

Spring为什么可以解决 set + singleton模式下循环依赖?
根本的原因在于:这种方式可以做到将” 实例化Bean“和给”” Bean属性赋值“这两个动作分开去完成。
实例化Bean的时候:调用无参数构造方法来完成。此 时 可 以 先 不 给 属 性 赋 值 , 可 以 提 前 将 该 B e a n 对 象 ” 曝 光 ” 给 外 界 。 \color{red}此时可以先不给属性赋值,可以提前将该Bean对象”曝光”给外界。此时可以先不给属性赋值,可以提前将该B e a n 对象”曝光”给外界。
给Bean属性赋值的时候:调用setter方法来完成。
两 个 步 骤 是 完 全 可 以 分 离 开 去 完 成 的 , 并 且 这 两 步 不 要 求 在 同 一 个 时 间 点 上 完 成 。 \color{red}两个步骤是完全可以分离开去完成的,并且这两步不要求在同一个时间点上完成。两个步骤是完全可以分离开去完成的,并且这两步不要求在同一个时间点上完成。
针对
<bean id="a" class="com.cjf.bean.A">
<property name="b" ref="b"/>
bean>
<bean id="b" class="com.cjf.bean.B">
<property name="a" ref="a"/>
bean>
1、实例化/初始化
实例化
- 内存中申请一块存储空间
初始化属性填充
- 完成属性的各种赋值
2、3个Map&4大方法
DefaultSingletonBeanRegistry类有三个重要的缓存
一级缓存
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
一级缓存存储的是: 完整的Bean对象,也就是说这个缓存中的 Bean对象的属性都已经复制了。只一个完整的Bean对象
二级缓存
private final Map<String, Object> earlySingletonObjects = new ConcurrentHashMap<>(16);
二级缓存存储的是:早期的单例 Bean对象,这个缓存中的单例 Bean对象的属性 没有赋值,只是一个早期的单例对象
三级缓存
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
- 三级缓存存储的是:
- 单例工厂对象,这个里面存储了大量的工厂对象,每一个单例Bean对象都会对应一个单例工厂对象。
- 这个集合中存储的是:
- 创建该单例对象时对应的哪个对应的那个
单例工厂的对象(在这里存放的是bean的lambda的工厂)
AbstractAutowireCapableBeanFactory类的
doCreateBean(2),创建beanpopulateBean(3),给实例化后的bean进行属性赋值
DefaultSingletonBeanRegistry类的
getSingleton(1),主要一个是创建bean对象,创建完最后走(4)。(还有一个是从缓存中获取Bean对象)addSingleton(4),加入到一级缓存,并删除二/三级缓存的中Bean
3、A/B对象在三级缓存中的迁移说明
这里过程最好记住(有助于理解源码)
- 先去一级缓存寻找
A,没有去创建A, 然后A将自己放到三级缓存中,初始化的时候需要B,去创建B B实例化同理A(B放入到了 三级缓存),B初始化的时候发现需要A,于是B先查一级缓存,没有,再查二级缓存,还是没有,再查三级缓存,找到了A然后把三级中的A放入二级缓存里面,并删除三级缓存中的AB顺利初始化完毕,将自己放到一级缓存里面(此时B里面的A依然是创建中的状态),再删除三级缓存中的B和 尝试去删除二级缓存中的B(此时二级缓存中只有A)- 然后回来接着创建
A,此时B已经创建结束,直接从一级缓存里面拿到B,然后完成A创建,再从 二级缓存中获取A对象, 并将A自己放入到一级缓存里面,再删除三级缓存中的A和 删除二级缓存中的A
4、源码分析-1
以下一句话
- 先去一级缓存寻找
A,没有去创建A, 然后A将自己放到三级缓存中,初始化的时候需要B,去创建B
我们直接进入 debug进入 AbstractBeanFactory工厂的 doGetBean方法。
我们发现会首先从 getSingleton(beanName) 方法中先去尝试获取共享的实例化对象。
进入该方法,首先会去从 一级缓存中获取该 bean 对象,此时为 bean 对象空并且该 bean 对象没有在创建中(就是实例化完成的对象,没有被赋值),直接结束方法,直接返回一个 null 对象
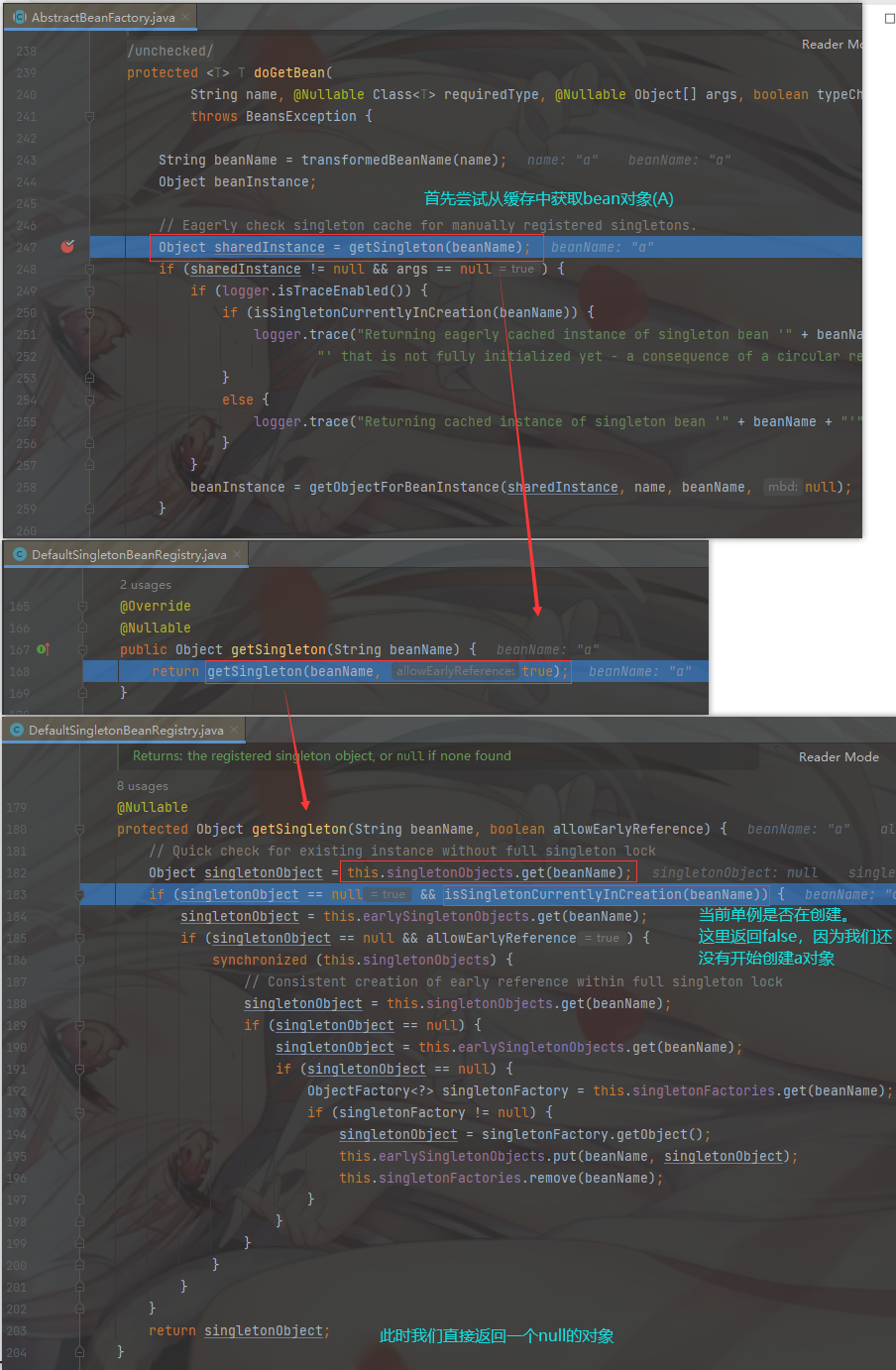

- 我们可以进入
isSingletonCurrentlyInCreation(String beanName)方法,可以看出这是从一个set集合中获取是否这个在创建中的对象,这里这个set里面存放的是是刚刚实例化完成的对象,还没有初始化的bean对象的名称
*
private final Set<String> singletonsCurrentlyInCreation =
Collections.newSetFromMap(new ConcurrentHashMap<>(16));
public boolean isSingletonCurrentlyInCreation(String beanName) {
return this.singletonsCurrentlyInCreation.contains(beanName);
}
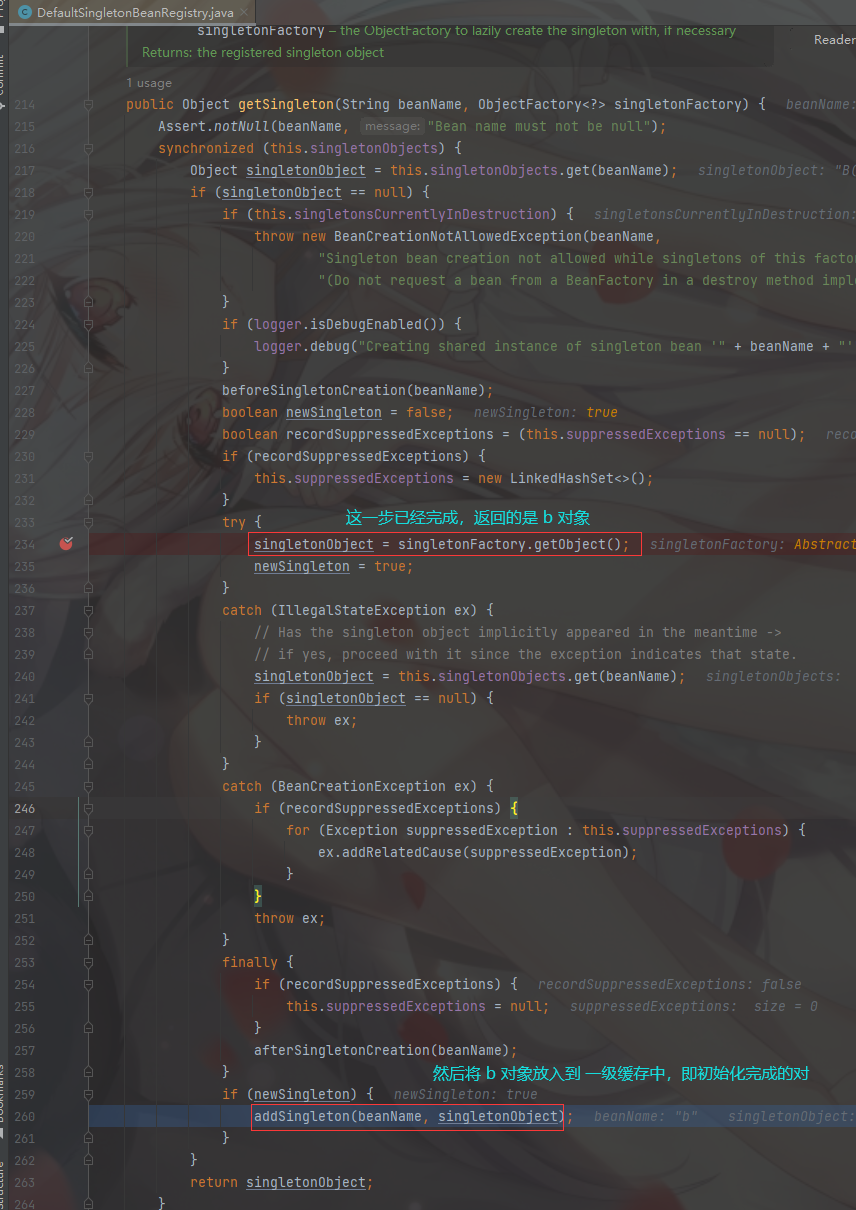
然后我们直接走到 doCreateBean 方法中的 324行获取单例对象的方法 getSingleton(....) ,返回一个实例化的 Bean对象
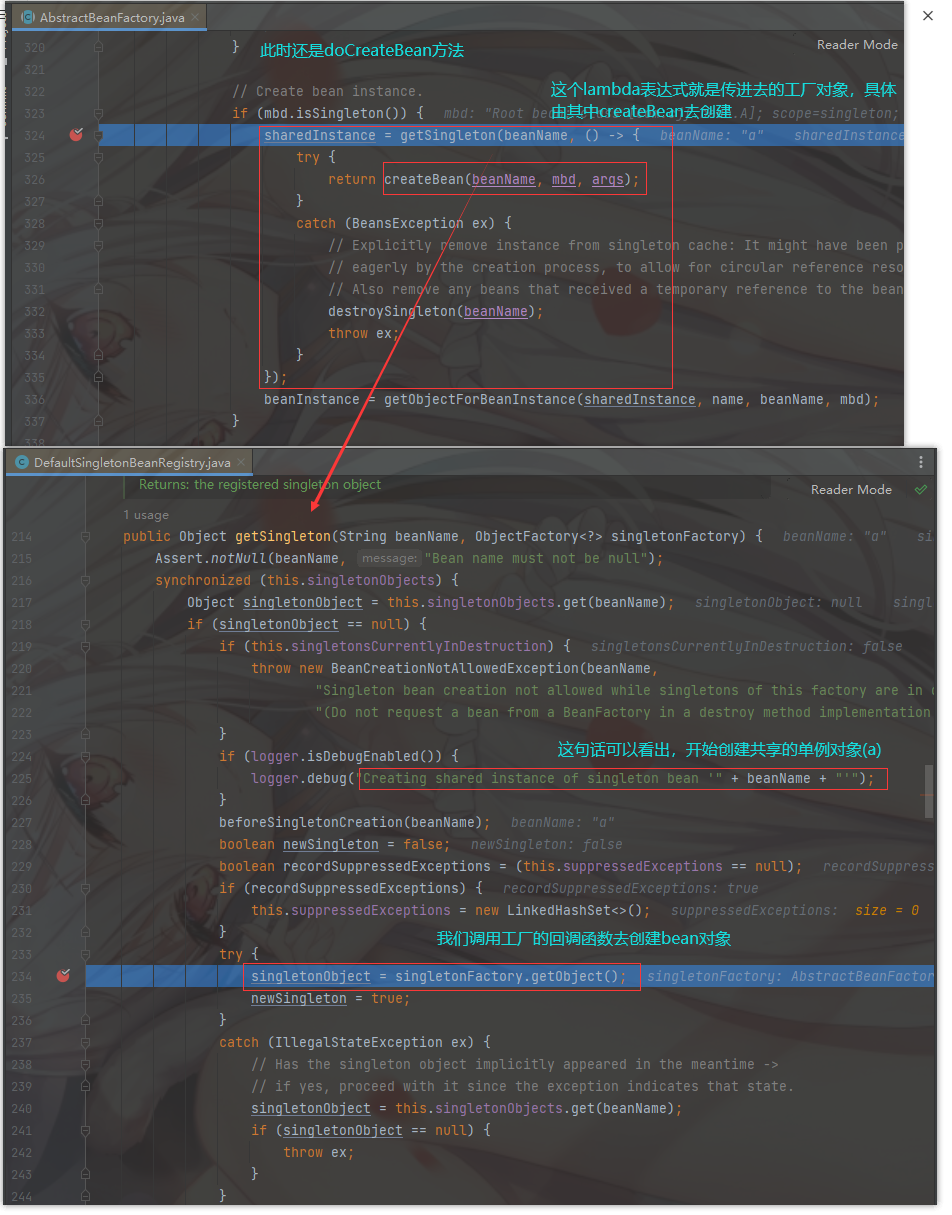
此时真正的开始创建 Bean对象,
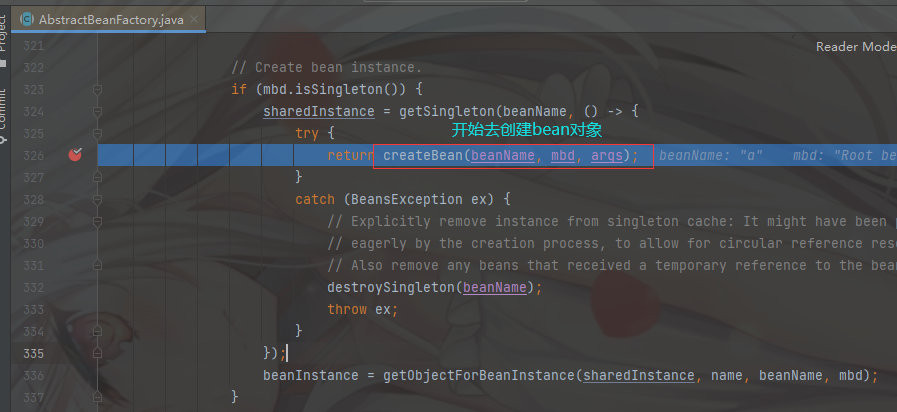
进入 createBean 方法
其中重点是
try {
Object beanInstance = doCreateBean(beanName, mbdToUse, args);
if (logger.isTraceEnabled()) {
logger.trace("Finished creating instance of bean '" + beanName + "'"); }
return beanInstance;
}
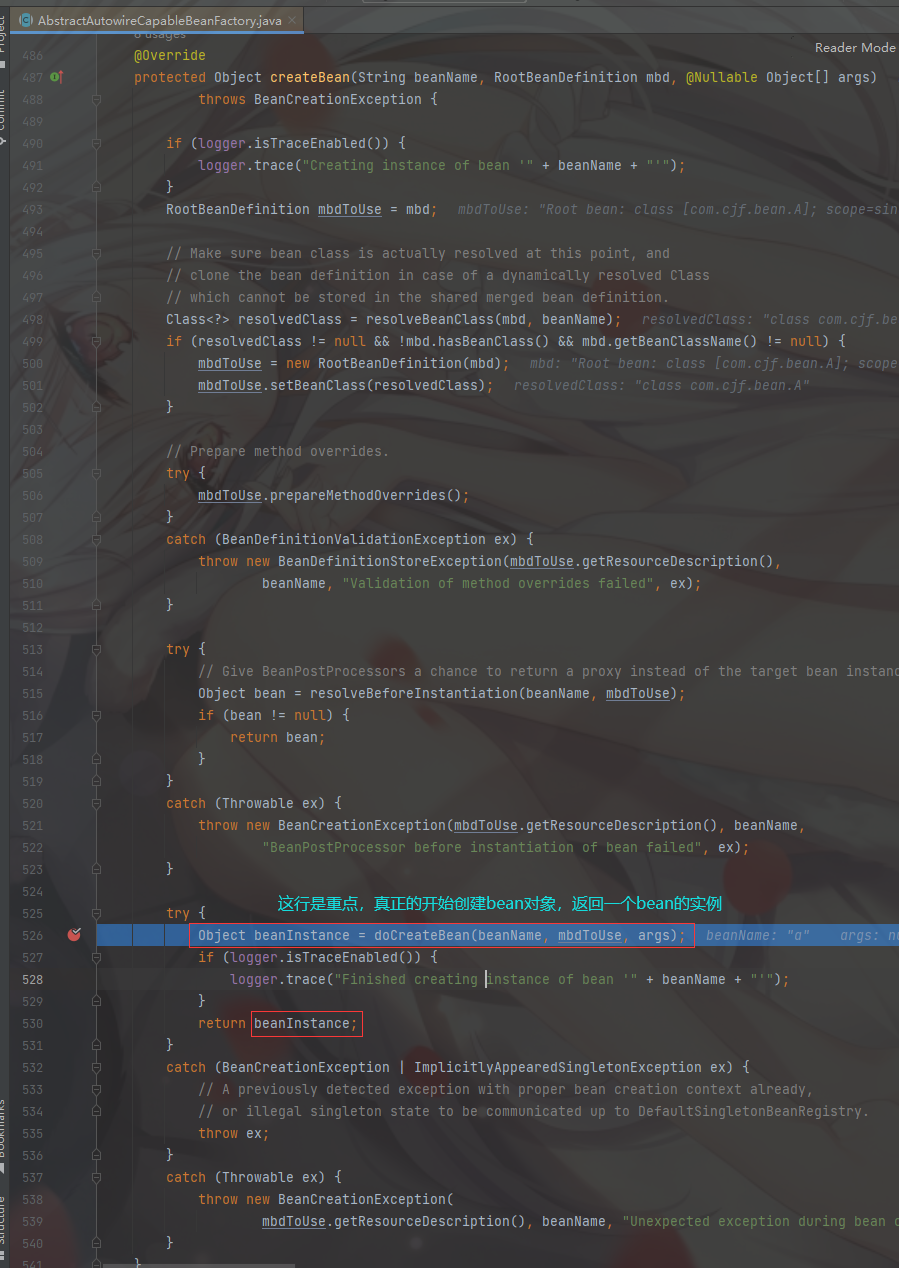
进入 AbstractAutowireCapableBeanFactory的 doCreateBean 方法,我们可以发现这里正是 bean 对象的 生命周期前 7步执行的方法。关于生命周期的讲解可以看7.6、bean的周期10步源码解析
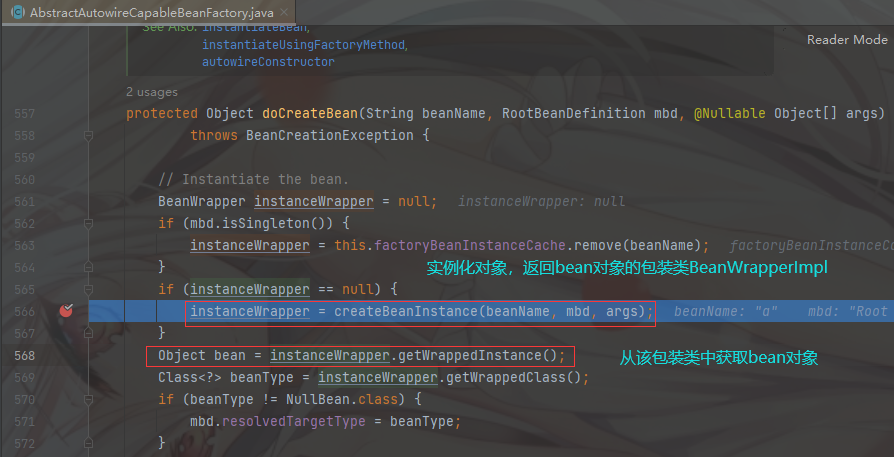
关于bean的实例化可以去看Spring源码:bean创建(三):createBeanInstance_
这里我们是通过缺省构造器来获得bean对象的
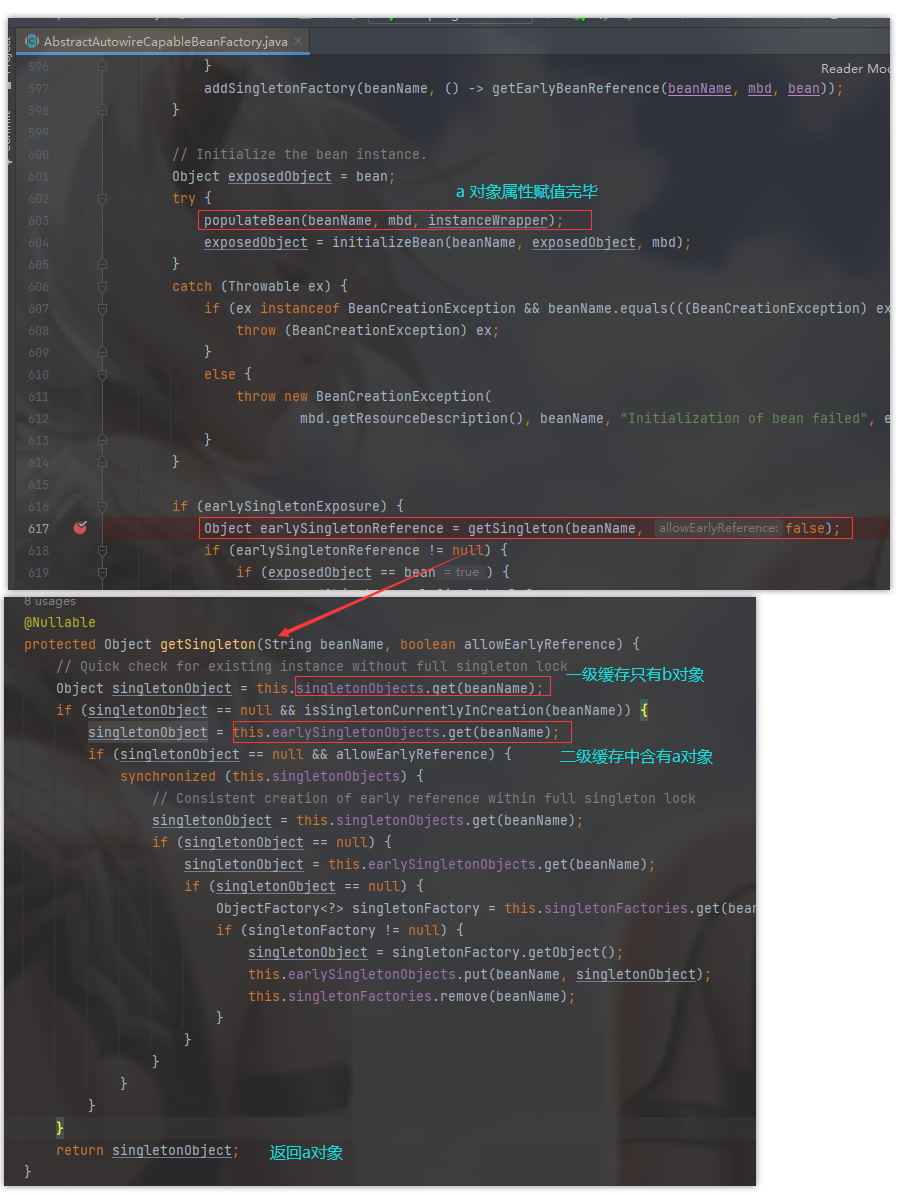
将返回的 bean对象( a),通过 addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean)); 方法放入到 三级缓存 中。
(这里三级缓存存放的是 k :a,v :lambda(一个单例工厂))
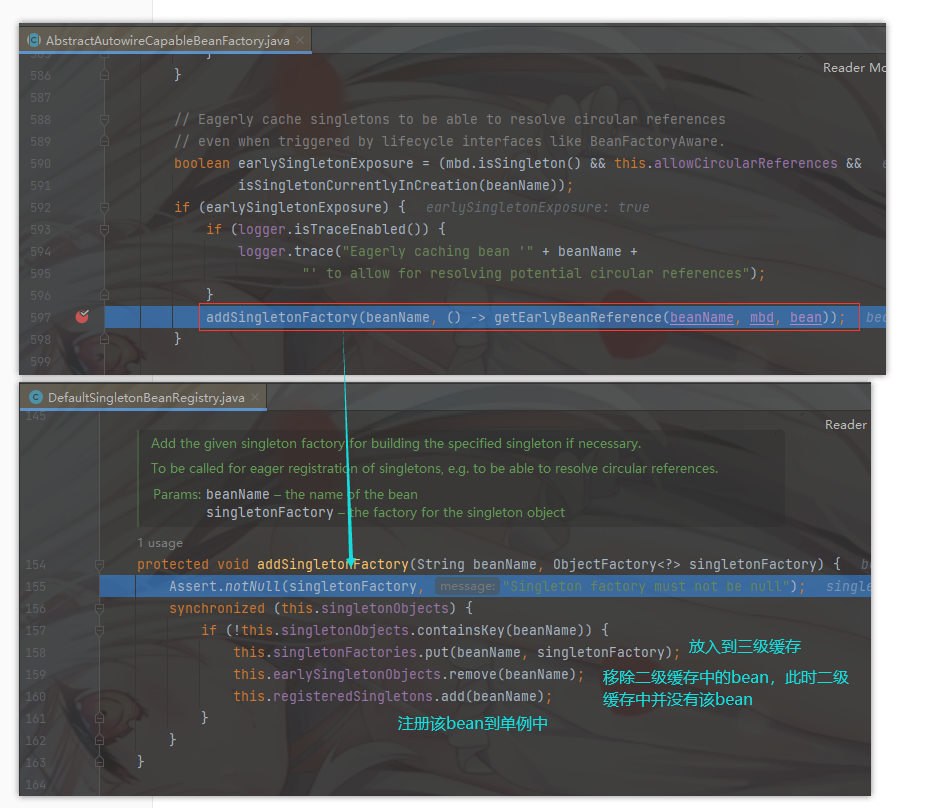
然后对 bean对象( a)进入属性赋值对于如何赋值的可以看 Spring源码:bean创建(四)属性注入
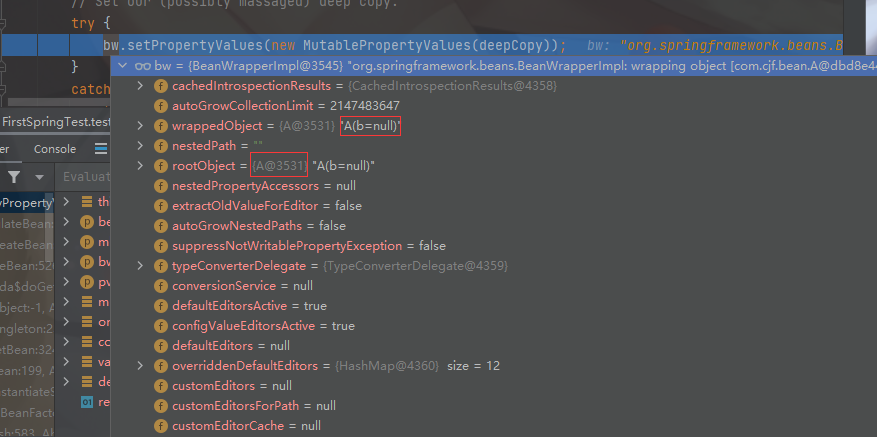
此时我们已经将 a 对象放入到了三级缓存中,然后进入 doCreateBean 方法 populateBean(beanName, mbd, instanceWrapper); 对 bean 对象进入赋值
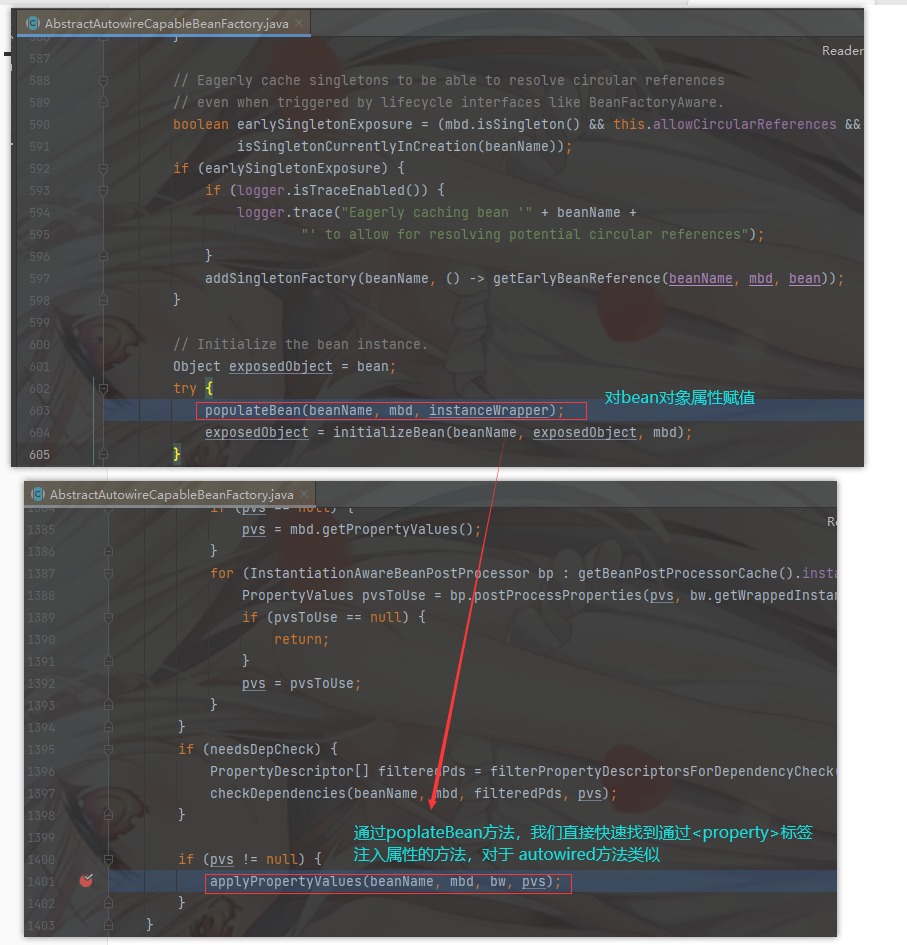
进入 applyPropertyValues 方法
protected void applyPropertyValues(String beanName, BeanDefinition mbd, BeanWrapper bw, PropertyValues pvs) {
BeanDefinitionValueResolver valueResolver = new BeanDefinitionValueResolver(this, beanName, mbd, converter);
List<PropertyValue> deepCopy = new ArrayList<PropertyValue>(original.size());
boolean resolveNecessary = false;
for (PropertyValue pv : original) {
if (pv.isConverted()) {
deepCopy.add(pv);
}
else {
String propertyName = pv.getName();
Object originalValue = pv.getValue();
Object resolvedValue = valueResolver.resolveValueIfNecessary(pv, originalValue);
Object convertedValue = resolvedValue;
boolean convertible = bw.isWritableProperty(propertyName)
&&!PropertyAccessorUtils.isNestedOrIndexedProperty(propertyName);
if (convertible) {
convertedValue = convertForProperty(resolvedValue, propertyName, bw, converter);
}
if (resolvedValue == originalValue) {
if (convertible) {
pv.setConvertedValue(convertedValue);
}
deepCopy.add(pv);
}
try {
bw.setPropertyValues(new MutablePropertyValues(deepCopy));
}
catch (BeansException ex) {
throw new BeanCreationException(
mbd.getResourceDescription(), beanName, "Error setting property values", ex);
}
}
我们重点进入 valueResolver.resolveValueIfNecessary(pv, originalValue); 方法
Object resolvedValue = valueResolver.resolveValueIfNecessary(pv, originalValue);
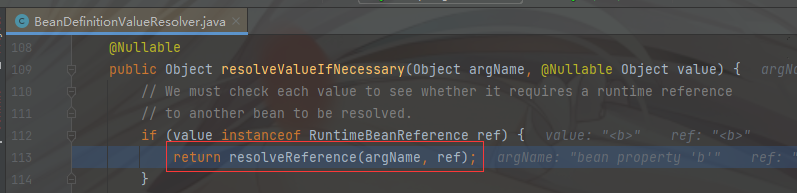
直接进入 resolveReference(argName, ref);
重点 bean = this.beanFactory.getBean(resolvedName); 返回一个 bean对象,
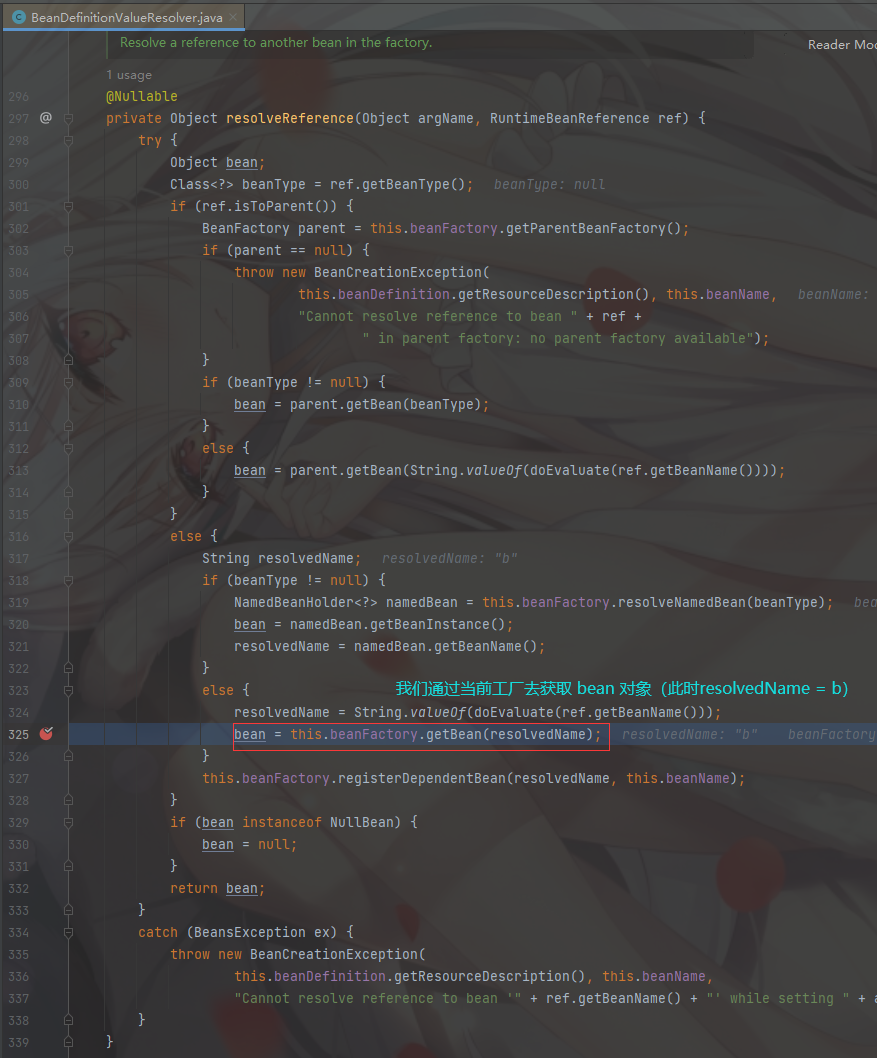
直接进入 bean = this.beanFactory.getBean(resolvedName); 方法
我们发现又回到了 doGetBean 方法,更 A 对象一样的去获取 B 对象
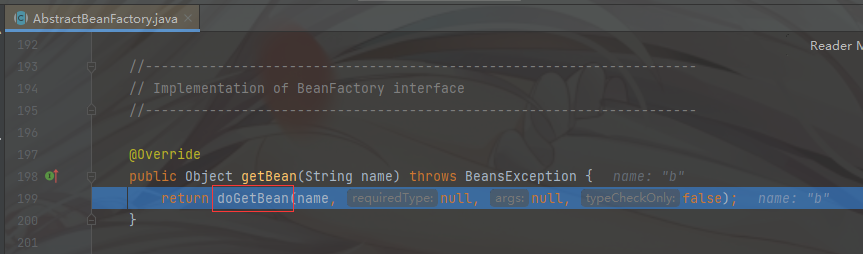
一句话
- 先去一级缓存寻找
A,没有去创建A, 然后A将自己放到三级缓存中,初始化的时候需要B,去创建B
5、源码分析-2
以下一句话
B实例化同理A(实例化后,B放入到了 三级缓存),B初始化的时候发现需要A,于是B先查一级缓存,没有,再查二级缓存,还是没有,再查三级缓存,找到了A然后把三级中的A放入二级缓存里面,并删除三级缓存中的A
我们跳到对 b 对象的赋值操作,去获取 b 对象的属性 a 对象
Object resolvedValue = valueResolver.resolveValueIfNecessary(pv, originalValue);
在进入 BeanDefinitionValueResolver 的 resolveReference(argName, ref);
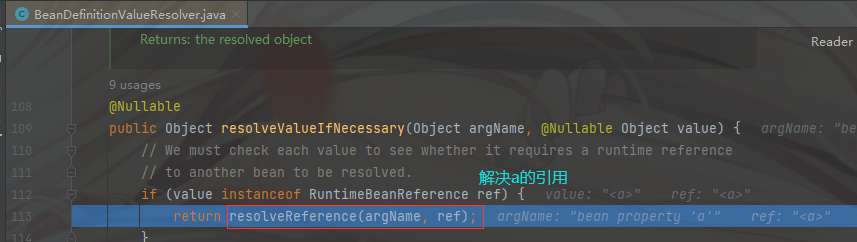
同理的 进入 resolveReference 方法去获取 a 对象
@Nullable
private Object resolveReference(Object argName, RuntimeBeanReference ref) {
bean = this.beanFactory.getBean(resolvedName);
}
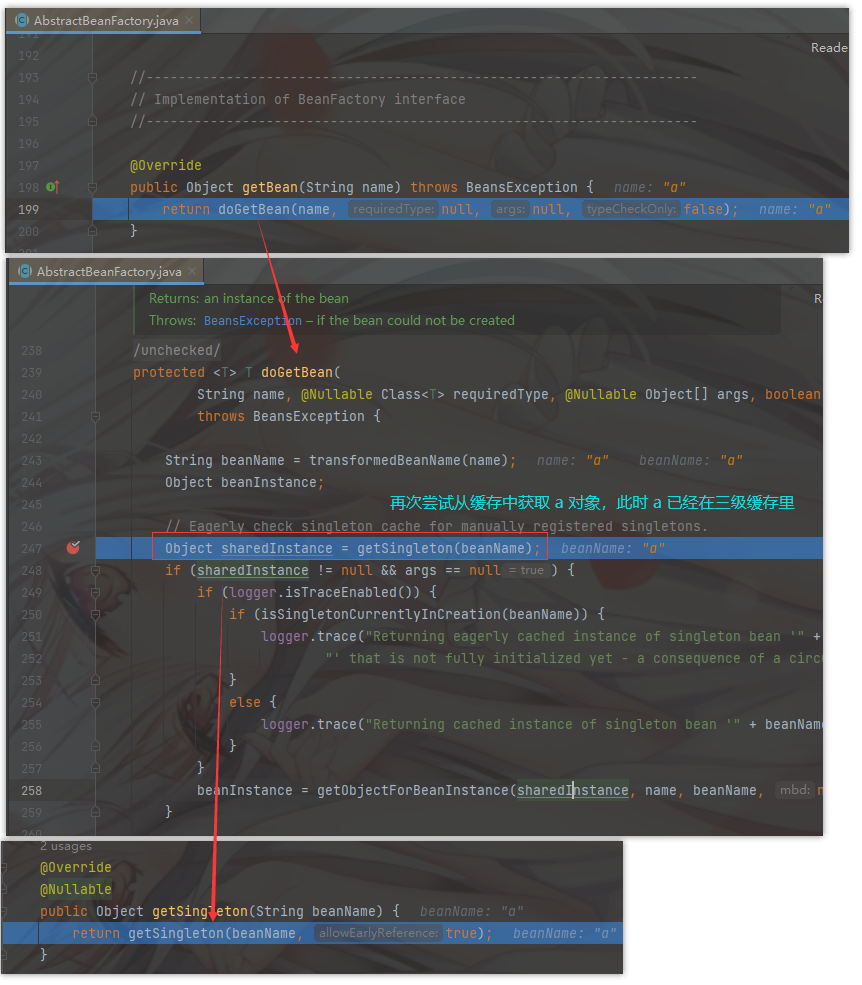
我们此时到了 getSingleton(String beanName, boolean allowEarlyReference) 方法中。
我们获取 A 对象,先查一级缓存,没有,再查二级缓存,还是没有,再查三级缓存,找到了 A 然后把三级中的 A 放入二级缓存里面,并删除三级缓存中的 A
@Nullable
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
synchronized (this.singletonObjects) {
singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null) {
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
singletonObject = singletonFactory.getObject();
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
}
}
return singletonObject;
}
6、源码分析-3
以下一句话
B顺利初始化完毕,将自己放到一级缓存里面(此时B里面的A依然是创建中的状态),再删除三级缓存中的B和 尝试去删除二级缓存中的B(此时二级缓存中只有A)
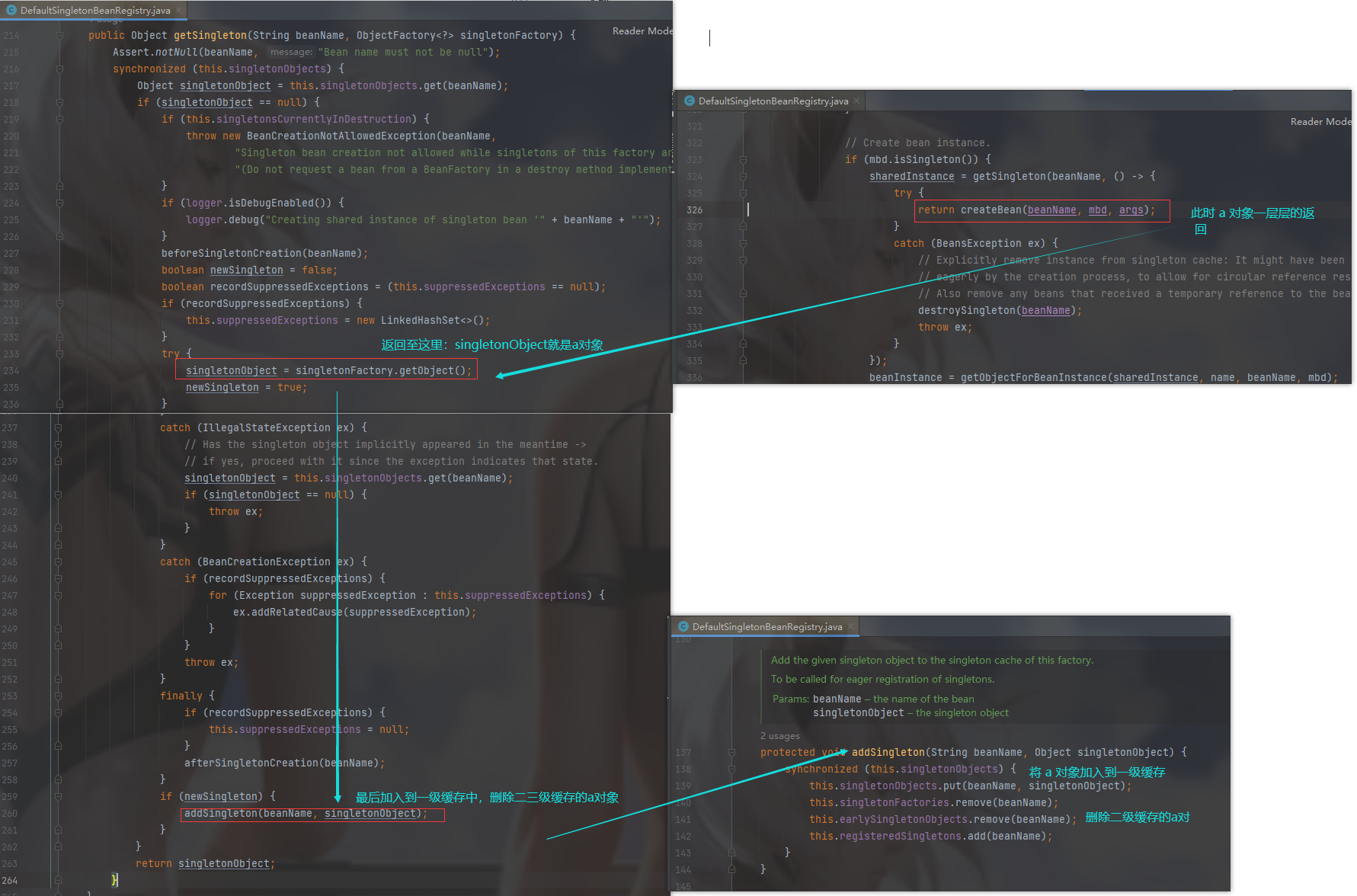
从以上获取到 bean 对象后( a) ,一层一层的返回,
此时 Object resolvedValue = a 对象,将 a 对象赋值给 b 对象的 a 属性
try {
bw.setPropertyValues(new MutablePropertyValues(deepCopy));
}
我们发现 b 的包装类 BeanWrapper 中含有了 a 对象
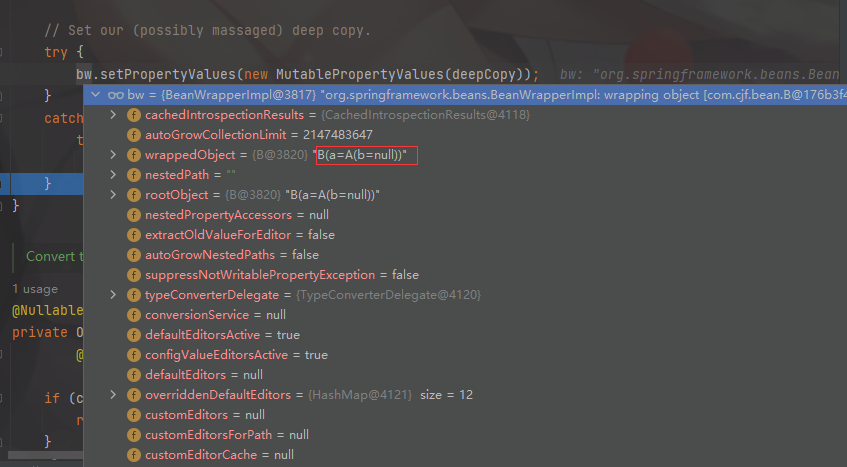
此时 b 完成了对属性的赋值
protected Object doCreateBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args) {
populateBean(beanName, mbd, instanceWrapper);
exposedObject = initializeBean(beanName, exposedObject, mbd);
return exposedObject;
}
不断的返回到
singletonObject = singletonFactory.getObject();
protected void addSingleton(String beanName, Object singletonObject) {
synchronized (this.singletonObjects) {
this.singletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}
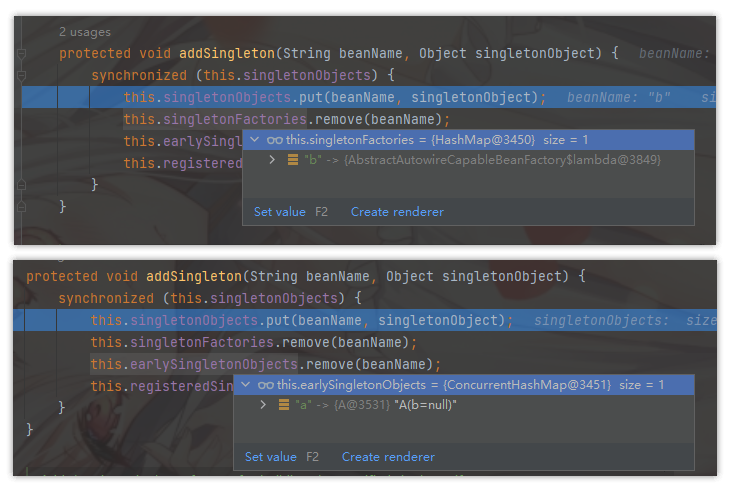
此时 B 顺利初始化完毕,将自己放到一级缓存里面(此时 B 里面的 A 依然是创建中的状态),再删除三级缓存中的 B 和 尝试去删除二级缓存中的 B (此时二级缓存中只有 A )
7、源码分析-4
以下一句话
- 然后回来接着创建
A,此时B已经创建结束,直接从一级缓存里面拿到B,然后 完成创建, 并将A自己放入到一级缓存里面
从以上不断的返回至
Object resolvedValue = valueResolver.resolveValueIfNecessary(pv, originalValue);
给 a 对象属性的 b 属性赋值为 resolvedValue
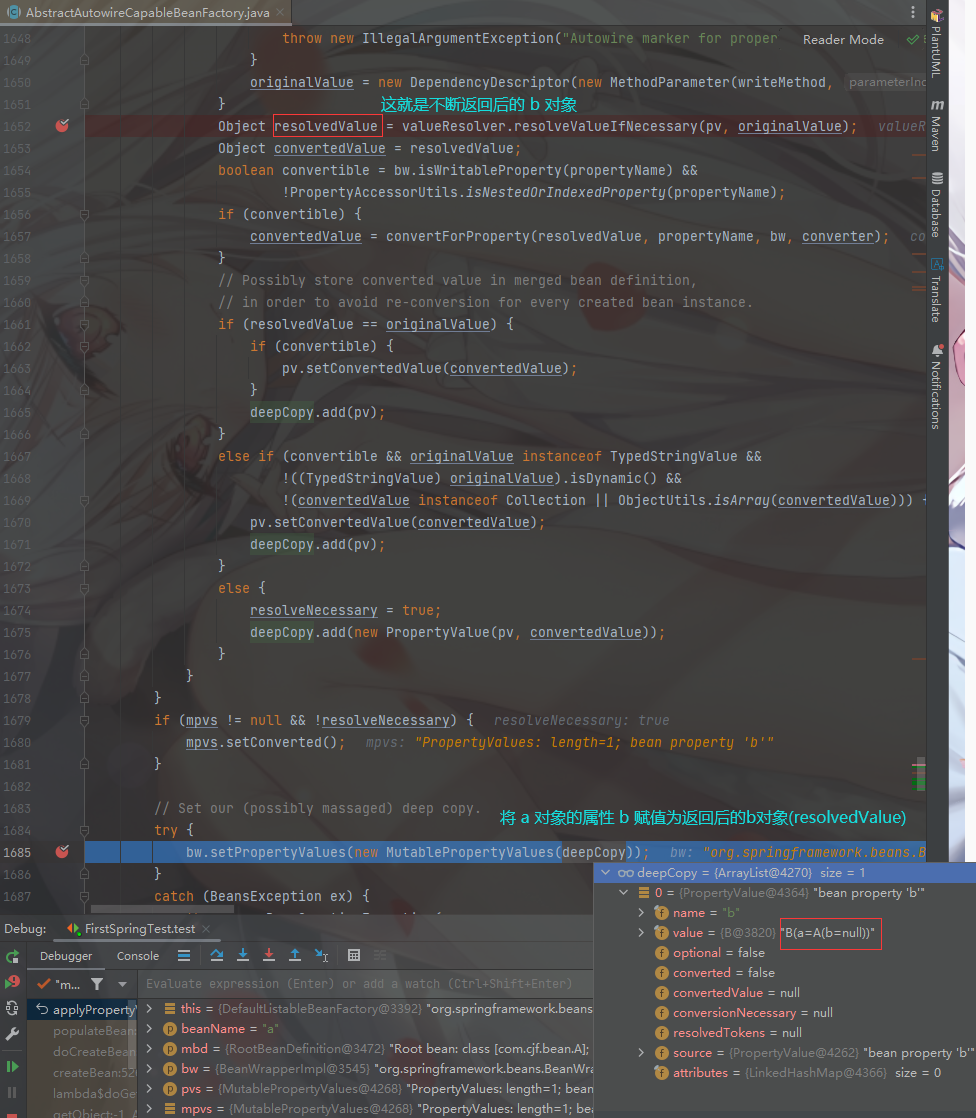
其中 的 BeanWrapperImpl 就是 a 的包装类
a 对象注入属性完毕之后,然后去从缓存中获取 a 对象,此时 a 对象直接从二级缓存中获取
此时将返回的 a 对象放入到一级缓存中,删除三级缓存中的 a (此时三级缓存中没有 a),删除二级缓存中的 a。
最后完成了 a b 对象的依赖( 最后全部放入到了一级缓存)
8、小总结
通过源码分析,其实单纯的循环依赖二/一级缓存也可以解决(只不过一级会覆盖中间态),但是用三级缓存有其他的作用(主要为了解决 aop增强的问题,所以三级缓存的 Value是 objectFactory)。
Spring创建bean主要分为两个步骤,创建原始bean对象,接着去填充对象属性和初始化- 每次创建
bean之前,我们都会从缓存中查下有没有该bean,因为是单例,只能有一个 - 当我们创建
beanA的原始对象后,并把它放到三级缓存中,接下来就该填充对象属性了,这时候发现依赖了beanB,接着就又去创建beanB,同样的流程,创建完beanB填充属性时又发现它依赖了beanA又是同样的流程, - 不 同 的 是 \color{red}不同的是不同的是
- 这时候可以在三级缓存中查到刚放进去的原始对象
beanA,所以不需要继续创建,用它注入beanB,完成beanB的创建 -
既然
beanB创建好了,所以beanA就可以完成填充属性的步骤了,接着执行剩下的逻辑,闭环完成 -
Spring解决循环依赖依靠的是Bean的”中 间 态 \color{red}中间态中间态”这个概念, - 而这个中间态指的是已 经 实 例 化 但 还 没 初 始 化 的 状 态 − > 半 成 品 \color{red}已经实例化但还没初始化的状态 ->半成品已经实例化但还没初始化的状态−>半成品。
实例化的过程又是通过构造器创建的,如果 A还没创建好出来怎么可能提前曝光,所以构造器的循环依赖无法解决。
Spring为了解决单例的循环依赖问题,使用了三级级存。
- 其中一级缓存为单例池(
singletonObjects) - 二级缓存为提前曝光对象(
earlySingletonObjects) - 三级缓存为提前曝光对象工厂(
singletonFactories) 。
假设 A、 B循环引用,实例化 A的时候就将其放入三级缓存中,接着填充属性的时候,发现依赖了 B,同样的流程也是实例化后放入三级缓存接着去填充属性时又发现自己依赖 A,这时候从缓存中查找到早期暴露的 A,没有 AOP代理的话,直接将 A的原始对象注入 B,完成 B的初始化后,进行属性填充和初始化,这时候 B完成后,就去完成剩下的 A的步骤,如果有 AOP代理,就进行 AOP处理获取代理后的对象 A,注入 B,走剩下的流程。
9、分析流程图
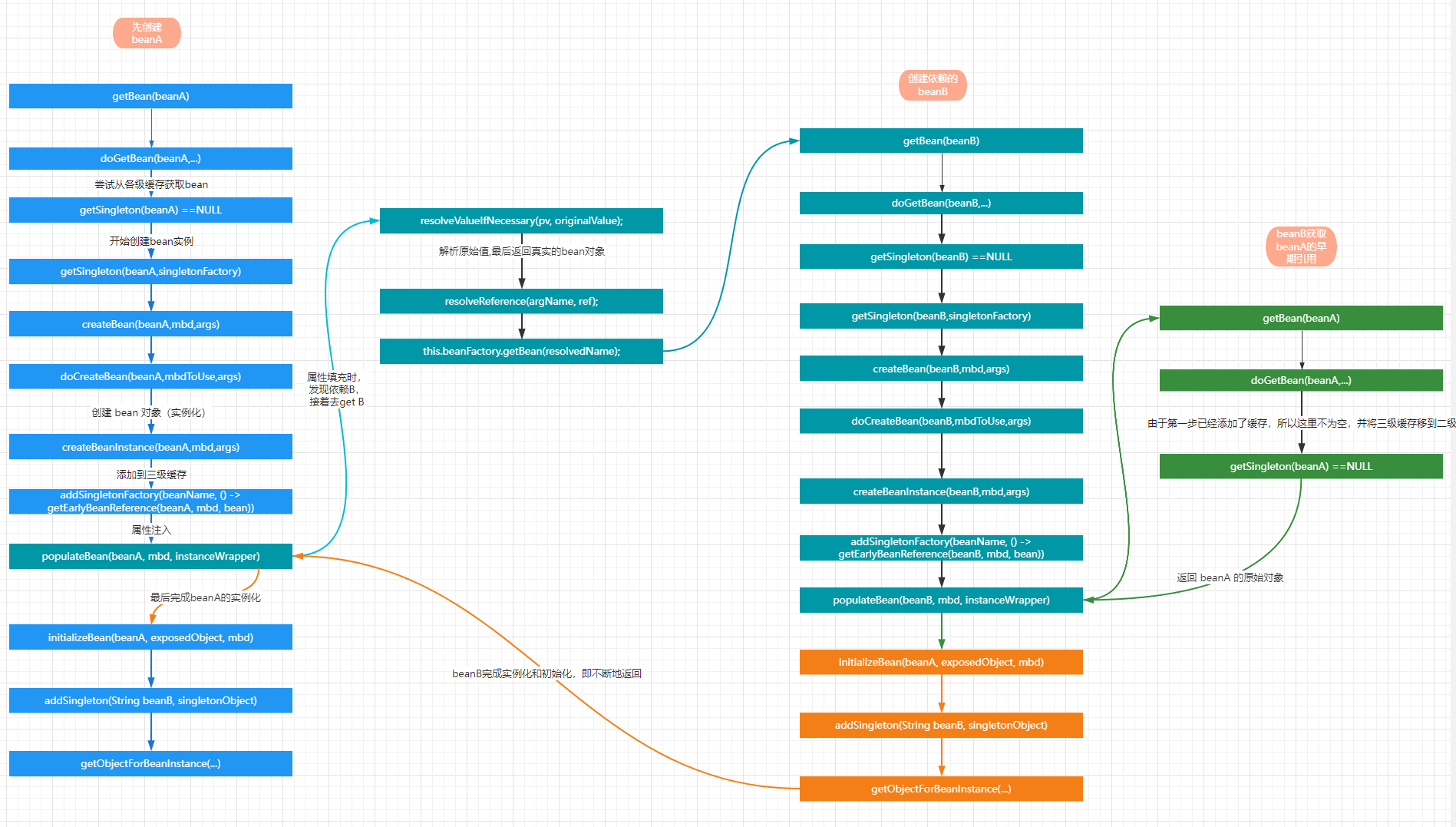
;
Original: https://blog.csdn.net/qq_67720621/article/details/127826245
Author: 伤如之何?
Title: 8.5 Spring解决循环依赖的原理(非AOP)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/661171/
转载文章受原作者版权保护。转载请注明原作者出处!