

目录
3.1.3 统计出911数据中不同月份不同类型的电话的次数的变化情况
(一)为什么要学习pandas的时间序列
不管在什么行业,时间序列都是一种非常重要的数据形式,很多统计数据以及数据的规律也都和时间序列有着非常重要的联系
(二)pandas创建时间序列
pd.date_range(start=” “, end=” “, freq=” “)
import pandas as pd
time = pd.date_range(start="20171230", end="20180130", freq="D")#频率是天
print(time)
'''
DatetimeIndex(['2017-12-30', '2017-12-31', '2018-01-01', '2018-01-02',
'2018-01-03', '2018-01-04', '2018-01-05', '2018-01-06',
'2018-01-07', '2018-01-08', '2018-01-09', '2018-01-10',
'2018-01-11', '2018-01-12', '2018-01-13', '2018-01-14',
'2018-01-15', '2018-01-16', '2018-01-17', '2018-01-18',
'2018-01-19', '2018-01-20', '2018-01-21', '2018-01-22',
'2018-01-23', '2018-01-24', '2018-01-25', '2018-01-26',
'2018-01-27', '2018-01-28', '2018-01-29', '2018-01-30'],
dtype='datetime64[ns]', freq='D')
'''
time = pd.date_range(start="20171230", end="20180130", freq="10D")#频率是天
print(time)
#DatetimeIndex(['2017-12-30', '2018-01-09', '2018-01-19', '2018-01-29'], dtype='datetime64[ns], freq='10D')
time = pd.date_range(start="20171230", periods=10, freq="1D")#periods表示生成几个数
print(time)
'''
DatetimeIndex(['2017-12-30', '2017-12-31', '2018-01-01', '2018-01-02',
'2018-01-03', '2018-01-04', '2018-01-05', '2018-01-06',
'2018-01-07', '2018-01-08'],
dtype='datetime64[ns]', freq='D')
'''
time = pd.date_range(start="20171230", periods=10, freq="M")
print(time)
'''
DatetimeIndex(['2017-12-31', '2018-01-31', '2018-02-28', '2018-03-31',
'2018-04-30', '2018-05-31', '2018-06-30', '2018-07-31',
'2018-08-31', '2018-09-30'],
dtype='datetime64[ns]', freq='M')
'''
time = pd.date_range(start="2017-12-30 10:10:30", periods=10, freq="H")
print(time)
'''
DatetimeIndex(['2017-12-30 10:10:30', '2017-12-30 11:10:30',
'2017-12-30 12:10:30', '2017-12-30 13:10:30',
'2017-12-30 14:10:30', '2017-12-30 15:10:30',
'2017-12-30 16:10:30', '2017-12-30 17:10:30',
'2017-12-30 18:10:30', '2017-12-30 19:10:30'],
dtype='datetime64[ns]', freq='H')
'''
(三)案例分析
3.1 911电话按照紧急类型进行统计分析
现在我们有2015到2017年25万条911的紧急电话的数据,请统计出出这些数据中不同类型的紧急情况的次数,如果我们还想统计出不同月份不同类型紧急电话的次数的变化情况,应该怎么做呢?
3.1.1 统计不同类型的紧急情况的次数
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
file_path = "911.csv"
df = pd.read_csv(file_path)
#print(pf.head())
#print(pf.info())
temp_list = df["title"].str.split(":").tolist()
#print(temp_list)
cate_list = list(set([i[0] for i in temp_list]))
#print(cate_list)
#['Traffic', 'Fire', 'EMS']
#构造全为0的数组
zeros_df = pd.DataFrame(np.zeros((df.shape[0], len(cate_list))), columns=cate_list)
#print(zeros_df)
for cate in cate_list:
zeros_df[cate][df["title"].str.contains(cate)] = 1
sum_ret = zeros_df.sum(axis=0)
print(sum_ret)
'''
Fire 96177.0
Traffic 223395.0
EMS 320333.0
'''
zeros_df最后的结果是:
Fire  Traffic  EMS
0        0.0      0.0  0.0
1        0.0      0.0  0.0
2        1.0      0.0  0.0
3        0.0      0.0  0.0
4        0.0      0.0  0.0
...      ...      ...  ...
639893   1.0      0.0  0.0
639894   0.0      0.0  0.0
639895   1.0      0.0  0.0
639896   0.0      0.0  0.0
639897   1.0      0.0  0.0
[639898 rows x 3 columns]
        Fire  Traffic  EMS
0        0.0      0.0  0.0
1        0.0      0.0  0.0
2        1.0      0.0  0.0
3        0.0      0.0  0.0
4        0.0      0.0  0.0
...      ...      ...  ...
639893   1.0      0.0  0.0
639894   0.0      0.0  0.0
639895   1.0      0.0  0.0
639896   0.0      0.0  0.0
639897   1.0      0.0  0.0
[639898 rows x 3 columns]
        Fire  Traffic  EMS
0        0.0      0.0  1.0
1        0.0      0.0  1.0
2        1.0      0.0  0.0
3        0.0      0.0  1.0
4        0.0      0.0  1.0
...      ...      ...  ...
639893   1.0      0.0  0.0
639894   0.0      0.0  1.0
639895   1.0      0.0  0.0
639896   0.0      0.0  1.0
639897   1.0      0.0  0.0
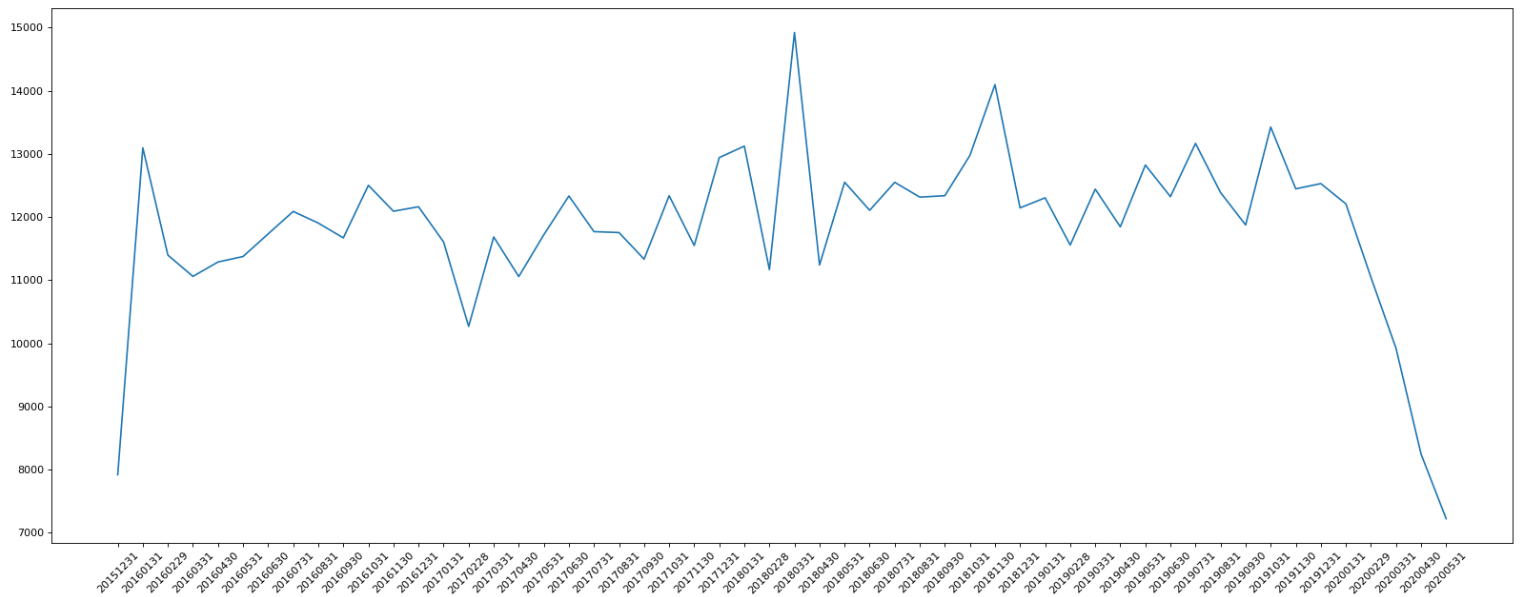
3.1.2 统计出911 数据中不同月份电话次数的变化情况
使用pandas 提供的方法把时间字符串转化为时间序列
(1)df[“timeStamp “] =pd.to_datetime (df[“timeStamp “],format =””)
format参数大部分情况下可以不用写,但是对于pandas 无法格式化的时间字符串,我们可以使用该参数,比如包含中文
(2)重采样:指的是将时间序列从一个频率转化为另一个频率进行处理的过程,将高频率数据转化为低频率数据为降采样,低频率转化为高频率为升采样
pandas提供了一个resample的方法来帮助我们实现频率转化
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
file_path = "911.csv"
df = pd.read_csv(file_path)
#print(df.info())
df["timeStamp"] = pd.to_datetime(df["timeStamp"])
#将时间字符串转化为时间序列,给数据盖上dataframe里面可以识别的时间戳
print(df["timeStamp"])
df.set_index("timeStamp", inplace=True)
#把时间戳设置为索引
#print(df)
count_by_month = df.resample("M").count()["title"]
#对数据进行重采样,降低其维度,进行聚合,把每个月的数据放在一起进行统计
#print(count_by_month)
#统计出911数据中不同月份电话次数的变化情况
#画图
_x = count_by_month.index
_y = count_by_month.values
'''
for i in _x:
print(dir(i))
break
'''
_x = [i.strftime("%Y%m%d") for i in _x]
plt.figure(figsize=(20, 8), dpi=80)
#在图像显示中,我们并不需要几分几秒具体的信息
plt.plot(range(len(_x)), _y)
plt.xticks(range(len(_x)), _x, rotation=45)
plt.show()

时间格式化
python中时间日期格式化符号:
%y 两位数的年份表示(00-99)
%Y 四位数的年份表示(000-9999)
%m 月份(01-12)
%d 月内中的一天(0-31)
%H 24小时制小时数(0-23)
%I 12小时制小时数(01-12)
%M 分钟数(00=59)
%S 秒(00-59)
%a 本地简化星期名称
%A 本地完整星期名称
%b 本地简化的月份名称
%B 本地完整的月份名称
%c 本地相应的日期表示和时间表示
%j 年内的一天(001-366)
%p 本地A.M.或P.M.的等价符
%U 一年中的星期数(00-53)星期天为星期的开始
%w 星期(0-6),星期天为星期的开始
%W 一年中的星期数(00-53)星期一为星期的开始
%x 本地相应的日期表示
%X 本地相应的时间表示
%Z 当前时区的名称
%% %号本身
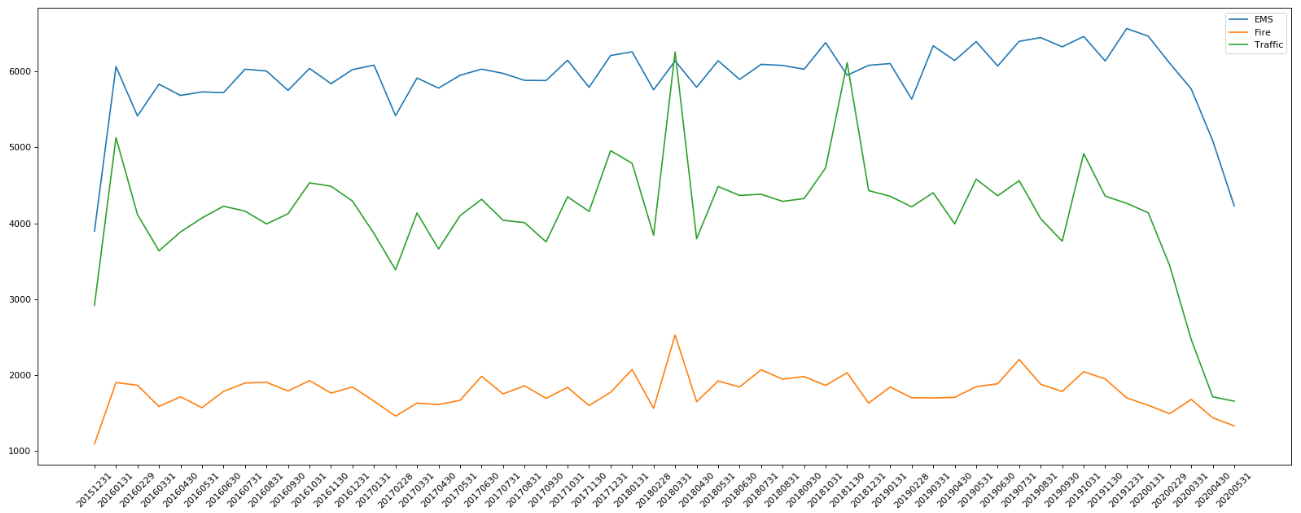
3.1.3 统计出911 数据中不同月份不同类型的电话的次数的变化情况
先将数据进行序列化,然后给将不同的紧急类型提取出来,转化为一列,把时间戳设置为索引,按照紧急类型进行分组,对每一组的数据都进行绘图分析
#统计出911数据中不同月份不同类型的电话的次数的变化情况
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
def plot_img(df, label):
count_by_month = df.resample("M").count()["title"]
_x = count_by_month.index
_y = count_by_month.values
_x = [i.strftime("%Y%m%d") for i in _x]
plt.plot(range(len(_x)), _y, label=label)
plt.xticks(range(len(_x)), _x, rotation=45)
file_path = "911.csv"
df = pd.read_csv(file_path)
df["timeStamp"] = pd.to_datetime(df["timeStamp"])
#添加列,表示分类
temp_list = df["title"].str.split(":").tolist()
cate_list = [i[0] for i in temp_list]
#print(cate_list)
df["cate"] = pd.DataFrame(np.array(cate_list).reshape((df.shape[0], 1)))
#创建了cate这一列,但是这列中并没有具体的类型
#print(df["cate"])
df.set_index("timeStamp", inplace=True)
#print(df.head(1))
cate = df.groupby(by="cate").count()
#print(cate)
plt.figure(figsize=(20, 8), dpi=80)
for group_name, group_data in df.groupby(by="cate"):
#对不同的分类都进行绘图
plot_img(group_data, group_name)
plt.legend(loc="best")
plt.show()
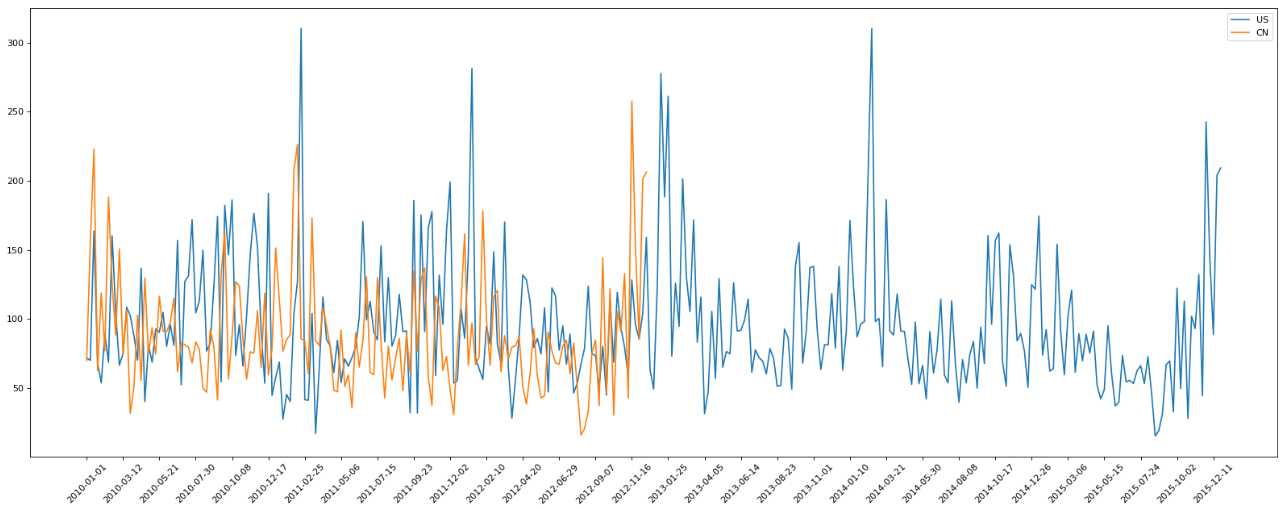
3.2 PM2.5数据分析
现在我们有北上广、深圳、和沈阳5 个城市空气质量数据,请绘制出5 个城市的PM2.5随时间的变化情况
数据来源:https://www.kaggle.com/uciml/pm25-data-for-five-chinese-cities
观察这组数据中的时间结构,并不是字符串,这个时候我们应该怎么办?
利用PeriodIndex将字符串时间转换成时间序列的时间戳
periods =pd.PeriodIndex (year =data[“year”],month=data[“month”],day=data[“day”],hour=data[“hour”],freq =”H”)
import pandas as pd
from matplotlib import pyplot as plt
file_path = "BeijingPM20100101_20151231.csv"
df = pd.read_csv(file_path)
#print(df.info())
#把分开的时间字符串通过periodIndex的方法转换为pandas的时间类型
period = pd.PeriodIndex(year=df["year"], month=df["month"], day=df["day"], hour=df["hour"], freq="H")
#print(period)
#print(type(period))
#<class 'pandas.core.indexes.period.periodindex'>
#把datetime设置成索引
df["datetime"] = period
#print(df.head(10))
df.set_index("datetime", inplace=True)
#对数据进行降采样
df = df.resample("7D").mean()
#print(df)
#处理缺失数据,删除缺失数据
data = df["PM_US Post"].dropna()
china_data = df["PM_Dongsi"].dropna()
_x = data.index
_x_china = china_data.index
_y = data.values
_y_china = china_data.values
plt.figure(figsize=(20, 8), dpi=80)
plt.plot(range(len(_x)), _y, label="US")
plt.plot(range(len(_x_china)), _y_china, label="CN")
plt.xticks(range(0, len(_x), 10), list(_x)[::10], rotation=45)
plt.legend(loc="best")
plt.show()</class>
Original: https://blog.csdn.net/weixin_51589123/article/details/116762053
Author: 斯外戈的小白
Title: 时间序列pandas的创建date_range+时间戳的序列化to_datetime+重采样resample+将字符串时间转化为时间序列PeriodIndex(传入年月日)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/679967/
转载文章受原作者版权保护。转载请注明原作者出处!