

文章目录
*
– faster rcnn 原理概括
– 特征提取层的特点和其与feature mpa坐标映射的关系
– RPN layer详解
– ROI pooling详解
– 分类层与第二次边框回归
faster rcnn 原理概括
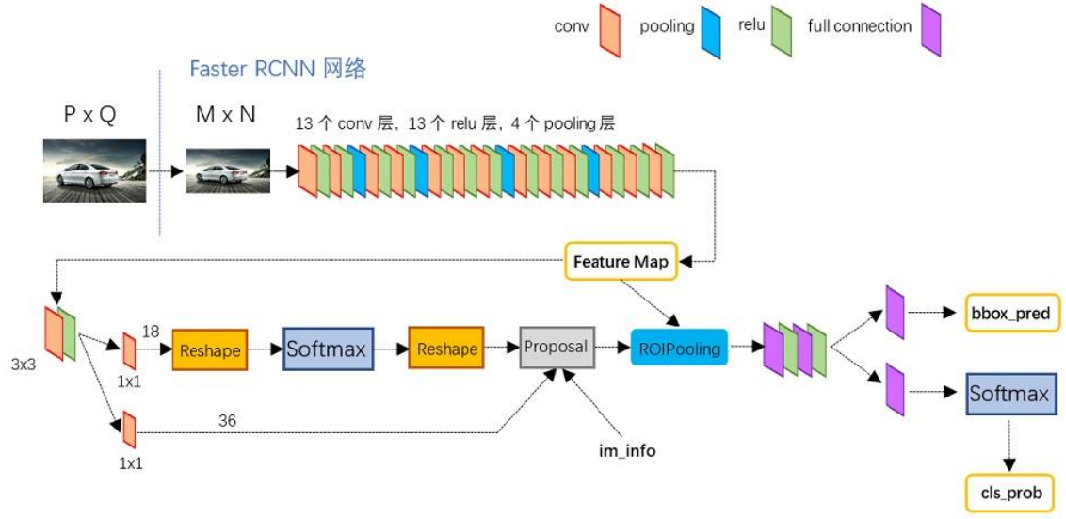

fater rcnn就是一个几个不同功能的小卷积结合起来的一个大卷积,后面的全连接层同样可以用卷积层来代替。
我们输入的图片首先会被放缩到MxN的大小,然后经过一个特征提取网络得到我们的feature map。然后根据feature map的尺寸来得到我们的anchors。
之后feature map会进入RPN layer,这一步的最终结果会帮我们提出有物体的框,并对这些框的位置和大小进行边框回归,这些被初选出来的框会进一步进行筛选得到进入ROI pooling的最终128个框,之后128个框会变成一样的大小,之后可以看作对128张图片进行的图像识别,最终会对这些框进行识别并且进行第二次的边框回归,第二次的边框会给它增加物体类别的特征。
下面我会用代码配合原理来讲解每一步是如何实现的
; 特征提取层的特点和其与feature mpa坐标映射的关系
题目里面包含的信息量我个人认为就已经很大了,因为很多人不会去注意这一点。在faster rcnn的论文中就已经提到,它自身提取特征的网络是VGG16,并且这个提取特征的网络可以是我们现在用的任何一种成熟的网络。在VGG16中,有13个卷基层,13个relu层,4个maxpooling层,其结构我会去分析为什么这么做,而不是为什么不那样做。
这13个卷基层都有一个特点,那就是其卷积本身并不改变特征图的尺寸,这样有一个好处,就是虽然每次经过一个卷积以后,虽然感受野扩大了,但是你会发现感受野的中心始终没变,换句话说,如果卷积不改变大小,每一个特征点映射回上面任意特征层的中心位置就是它自己所在的这个特征层的位置,并且始终不会改变
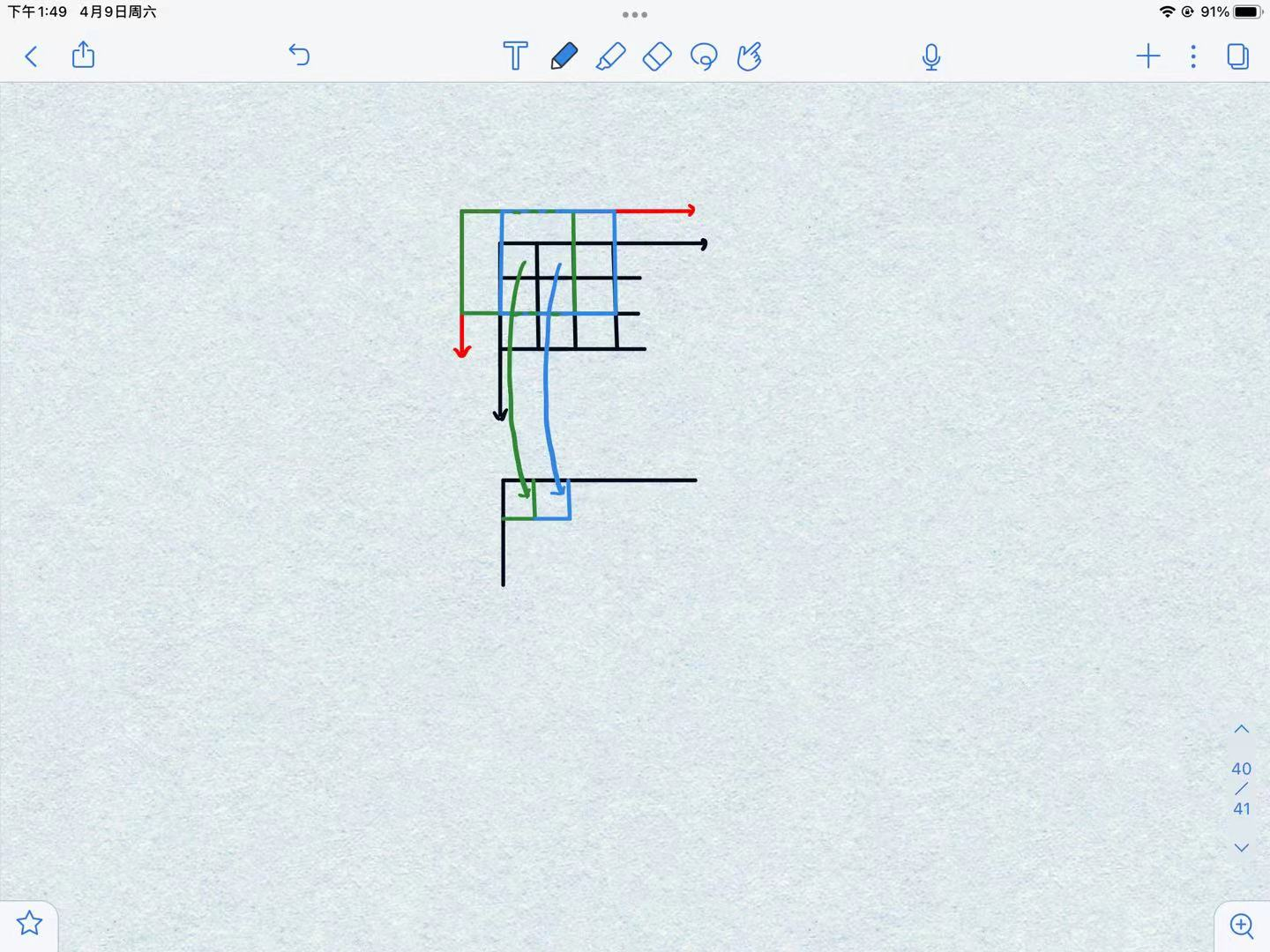
这是我自己画的示意图,黑框表示需要卷积的特征层,红框表示为了保证卷积大小不变增加的padding,可以看到,一个3×3的卷积卷右上角的时候,其中心点在原来特征图的坐标是(0.5,0.5),其卷积以后的结果也在(0.5,0.5)这个位置,往右边移动一个步长,第二个卷积(蓝色)的中心在(0.2,1.5),其卷积以后的结果也在(0.5,1.5),这就是我刚才说的,只要你保证你卷积大小不变,感受野肯定会变大,但是中心点坐标始终不变。
所以综上所述我们便会引申出来一个问题,从我们对于产生anchors的原理我们知道,对于坐标的映射,卷积不会起到任何作用,relu就更别说了,所以问题一定出在pool上,这个pool在VGG16里面,是采用了3×3,步长为2×2,但是呢,在tf里面pool层设置了一个padding=same,设置为same时候就代表,最后的输出和池化核的大小无关,只和步长有关,除以步长就是最后的大小,这也是为什么最大池化可以将尺寸减半的原因。那么它与池化核大小无关的原理是什么呢?我们以3×3的池化核为例,只需要在需要池化的卷积层的周围补一圈0就可以了。之后我们在研究映射关系的时候就方便多了
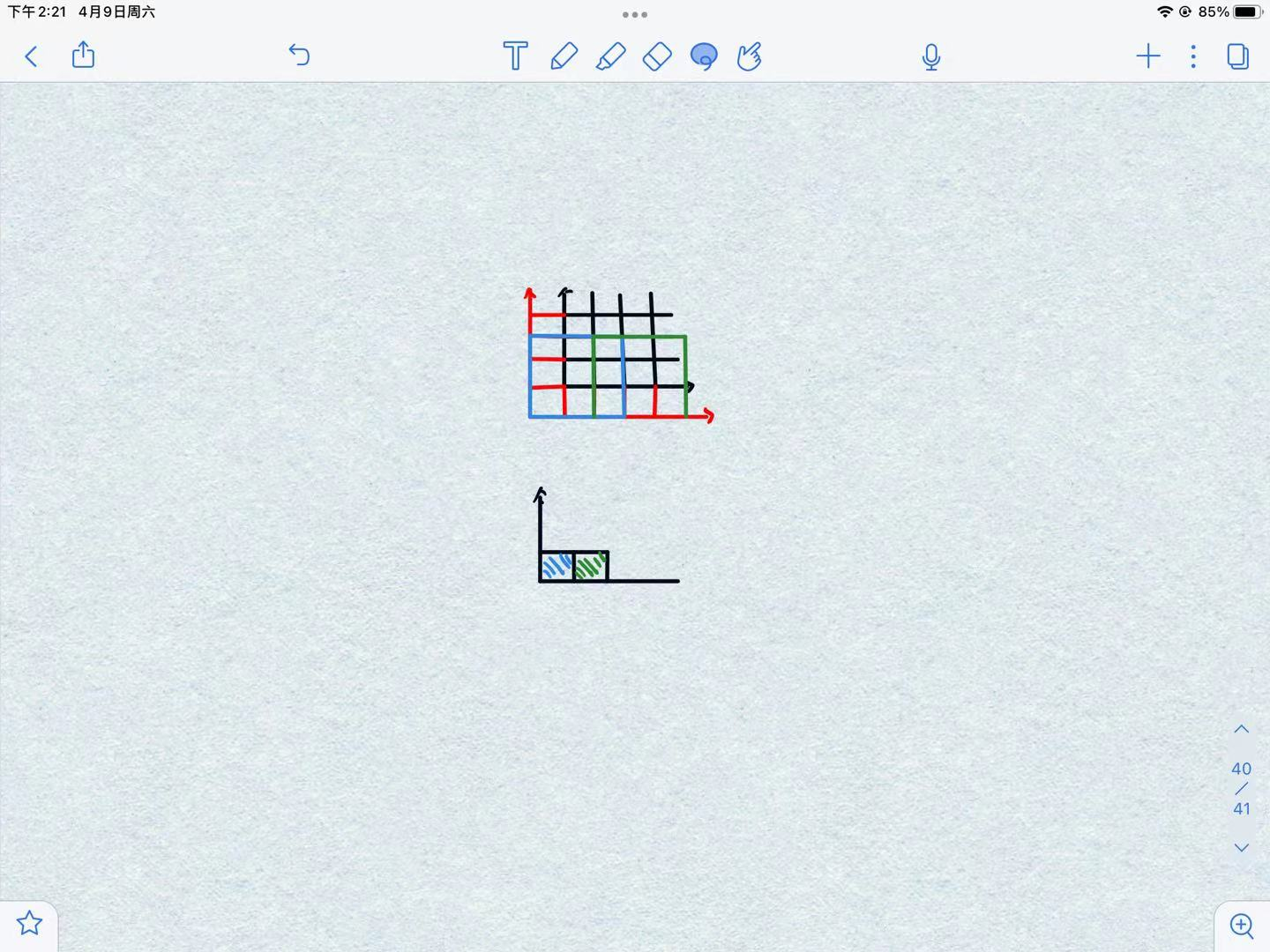
黑框是我们需要进行池化的特征层,红框是我们padding的一圈0,池化的大小是3×3,步长是2,第一个池化的步骤的结果是下面的蓝色虚线,之后往后右移了两个单位做第二个池化,结果是绿色虚线。之后我们便会发现,下面蓝色结果中,我们的中心点坐标是(0.5,0.5),乘上2,也就是我们缩小的倍数,刚好是(1,1),也就是我们坐池化的中心格子坐标。同样的,绿色结果的中心点坐标是(1.5,0.5),其对应的池化的中心的格子坐标也是(3,1)。但是这样举例可能有一个矛盾的地方,我们在卷积的时候明明是点对点的映射,发现没有改变,为什么到池化就成点对格子了呢?
其实卷积的时候我想要强调的是格子本身在特征图与上一层的特征图中的位置是不变的,你用格子对格子,点对点得出来的结论都是一样的。而对于池化,我们必须用点对格子的方法来进行映射,你可以理解为这是一个经验,也就是说只有点对格子才会符合我们的映射公式,那我们的映射公式是什么呢?(其实就是乘缩小的倍数)我们假设feature map的大小为50×50,那么,我们feature map上面随便找到一个特征点的坐标,比如第5行,第8个格子(5,8),然后找到这个格子的中线点坐标(5.5,8.5),然后乘16,就是(88,136),所以(5,8)映射回特征图的中心点坐标是(88,136),然后就可以形成anchors了。代码奉上。
shift_x = (np.arange(0, shape[0], dtype=keras.backend.floatx()) + 0.5) * stride
shift_y = (np.arange(0, shape[1], dtype=keras.backend.floatx()) + 0.5) * stride
stride就是16,加的那个0.5就是找格子的中心点坐标
RPN layer详解
在说明之前我阐明一下我上面没提到的准备工作,就是ahchors的产生原理,其实就是feature map上面的每一个特征点映射回原图以后中心格子,以这个格子为中心,做一组三个宽高比,三种面积,一共9个anchor。我们以后的举例都用特征图为50×50来说明。如此一来,我们得到的所有anchors一共有22500个(50x50x9),我们的RPN层其实就是在对22500个anchors进行筛选
再来说明一下RNP网络的作用,这个作用不是它的功能作用,而是训练作用,我们会在RPN阶段产生两个误差,既然有误差,就一定会有标签,而两个误差对应的标签是我们根据目标框的位置自己算出来的,所以我会重点放在标签的设置上面。
首先我们会对feature map进行一个3×3的卷积,对于这个3×3的卷积的解释可谓是众说纷纭,有说可以改善鲁棒性的,我在这里给出我的一个解释,那就是这个3×3的卷积可以提高迁移性,也就是说我们允许前面的VGG16网络使用的权重是已经训练好的权重,在迁移到另一个网络以后我们就只需要训练这个3×3卷积就可以得到一个符合自己要求的特征层了。当然,这个3×3卷积的存在不影响我们解释RPN的原理。
在经过3×3卷积以后,我们会兵分两路,上路的作用是判断这个anchor内是否有物体
下路的作用是对anchor进行边框回归。我们逐一说明
首先是上路:其会首先经过1×1的卷积来改变通道数为18,准确来说是9×2,也就是50x50x(9×2),9×2表示每一个特征格产生的9个anchor内是否有物体,用一个二分类来表示。这里我要说明的是,对于判断是否有物体,我们并没有对所有的22500框进行判断,而是从中选取了8940框,这8940个框具备什么特点呢?那就是他们是完完整整都在原图尺寸范围内的,也就是说在兵分两路之前,我们会对22500个框进行判断,看看他们是否超出了原图的范围,然后把未超出范围的框全部拿出来,就是这8940个。那剩下的框我们会单独为他们这是标签。
我们会先对8940个框分别对所有的目标框所在的位置(我们假设只有两个目标框)做iou处理,并且规定iou大于0.7,被视作这个框内存在物体,给其标签定为1。小于0.3的,认为其内没有物体,标签设定为0。二者之间的,标签设为-1。这里还有一个小问题,就是万一没有0.7的怎么办,那就找到两个目标框最大的那些anchor,标签单独设置为1,其他操作不变,这种情况很少发生。
如此一来(以下数据均为假设),8940个anchors里面有200个anchor的标签被视为1。5000个标签被设为0,其余被设置为-1。可以看到正负样本之间差别太大,训练的时候会使得效果权重偏向负样本。故我们需要缩小这里面的比例,我们会从所有的正样本中随机抽取128个正样本,这128个正样本的标签保持不变,其余的正样本标签设置为-1,如果不够128个,那就不动正样本的标签。然后从5000个负样本中抽取(256-标签为1的个数)个负样本,也就是说负样本加正样本一共256个,同样的道路,我们从5000个里面随机抽要求的个数的负样本,保持其标签为0不变,其余的全部改成-1。这样以后我们的在8940里面的标签分布就是a个标签为1,b个标签为0,8940-256个标签为-1。那么,有没有一种可能,那就是正样本太多了,我们只取了128个,然后另外的128个从负样本里面去,但是负样本又太少了,凑不齐258个,那这样我们的总数就达不到256了。答,是有这种可能的,所以对于训练集的图片,目标框一定不能太多,还有就是设置合理的阈值来归类最初的正负样本。
那8940个anchors以外的anchors的标签呢?同样,全部设置为-1就可以了。
代码奉上,注释都是我自己作为一个初学者写的,有什么不对的欢迎指正。
def get_pos_neg_sample(ious,valid_anchor_len,
pos_iou_threshold=0.7,
neg_iou_threshold=0.3,
pos_ratio=0.5,
n_sample=256):
argmax_ious=ious.argmax(axis=1)
max_ious=ious[np.arange(valid_anchor_len),argmax_ious]
label=np.empty((valid_anchor_len,),dtype=np.int32)
label.fill(-1)
label[max_ious<neg_iou_threshold]=0
label[max_ious>pos_iou_threshold]=1
gt_argmax_ious=ious.argmax(axis=0)
get_max_ious=ious[gt_argmax_ious,np.arange(ious.shape[1])]
gt_argmax_ious_new=np.where(ious==get_max_ious)[0]
label[gt_argmax_ious_new]=1
n_pos=pos_ratio*n_sample
pos_index=np.where(label==1)[0]
if len(pos_index)>n_pos:
disable_index_pos=np.random.choice(pos_index,size=(len(pos_index)-n_pos),replace=False)
label[disable_index_pos]=-1
n_neg=n_sample-np.sum(label==1)
neg_index=np.where(label==0)[0]
if len(neg_index)>n_neg:
disable_index_neg=np.random.choice(neg_index,size=(len(neg_index)-n_neg),replace=False)
label[disable_index_neg]=-1
return label,argmax_ious
然后是下路:下路同样经过一个1×1的卷积来改变通道数为36,最后shape为(b,50,50,36),同样,36也可以写成(9×4),表示的是22500中的每一个anchor的四个回归系数,分别影响着xy和wh四个参数。
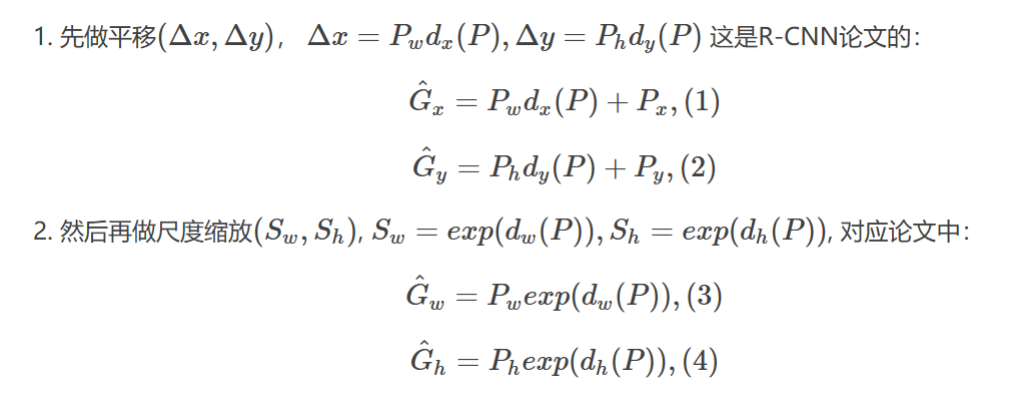
我们知道回归的系数其实是上面的dx,dy,dw和dh。Px是anchor的中心x,Pw是anchor的宽,Gx小尖尖是我们经过回归后的新的anchor所在的中心x的坐标。所以这里实际需要做一个转化,因为我们不知道dx是标签是多少,但是我们知道Gx小尖尖的标签是多少,就是它附近的那个目标框的中心x。所以这里设置标签,只需要用Gx小尖尖的标签,带入公式就可以推的dx的标签应该是多少,这样就可以用dx的标签和预测出来的dx进行反向传播了。
bbbox=bbox[argmax_ious]
def get_coefficient(anchor,bbox):
height=anchor[:,2]-anchor[:,0]
width=anchor[:,3]-anchor[:,1]
ctr_y=anchor[:,0]+0.5*height
ctr_x=anchor[:,1]+0.5*width
base_height=bbox[:,2]-bbox[:,0]
base_width=bbox[:,3]-bbox[:,1]
base_ctr_y=bbox[:,0]+0.5*base_height
base_ctr_x=bbox[:,1]+0.5*base_width
eps=np.finfo(height.dtype).eps
height=np.maximum(height,eps)
width=np.maximum(width,eps)
dy=(base_ctr_y-ctr_y)/height
dx=(base_ctr_x-ctr_x)/width
dh=np.log(base_height/height)
dw=np.log(base_width/width)
gt_roi_locs=np.vstack((dy,dx,dh,dw)).transpose()
return gt_roi_locs
同理,8940个anchor以外的框的标签全部设置为0就可以了,因为你把0带进公式里面以后,前后的Gx小尖尖和Px完全一样,就代表不需要改变超出边界的框的大小和位置。
这里提出一些我个人的观点,就是为什么判断是否有物体我们的标签是3类,0,-1,1,因为我们会在计算损失的时候把标签为-1的省略。而边框回归的时候标签需要都设置为0,而好像是只有两类,为什么不设置和前者一样,超出边界的anchor就不训练了呢?那是因为超出边界的anchor的标签真的不好设置,因为你取的值很有可能和需要训练的ahchor的标签是一样的,如果单方面忽略某个标签容易对正在训练的产生影响,因为目前而言,暂时没有找到说8940个anchor的边框回归系数很少取到或者说取不到某个值,这个暂时我没看到谁研究过,如果存在,那么我认为完全可以仿照前者,超过边界的anchor的标签设置为那个取不到的数,继而不训练回归系数,这样速度可以大幅提升,因为0本身也是一种训练标签,你相当于在告诉系统,超出边界的框一定要保持不变,你都用不着这些框,为什么还要对它们有要求呢?这一点也是可以改进的地方。
还有一个有争论的点在于,我们相当于在上路的时候找到了128个正样本,128个负样本(理想情况)。我为什么不只对正样本进行边框回归,而不光回归了负样本的边框,甚至还回归了众多标签为-1的框,这不是在浪费资源吗?
我给出的解释是,我们只会计算正样本的损失并回归,并不会管其他的anchor回归,计算归计算,但是不会影响其他未参与损失计算的anchors。
我们在计算RPN阶段的损失的时候,正负样本标签采用的是交叉熵函数,边框回归采用的是smooth L1损失函数。
这里需要说明一点的就是正负样本的标签,我们之前规定了128个正样本的标签为1。128个负样本的标签为0(理想情况),可是咱们给的判断是否存在的位置明明是”2″。这个就和tf中的交叉熵函数有关了,它会自己把一个数的标签转化成one hot形式然后,也就是0转为[1,0],1转为[0,1]。
之后我们还需要把这个预测的标签的第二列拿出来,你会发现,随着训练的进行,标签为1的anchor第二列会不断趋于1,而标签为0的会趋于0,也就是说第二列可以作为是否有物体的一个得分来给我们提供信息以备后面使用。
ROI pooling详解
ROI pooling实际就是对我们选取的一众anchor进行统一大小,那我们选取的anchor是哪些呢?最直接的不就是我们在256个样本里面的128个正样本吗?有可能不够128个正样本呢?那我们就选取这256个样本,负样本的标签我们不计算不就好了。好像说得通,但是实际并不是这么操作的。这里我会先说网络里面是如何操作的,再说说我的想法。
网络里面选择优先级的顺序不是看这个anchors是否被判别是正样本,而是看这个anchor是否存在物体的得分,也就是我们上面所说的第二列,也被称作置信度。它选取的范围是所有的22500个anchors,也就说在网络并未训练成熟之前,它选取的框很有可能是负样本。我们先放下争议继续说下面的步骤。
其会选择22500里面前12000个得分最多的anchor,然后把这些anchor进行nms处理,也就是非极大值抑制,得到最多2000个,但是我自身网络只输出了1758个。也就说网络认为这1758个anchor是”相隔甚远”的,之后会把这1758个anchor与两个目标框计算iou,我设定阈值为0.5,超过0.5的视作正样本,低于0.5的视作负样本。然后故技重施,从正样本里面抽取32个,从负样本里面抽取96个,一共抽128个。如果正样本不够,就多抽一点负样本的,总数为128即可。所以,最后进入ROI pooling的框就是这128个,最后进行图像识别的也是这128个。
现在提出我的观点,那就是为什么非要放弃我们已经寻找到的基本可以确实里面有物体的框(那128个正样本),而要自己根据分数来重新选择呢?甚至可以说在训练初期,那些分高还可能是负样本,这样岂不是白白给自己找事干,直接从我们已经确定是正样本的框里面进行pooling再识别岂不是更快,白送给你的正样本你不要,你要去自己再根据分数来自己选。那么我的观点是否有可行性呢?我认为是有的,因为在RPN阶段我们选择的正样本的框,这是实实在在有物体的,也就说我们标签给它打成1,它基本就确定肯定有物体,那么唯一麻烦的地方就是,我们打上正样本的框的分布,大概率是比较密集的,因为它们会分布在目标框的周围,但是我们依然可以用nms的方法过滤掉分低的框,从而再去识别分最高的那个anchor。
现在给出我对网络如此做的看法——防止过拟合。
我为什么会给出这种解释呢?因为这是很明显地把物体种类的判别与判断是否有物体捆绑在一起了,因为二者的误差是被联系起来了。熟悉YOLOV3的人应该知道,我们最后进行边框筛选的时候设置的分数,它是是否存在物体的置信度与该框内80个物种各自概率的乘积。也就是二者必须都不低,这样的框才能被留下。换句话说,是存在confidence低,而识别物种时概率高的情况的。故其把是否存在物体与这个物体的识别联系起来是有据可循的。另一个原因,我举一个例子,如果一个anchor是负样本,但是一开始它的分很高,被选进了128个框中,然而由于它是负样本,所以只可能在计算iou的时候被放进负样本,物体识别标签被置为0(背景),pooling之后要被用来识别背景0。换句话说,在训练其分数的时候,一个是RPN阶段训练其要尽可能的低,另外它还会受到训练物体识别时候的影响,换句话说,这个负样本本身不太好收敛,这既是缺点,也是优点。一个样本越不容易收敛,其过拟合的可能性就越小(这是我自己的理解,如果有错,欢迎指正)。
如果按照我自己的想法,那么判断是否有物体与这个框中物体识别这两个步骤是分开的话,确实缺少了二者的联系,但是我觉得可以仿照YOLOV3的筛选过程,将二者结合起来一起做一遍框的过滤也可以解决这个问题。
最后对我们选取的128个anchor,映射回特征图上面(直接除以16就可以了),再进行ROI pooling就可以了,结果128anchor会变的一样的大小。
我在这里稍微解释一下为什么原图的区域除以16就是特征图的上面的区域。
在特征图的(1,1)位置上,它投影到原图上面的区域是(0,0),(0,16),(16,16),(16,0)四个点围起来。,故其从原图返回特征图的投影的区域,就是各个坐标值除以16,刚好就是(1,1)这个特征格四个顶角的坐标。
def get_propose_target(new_roi,bbox,
labels,
n_sample=128,
pos_ratio=0.25,
pos_iou_thresh=0.5,
neg_iou_thresh_hi=0.5,
neg_iou_thresh_lo=0.0):
ious=compute_iou(new_roi,bbox)
near_bbox_index=ious.argmax(axis=1)
near_bbox_iou=ious.max(axis=1)
near_label=labels[near_bbox_index]
pos_index=np.where(near_bbox_iou>=pos_iou_thresh)[0]
pos_aim_num=n_sample*pos_ratio
pos_num=int(min(pos_aim_num,pos_index.size))
if pos_index.size>32:
pos_index=np.random.choice(pos_index,size=pos_aim_num,replace=False)
neg_index=np.where((near_bbox_iou<neg_iou_thresh_hi)&(near_bbox_iou>=neg_iou_thresh_lo))[0]
neg_aim_num=n_sample-pos_num
neg_num=int(min(neg_aim_num,neg_index.size))
if neg_index.size >neg_num:
neg_index=np.random.choice(neg_index,size=neg_num,replace=False)
keep_index=np.append(pos_index,neg_index)
roi_labels=near_label[keep_index]
roi_labels[pos_num:]=0
sample_roi=new_roi[keep_index]
return sample_roi,keep_index,near_bbox_index,roi_labels
分类层与第二次边框回归
摆在首位的就是分类层的标签是什么。
要解决这个问题,就必须弄明白,参与分类的框由什么组成,答:里面有物体的正样本的框和里面没有物体的负样本的框。由此我们如下规定,正样本的框由于包含两种正样本(两个目标框内的物体种类不一样的话),我们看看这些框与哪个目标框的iou更大,就匹配上这个目标框的种类标签。然后负样本的框标签全部置为0,(相当于我们自己创造了一个物体:背景,标签是0),这个标签0也要参与运算,并不是说它是背景就不训练了,如果不训练标签为0的anchor,相当于不只是有物体时候才使其confidence训练为,还需要没有物体,也就是背景的时候训练为confidence为0也要被考虑。(这个背景0和confidence为0是两回事,我只是想强调创建这俩的联系的必要性)。
然后是第二次边框回归的标签,这里只会对正样本里面的anchor进行第二次边框回归,因为没有必要对背景框的大小进行回归的必要,他们的标签自然也是自己iou最大的那个目标框的xyhw。但是这里要说明一下,最后全连接层输出的shape是(128,21,4),但是在正样本有32个前提下,不应该是(32,4)吗。为什么维度还一样呢?因为文章开头我们就说过,第二次边框回归是把物体特征也融入进去了,也就是这个anchor的标签是哪个号码,我就从中间那个21中拿出对应号码的一组4个回归系数,如果你有32个正样本,我就拿出来你对应的32个正样本所对应标签的那4组(32,4),刚刚好。也就说训练出来的128个anchor,其对每一个种类都设置了它们自己的4个回归系数(别忘了还有背景的那个1)。为什么背景的那个1明明不会进行回归,还要加进20里面呢?理由就是背景的标签是0,你在进行元素提取的时候为了保证标签的数字与下标一致,这个0不能省略,举个例子,如果不加标签为0的背景,那如果我需要提取标签为1的4组回归系数的时候,我使用的下标是却是0.当然你不嫌烦的话可以在调用的时候自己加一个1,毕竟最后回归的时候只会反向传播正样本的误差,背景的回归系数存不存在无所谓。
def rio_loss(pre_loc,pre_conf,target_locs,target_conf,weight=10.0):
target_conf=torch.autograd.Variable(target_conf.long())
pred_conf_loss=torch.nn.functional.cross_entropy(pre_conf,target_conf)
pred_conf_loss=np.squeeze(pred_conf_loss.data.numpy())
pos=target_conf.data>0
mask=pos.unsqueeze(1).expand_as(pre_loc)
mask_pred_loc=pre_loc[mask].view(-1,4)
mask_target_loc=target_locs[mask].view(-1,4)
x = np.abs(mask_target_loc.numpy() - mask_pred_loc.data.numpy())
pre_loc_loss = ((x < 1) * 0.5 * x ** 2) + ((x >= 1) * (x - 0.5))
num_reg=(target_conf>0).float().sum()
num_reg=np.squeeze(num_reg.numpy())
pre_loc_loss=pre_loc_loss.sum()/num_reg
pre_loc_loss=np.float32(pre_loc_loss)
total_loss=pred_conf_loss+(weight*pre_loc_loss)
return total_loss
最后我想补充一点的就是,我们一共产生了22500个anchor,但是真正用到的好像并没有这么多。在第一次判别是否存在物体的时候,我们只用了8940个框,其余的框根本没有参与训练,甚至8940个anchor里面也有不参与训练的框(当然这里不影响,因为迟早会训练到他们,8940以外的anchor就没那么幸运了)在第一次边框回归的时候,我们把8940框进行了正常的边框回归,先找他们离哪个目标框最近,然后用这个目标框的xyhw来制作正常的标签,8940以外的anchor的回归便签全部置为0.
在提取最后的128个anchos时候,我们是按照分数的,这个时候22500个anchors是平等对待的,但是我们是根据它的得分来取的,8940以外的anchor根本不会去训练分数,换句话说他们被取到的概率完全是随机的。也就说虽然候选的是一共22500个anchor,但是8940以外的anchor能够作为参考的价值就代码而言是不大的,但是也有可能它的分很高,而且iou也高,最后被训练出类别以及边框回归。故而对于第二次边框回归,其只会回归正样本,而正样本是由其iou决定的,所以它也是有可能被训练到的。综上所述,我觉得对于8940以外的anchor的分数不参与训练是及其不恰当的。
!!代码是知乎一位大神编写的,我也只是做了一个注释的工作,并且加入了我自己的想法,如果哪里理解失误了,欢迎批评指正。
Original: https://blog.csdn.net/weixin_44586881/article/details/124059238
Author: 做梦还会想
Title: faster rcnn 代码与原理结合详解
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/681733/
转载文章受原作者版权保护。转载请注明原作者出处!