习过程。
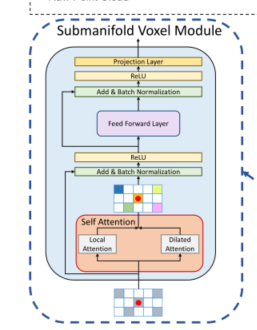
3.2.3 Sparse voxel module
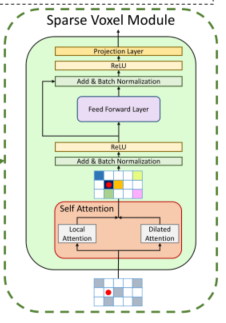
这个模块可以提取空位置的特征,导致原始非空空间的扩展 ,对于空位置的注意力,从特征中赋予初始值
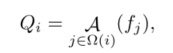
其中A是参与特征fj的maxpooling
两个模块仿佛只差一条残差边,原文这样说的:稀疏体素模块的体系结构类似于子流形体素模块,不同之处在于我们移除了自我关注层周围的第一个残余连接,因为输入和输出不再相同。
3.3 Efficient Attention Mechanism
探讨注意力的范围 Ω(i) 。文中说 Ω(i) 应该有三个要求:1)Ω(i)应覆盖相邻体素以保留细粒度的3D结构。2)Ω(i)应尽可能多地获取较大的上下文信息。3) Ω(i)中的参与体素数量应足够小。为了解决这些问题,提出了两种注意机制:局部注意和扩张注意Local Attention and Dilated Attention来控制注意范围Ω(i)。
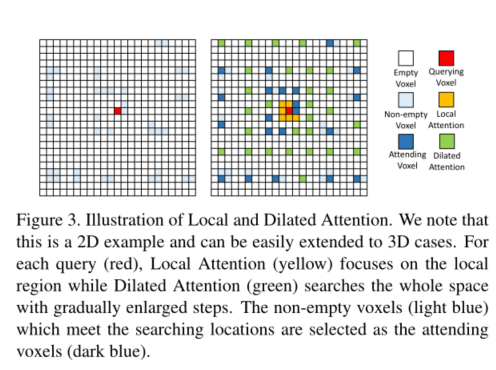
Dilated Attention应扩大范围,同时要保证参与查询体素数量小于50
3.4 Fast Voxel Query
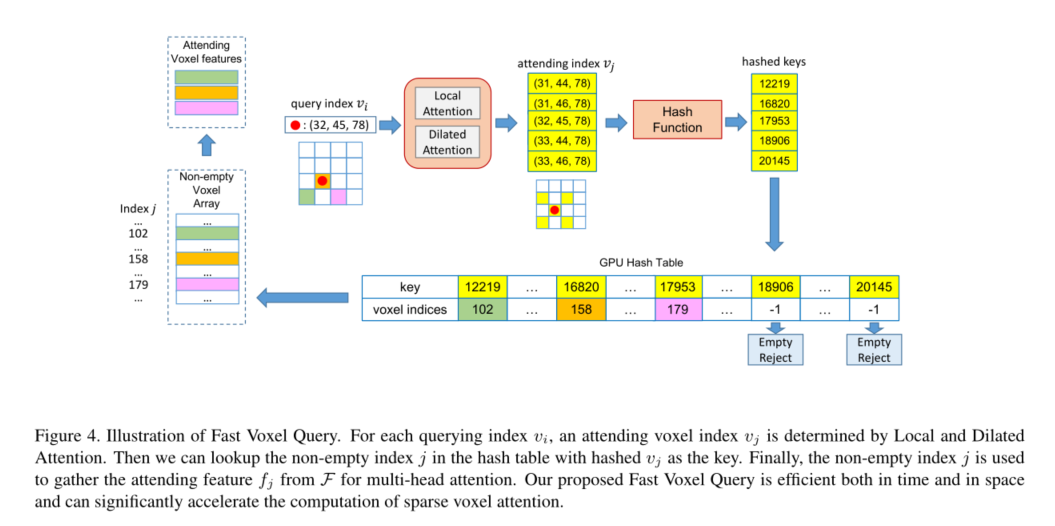
1)对于每个查询i,我们应用Local Attention和Dilated Attention来获得参与体素索引vj∈Ω(i)。
2)我们在哈希表中使用哈希键vj查找V的各个索引j,如果哈希值返回−1,则判断主播为空体素并拒绝
3) 我们在GPU上建立哈希表,将散列后的非空整数体素索引Vj存储为关键字,并将数组V的相应索引j存储为值。
4) 我们最终可以收集来自V和F的注意力体素索引Vj和特征fj,其中j用于体素自我注意。
花费时间为O(NΩ),NΩ是Ω中的体素数(i);
哈希表中使用线性探测来解决碰撞问题,使用原子操作来解决数据冲突
4、实验
4.1 数据集
Waymo Open 和 KITTI
4.2 比较模型:
1)使用Votr替换SECOND中的3D稀疏卷积形成一阶段的模型VoTr-SSD
2)使用Votr替换PV-RCNN中的3D稀疏卷积形成二阶段的模型VoTr-TSD
4.3 结果:
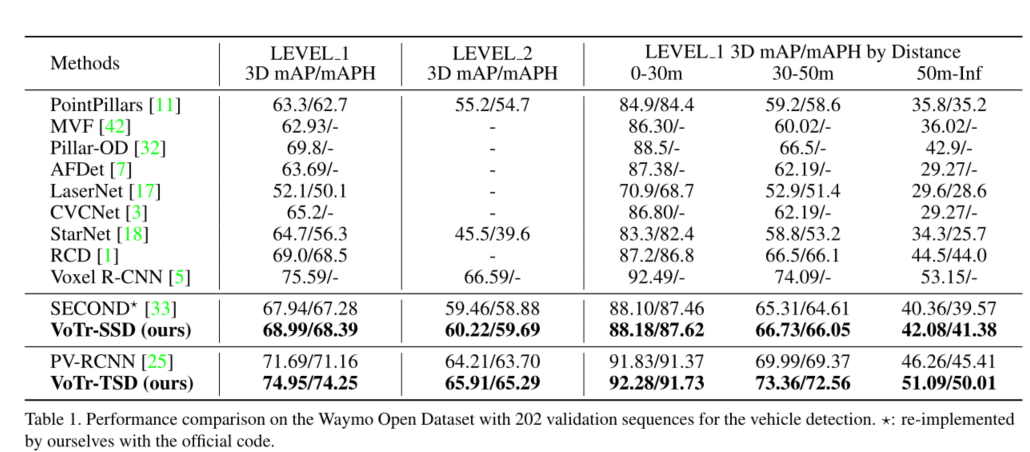
1、在Waymo Open上表现
一阶段,二阶段都有提升。原文中:在较远区域的显著性能提升表明了Votr获得的大量上下文信息对于3D目标检测的重要性。
2、在KITTI数据集上表现
可以看到在Easy的难度上相比于PV-RCNN来说是有下降的,其余的都有提升,原文总结说:在Kitti数据集上的观测结果与在Waymo Open数据集上的观测结果一致。

4.4 消融实验
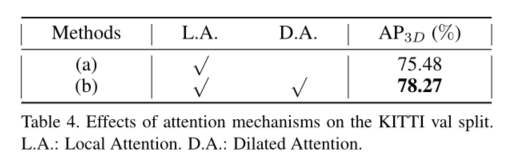
1、 Local and Dilated Attention
单独使用L,精度为75.48%;两个同时使用为78.27%
2、dropout in Voxel Transformer
随着丢弃的越多,精度逐渐在下降,这也就是作者为什么不适用drop layer的原因

3、空间复杂度 the number of attending voxels
相对于使用3D稀疏卷积层的网络,当使用我们的backbone后,参数数量都有所下降。

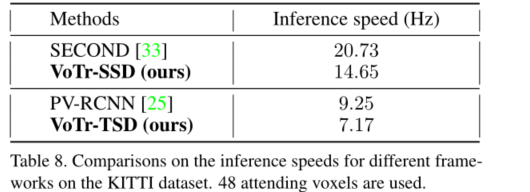
4、时间复杂度
使用3D卷积参数特别多,会造成计算时间也会特别多,所以当使用VoTr后,时间都会下降不少
5 、结论
我们介绍了Voxel Transformer,这是一个通用的基于Transformer的3D主干,可以应用于大多数基于体素的3D探测器。VoTr由一系列稀疏和子流形体素模块组成,通过特殊的注意机制和快速体素查询,可以有效地对稀疏体素执行自我注意。在未来的工作中,我们计划探索更多基Transformer的3D检测架构。
Original: https://blog.csdn.net/ko_gu_dao/article/details/124312518
Author: 莫~忆轩*
Title: VoTr:Voxel Transformer for 3D Object Detection 论文解读
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/681741/
转载文章受原作者版权保护。转载请注明原作者出处!