

文章目录
*
– 0️⃣前言
– 1️⃣Introduction
– 2️⃣FCOS原理
–
+ 2.1 FCOS网络结构及输出设计
+ 2.2 Head输出特征图解码详解
+ 2.3 FPN的多级预测机制
+ 2.4 Centerness分支设计
+ 2.5 Loss函数设计
– 3️⃣优劣势分析
– 4️⃣算法实现细节
– 引用
0️⃣前言
Paper link:https://arxiv.org/pdf/1904.01355.pdf
Code link:https://github.com/tianzhi0549/
1️⃣Introduction
目前目标检测根据是否需要anchor主要分为anchor-based和anchor-free两大流派。
- Anchor-based 主流的检测器比如RetinaNet、Faster R-CNN, SSD, YOLOv2,v3都是anchor-based的,也就是提前定义好框的大小,再用这个框在全图扫描寻找目标点。 但anchor-based的检测器有一些缺点:
- 框的大小、宽高比、不同框的数量,这些超参对检测器的效果影响很大。例如在COCO数据集上对RetinaNet调整这些超参,最高可上影响4%的AP。因此,这些超参需要很小心的去优化;
- 就算很仔细的调整了上述这些超参,因为框的大小和宽高比都已经固定了,一些小目标比较难检测。并且碰到不同的场景任务时,还需要重新设计框的大小等,比较麻烦;
- Anchor-based的方法为了得到尽可能高的召回率,需要很多anchor防止漏检。但这些框大部分都是负样本,这样会导致训练时正负样本很不均衡;
- Anchor-based在判断正负样本时一般用IOU,从而也导致计算比较复杂。
- Anchor-free 与基于锚框不同的地方
- 基于锚框的检测器将不同尺寸的锚框分配到不同级别的特征层
FCOS通过直接限定不同特征级别的边界框的回归范围来进行分配 - 此外,FCOS在不同的特征层之间共享信息,不仅使检测器的参数效率更高,而且提高了检测性能。 Anchor-free的方法,也是 FCOS的流派归属,就是不预先定义框,由网络自己回归出框来。最有名的anchor-free的检测器可能就是YOLOv1了,但YOLOv1因为只检测离中心点近的目标,导致召回率比较低(YOLOv2中提到过,所以YOLOv2还是用了anchor)。CornerNet需要比较复杂的后处理、DenseBox不太适合通用目标检测,并且对重叠目标检测不好。
- FCOS FCOS的paper是《FCOS: Fully Convolutional One-Stage Object Detection》,这篇论文基本是和CenterNet同时发出来的,都属于Anchor Free的目标检测算法。对比下三个Anchor Free的算法,CornerNet是在找边界框的角点,CenterNet是在找边界框的中心点,而FCOS是在找所有的点,CornerNet和CenterNet是基于关键点检测进行目标检测的,而FCOS更像是一个实例分割任务。 全卷积目标检测(FCOS)是一种基于像素级、类似实例分割的目标检测网络。FCOS的特点是不依赖Anchor机制,完全是anchor free的,避免了anchor的复杂运算,例如训练过程中计算IOU,也不需要依赖于anchor的稠密设置、尺寸和大小超参数设置,并且节省了训练过程中的内存占用。
2️⃣FCOS原理
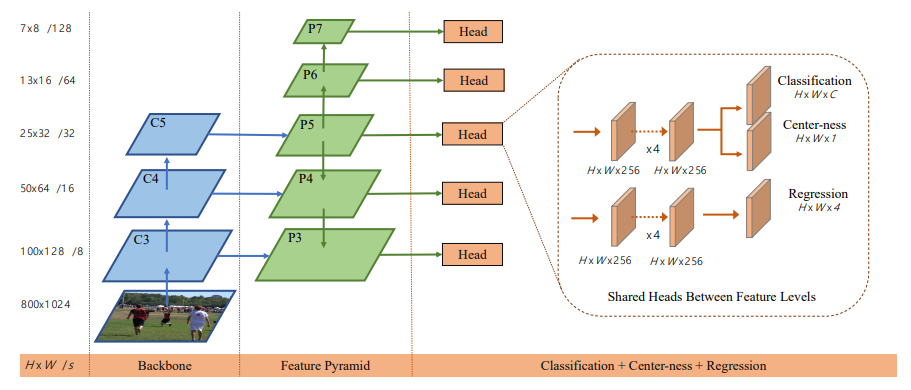
2.1 FCOS网络结构及输出设计
- backbone: FCOS的backbone可以根据需求自行定义,这里途中以ResNet50为例,原图输入尺寸为3 _800_1024,经过backbone之后得到CNN特征C3-C5,其中C3-C5的特征图尺寸大小分别为原图的1/8、1/16和1/32。
- Neck: 后面Neck部分接一个FPN模块,考虑到P2的尺寸太大了,这里只用到P3-P5,同时进行下采样两次分别得到特征融合层P6和P7,这里更浅层的特征(如P3)更适合小目标的检测,更深层次的特征(如P7)更适合大目标的检测。
- 检测头:Neck之后每个特征层后面都接一个检测头,实现相应的检测功能,这里检测头的权重都是共享的。
- 网络输出:每个检测头分3个子分支,分别负责分类、中心度和框回归任务的预测。输出3个特征图:
- Classification: C * H * W,C表示类别数(不含背景),每个类别都是二分类。
- Centerness:1 * H * W,中心度估算,目的是对目标中心很远的像素点(低质量点)进行抑制。
- Box Size: 3 * H * W,对每个特征图的element对应的边界框位置进行预测。
注:由于每个特征图的element都会对目标框进行预测,所以最后一定需要NMS来进行后处理。

; 2.2 Head输出特征图解码详解
- 特征图中心点位置映射:对于特征图中某一点x, y(x和y为整数),可以找到其在原始图像上的对应点。如果这个中心点在真实物体的边界框内,那么负责预测该物体,如果不在任何真实物体的边界框内,则为negative点。特征图和原图点位置的映射关系如下图所示:
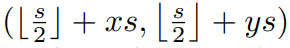
其中s为步长stride,x和y表示特征图上的坐标,s/2的外括号表示向下取整。 - 检测框解码映射:对于每一个特征图的点,目标框由Regression的四个维度l,r,t,b结合解码得到,分别表示该中心点距离边界框的左侧、右侧、顶部和底部的距离,就可以解码出预测框的具体位置坐标。

这里l,r,t,b可以通过如下公式进行学习而得到:
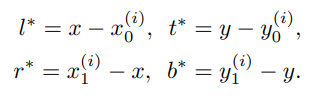
- 目标框的置信度:在特征图上,每个element都会输出一个预测框,但是显然并不是每个element都可以代表一个真实的物体,即某些像素点虽然在目标框范围内,但是所含有的语义信息与真实目标无关,这类特征图点并不代表真实物体,这类特征图点被称为低质量点。为了抑制这类低质量点所产生的预测框,将所有点的类别概率乘以centerness,得到置信度来作为最终的类别预测分数。这里centerness是中心度,由网络预测而来,点离物体中心越近值越大,离物体中心越远值越小,后面章节会详细说明。如果所有类别的概率值乘以centerness都达不到阈值,该点分类结果为negative,否则为positive,取乘积最大值对应的类别作为预测结果。
- 重叠目标预测:
- 不同尺度范围的目标会被分配给FPN中不同的P层特征图对应的head中进行分类和回归,如果重叠的目标属于不同尺度范围的,则它们被分配给不同的检测头中,并不会相互干扰,即FPN的分级预测机制发挥作用,这部分在2.3中进行详解。
- 如果经过了FPN分级预测还是存在重叠目标,则此点(图中橘黄色圆圈)负责 预测面积最小的目标框。如下图,橘黄色点将负责网球拍蓝框的预测。

2.3 FPN的多级预测机制
FCOS使用backbone输出的C3、C4、C5特征图,横向交互得到P3、P4、P5特征图。P5再经过两个步长为2的下采样得到P6和P7。最后的特征图共有5个,下采样背书分别为8、16、32、64和128。FCOS中利用FPN多尺度的特点来对GT Box进行分配,即多级预测。原论文是这么描述的:

论文中每个P层特征图设置了m阈值,P3,P4,P5,P6,P7分别对应64,128,256,512,∞。为每个特征图的element计算对应GT Box的l,r,t,b,然后对四个值取max,这个取到的最大值落到哪个范围,就由哪个P层的特征图负责预测,如取到63则对应P3层预测,取到240则对应P5层预测。这样FPN的多级预测机制可以让低层的特征尽可能的去预测小物体,让高层的特征尽可能预测大物体。当有重叠物体出现时,FPN的分级预测机制也能很大程度将重叠物体分开到不同的head上进行预测。
; 2.4 Centerness分支设计
论文一开始并没有加入centerness分支,发现检测效果并没有那么好。后来认为是大量低质量预测框导致的,低质量预测框指的是一个真实物体框内的特征图点钟离物体中心点较远的点,预测效果较差,因为特征图上的点对应的正是感受野的中心,离目标中心远的点周围像素区域很有可能压根就不是目标的语义信息,而是背景的信息。如下图所示,绿色的点离中心点很远,它周围是栅栏网的图像信息,与目标无关,大量的低质量预测框必然导致准确率的降低。

centerness的设计就是为了抑制低质量框,降低它的分数,实现离中心点远时它的值小,近时它的值大。centerness定义如下:
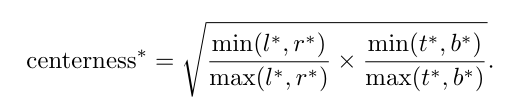
2.5 Loss函数设计
损失函数分为3个部分:
- classification loss:采用focal loss的方式对分类损失进行评估,能够解决正负样本不均衡和难易样本不均衡的问题。
- Regression Loss: 采用IOU LOSS,将边界框四个值作为一个整体去评估损失。
原文中对以上两个Loss的公式:

- Centerness Loss: 采用BCE Loss,评估中心度估计的损失。
原文对中心点Loss的计算描述:

; 3️⃣优劣势分析
优点:
- 使用了anchor free机制,减少了计算量、参数量和内存占用。
- FCOS支持小幅度改动应用到其它任务中,例如关键点检测。
- FCOS具有较高的准确率,整个结构也非常简洁。
- 与YOLOV1相比:虽然都是Anchor Free算法,但是yolov1只利用了目标中心区域的点做预测,因此recall较低。而FCOS利用了目标整个区域的点,recall和anchor-based算法相当,甚至准确率更高。
缺点:
- 利用小网络训练FCOS不易训练,容易产生不收敛的情况。
- FCOS的centerness与classification在训练中并不产生交互关系,但是在推理的时候直接相乘作为分数,对框质量的预测效果存在提升空间。
- 对近似大小的重叠物体检测效果不好,模型会归并为同一个bbox的预测。
4️⃣算法实现细节
在训练阶段,文中使用ResNet-50作为backbone网络,使用SGD优化器,初始学习率为0.01,batch_size=16,在迭代60K和80K时的weight_decay分别为0.0001和0.9,使用ImagNet预训练权重进行初始化,将输入图片裁剪为短边不小于800,长边不小于1333大小。整个网络是在COCO数据集上面训练得到的。
引用
[0] https://juejin.cn/post/7047151473909563429/#heading-6
[1] https://blog.csdn.net/WZZ18191171661/article/details/89258086
[2] https://zhuanlan.zhihu.com/p/339023466
[3] https://zhuanlan.zhihu.com/p/63868458
Original: https://blog.csdn.net/qq_41542989/article/details/123976690
Author: 小Aer
Title: 详解FCOS《FCOS: Fully Convolutional One-Stage Object Detection》
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/681602/
转载文章受原作者版权保护。转载请注明原作者出处!