

工程应用中,检测算法以one-stage算法yolo系列等为主,因为one-stage通常来说速度快,可以完成良好的实时检测。
本文回顾的是two-stage算法:RCNN系列
One-stage and two-stage:
one-stage: 直接回归物体的类别概率和位置坐标值(无region proposal),但准确度低,速度相比two-stage快。
two-stage:先由算法生成一系列作为样本的候选框,再通过卷积神经网络进行样本分类。
一.RCNN
算法流程概述:
(1)search selective生成候选框
(2)对候选框用深度网络提取特征(候选框resize成224*224)
(3)特征送入每一类的SVM分类器进行分类
(4)用回归器对候选框进行位置修正


这里的深度网络用的是Alexnet CNN,不同的是将最后的一层的11000全连接层(原先全连接是用来分类)去掉了,这样就得到了一个4096维的特征向量,若有K个候选框则得到K个4096维的特征向量。再经过特征提取后将K4096维的特征向量输入到20个SVM分类器中(权值矩阵409620),从而得到K20维的矩阵,表示K个候选框对应20个类别的得分。对K*20维矩阵在每一列(每一类)进行NMS得到该类中得分最高的框。
NMS非极大值抑制算法:
寻找每个类别中得分最大的目标,因为对于一类,score越高越能说明物体在里面。取score最高的一个框,计算其与其他框的iou,iou越大越可能是同一个物体,去掉iou大于给定阈值的目标框。

在经过NMS处理后,对剩余的高质量建议框进行回归操作,其主要回归有四个参数,中心点距离实际位置的偏移量x和y,以及建议框宽高的缩放因子hw
二.Fast-RCNN
RCNN存在的问题:用Selective search算法提取候选框费时,并且对于每个proposalregion都要经过深度网络进行计算,并且计算前要经过resize。
算法流程概述:
(1)一张图生成K个候选框
(2)将图像输入CNN得到feature map,将SS算法生成的候选框投影到特征图上获得相应的特征矩阵(RCNN并未将整张图片输入进网络,而是将生成的每个候选框输入进网络,得到其特征向量)
(3)将每个特征矩阵经过ROI Pooling层缩放得到7*7大小的特征图,接着将特征图展平通过一系列全连接得到预测结果(RCNN训练了SVM和回归器进行分类和回归,Faster-RCNN直接将分类和回归融合进一个网络中)

Fast-RCNN一次性计算整张图的特征,与RCNN相比,避免了K个候选框计算特征时的K次前向传播,提高了计算速度,使候选框的特征不需要重复计算
Mini-batch sampling:
在训练过程中,我们并不是将SS算法提供的所有候选框,而是通过采样解决正负样本可能带来的数据不平衡问题(假如我们要识别正样本猫,但SS得到候选框大多数都是负样本狗,这对网络预测会更偏向于狗),Fast-RCNN在所有ROI中采样64个ROI,根据其与真实值的IOU划分他们的正负。
在得到训练样本之后,我们将候选框通过ROI Pooling(不限制图像输入尺寸)缩放到同一尺寸
ROI Pooling:
下图是8*8feature map 上的一个proposal region:

假设我们想得到一个22的输出,对proposal region进行22划分:
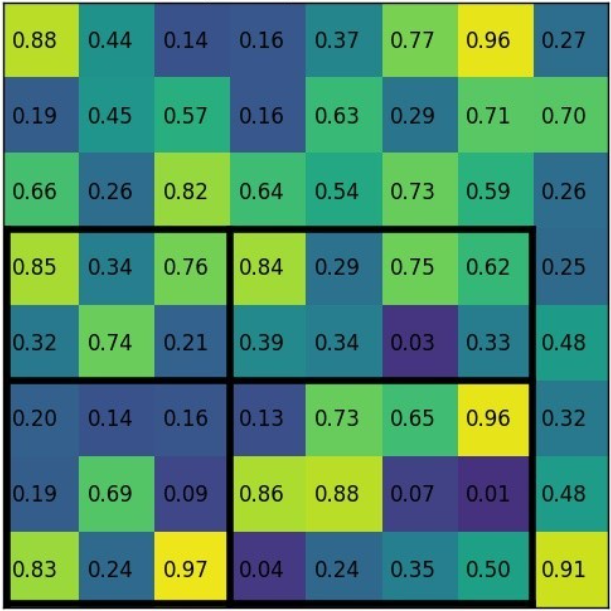
再对每个划分区域进行MAX Pooling:

在经过这一步后,经过两个全连接层进行展平得到ROI feature vector,再通过两个并联的结构,一个进行概率预测,一个进行回归修正。
softmax分类器输出的是N+1个类别的概率,N为检测目标种类,1为背景。bbox regressor输出的是N+1类别的4个候选框回归参数,共(N+1)*4个节点。
在计算损失时,SoftmaxLoss 代替了SVM,证明了softmax比SVM更好的效果;SmoothL1Loss 取代Bouding box 回归。将分类和边框回归进行合并(又一个开创性的思路),通过多任务Loss层进一步整合深度网络,统一了训练过程,从而 提高了算法准确度。网络代价函数具体如下图所示:

三.Faster-RCNN
Fast-RCNN中用的候选框生成算法SS仍然很费时,Faster-RCNN对此提出了一个Region Proposals Network,Faster-RCNN可以看作是RPN+Fast-RCNN.
算法流程概述:将图像输入网络得到特征图,使用RPN生成候选框,将生成的候选框投影到特征图上获得相应的特征矩阵,将每个特征矩阵通过ROI Pooling缩放到7*7,接着将特征图经过展平通过一系列全连接得到预测结构。

RPN: 总体来说,RPN就是在feature map上,对每个对应原图区域的点,设计不同的固定尺度窗口(bbox),根据该窗口与ground truth的IOU给它正负标签,让它学习里面是否有object。
Anchor:对于特征图上的每个3*3的滑动窗口,计算出滑动窗口中心点,在原图位置上的中心点,并计算出k个anchor box

Faster-RCNN中的anchor具有三种尺度,三种比例,所以每个滑动窗口在原图上都对应有9个anchor ,下图为RPN网络。256对应的是特征提取网络得到的feature map的通道数。

RPN的具体实现:滑动窗口采用的是33的卷积,padding为1,步长为1,这样滑动窗口便可以遍历特征图上所有的点,经过卷积之后生成宽度高度深度与feature map一样的特征矩阵,在特征矩阵上并列两个卷积层,分别进行分类和回归的预测,cls layer分支用的是11的卷积核,个数为2k的卷积层来处理,reg layer分支用的是1*1的卷积核,个数为4k的卷积层来处理。对于原图上一个点处产生的K个anchor,其最后输出的向量(分类信息和回归信息)为:

RPN网络的结果就是每个点都有关于K个anchor box的输出,包括是不是物体,物体的位置调整

RPN损失计算:
与Fast-Rcnn类似,在计算损失前我们对正负样本进行了采样
对于每个anchor,首先在后面接上一个二分类softmax,有2个score 输出用以表示其是一个物体的概率与不是一个物体的概率
,然后再接上一个bounding box的regressor 输出代表这个anchor的4个坐标位置,因此RPN的总体Loss函数可以定义为
 表示一个mini-batch的所有样本个数,表示anchor位置的个数(N*M) ,真实边界框和预测边界框的转化关系如下:
表示一个mini-batch的所有样本个数,表示anchor位置的个数(N*M) ,真实边界框和预测边界框的转化关系如下:

Faster-RCNN的损失则与Fast-RCNN类似。
训练过程:
原论文采用分别训练的方法:
第一步:用ImageNet模型初始化,独立训练一个RPN网络;
第二步:仍然用ImageNet模型初始化前置网络参数,但是使用上一步RPN网络产生的proposal作为输入,训练一个Fast-RCNN网络
第三步:使用第二步的Fast-RCNN网络参数初始化一个新的RPN网络,但是把RPN、Fast-RCNN共享的那些卷积层的learning rate设置为0,也就是不更新,仅仅更新RPN特有的那些网络层,重新训练,此时,两个网络已经共享了前置的公共卷积层;
第四步:仍然固定共享的那些网络层,去微调Fast-RCNN网络的全连接参数。最后RPN和Fast-RCNN网络共享前置卷积网络层,形成一个同一网络。
在Faster-RCNN之后,Mask-RCNN被推出,其在Faster-RCNN的基础上加了一个预测物体Mask的分支,用来解决实例分割问题,将在之后的文章中阐述。
参考资料:https://www.bilibili.com/video/BV1ha411r7cK?spm_id_from=333.337.search-card.all.click https://zhuanlan.zhihu.com/p/24916624
https://search.bilibili.com/all?from_source=webtop_search&spm_id_from=333.788.b_696e7465726e6174696f6e616c486561646572.9&keyword=yolo
Original: https://blog.csdn.net/weixin_44768052/article/details/124056260
Author: Rainlin.Zhang
Title: 目标检测—RCNN系列
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/681344/
转载文章受原作者版权保护。转载请注明原作者出处!