



©PaperWeekly 原创 · 作者|张一帆
学校|华南理工大学本科生
研究方向|CV,Causality
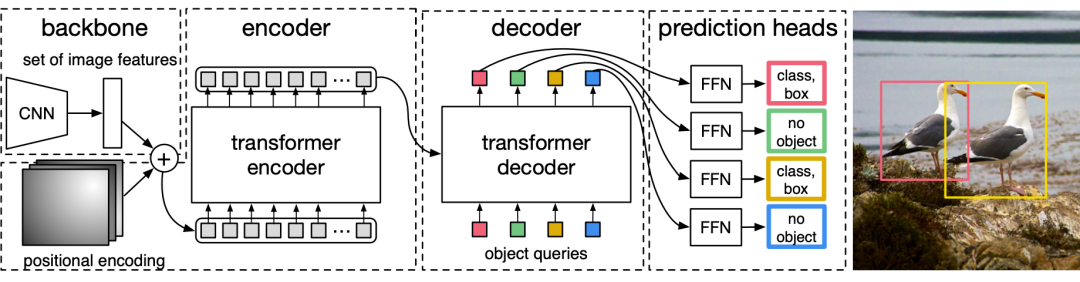
DETR 在短短一年时间收获了 200+ 引用量,可谓是风靡一时,各种变体层出不穷,这篇文章主要总结了几篇论文来研究各种关于 DETR 的改进以及它存在的问题。

DETR

论文标题:
End-to-End Object Detection with Transformers
收录会议:
ECCV 2020
论文链接:
https://arxiv.org/abs/2005.12872
代码链接:
https://github.com/facebookresearch/detr
facebook 力作,网上类似的解读已经很多了,将 object detection 视为一个 set prediction 的问题。个人觉得他吸引人的地方在于简洁优雅的训练方式,无需任何后处理,实现非常简单。当然 DETR 的缺点也很明显,需要较长的训练时间,而且在小物体上的检测结果并不尽如人意。之后这几篇 paper 也是从不同的角度相对这个问题作出回应。

ViT-FRCNN

论文标题:
Toward Transformer-Based Object Detection
论文链接:
https://arxiv.org/abs/2012.09958
文章提出了 ViT-FRCNN 模型,听名字就知道是 ViT 与 FRCNN 的结合。我们先来看看 ViT。
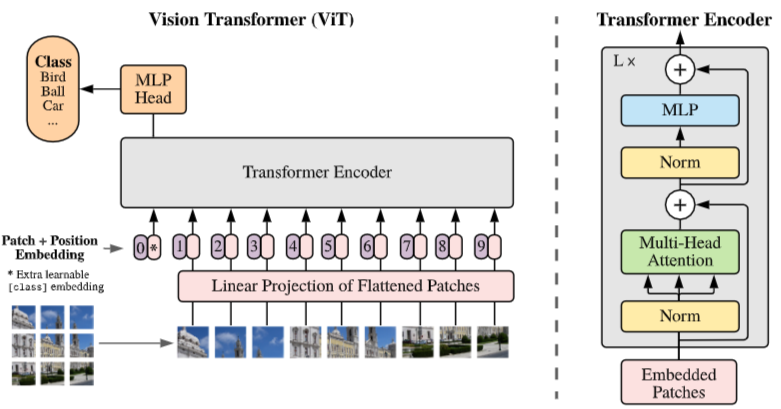
我们知道 ViT 其实只有 encoder,但是他很好地完成了分类这一任务,他只使用 cls token 做分类,其余的 image patch 生成的 token 抛弃掉了。但是这些 token 其实包含大量的局部信息,非常适合用来做目标定位。所以只要能利用好这些 token,我们是不是可以不需要 decoder 呢?答案是肯定的。
ViT-FRCNN,具体与 DETR 的不同之处主要体现在以下几个方面:
- 无需 CNN 提取特征,采用了 ViT 的输入方式直接将 image 切割成 patch 然后做 Linear projection 即可变为输入。
- 对于 encoder 产生的各个 embedding,ViT-FRCNN 将他们重新组织成为 feature map。这样我们就可以用 Faster-RCNN 的方法,先在 feature map 上做 region proposal,然后对这些 RoI 做分类和定位。
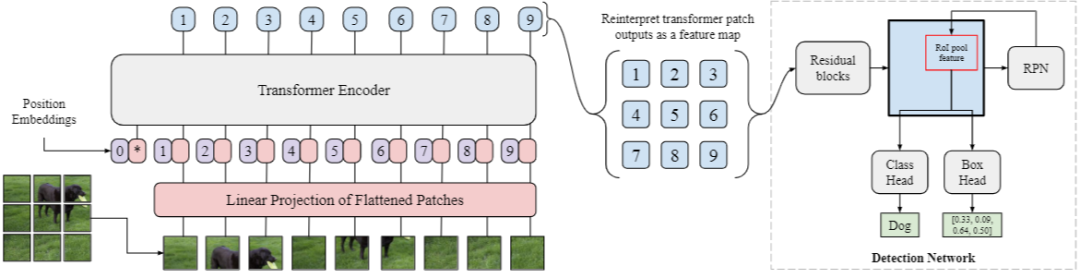
总的来看,就是将 Faster-RCNN 的 backbone 替换为了 transformer,文章也没有与 DETR 进行深入比较。

TSP-FCOS & TSP-RCNN

论文标题:
Rethinking Transformer-based Set Prediction for Object Detection
论文链接:
https://arxiv.org/abs/2011.10881
文章研究了 DETR 训练中优化困难的原因:Hungarian loss 和 Transformer cross-attention 机制等问题。为了克服这些问题,还提出了两种解决方案,即 TSP-FCOS 和 TSP-RCNN。实验结果表明所提出的方法不仅比原始 DETR 训练更快,准确性方面也明显优于 DETR。
3.1 是什么使得DETR收敛如此之慢?
作者首先猜测可能是因为使用了二分图匹配来计算两个集合的相似度,但是试验结果表明问题这里的问题其实不算严重。相反,decoder 中的 cross attention 才是罪魁祸首。我们知道 attention map 在初始化的时候是非常均匀的,但是随着他不断收敛会变得越来越稀疏。
相关研究表明,如果我们将 attention 替换为更加系数的算子比如卷积将会大大加快收敛的速度。所以这里的 cross-attention 到底影响有多大,文中给出了以下实验:
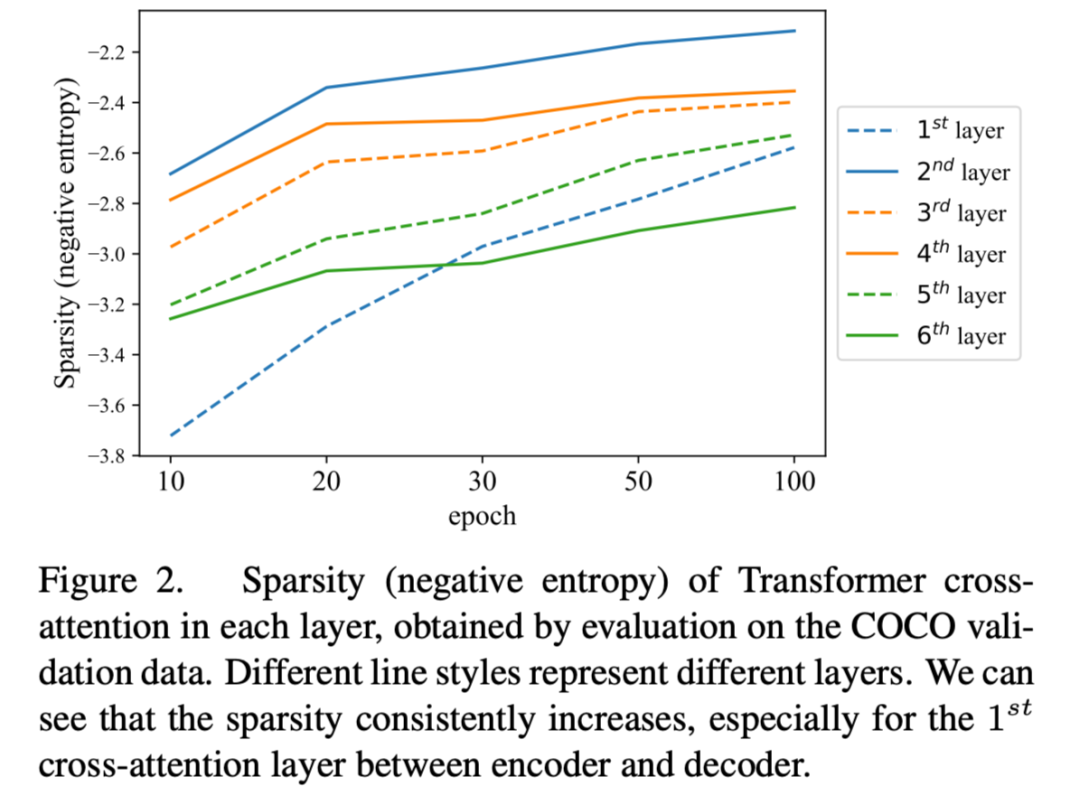
我们可以看到,cross-attention 的稀疏性持续增加,即使在 100 次训练后也没有收敛。这意味着 DETR 的交叉注意部分是一个导致收敛速度慢的主导因素。
3.2 我们一定需要交叉注意力吗?
通过设计只有 encoder 的网络,即 encode 出来的 embedding 直接用来做分类和定位(结构图如下),因为 encoder 其实就是一个自注意力的网络,所以DETR训练的方式可以照搬过来。
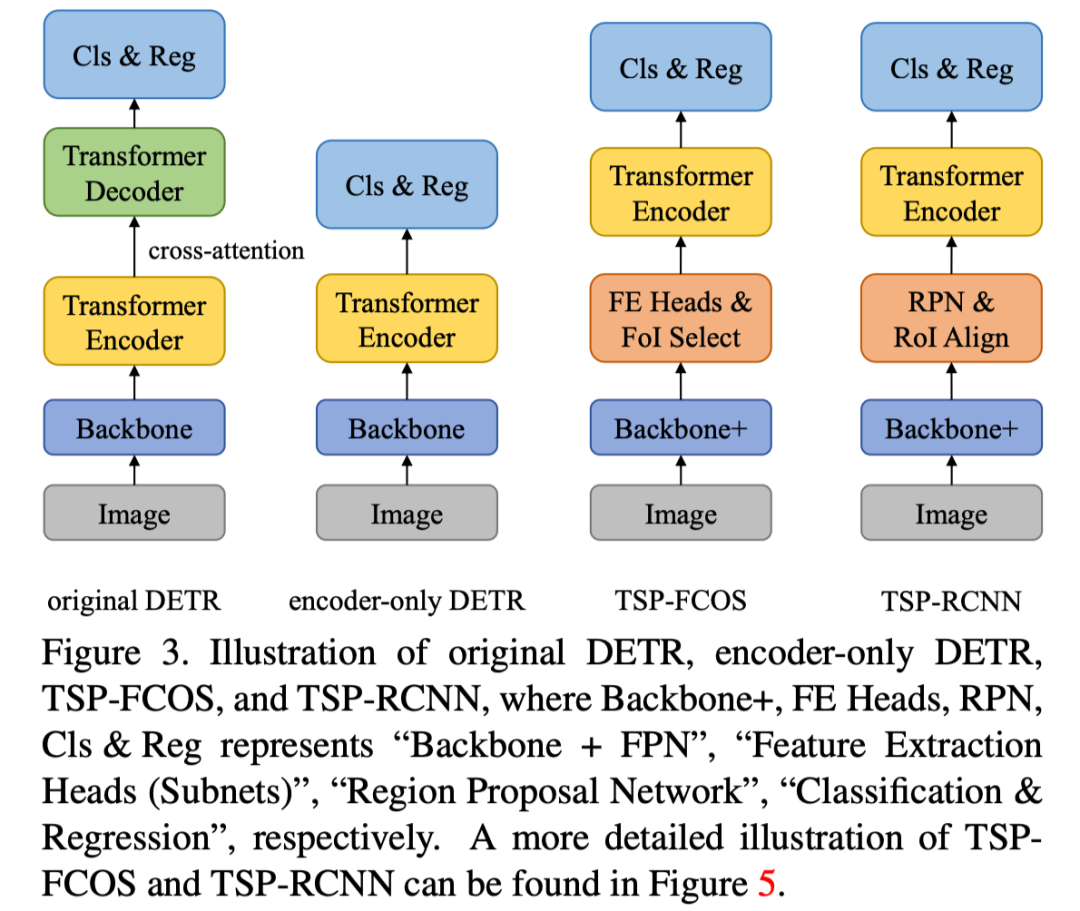
我们可以得到下图的结果,可以看到其实 AP 下降的并不多,相反对小物体而言我们有非常大的提升,但是对大物体而言效果有所下降。
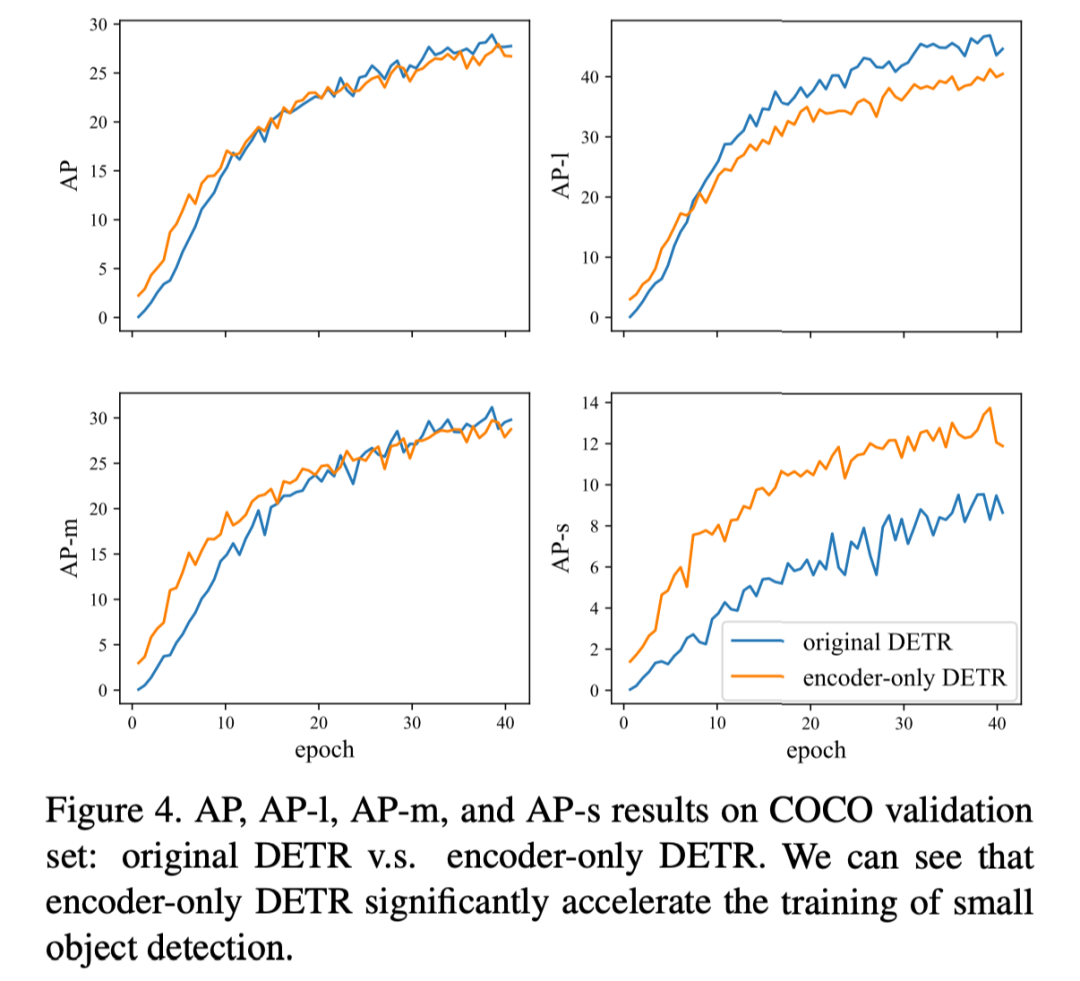
文中认为一种可能的解释是,一个大对象可能包含太多潜在的匹配特征点,这对于只使用编码器的 DETR 来说是很难处理的。另一个可能的原因是编码器处理的单一特征映射对于预测不同尺度的对象是不鲁棒的(融入 FPN 可能能解决这个问题)。
3.3 如何解决上述问题?
作者提出了两种不同的架构,这两种架构都融入了 FPN 对 CNN 提取出来的特征图进行处理来缓解 Encoder-Only DETR 对大尺度物体不敏感的缺陷。
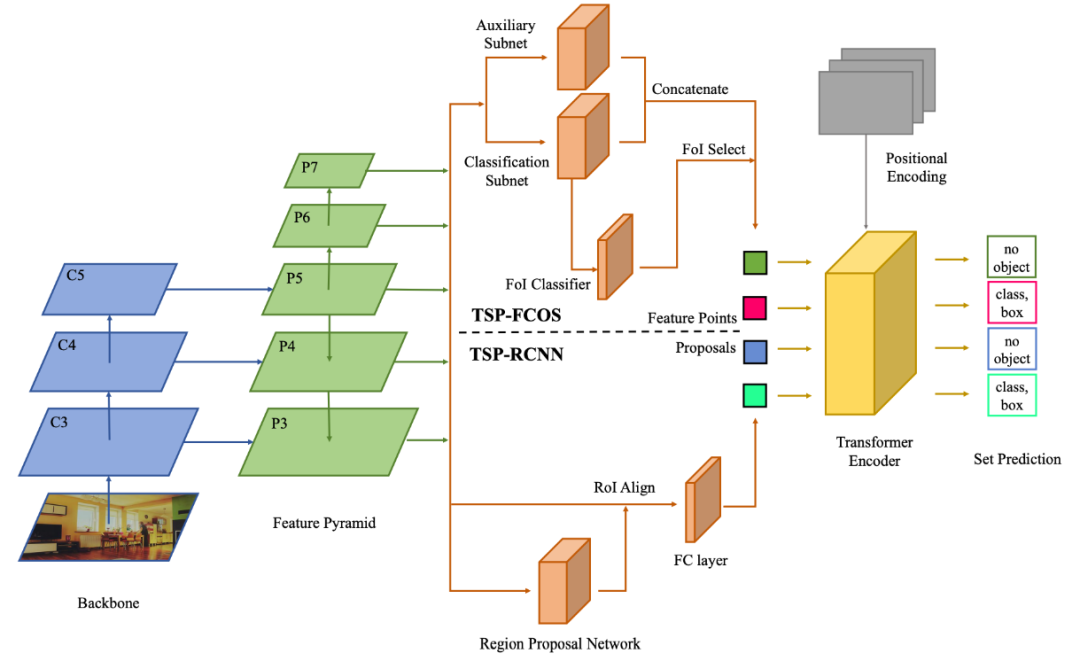
- TSP-FCOS:在 backbone 和 encoder 之间加上了 head;
- TSP-RCNN:在 backbone 和 encoder 之间加上了 RoIAlign; 主要与 DETR 的区别在于
- 在输入 encoder 之前都会从图像金字塔中抽取 RoI,FoI 作为 encoder 的输入,这一步显然会增加定位精度,但是同时模型也变得更加复杂了。
- 针对 RoI 采取了特殊的 position encoding (根据 box 的中心点,长宽高设计 encoding)
- 将传统 FCOS 和 RCNN 匹配 ground truth 和预测 box 的方法融入 DETR 中,进一步提高匹配的效果与效率。
3.4 实验
下表比较充分地说明了训练精度和速度都有所提升。
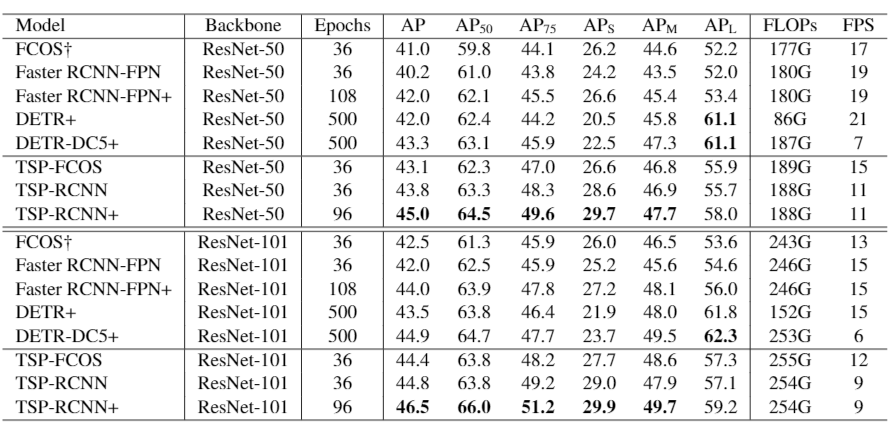
作者还贴心的画了一张图,上面两张图比较了文中提出的损失函数收敛速度的影响(DETR-Like)就是直接二分匹配。下面的图展示了文中两个model与DETR收敛速度的比较。
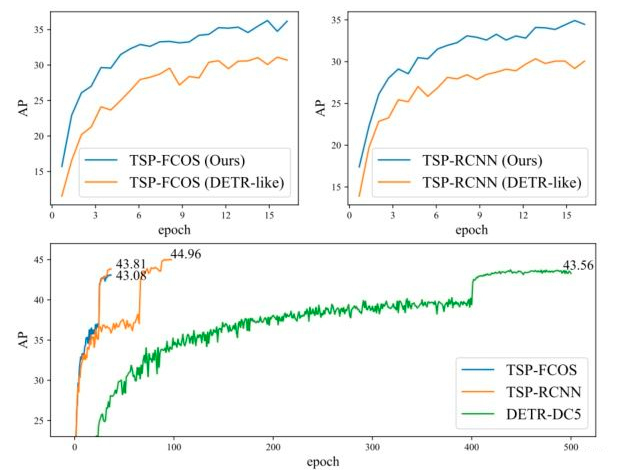
3.5 总结与讨论
上两篇文章的区别在哪呢?ViT-FRCNN 使用 transformer encoder 提取特征,将重组后的 feature map 扔进 RCNN 的检测网络中得到最终结果。而 TSP-RCNN 先用传统方法将特征处理好,找到 RoI 或者 FoI,然后将他们扔到 transformer encoder 中,二者可能都有提升,但还是大量依赖与传统检测的各种处理方法。Transformer 在他们之中扮演的角色仿佛也不是那么重要。

Deformable DETR

论文标题:
Deformable DETR: Deformable Transformers for End-to-End Object Detection
收录会议:
ICLR 2021
论文链接:
https://arxiv.org/abs/2010.04159
代码链接:
https://github.com/DeppMeng/Deformable-DETR
文章先 argue 了两个 DETR 面临的主要问题
- 训练周期长,收敛速度慢,比 Faster-RCNN 慢 20 倍。这主要是因为 attention map 要从均匀到稀疏这个训练过程确实非常耗时。
- 小物体检测效果差,FPN 可以减缓这个缺陷,但是由于 Transformer 的复杂度是 ,高分辨率对 DETR 来说会带来不可估量的内存和计算速度增加。
而可变形卷积 deformable convolution 就是一种有效关注稀疏空间定位的方式,可以克服以上两个缺点。
4.1 Deformer Attention
作者首先提出了 Deformer Attention 模块,attention 难就难在他是一个密集连接,但是需要学到非常稀疏的知识,Deformer 直接将需要学习的知识定义为稀疏的。与传统 attention 的最大区别在于:Attention weight 不再基于 query 和 key 的 pairwise 对比,而是只依赖于 query。
在实现上,每个 query 会被映射到 的特征空间(M 是 attention head 的数目,K 是我们预设的 key 的数目 e),前 个通道编码采样的 offset(对 个 key 值分别有一对 offset),决定每一个 query 应该找哪些 key,最后 个通道,输出 keys 的贡献(不再用 key-query 交互来计算权重,直接输入 query 回归),且只对找到的 keys 的贡献进行归一化。
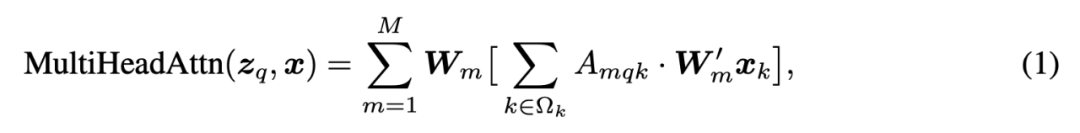
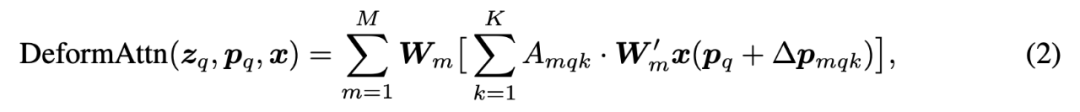
对比一下传统 attention 和这个方法,在公式中体现出来的区别在于 ,这里 是每个 query 都有的一个二维 reference point(二维的索引),但是我们生成的第 k 个 key 的索引 可能并不会精确的 match 到一个点的索引,这时就会用到双线性插值通过周围的 embedding 得到我们需要位置的 embedding。
4.2 Multi-scale Deformable Attention Module
将 resnet 中间多层不同分辨率的特征图拿出来构成 ,在每一层挑选 个点,所以一共 个点做归一化得到权重 。其中归一化的 reference 坐标在 [0,0] 到 [1,1],这二者分别表示左上和右下 (因为有多个尺度,所以不能像单尺度那样直接使用 ),然后 就会将这个 reference 重新映射回 层的真实坐标用于索引。
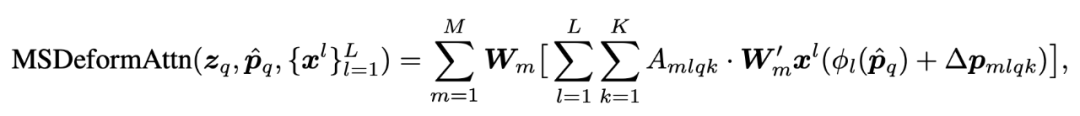
4.3 Deformable Transformer Encoder
这里虽然还称之为 transformer,实际上输入输出已经不是序列数据了,而是保持相同分辨率的多尺度特征图。这里的 query,key 都是多尺度特征图上的像素点,对每个 query 像素点,他的 reference point 就是它本身。之后我们就使用上文提出的 deformable attention 对 query,key 进行处理。
4.4 Deformable Transformer Decoder
将 cross-attention 的部分替换为 deformable attention,保持 self-attention 模块不变(query,key 都是 object query),这样做是为了使得各个 object query 之间也能够有充分的交互,同时减少交叉注意力时 key 值的数目。
有一点也很有意思,我们这些 reference point 并不只是用来索引的,他们还可以作为预测 box 的初始中心点,这样我们就能将回归目标设为 offset 而不是直接预测长和宽,降低了优化的难度。
decoder 部分 iterative bbox refinement 和 two stage 的思路看起来就是传统检测模型的一种引入。
4.5 Experiments
效果感人,和 DETR 同等参数量下只训练 50 个 epoch 就已经得到非常不错的结果了。
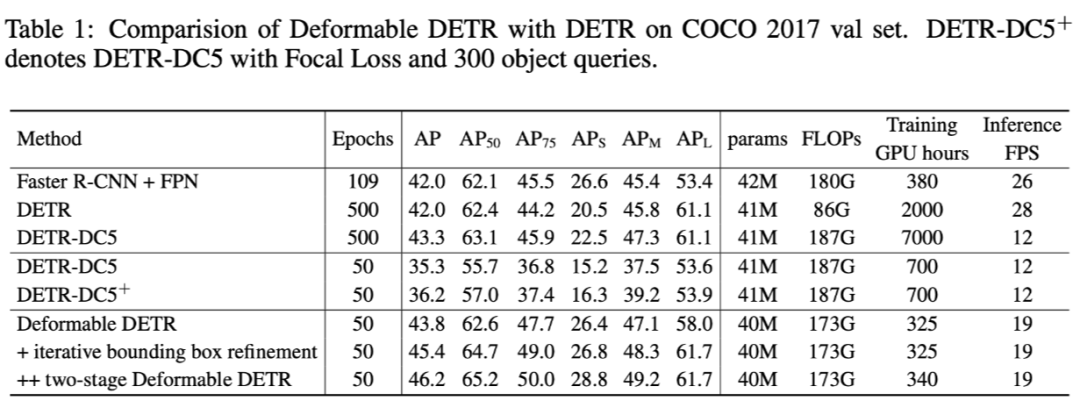
有个图感觉有点争议,这张图虽然效果很好。但是没有 MS attention 而且 K=1 的时候其实已经退化成了 deformable conv,此时的的效果也并不差。
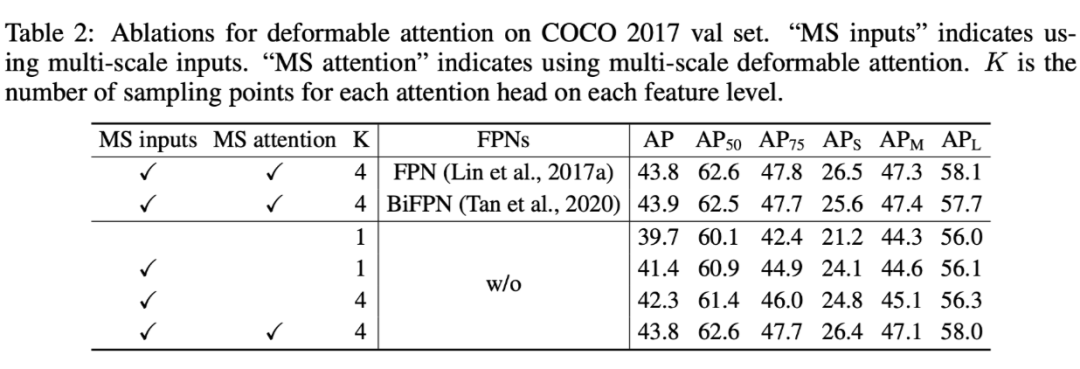
可变性注意力的设计值得关注,是不是也能扩展到序列数据处理上是一个有待研究的问题。但总体来看与传统 transformer 已经不太像了,也有人说”如果把 attention 那部分再改改,就又回到传统检测的老路上了”。

ACT

论文标题:
End-to-End Object Detection with Adaptive Clustering Transformers
论文链接:
https://arxiv.org/abs/2011.09315
文章的 motivation 给的比较清晰,主要有两点:
- Attention Map 存在很多冗余,可以看到 DETR 的编码器输出的结果中,相近的点他的 attention map 是非常类似的。
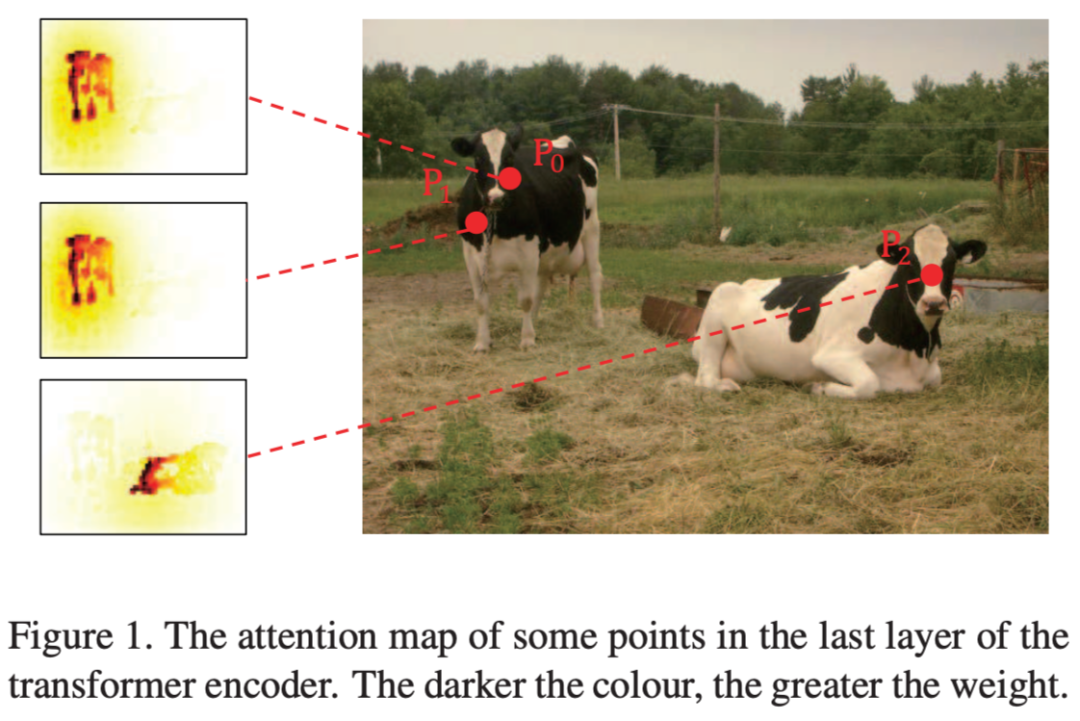
- 随着 encoder 的加深,特征之间的相似度会逐渐增高。这其实是很直观的,因为 encoder 一直在做自注意力,交互的越多就包含了更多的全局信息。作者也做了实验进行验证。
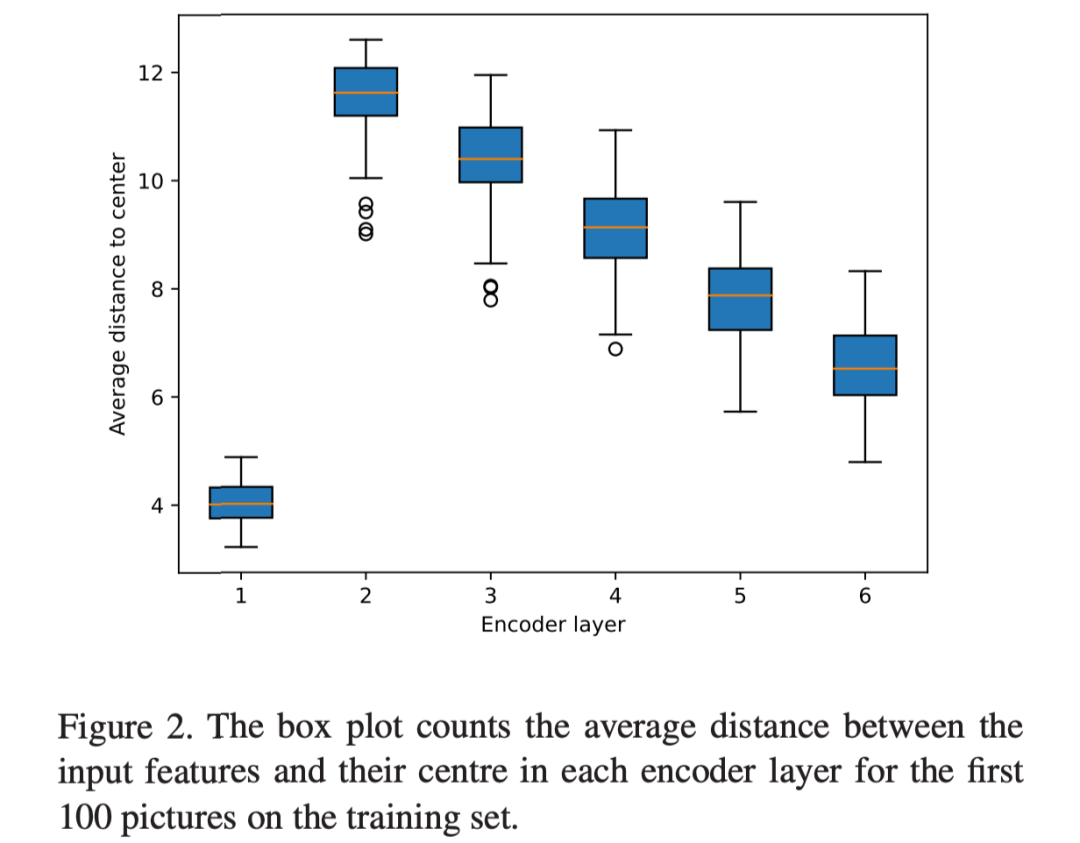
为了解决上述第一个问题,作者想到了对相似的特征图聚类,计算它们的聚类中心(prototype),原型的特征是一整个 cluster 的均值,我们做 key-value attention 的时候也只是针对这些原型来做,这样就大大的减小了参数量。但是对于聚类而言,我们要聚多少类这是一个比较重要的问题。
而第二个观察告诉我们,不同层特征的相似度是不同的,因此我们可以对不同层规定不同数目的 prototype,如果这一层大多数都很类似,那我们大可以选比较少的 prototype。文中采用了 E2LSH 这种哈希技术来自动进行聚类。
5.1 Adaptive Clustering Transformer
- 确定原型:文中使用了 Locality Sensitivity Hashing(LSH)这一近邻搜索方法来进行聚类。通过控制参数,我们可以做到使得距离小于 的特征向量以大于 的概率进入同一组。以下是我们的哈希函数 ,其中 是超参, 都是随机变量。
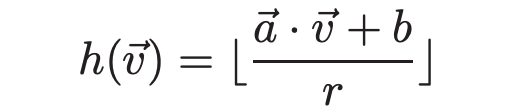
我们做 次哈希然后来增加可信度:
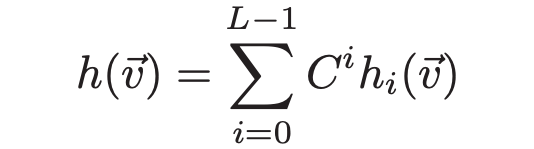
直观理解一下这个过程,其实每个哈希函数都可以看作是一组由超参数控制的平行线,将空间分为不同的区域, 控制着他们的间距。 个不同的哈希函数将空间分成了不同的 cell,落在一个 cell 中的特征具有同样的哈希值。只管上来看欧几里得距离越小,更容易有相同的哈希值。将拥有相同哈希值的 query 求平均,我们就得到了第 个 cluster 的 prototype 。

- 估计注意力输出:使用这些 prototype 来代替 query,我们就可以将时间复杂度从 降到 。更加正式一点的定义如下 ,那么我们通过以下公式得到 attention 的输出 :
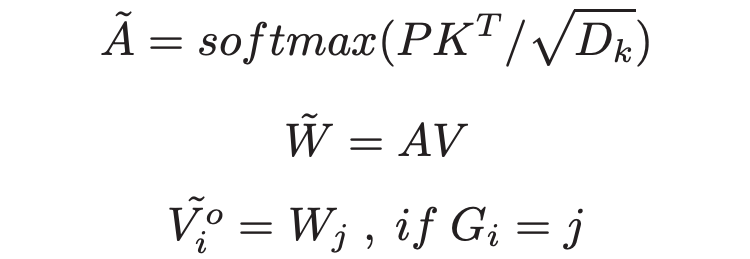
这里的 指的是 query 所属的 cluster。
主题内容到这里就结束了,文章还提到了误差的分析和使用知识蒸馏的方式进一步提升效果。
5.2 Experiments
首先是超参数的选择,作者随机在训练集采样 1000 张 image 计算它们真实 attention map 和使用本文 ACT 产生的 attention map 之间的均方误差,从而来选择合适的 。超参数对这篇文章影响非常大,因此需要仔细地选择一个比较合适的超参。
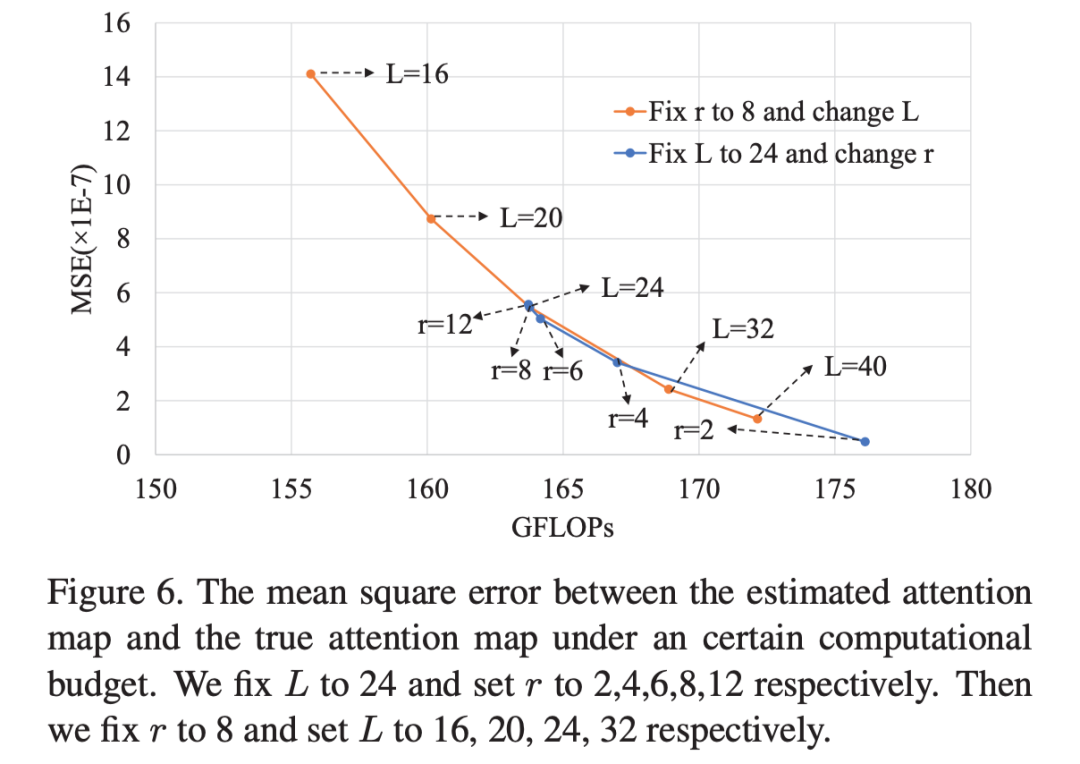
在速度-准确性的 tradeoff上,ACT 表现出了比传统 DETR 或者使用 Kmeans 来聚类更好的效果。
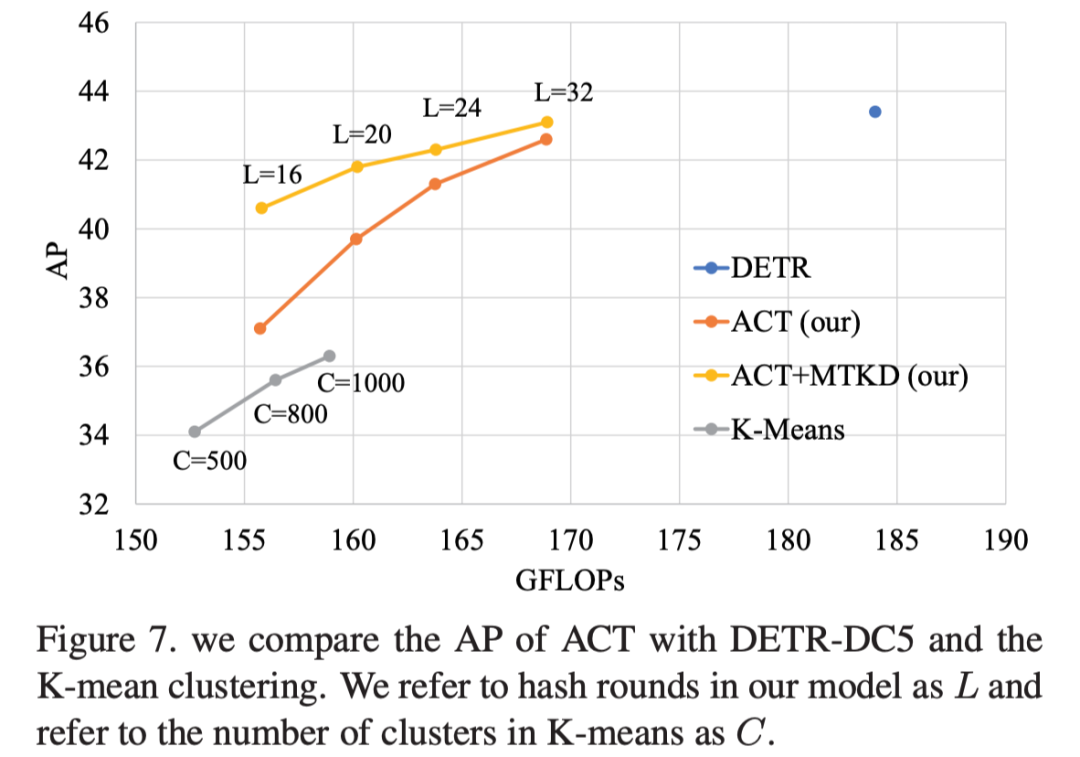
AP 的比较有点意思,ATP 可以比较好的近似 DETR 产生的 attention map,不过利用 prototype 代替 query 直觉上来看更加丢失了局部信息,反映在实验上 确实变差了,但是小物体检测一直是 DETR 至关重要的一个缺陷,而 ACT 使得这点更为突出。
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢? 答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是 最新论文解读,也可以是 学习心得或 技术干货。我们的目的只有一个,让知识真正流动起来。
???? 来稿标准:
• 稿件确系个人 原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加”原创”标志
???? 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
????
现在,在 「知乎」也能找到我们了
进入知乎首页搜索 「PaperWeekly」
点击 「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击 「交流群」,小助手将把你带入 PaperWeekly 的交流群里。


Original: https://blog.csdn.net/c9Yv2cf9I06K2A9E/article/details/116141163
Author: PaperWeekly
Title: 如何用Transformer来做目标检测?一文简述DERT及其变体
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/681241/
转载文章受原作者版权保护。转载请注明原作者出处!