

阅读论文:《An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale》
来源:ICLR 2021 https://arxiv.org/abs/2010.11929
代码:https://github.com/google-research/vision_transformer
一、提出问题
这个工作保留了Transformer的基本结构和思想,迁移到了经典的图像分类问题。通过实验,作者认为CNN并不是必须的,只用Transformer也能够在分类任务中表现很好,尤其是在使用大规模训练集的时候。同时,在大规模数据集上预训练好的模型,在迁移到中等数据集或小数据集的分类任务上以后,也能取得比CNN更优的性能。
引入:
基于self-attention机制的Transformer结构是自然语言处理模型(NLP)的首选模型,其主要方法是在大型文本语料库上进行预训练,然后在较小的特定于任务的数据集上进行fine-tuning。
在计算机视觉中,卷积神经网络(ResNet)仍然占主导地位,此前的研究有受到NLP的启发,尝试将self-attention机制融合到CNN结构中,但由于使用了专门设定的注意力模式,因此尚未实现有效地扩展。
本文作者受到NLP中Transformer的启发,通过将图像拆分为小patch,之后进行线性嵌入序列作为Transformer的输入。最后以监督方式对模型进行图像分类任务的训练。
二、主要思想
Transformer结构:


本文提出的模型:
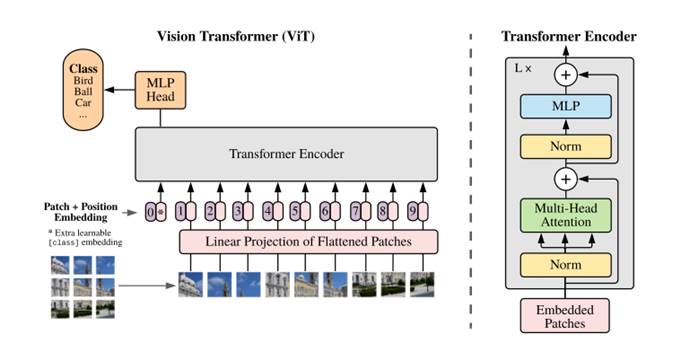
Embadding:

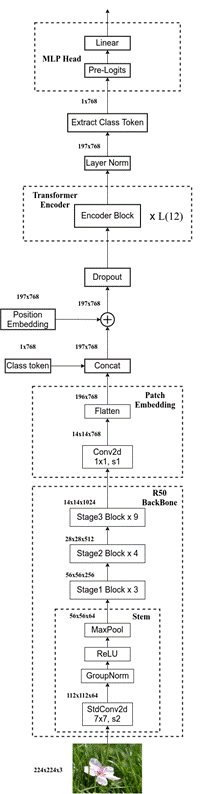
使用了Transformer结构中的Encoder结构,由于标准的Transformer结构是一维的句子embadding,即二维矩阵[num_token, token_dim],所以需要对二维图像进行展平操作以适应结构。
以大小为224*224的图像为例,其数据格式为[H, W, C]三维格式,所以需要先通过Embedding层对数据做个变换。选取patch_size为16(ViT-B/16模型),输入图像RGB三个维度的数据,对每一个维度按给定大小分成一堆Patches:(224/16)x(224/16)=196 个;其中每一个patch目前的shape为[16, 16, 3],通过一个线性映射将其展平为shape为[768]的向量
具体代码实现中使用了einops库的Rearrange操作:

此外,在embadding后的图像序列中加了一个可学习的embedding向量专门用作分类,该序列在Transformer Encode的输出可以用作得出图像分类的y。这个[class] token的格式和其他Token保持一致:shape为[768]的向量。之后和shape为[196,768]图片Token序列进行Concat拼接操作得到[197, 768]维Token数据。
类同于Transformer中的Positional Encoding,此处也采用了一个可以训练的Position Embedding,维度也是[197, 768]维。两者进行add操作,最后得到的embadding为[197, 768]维。


Transformer Encoder:

由multi-head self-attention(MSA)和MLP块组成,在每个块之前应用Layer norm(LN),在每个块之后应用残差连接。MLP包含具有GELU和两全连接层。
主要包括:
Norm层:此处使用了Layer Norm
残差连接:参考Resnet的结构
多头注意力机制:Multi-Head Attention,类同于Tramsformer
MLP Block:全连接+GELU激活函数+Dropout
最后输出的数据维度仍然是[197,768]维。
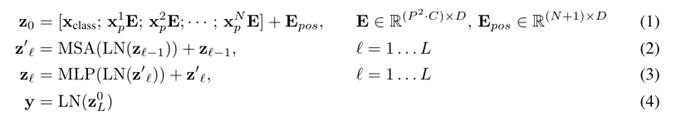




MLP Head:

对于分类任务,只需要提取出[class]token生成的对应结果即可,即[197, 768]维中抽取出[class]token对应的[1, 768]。MLP Head主要就是一个普通的分类结构:Layer Norm后加一个Linear,最后softmax分类即可。
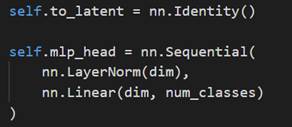

训练采取先在大数据集上预训练,再迁移到小数据集上面。做法是把ViT的MLP Head去掉,换成一个768 x K的全连接层。其中K为对应数据集的类别数。
三、实验
实验一:效果测试

性能超过了CNN的SOTA结果(对比:Big Transfer (BiT)模型和Noisy Student模型)
实验二:对预训练数据的要求

数据集扩大后,ViT模型的优势显著。
实验三:注意力机制

四、存在的问题以及改进
CNN模型在图像任务中会有一些优点,比如平移不变性和局部性等,这些特点Transformer并不具备,因此该方法在训练不足的数据量时不能很好地学习,从结果上来看对中等规模的数据集进行训练时,精度要低于同等大小的ResNet系列模型。但对于更大规模的数据集(JFT-300)上的训练,CNN模型可能会趋于饱和,Transformer的性能要胜过inductive bias。但是首先JFT-300是私有的数据集,很难复现结果;此外,Transformer结构若想取得理想的性能和泛化能力,计算资源和数据集都不具备,很难有所收获。
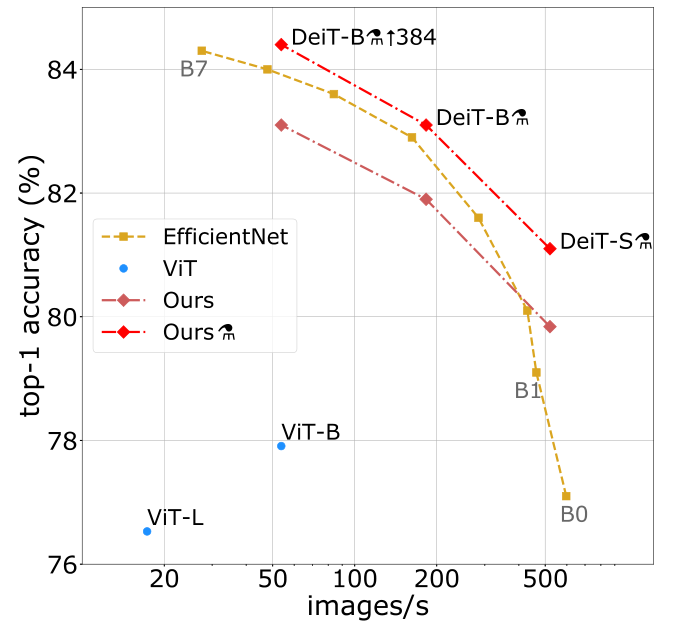
对此的解决:《Training data-efficient image transformers & distillation through attention》
使用一个性能很好的分类器 (CNN/Transformer,实验验证) 作为teacher model,设定了distillation token和蒸馏损失,通过知识蒸馏的方法进行训练。
主要改进:引入了一个distillation token,然后在自注意力机制中跟class token、patch token不断交互学习知识,这个distillation token要跟teacher model预测的label一致。





五、扩展
基于这个思想,传统的CNN网络也可以和Transformer结合起来,将其他网络尾部的特征取出来进行Patch embadding,然后按照类似的方法进行组合和训练。
Vision Transformer在其提出的一年期间,很多应用于图像检索、ReID、自监督学习等领域的Vision Transformer快速被提出,并取得了较为优异的成绩。
多目标跟踪 (MOT):《TrackFormer: Multi-Object Tracking with Transformers》

3D:《3D-Transformer: Molecular Representation with Transformer in 3D Space》

YOLOS:《You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection》

点云:《PoinTr: Diverse Point Cloud Completion with Geometry-Aware Transformers》
Neural Architecture Search:《GLiT: Neural Architecture Search for Global and Local Image Transformer》

自动驾驶:《Multi-Modal Fusion Transformer for End-to-End Autonomous Driving》

文本到视觉检索:《Thinking Fast and Slow: Efficient Text-to-Visual Retrieval with Transformers》

基于自然语言查询视频帧片段:《QVHighlights: Detecting Moments and Highlights in Videos via Natural Language Queries》

掩码自编码器:《Masked Autoencoders Are Scalable Vision Learners》

Original: https://www.cnblogs.com/jiojio-star/p/16078864.html
Author: jiojio-star
Title: 论文阅读:《An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale》
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/568138/
转载文章受原作者版权保护。转载请注明原作者出处!